




2026年にRAGに最適な埋め込みモデルを選ぶ方法:10モデルをベンチマーク済み
要約: 公開ベンチマークでは見落とされる4つの本番シナリオ(クロスモーダル検索、クロスリンガル検索、キー情報検索、次元圧縮)で、10個のembedding modelsをテストしました。すべてで勝つ単一のモデルはありません。Gemini Embedding 2は最も優れたオールラウンダーです。オープンソースのQwen3-VL-2Bは、クロスモーダルタスクでクローズドソースAPIを上回ります。ストレージを節約するために次元を圧縮する必要があるなら、Voyage Multimodal 3.5またはJina Embeddings v4を選ぶべきです。
埋め込みモデル選定にMTEBだけでは不十分な理由
ほとんどのRAGプロトタイプは、OpenAIのtext-embedding-3-smallから始まります。安価で、統合しやすく、英語テキスト検索では十分に機能します。しかし本番RAGではすぐに限界が来ます。パイプラインが画像、PDF、多言語ドキュメントを扱うようになると、テキスト専用のembedding modelでは不十分になります。
MTEB leaderboardを見ると、より優れた選択肢があることがわかります。問題は何でしょうか?MTEBは単一言語のテキスト検索しかテストしません。クロスモーダル検索(画像コレクションに対するテキストクエリ)、クロスリンガル検索(中国語クエリで英語ドキュメントを見つける)、長文ドキュメントでの精度、あるいはvector databaseのストレージを節約するためにembedding dimensionsを切り詰めたときにどれだけ品質が失われるかはカバーしていません。
では、どの埋め込みモデルを使うべきでしょうか?それはデータ型、言語、ドキュメント長、そして次元圧縮が必要かどうかによって異なります。私たちはCCKMというベンチマークを構築し、2025年から2026年にリリースされた10個のモデルを、まさにこれらの軸でテストしました。
CCKMベンチマークとは?
CCKM(Cross-modal、Cross-lingual、Key information、MRL)は、標準的なベンチマークでは見落とされる4つの能力をテストします。
| Dimension | What It Tests | Why It Matters |
|---|---|---|
| クロスモーダル検索 | ほぼ同一の紛らわしい候補がある中で、テキスト説明を正しい画像に一致させる | Multimodal RAGパイプラインでは、テキストと画像の埋め込みが同じベクトル空間にある必要があります |
| クロスリンガル検索 | 中国語クエリから正しい英語ドキュメントを見つける、またはその逆 | 本番ナレッジベースは多言語であることが多いです |
| キー情報検索 | 4K〜32K文字のドキュメントに埋もれた特定の事実を特定する(needle-in-a-haystack) | RAGシステムは、契約書や研究論文のような長文ドキュメントを頻繁に処理します |
| MRL次元圧縮 | 埋め込みを256次元に切り詰めたときに、モデルがどれだけ品質を失うかを測定する | 次元数が少ない = ベクトルデータベースのストレージコストが低い、しかし品質コストはどれくらいか? |
MTEBはこれらを一切カバーしていません。MMEBはマルチモーダルを追加していますが、難しいネガティブ例を省いているため、モデルは微妙な違いを扱えることを証明しなくても高スコアを取れます。CCKMは、それらが見落としているものをカバーするように設計されています。
どの埋め込みモデルをテストしたのか?Gemini Embedding 2、Jina Embeddings v4など
APIサービスとオープンソースの選択肢の両方に加え、2021年のベースラインとしてCLIP ViT-L-14を含む10個のモデルをテストしました。
| モデル | 提供元 | パラメータ | 次元数 | モダリティ | 主な特徴 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | 非公開 | 3072 | テキスト / 画像 / 動画 / 音声 / PDF | 全モダリティ対応、最も広いカバレッジ | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | テキスト / 画像 / PDF | MRL + LoRA アダプター |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | 非公開 | 1024 | テキスト / 画像 / 動画 | タスク間でバランスがよい |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | テキスト / 画像 / 動画 | オープンソース、軽量なマルチモーダル |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | テキスト / 画像 | 現代化された CLIP アーキテクチャ |
| Cohere Embed v4 | Cohere | 非公開 | 固定 | テキスト | エンタープライズ検索 |
| OpenAI text-embedding-3-large | OpenAI | 非公開 | 3072 | テキスト | 最も広く使われている |
| BGE-M3 | BAAI | 568M | 1024 | テキスト | オープンソース、100+ 言語 |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | テキスト | 軽量、英語に重点 |
| nomic-embed-text | Nomic AI | 137M | 768 | テキスト | 超軽量 |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | テキスト / 画像 | ベースライン |
クロスモーダル検索: テキストから画像を検索できるモデルはどれか?
RAG パイプラインがテキストと並んで画像を扱う場合、埋め込みモデルは両方のモダリティを同じベクトル空間に配置する必要があります。EC の画像検索、画像とテキストが混在するナレッジベース、あるいはテキストクエリで適切な画像を見つける必要があるあらゆるシステムを考えてみてください。
方法
COCO val2017 から 200 組の画像・テキストペアを取得しました。各画像について、GPT-4o-mini が詳細な説明を生成しました。その後、画像ごとに 3 つの難しいネガティブ例を書きました。これは正解の説明とわずか 1 つか 2 つの詳細だけが異なる説明です。モデルは、200 枚の画像と 600 個の撹乱候補のプールの中から正しい一致を見つける必要があります。
データセットの例:
 California や Cuba を含む旅行ステッカーが貼られたヴィンテージの茶色い革製スーツケースが、青空を背景に金属製の荷物ラックの上に置かれている — クロスモーダル検索ベンチマークのテスト画像として使用
California や Cuba を含む旅行ステッカーが貼られたヴィンテージの茶色い革製スーツケースが、青空を背景に金属製の荷物ラックの上に置かれている — クロスモーダル検索ベンチマークのテスト画像として使用
正しい説明: "画像には、'California'、'Cuba'、'New York' などのさまざまな旅行ステッカーが貼られたヴィンテージの茶色い革製スーツケースが、澄んだ青空を背景に金属製の荷物ラックの上に置かれている様子が写っています。"
難しいネガティブ: 同じ文だが、"California" が "Florida" になり、"blue sky" が "overcast sky" になる。モデルはこれらを区別するために、画像の詳細を実際に理解しなければなりません。
スコアリング:
- すべての画像とすべてのテキスト(200 個の正しい説明 + 600 個の難しいネガティブ)について埋め込みを生成する。
- テキストから画像 (t2i): 各説明が 200 枚の画像から最も近い一致を検索する。トップ結果が正しければ 1 点。
- 画像からテキスト (i2t): 各画像が 800 個すべてのテキストから最も近い一致を検索する。トップ結果が難しいネガティブではなく正しい説明の場合のみ 1 点。
- 最終スコア: hard_avg_R@1 = (t2i accuracy + i2t accuracy) / 2
結果
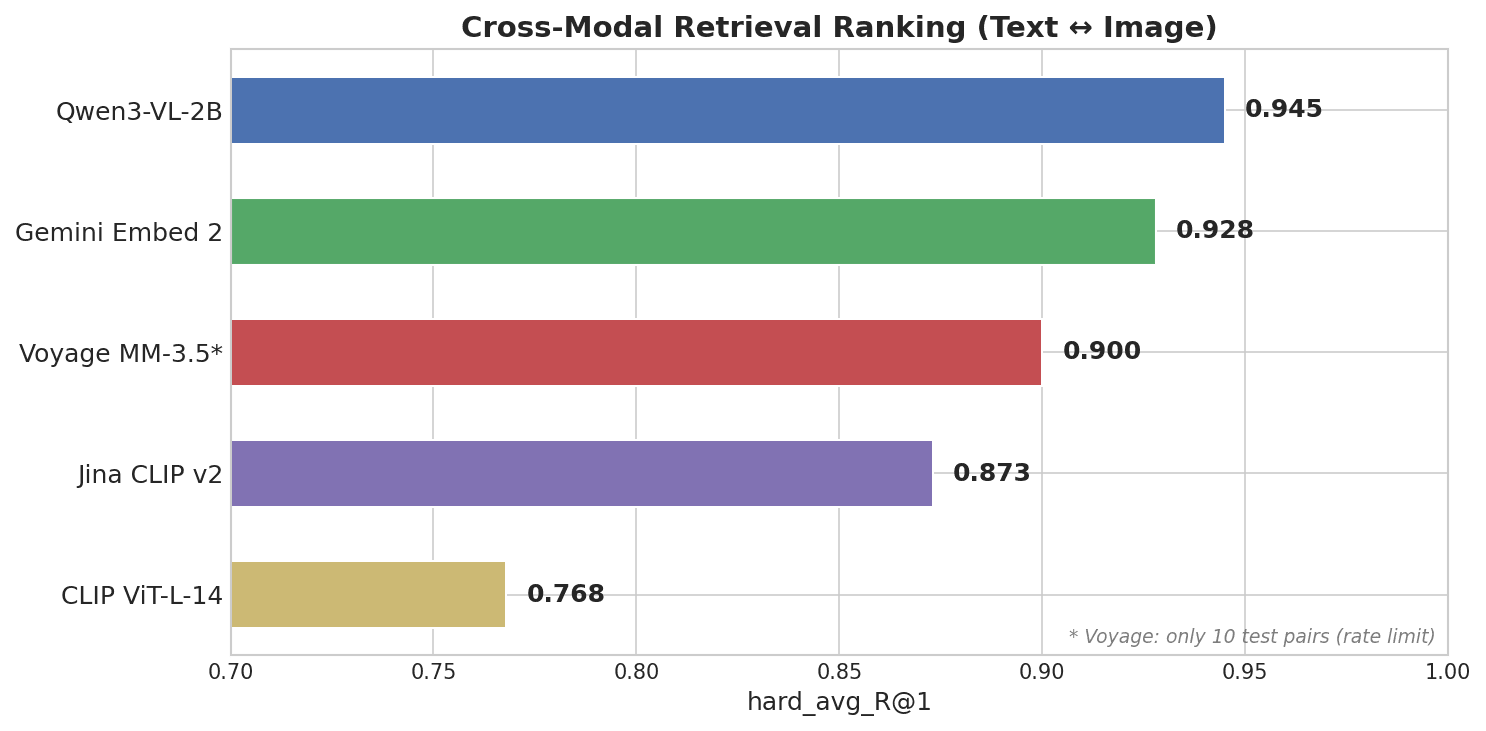 クロスモーダル検索ランキングを示す横棒グラフ: Qwen3-VL-2B が 0.945 で首位、続いて Gemini Embed 2 が 0.928、Voyage MM-3.5 が 0.900、Jina CLIP v2 が 0.873、CLIP ViT-L-14 が 0.768
クロスモーダル検索ランキングを示す横棒グラフ: Qwen3-VL-2B が 0.945 で首位、続いて Gemini Embed 2 が 0.928、Voyage MM-3.5 が 0.900、Jina CLIP v2 が 0.873、CLIP ViT-L-14 が 0.768
Alibaba の Qwen チームによるオープンソースの 2B パラメータモデルである Qwen3-VL-2B が、すべてのクローズドソース API を上回って 1 位になりました。
モダリティギャップが差の大部分を説明します。埋め込みモデルはテキストと画像を同じベクトル空間にマッピングしますが、実際には 2 つのモダリティは異なる領域にクラスタリングされる傾向があります。モダリティギャップは、これら 2 つのクラスタ間の L2 距離を測定します。ギャップが小さいほど、クロスモーダル検索は容易になります。
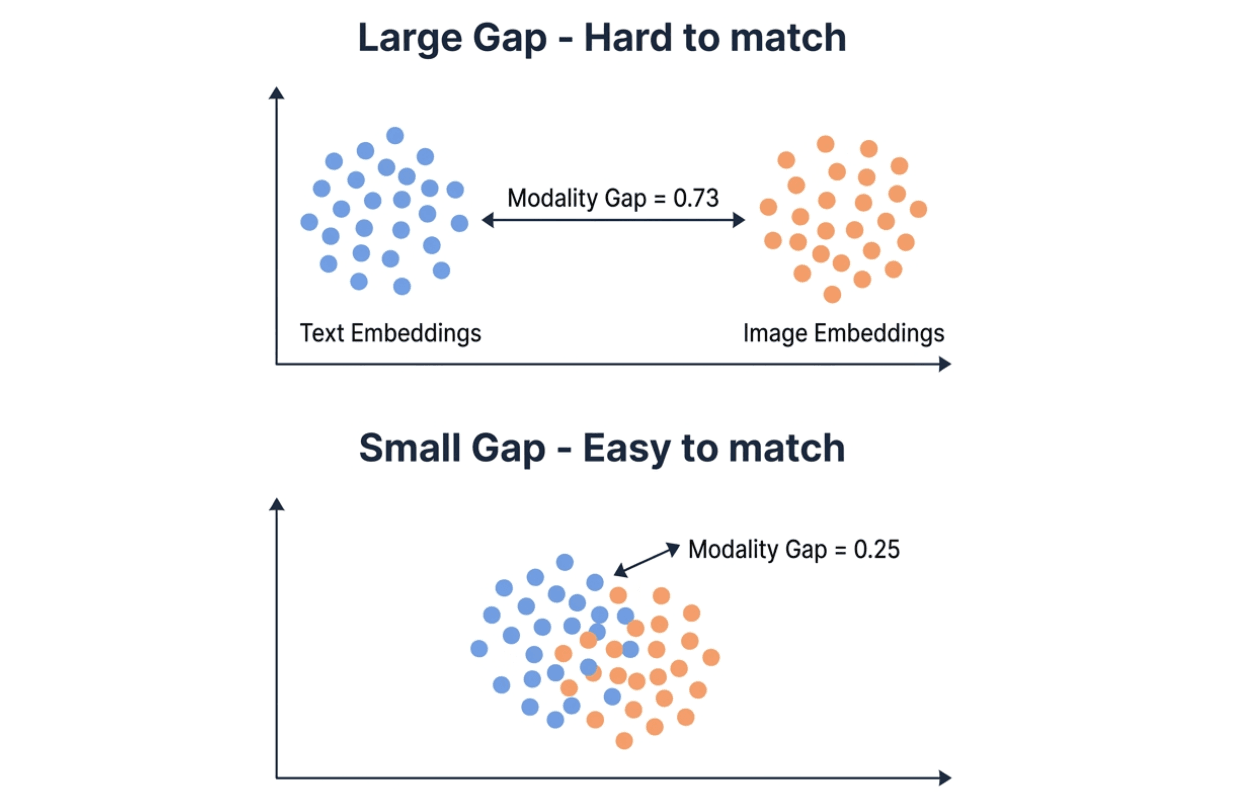 大きなモダリティギャップ(0.73、テキストと画像の埋め込みクラスタが大きく離れている)と小さなモダリティギャップ(0.25、クラスタが重なっている)の比較可視化 — ギャップが小さいほどクロスモーダルマッチングが容易になる
大きなモダリティギャップ(0.73、テキストと画像の埋め込みクラスタが大きく離れている)と小さなモダリティギャップ(0.25、クラスタが重なっている)の比較可視化 — ギャップが小さいほどクロスモーダルマッチングが容易になる
| モデル | スコア (R@1) | モダリティギャップ | パラメータ |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Unknown (closed) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Unknown (closed) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Qwenのモダリティギャップは0.25で、Geminiの0.73のおよそ3分の1です。Milvusのようなベクトルデータベースでは、モダリティギャップが小さいということは、テキストと画像の埋め込みを同じコレクションに格納し、両方をまたいで直接検索できることを意味します。ギャップが大きいと、クロスモーダルな類似性検索の信頼性が低下する可能性があり、それを補うために再ランキングのステップが必要になる場合があります。
クロスリンガル検索:どのモデルが言語を越えて意味をそろえられるか?
多言語ナレッジベースは本番環境で一般的です。ユーザーが中国語で質問する一方、答えは英語の文書にある、あるいはその逆もあります。埋め込みモデルには、1つの言語内だけでなく、言語を越えて意味を対応付けることが求められます。
方法
中国語と英語で、3つの難易度レベルにわたる166組の対訳文ペアを作成しました。
 クロスリンガルの難易度ティア:Easyティアは「我爱你」から「I love you」のような直訳を対応付ける;Mediumティアは「这道菜太咸了」から「This dish is too salty」のような言い換え文を、難しいネガティブ例とともに対応付ける;Hardティアは「画蛇添足」のような中国語の慣用句を「gilding the lily」に対応付け、意味的に異なる難しいネガティブ例を含む
クロスリンガルの難易度ティア:Easyティアは「我爱你」から「I love you」のような直訳を対応付ける;Mediumティアは「这道菜太咸了」から「This dish is too salty」のような言い換え文を、難しいネガティブ例とともに対応付ける;Hardティアは「画蛇添足」のような中国語の慣用句を「gilding the lily」に対応付け、意味的に異なる難しいネガティブ例を含む
各言語には、さらに152件の難しいネガティブの撹乱候補があります。
スコアリング:
- すべての中国語テキスト(166件の正解 + 152件の撹乱候補)とすべての英語テキスト(166件の正解 + 152件の撹乱候補)について埋め込みを生成します。
- 中国語 → 英語: 各中国語文が318件の英語テキストから正しい翻訳を検索します。
- 英語 → 中国語: 逆方向でも同様に行います。
- 最終スコア: hard_avg_R@1 = (zh→en accuracy + en→zh accuracy) / 2
結果
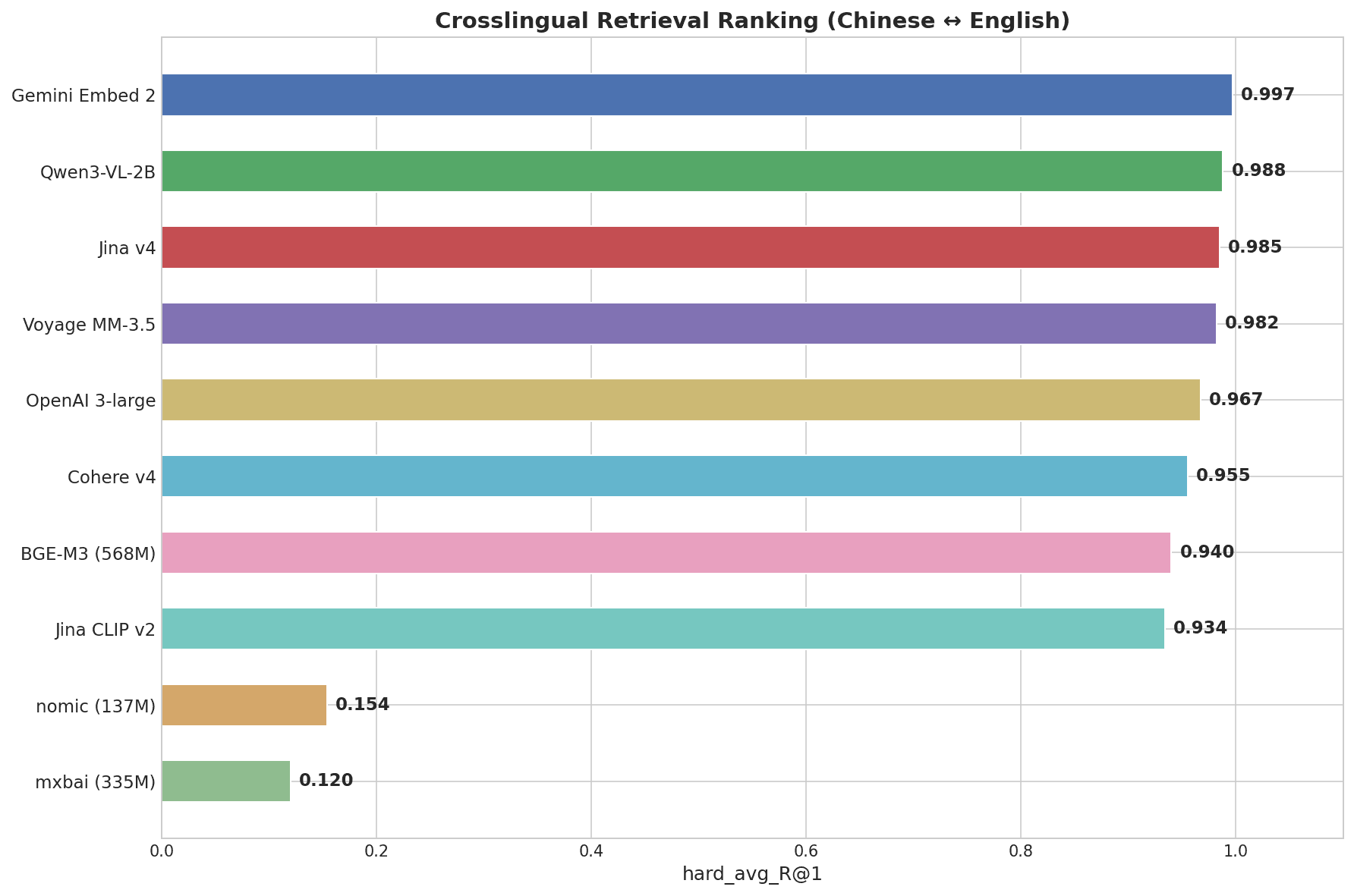 クロスリンガル検索ランキングを示す横棒グラフ:Gemini Embed 2が0.997で首位、続いてQwen3-VL-2Bが0.988、Jina v4が0.985、Voyage MM-3.5が0.982、最下位はmxbaiの0.120
クロスリンガル検索ランキングを示す横棒グラフ:Gemini Embed 2が0.997で首位、続いてQwen3-VL-2Bが0.988、Jina v4が0.985、Voyage MM-3.5が0.982、最下位はmxbaiの0.120
Gemini Embedding 2は0.997を記録し、テストしたすべてのモデルの中で最高でした。「画蛇添足」→「gilding the lily」のようなペアで、パターンマッチングではなく言語を越えた本物の意味的理解が求められるHardティアで、唯一1.000の満点を獲得したモデルでした。
| モデル | スコア (R@1) | Easy | Medium | Hard(慣用句) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
上位7モデルはいずれも総合スコアで0.93を上回っています。実際の差別化はHardティア(中国語の慣用句)で起こります。nomic-embed-textとmxbai-embed-largeはいずれも英語重視の軽量モデルで、クロスリンガルタスクではほぼゼロに近いスコアです。
重要情報検索:モデルは32Kトークンの文書から針を見つけられるか?
RAGシステムは、法務契約書、研究論文、非構造化データを含む社内レポートなど、長いドキュメントを処理することがよくあります。問題は、埋め込みモデルが、周囲にある何千文字ものテキストに埋もれた特定の事実を、それでも見つけられるかどうかです。
方法
さまざまな長さ(4K〜32K文字)のWikipedia記事を干し草の山として用意し、単一の架空の事実(針)を、先頭、25%、50%、75%、末尾の異なる位置に挿入しました。モデルは、クエリ埋め込みに基づいて、どのバージョンのドキュメントに針が含まれているかを判断する必要があります。
例:
- 針: 「The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025.」
- クエリ: 「Meridian Corporationの四半期売上高はいくらでしたか?」
- 干し草の山: 光合成に関する32,000文字のWikipedia記事で、そのどこかに針が隠されています。
スコアリング:
- クエリ、針を含むドキュメント、含まないドキュメントの埋め込みを生成します。
- クエリが、針を含むドキュメントに対してより類似している場合、ヒットとしてカウントします。
- すべてのドキュメント長と針の位置にわたって精度を平均します。
- 最終指標: overall_accuracyとdegradation_rate(最短ドキュメントから最長ドキュメントまでで精度がどれだけ低下するか)。
結果
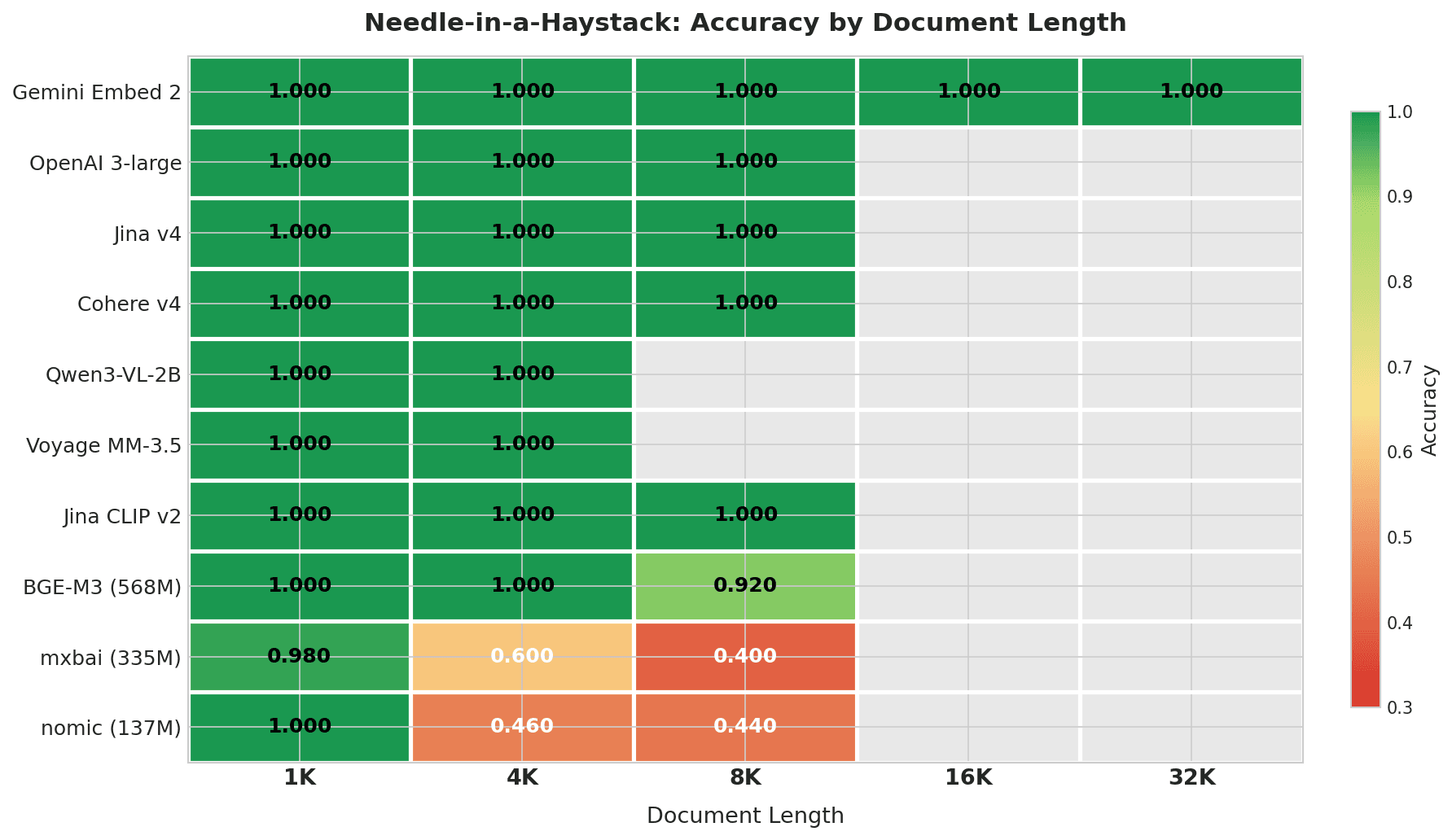 ドキュメント長別のNeedle-in-a-Haystack精度を示すヒートマップ: Gemini Embed 2は32Kまでの全長で1.000を記録、上位7モデルは各自のコンテキストウィンドウ内で完全スコア、mxbaiとnomicは4K+で急激に低下
ドキュメント長別のNeedle-in-a-Haystack精度を示すヒートマップ: Gemini Embed 2は32Kまでの全長で1.000を記録、上位7モデルは各自のコンテキストウィンドウ内で完全スコア、mxbaiとnomicは4K+で急激に低下
Gemini Embedding 2は、4K〜32Kの全範囲でテストされた唯一のモデルであり、すべての長さで完全なスコアを記録しました。このテストにおける他のモデルには、32Kに達するコンテキストウィンドウがありません。
| Model | 1K | 4K | 8K | 16K | 32K | Overall | Degradation |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
「—」は、ドキュメント長がモデルのコンテキストウィンドウを超えていることを意味します。
上位7モデルは、それぞれのコンテキストウィンドウ内で完全なスコアを記録しています。BGE-M3は8Kで低下し始めます(0.920)。軽量モデル(mxbaiとnomic)は、わずか4K文字(およそ1,000トークン)で0.4〜0.6まで低下します。mxbaiの場合、この低下は512トークンのコンテキストウィンドウによってドキュメントの大半が切り捨てられることを部分的に反映しています。
MRL次元圧縮: 256次元でどれだけ品質を失うのか?
Matryoshka Representation Learning (MRL) は、ベクトルの最初のN次元だけでも意味を持つようにするトレーニング手法です。3072次元のベクトルを256次元に切り詰めても、その意味的品質の大部分は維持されます。次元数が少ないほど、ベクトルデータベースにおけるストレージとメモリのコストは低くなります。3072次元から256次元にすると、ストレージは12分の1に削減されます。
 MRL次元切り詰めを示す図: 3072次元でフル品質、1024で95%、512で90%、256で85% — 256次元で12倍のストレージ削減
MRL次元切り詰めを示す図: 3072次元でフル品質、1024で95%、512で90%、256で85% — 256次元で12倍のストレージ削減
方法
STS-Bベンチマークから、人手で注釈付けされた類似度スコア(0〜5)を持つ150組の文ペアを使用しました。各モデルについて、フル次元で埋め込みを生成し、その後1024、512、256に切り詰めました。
 人間による類似度スコア付きの文ペアを示すSTS-Bデータ例:A girl is styling her hair vs A girl is brushing her hair のスコアは2.5、A group of men play soccer on the beach vs A group of boys are playing soccer on the beach のスコアは3.6
人間による類似度スコア付きの文ペアを示すSTS-Bデータ例:A girl is styling her hair vs A girl is brushing her hair のスコアは2.5、A group of men play soccer on the beach vs A group of boys are playing soccer on the beach のスコアは3.6
スコアリング:
- 各次元レベルで、各文ペアの埋め込み間のコサイン類似度を計算します。
- スピアマンのρ(順位相関)を使って、モデルの類似度ランキングを人間のランキングと比較します。
スピアマンのρとは? 2つのランキングがどれだけ一致しているかを測定する指標です。人間がペアAを最も類似、Bを2番目、Cを最も低いと順位付けし、モデルのコサイン類似度も同じ順序 A > B > C を生成する場合、ρは1.0に近づきます。ρが1.0なら完全一致を意味します。ρが0なら相関がないことを意味します。
最終指標: spearman_rho(高いほど良い)と min_viable_dim(品質がフル次元の性能の5%以内に留まる最小次元)。
結果
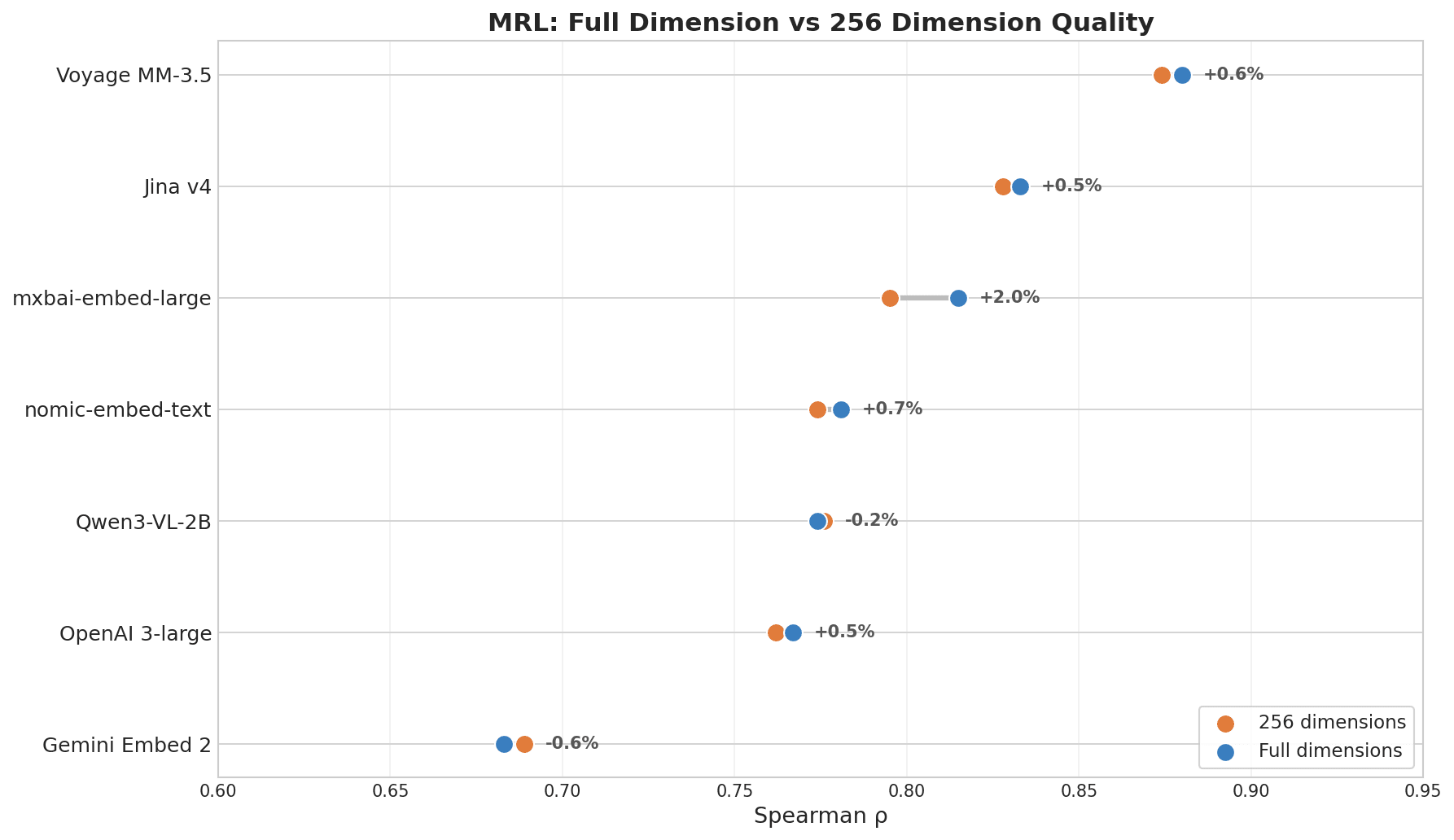 MRLのフル次元と256次元の品質を示すドットプロット:Voyage MM-3.5が+0.6%の変化で首位、Jina v4が+0.5%、一方Gemini Embed 2は最下位で-0.6%
MRLのフル次元と256次元の品質を示すドットプロット:Voyage MM-3.5が+0.6%の変化で首位、Jina v4が+0.5%、一方Gemini Embed 2は最下位で-0.6%
Milvusや別のベクトルデータベースで次元を切り詰めてストレージコストを削減する予定があるなら、この結果は重要です。
| モデル | ρ(フル次元) | ρ(256次元) | 低下 |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
VoyageとJina v4がリードしているのは、どちらもMRLを目的関数として明示的に学習されているためです。次元圧縮はモデルサイズとはほとんど関係ありません。そのために学習されていたかどうかが重要です。
Geminiのスコアに関する注記:MRLランキングは、モデルが切り詰め後に品質をどれだけ維持できるかを反映するものであり、フル次元での検索がどれほど優れているかを示すものではありません。Geminiのフル次元検索は強力です。クロスリンガルおよび重要情報の結果がすでにそれを証明しています。ただし、縮小向けに最適化されていなかっただけです。次元圧縮が不要なら、この指標はあなたには関係ありません。
どの埋め込みモデルを使うべきか?
すべてに勝つ単一のモデルはありません。以下が完全なスコアカードです。
| モデル | パラメータ | クロスモーダル | クロスリンガル | 重要情報 | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | 非公開 | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | 非公開 | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | 非公開 | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | 非公開 | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
「—」は、そのモデルがそのモダリティまたは機能をサポートしていないことを意味します。CLIPは参考用の2021年のベースラインです。
目立つ点は次のとおりです:
- クロスモーダル: Qwen3-VL-2B (0.945) が1位、Gemini (0.928) が2位、Voyage (0.900) が3位。オープンソースの2Bモデルが、すべてのクローズドソースAPIを上回った。決定要因はパラメータ数ではなく、モダリティギャップだった。
- クロスリンガル: Gemini (0.997) がリード — イディオムレベルのアラインメントで満点を獲得した唯一のモデル。上位8モデルはすべて0.93を超えている。英語専用の軽量モデルはほぼゼロに近いスコア。
- 重要情報: APIと大規模オープンソースモデルは、8Kまで満点を獲得。335M未満のモデルは4Kで劣化し始める。Geminiは32Kを満点で処理できる唯一のモデル。
- MRL次元圧縮: Voyage (0.880) と Jina v4 (0.833) がリードし、256次元での損失は1%未満。Gemini (0.668) は最下位 — フル次元では強いが、切り詰めには最適化されていない。
選び方: 意思決定フローチャート
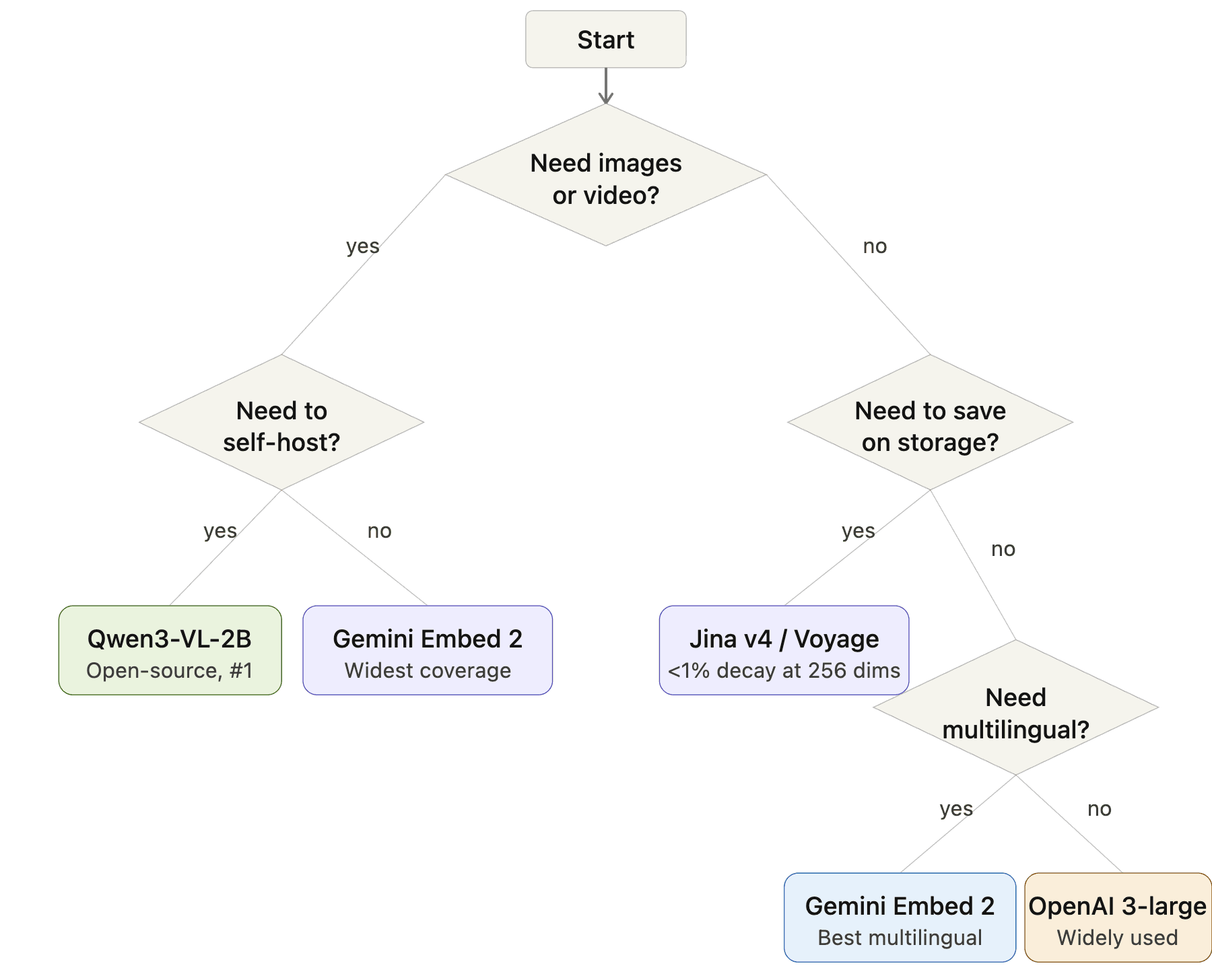 埋め込みモデル選択フローチャート: 開始 → 画像または動画が必要? → はい: セルフホストが必要? → はい: Qwen3-VL-2B、いいえ: Gemini Embedding 2。画像不要 → ストレージを節約する必要がある? → はい: Jina v4 または Voyage、いいえ: 多言語が必要? → はい: Gemini Embedding 2、いいえ: OpenAI 3-large
埋め込みモデル選択フローチャート: 開始 → 画像または動画が必要? → はい: セルフホストが必要? → はい: Qwen3-VL-2B、いいえ: Gemini Embedding 2。画像不要 → ストレージを節約する必要がある? → はい: Jina v4 または Voyage、いいえ: 多言語が必要? → はい: Gemini Embedding 2、いいえ: OpenAI 3-large
最高のオールラウンダー: Gemini Embedding 2
総合的に見て、Gemini Embedding 2はこのベンチマークで最も強力な全体モデルです。
強み: クロスリンガル (0.997) と重要情報検索 (32Kまでの全長で1.000) で1位。クロスモーダル (0.928) で2位。最も広いモダリティ対応 — ほとんどのモデルが3つで頭打ちになる中、5つのモダリティ(テキスト、画像、動画、音声、PDF)に対応。
弱み: MRL圧縮 (ρ = 0.668) で最下位。クロスモーダルではオープンソースのQwen3-VL-2Bに敗れている。
次元圧縮が不要なら、Geminiはクロスリンガル + 長文ドキュメント検索の組み合わせにおいて実質的な競合がありません。しかし、クロスモーダルの精度やストレージ最適化では、特化型モデルのほうが優れています。
制限事項
- 検討に値するすべてのモデルを含めたわけではありません — NVIDIAのNV-Embed-v2とJinaのv5-textはリストにありましたが、今回は対象に入りませんでした。
- テキストと画像モダリティに焦点を当てました。動画、音声、PDF埋め込み(一部のモデルが対応を主張しているにもかかわらず)は対象外でした。
- コード検索やその他のドメイン固有のシナリオはスコープ外でした。
- サンプルサイズは比較的小さいため、モデル間の僅差の順位差は統計的ノイズの範囲内に収まる可能性があります。
この記事の結果は1年以内に古くなります。新しいモデルは絶えずリリースされ、リーダーボードはリリースのたびに入れ替わります。より持続的な投資は、独自の評価パイプラインを構築することです — 自分のデータタイプ、クエリパターン、ドキュメント長を定義し、新しいモデルが出たら自分のテストにかける。MTEB、MMTEB、MMEBのような公開ベンチマークは監視する価値がありますが、最終判断は常に自分のデータから下すべきです。
私たちのベンチマークコードはGitHubでオープンソース公開されています — フォークして、あなたのユースケースに合わせて適応してください。
埋め込みモデルを選んだら、それらのベクトルを大規模に保存・検索する場所が必要です。Milvus は、まさにそのために構築された世界で最も広く採用されているオープンソースのベクトルデータベースで、GitHubスター43K+ を獲得しており、MRLで切り詰められた次元、混合マルチモーダルコレクション、密ベクトルと疎ベクトルを組み合わせたハイブリッド検索をサポートし、ラップトップから数十億ベクトルまでスケールします。
- Milvus Quickstart guideで始めるか、
pip install pymilvusでインストールしてください。 - 埋め込みモデルの統合、ベクトルインデックス戦略、本番環境でのスケーリングについて質問するには、Milvus SlackまたはMilvus Discordに参加してください。
- RAGアーキテクチャについて詳しく相談するには、無料のMilvus Office Hoursセッションを予約してください。モデル選定、コレクションスキーマ設計、パフォーマンスチューニングをお手伝いできます。
- インフラ作業を省きたい場合は、Zilliz Cloud(マネージドMilvus)が、開始用の無料枠を提供しています。
エンジニアが本番RAG向けの埋め込みモデルを選ぶ際によく出る質問をいくつか紹介します。
Q: 現時点ではテキストデータしかない場合でも、マルチモーダル埋め込みモデルを使うべきですか?
ロードマップ次第です。今後6〜12か月以内にパイプラインで画像、PDF、またはその他のモダリティを追加する可能性が高い場合、Gemini Embedding 2やVoyage Multimodal 3.5のようなマルチモーダルモデルから始めることで、後の痛みを伴う移行を避けられます。データセット全体を再埋め込みする必要がなくなります。予見可能な将来にわたってテキストのみだと確信している場合は、OpenAI 3-largeやCohere Embed v4のようなテキスト特化モデルの方が、価格性能比に優れています。
Q: MRL次元圧縮は、ベクトルデータベースで実際にどれくらいストレージを節約できますか?
3072次元から256次元にすると、ベクトルあたりのストレージは12倍削減されます。float32で1億ベクトルを持つMilvusコレクションの場合、およそ1.14 TB → 95 GBになります。重要なのは、すべてのモデルが切り詰めをうまく扱えるわけではないという点です。Voyage Multimodal 3.5とJina Embeddings v4は256次元で品質低下が1%未満ですが、他のモデルでは大幅に劣化します。
Q: Qwen3-VL-2Bは、クロスモーダル検索において本当にGemini Embedding 2より優れていますか?
私たちのベンチマークでは、はい。ほぼ同一の撹乱候補を含む難しいクロスモーダル検索において、Qwen3-VL-2Bは0.945を記録し、Geminiの0.928を上回りました。主な理由は、Qwenのモダリティギャップがはるかに小さい(0.25対0.73)ためで、これはテキストと画像の埋め込みがベクトル空間内でより近くにクラスタリングされることを意味します。とはいえ、Geminiは5つのモダリティをカバーする一方、Qwenは3つをカバーするため、音声またはPDFの埋め込みが必要な場合、Geminiが唯一の選択肢です。
Q: これらの埋め込みモデルをMilvusで直接使えますか?
はい。これらのモデルはいずれも標準的なfloatベクトルを出力し、それをMilvusに挿入して、コサイン類似度、L2距離、または内積で検索できます。PyMilvusは任意の埋め込みモデルで動作します。モデルのSDKでベクトルを生成し、それをMilvusに保存して検索してください。MRLで切り詰めたベクトルの場合は、コレクションの作成時にコレクションの次元をターゲット(例: 256)に設定するだけです。

読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.