




LangChainによるNotion Docsの検索拡張生成
この記事はThe Sequenceに掲載されたものを、許可を得てここに再掲載している。
言語モデルに検索を依頼したいNotionドキュメントがありますか?LangChainとMilvusを使って、基本的な検索拡張生成(RAG)タイプのアプリを作ってみよう。運用フレームワークにはLangChainを、類似性エンジンにはMilvusを使う。このブログのノートブックはcolabにあります。
このチュートリアルでは、以下を説明します:
LangChainセルフクエリの復習
LangChainでNotion Docsを使う
Notionドキュメントの取り込み
Notionドキュメントの保存
ノチオン・ドキュメントの照会
LangChainとMilvusによるNotionドキュメントのクエリのまとめ
LangChainセルフクエリのレビュー
LangChain](https://zilliz.com/partners/langchain)が "self-querying"(セルフクエリ)と呼んでいる機能の紹介として、How to use LangChain to query a vector databaseを最近取り上げました。舞台裏では、LangChainのセルフクエリ機能は以下のような基本的なRAGアーキテクチャを構築しています。
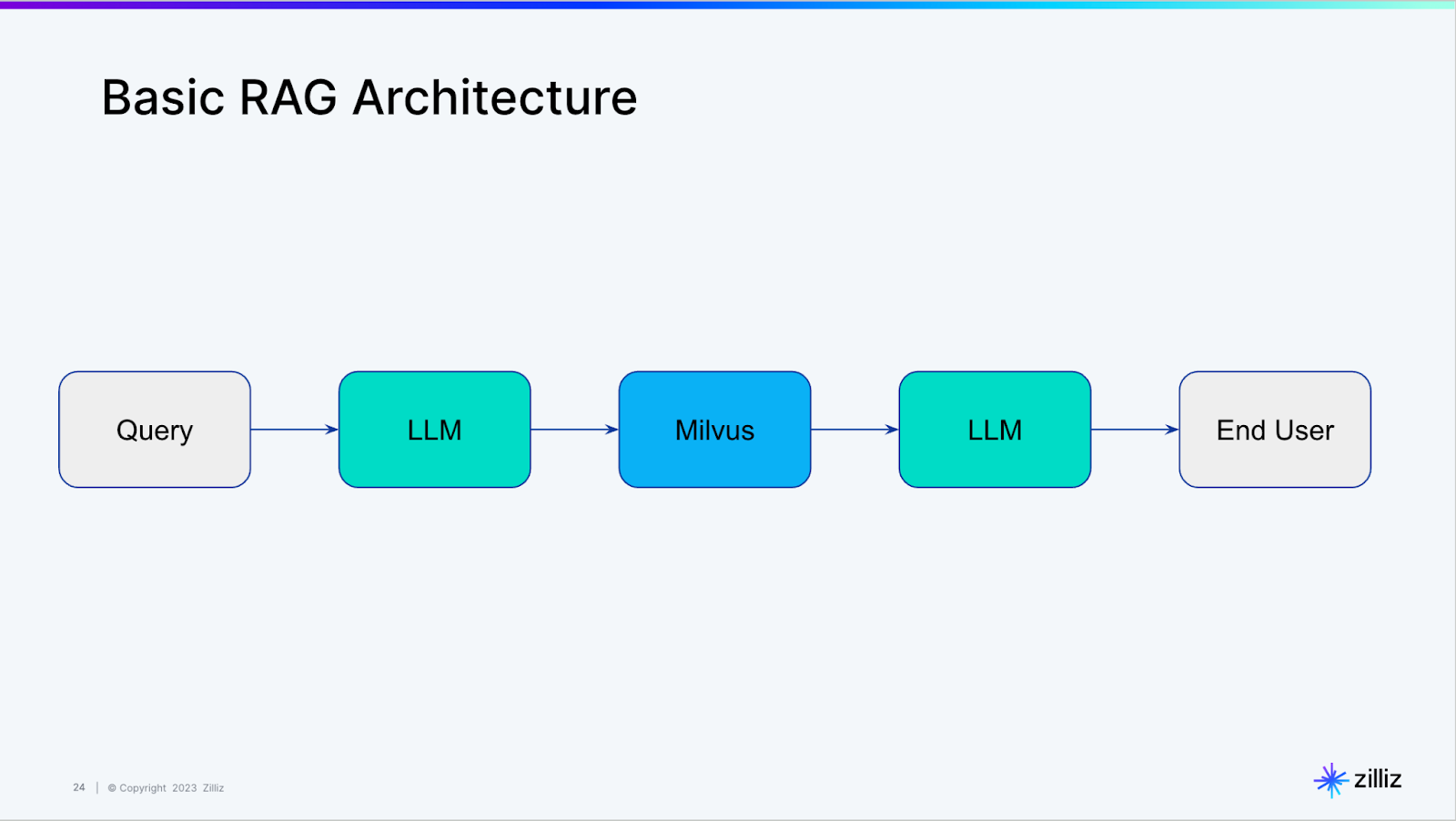
LangChainでNotionドキュメントを扱う
ここでは、インジェスト、保存、クエリの3つのステップに分けて説明します。取り込みでは、Notionドキュメントを取得し、内容をメモリにロードします。保存では、ベクトルデータベース(Milvus)を立ち上げ、ドキュメントをベクトル化し、ベクトルデータベースに格納します。
Notion文書の取り込み
LangChainの NotionDirectoryLoader を使って、ドキュメントをメモリにロードします。ドキュメントへのパスを指定し、load関数を呼び出してドキュメントを取得します。ドキュメントがメモリにロードされたら、マークダウン・ファイルを取得します。
次に、LangChainのマークダウン・ヘッダー・テキスト・スプリッターを使う。分割するヘッダのリストを渡し、md_fileという名前のヘッダを渡して分割します。headers_to_split_on`リストを定義するときは、私が提供した例だけでなく、Notionドキュメントで使用しているヘッダを使用してください。
# Notion ページを markdownfile ファイルとしてロードする。
from langchain.document_loaders import NotionDirectoryLoader
パス='./notion_docs'
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# ページのセクションヘッダに基づいてグループを作成しよう。
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers_to_split_on = [
("##", "Section")、
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_file)
以下のコードでは、分割の実行と検証を行っています。LangChainの RecursiveCharacterTextSplitter を使います。デフォルトでは、改行、二重改行、スペース、スペースなしの4つの文字がチェックされます。また、今回は使用しなかったが、separators パラメータで独自の文字を渡すこともできる。
Notion ドキュメントをチャンキングする際に定義すべき 2 つの重要なハイパーパラメータは、チャンクサ イズとチャンクのオーバーラップです。この例では、チャンクサ イズを 64、オーバーラップを 8 にしています。テキストスプリッタを定義したら、その split_documents 関数を呼び出して、すべてのドキュメントを分割します。
# テキストスプリッタを定義する
from langchain.text_splitter import RecursiveCharacterTextSplitter
チャンクサイズ = 64
chunk_overlap = 8
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
すべてのスプリット
下の図は、上記の分割で得られた Document オブジェクトを示している。このオブジェクトにはページのコンテンツと、そのコンテンツが取得されたセクションを含むメタデータが含まれていることに注目してください。
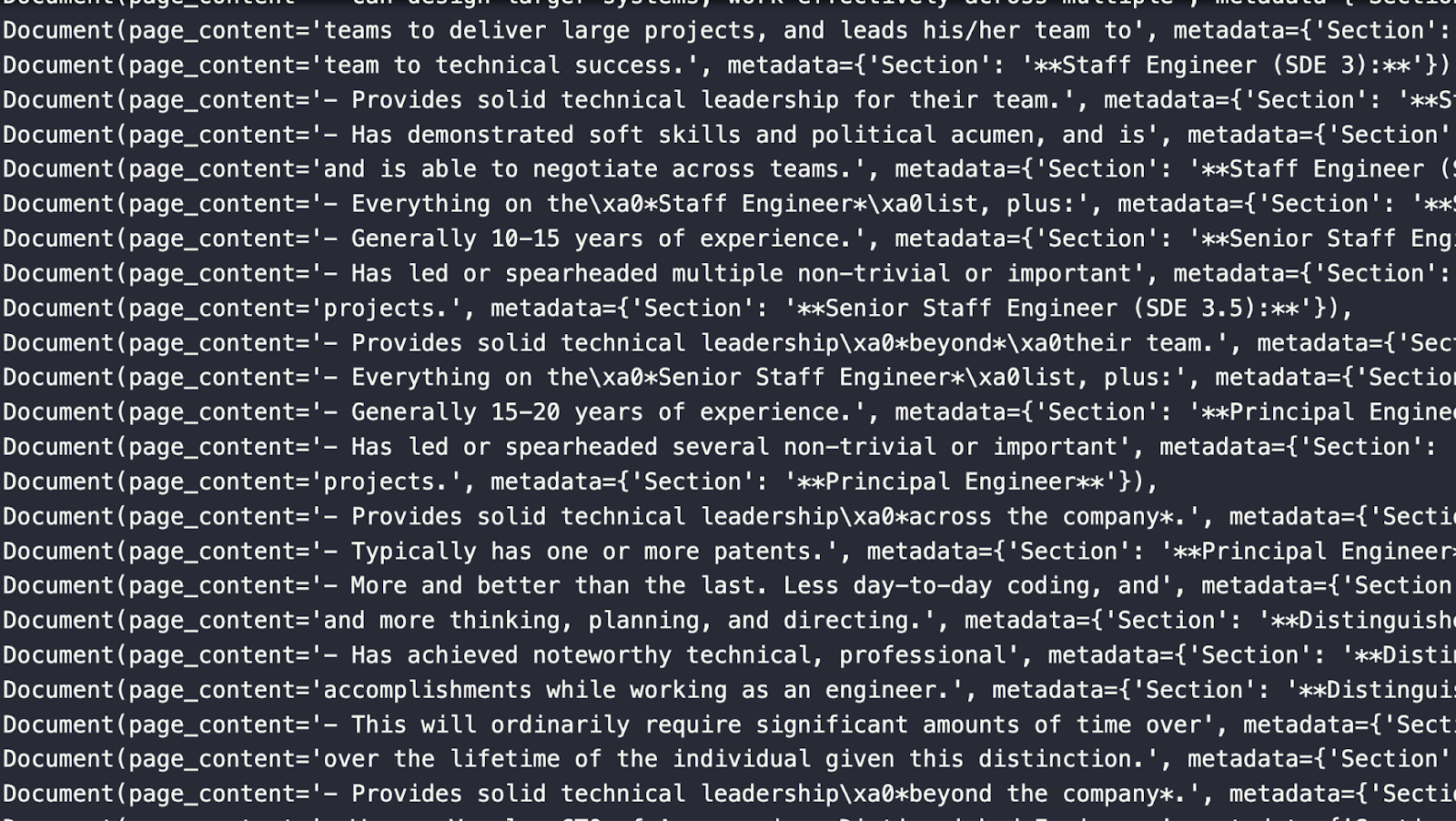
Notion文書の保存
すべてのドキュメントがロードされ、分割されたので、次は分割されたドキュメントを保存します。まず、Milvus Liteを使って、ノートブックで直接ベクターデータベースを立ち上げます。また、必要なLangChainモジュール Milvus と OpenAIEmbeddings を入手する必要があります。
インポートしてベクターデータベースを立ち上げた後、LangChainのMilvusモジュールを使ってドキュメントからコレクションを作成する。ドキュメントリスト、使用する埋め込み、接続パラメータ、そして(オプションで)コレクション名を渡す必要があります。
from milvus import default_server
default_server.start()
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
vectordb = Milvus.from_documents(documents=all_splits、
embedding=OpenAIEmbeddings()、
connection_args={"host":"127.0.0.1", "port": default_server.listen_port}、
コレクション名="EngineeringNotionDoc")
Notion ドキュメントのクエリ
すべてのセットアップが完了し、クエリの準備ができた。GPTにアクセスするためのOpenAI、基本的なRAGを作るためのSelfQueryRetriever、そしてメタデータを渡すための "Attribute info "オブジェクトだ。まず、メタデータを定義する。この例では、これまで使ってきたセクションだけを使う。
また、セルフクエリー・リトリーバーにドキュメントの説明を与える。この例では、単に「ドキュメントの主要なセクション」とします。セルフクエリーリトリーバーをインスタンス化する直前に、0℃バージョンのGPTをllm変数にセットする。LLM、ベクターデータベース、文書の説明、メタデータフィールドの準備ができたので、セルフクエリーリトリーバーを定義する。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_fields_info = [
属性情報(
name="Section"、
type="文字列またはリスト[文字列]"、
type="文字列またはリスト[文字列]"
),
]
document_content_description = "文書の主なセクション"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
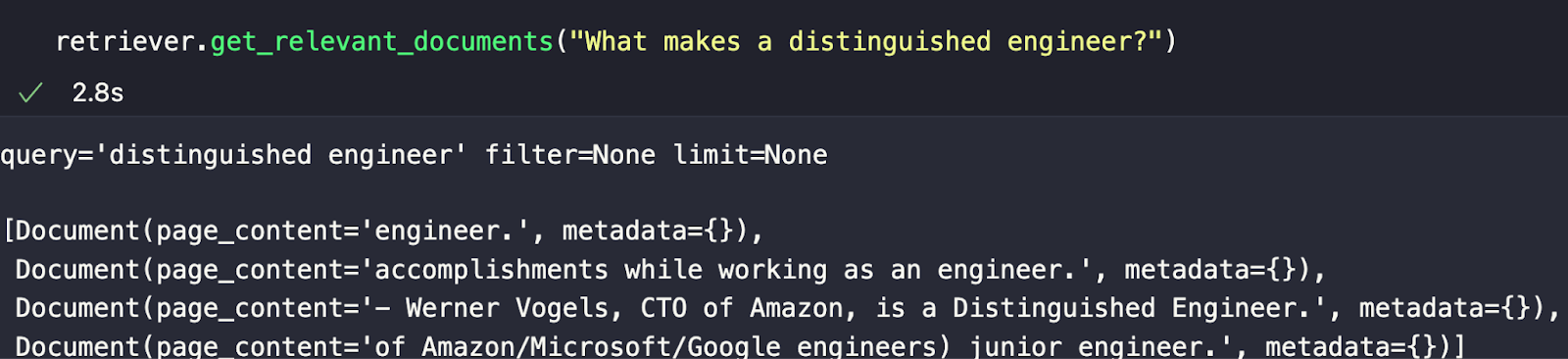
retriever.get_relevant_documents("What makes a distinguished engineer?")
私が選んだ例は、"What makes a distinguished engineer?" です。下の画像のレスポンスから、最も意味的に類似したチャンクが返されたことがわかります。見てわかるように、最も意味的に似ている回答だからといって、それが正しい回答であるとは限りません。今後、チャンキングやその他のテクニックを使って、回答を改善する方法について説明します。
LangChainにおけるNotionドキュメントのクエリまとめ
このチュートリアルでは、基本的なRAGアーキテクチャでNotionドキュメントをクエリするためのセクションにロードし、パースする方法を説明しました。オーケストレーション・フレームワークとしてLangChainを、ベクター・データベースとしてMilvusを使いました。LangChainが断片をまとめ、Milvusが類似検索を行います。
このチュートリアルをさらに進めるために、テストできることはたくさんあります。チェックすべき2つのハイパーパラメータの例はチャンクサイズとチャンク間のオーバーラップサイズです。これらを使って、応答をチューニングし、それがどのように見えるかを調べることができます。チューニングとは別に、応答を評価する必要もあります。
今後のチュートリアルでは、さまざまなチャンキング戦略を見ていきます。それだけでなく、埋め込み、分割戦略、評価についても深く見ていきます。
 Yujian Tang
Yujian TangYujian Tang is a Developer Advocate at Zilliz. He has a background as a software engineer working on AutoML at Amazon. Yujian studied Computer Science, Statistics, and Neuroscience with research papers published to conferences including IEEE Big Data. He enjoys drinking bubble tea, spending time with family, and being near water.
読み続けて

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.