




ベクターデータベースを評価するには?
この記事はInfoWorldに掲載されたもので、許可を得てここに再掲載している。
今日のデータ主導の世界では、非構造化データの急激な増大は、我々の注意を必要とする現象である。AIと大規模言語モデル(LLM)の台頭は、このデータ爆発に再び火をつけ、私たちの関心を画期的なテクノロジーであるベクトル・データベースに向けている。AI時代の重要なインフラとして、ベクトル・データベースは非構造化データの保存、インデックス付け、検索のための強力なツールである。
ベクターデータベースに世界中の注目が集まる中、喫緊の課題が浮上している:ビジネスのニーズに合ったものを選ぶにはどうすればいいのか?ベクターデータベースを比較・評価する際に考慮すべき重要な要素とは何でしょうか?この記事では、このような疑問について掘り下げ、スケーラビリティ、機能性、パフォーマンスの観点から洞察を提供し、このダイナミックな状況において十分な情報に基づいた意思決定を支援します。
ベクターデータベースとは?
従来のリレーショナルデータベースシステムは、あらかじめ定義されたフォーマットで構造化されたテーブルでデータを管理し、正確な検索操作を実行することに優れています。対照的に、ベクトルデータベースは、ベクトル埋め込みとして知られる高次元の数値表現を通して、画像、音声、動画、テキストなどの非構造化データを保存し、検索することに特化しています。
ベクトルデータベースは、近似最近傍(ANN)アルゴリズムのような技術を採用した類似検索で有名である。このアルゴリズムは空間的な関係に従ってデータを配置し、広範なデータセットの中から与えられたクエリに最も近いデータ点を素早く特定する。
開発者は、レコメンダーシステム、チャットボット、類似の画像、動画、音声を検索するアプリケーションを構築する際にベクターデータベースを使用する。ChatGPT](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code)の台頭により、ベクターデータベースは大規模言語モデルの幻覚問題への対処に有益なものとなっている。
ベクトルデータベースと他のベクトル検索技術との比較
ベクトル検索には、ベクトルデータベース以外にも様々な技術がある。2017年、MetaはFAISSをオープンソース化し、ベクトル検索に関連するコストと障壁を大幅に削減した。2019年には、Zilliz社が、業界をリードする専用オープンソースのベクターデータベースであるMilvusを発表した。それ以来、他にも多くのベクターデータベースの企業が登場している。2022年には、ElasticsearchやRedisといった従来の検索製品が多数参入し、ChatGPTのようなLLMが普及したことで、ベクトルデータベースの流れは一気に加速した。

これだけ多くのベクトル検索製品が存在する今、それぞれの違いはどこにあるのでしょうか?大まかに分類すると以下のようになる:
挿入、削除、更新、クエリ、データの永続性、スケーラビリティといった基本的なデータベース機能を持たないアルゴリズムのコレクションである。FAISSが主な例だ。
軽量ベクトルデータベース. ベクトル検索ライブラリをベースに構築されているため、導入は軽量だが、スケーラビリティやパフォーマンスは劣る。Chromaはその一例である。
ベクター検索プラグイン.** 伝統的なデータベースに依存するベクター検索アドオンである。しかし、そのアーキテクチャは従来のワークロード用であるため、パフォーマンスやスケーラビリティに悪影響を及ぼす可能性がある。ElasticsearchとPgvectorが主な例である。
ベクトル検索専用のデータベースは、他のベクトル検索技術よりも大きな利点を提供する。例えば、専用のベクトルデータベースは、分散コンピューティングやストレージ、ディザスタリカバリ、データの永続性など、よりユーザーフレンドリーな機能を提供します。Milvusが主な例である。
ベクターデータベースを評価するには?
ベクターデータベースを評価する場合、スケーラビリティ、機能性、パフォーマンスが最も重要な3つの指標です。
スケーラビリティ
スケーラビリティは、ベクトルデータベースが指数関数的に増大するデータを効率的に処理できるかどうかを判断するために不可欠です。スケーラビリティを評価する際には、水平/垂直方向のスケーラビリティ、負荷分散、複数レプリケーションを考慮する必要があります。
水平/垂直スケーラビリティ
さまざまなベクターデータベースは、ビジネスの成長需要に対応するために、多様なスケーリ ング技術を採用しています。例えば、PineconeやQdrantは垂直スケーリングを採用し、Milvusは水平スケーリングを採用しています。水平スケーラビリティは、垂直スケーリングよりも柔軟性とパフォーマンスが高く、上限も少ない。
ロードバランシング
スケジューリングは分散システムにとって極めて重要である。その速度、粒度、精度は負荷管理とシステム性能に直接影響し、正しく最適化されなければスケーラビリティを低下させる。
複数レプリカのサポート
複数のレプリカは、様々なクエリに対する差分応答を可能にし、システムのクエリパーセカンド(QPS)と全体的なスケーラビリティを向上させます。
ベクターデータベースによってユーザーのタイプが異なるため、スケーラビリティ戦略も異なります。例えばMilvusは、データ量が急増するシナリオに特化し、ストレージとコンピュートを分離した水平スケーラブルなアーキテクチャを採用している。一方、PineconeとQdrantは、データ量とスケーリング要求が中程度のユーザー向けに設計されています。一方、LanceDBとChromaは、スケーラビリティよりも軽量なデプロイを優先している。
機能
ベクトル・データベースの機能を、データベース指向の機能とベクトル指向の機能の2つに大別する。
ベクター指向の機能
ベクトルデータベースは、検索拡張生成(RAG)、レコメンダーシステム、様々なインデックスを用いた意味的類似性検索など、多くのユースケースに恩恵をもたらす。したがって、複数のインデックスタイプをサポートする能力は、ベクトルデータベースを評価する上で重要な要素である。
現在、ほとんどのベクトルデータベースはHNSW(Hierarchical Navigable Small World)インデックスをサポートしており、IVF(Inverted File)インデックスにも対応しているものもある。これらのインデックスはインメモリ操作に適しており、リソースが豊富な環境に最適です。しかし、ベクターデータベースの中には、ハードウェアリソースが限られている場合にmmapベースのソリューションを選択するものもあります。mmapベースのソリューションは実装が容易な反面、パフォーマンスが犠牲になります。
最も長い歴史を持つベクトルデータベースの一つであるMilvusは、ディスクベースとGPUベースのインデックスを含む11種類のインデックスをサポートしている。このアプローチは、幅広いアプリケーションシナリオへの適応性を保証する。
データベース指向の機能
チェンジデータキャプチャ(CDC)、マルチテナンシーサポート、リソースグループ、ロールベースアクセスコントロール(RBAC)など、従来のデータベースに有益な多くの機能がベクターデータベースにも適用されます。Milvusとベクタープラグインを搭載したいくつかの従来型データベースは、これらのデータベース指向の機能を効果的にサポートしています。
パフォーマンス
パフォーマンスは、ベクターデータベースを評価する上で最も重要な指標です。従来のデータベースとは異なり、ベクターデータベースは近似検索を行うため、検索された上位k件の結果が100%の精度を保証することはできません。したがって、Query Per Second (QPS)やLatencyのような伝統的な指標に加えて、検索精度を定量化する「想起率」もベクトルデータベースにとって不可欠なパフォーマンス指標です。
異なる評価指標を評価するために、よく知られたオープンソースのベンチマークツールを2つお勧めします:ANN-BenchmarkとVectorDBBenchです。
ANN-Benchmark
ベクターインデキシングは、ベクターデータベースの重要かつリソース集約的な側面です。その性能はデータベース全体の性能に直接影響します。ANN-Benchmarkは、様々な実データセットの多様なベクトルインデックスアルゴリズムのパフォーマンスを評価するための主要なベンチマークツールです。
以下のグラフは、GIST1Mデータセット(960次元の1Mベクトル)に基づき、様々なアルゴリズムのリコール/クエリー/秒をテストした結果を示しています。y軸のQPSに対してx軸のリコール率をプロットし、検索精度の異なるレベルでの各アルゴリズムのパフォーマンスを示しています。
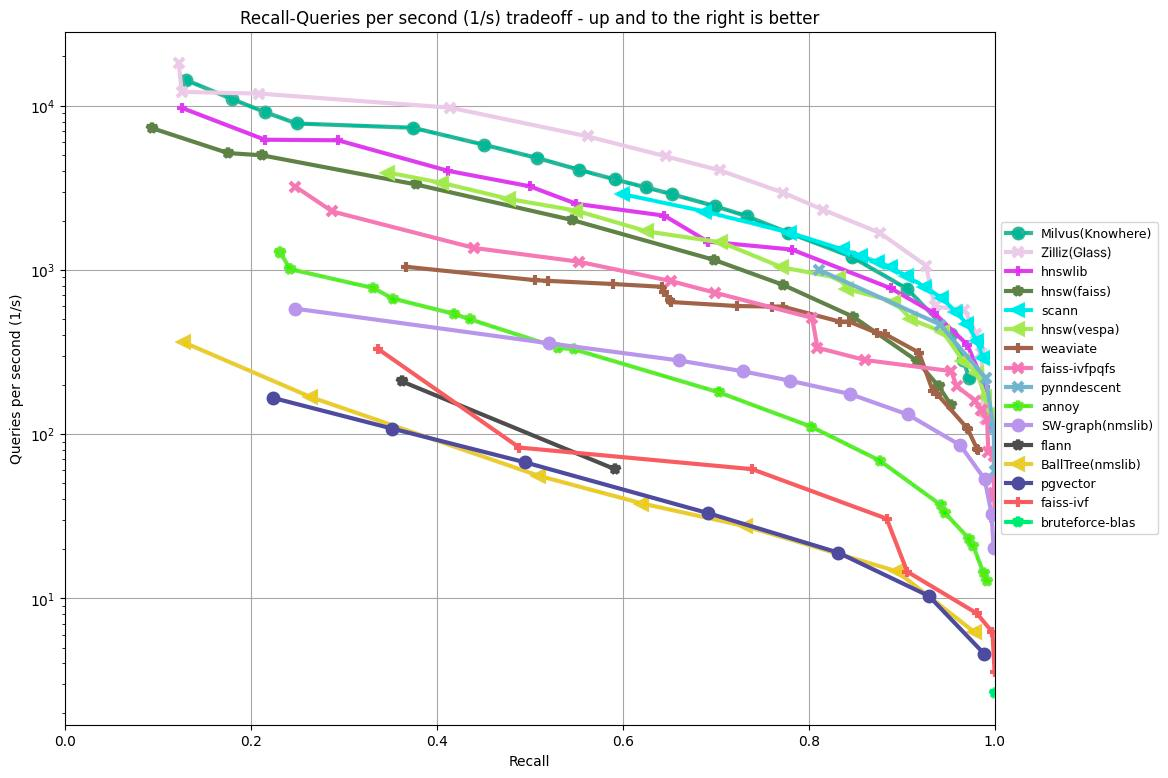
上のグラフに示された結果によると、960次元の1,000,000ベクトルを処理した場合、Milvus、Zilliz、HNSWライブラリがベスト3の結果を達成した。その他のベンチマーク結果については、ANN-Benchmarkのウェブサイトを参照。
ベクターDBBベンチ
ANN-Benchmarkは様々なベクトル検索アルゴリズムを選択・比較するのに非常に便利ですが、ベクトルデータベースの包括的な概要を提供するものではありません。リソース消費、データロード容量、システムの安定性といった要素も考慮しなければならない。さらに、ANN-Benchmarkはフィルタリングされたベクトル検索など、多くの一般的なシナリオを見逃している。
VectorDBBenchは、上記の制限に対処できるオープンソースのベンチマークツールで、MilvusやWeaviateのようなオープンソースのベクトルデータベースや、Zilliz CloudやPineconeのようなフルマネージドサービス向けに設計されています。多くのフルマネージドベクトル検索サービスはユーザーチューニングのためにパラメータを公開していないため、VectorDBBenchはQPSと再現率を別々に表示します。
以下のグラフは、1,536次元の50万ベクトルと768次元の100万ベクトルを処理した場合の、QPSと様々な主流のベクトルデータベースの再現率のテスト結果を示しています。
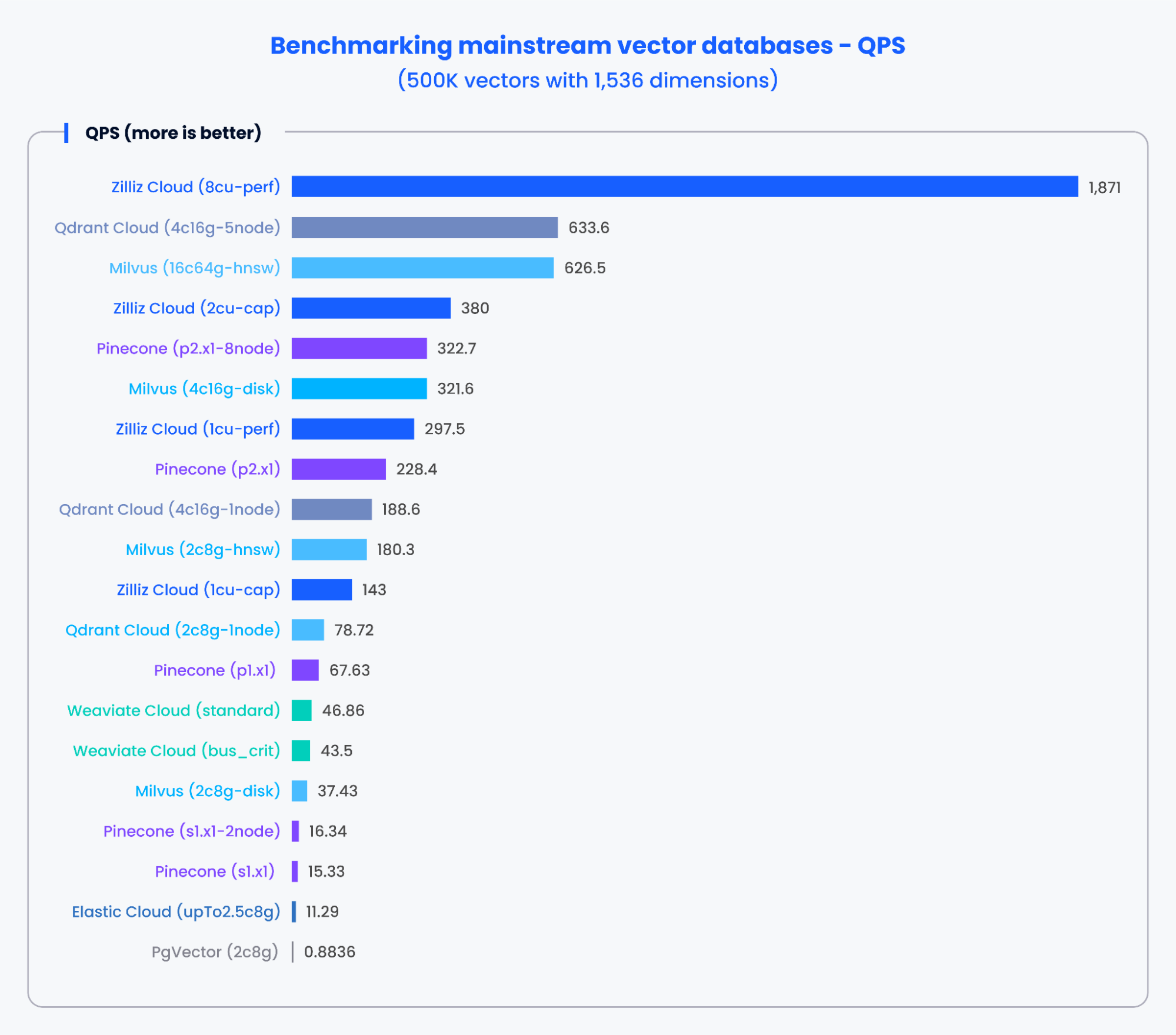
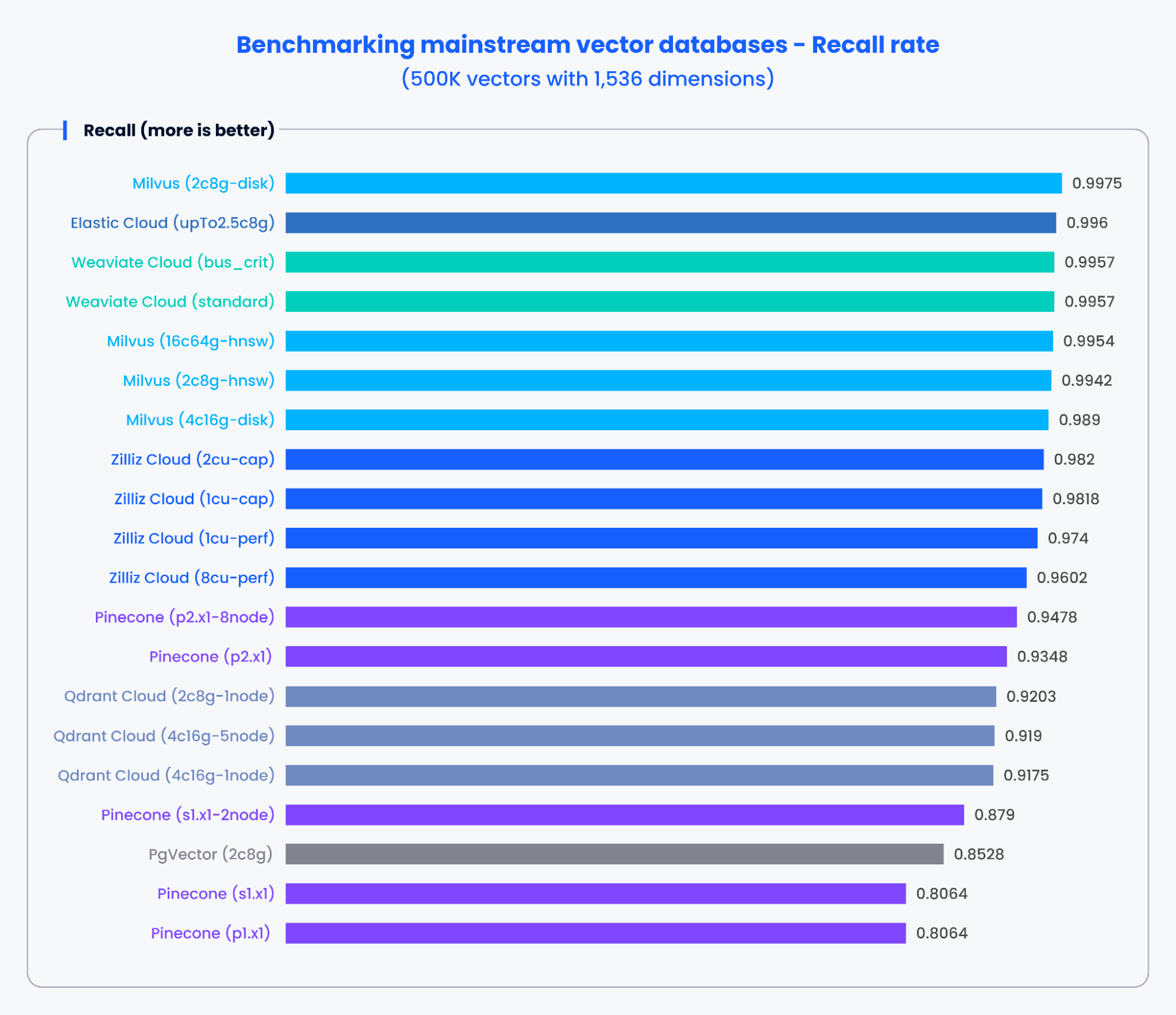
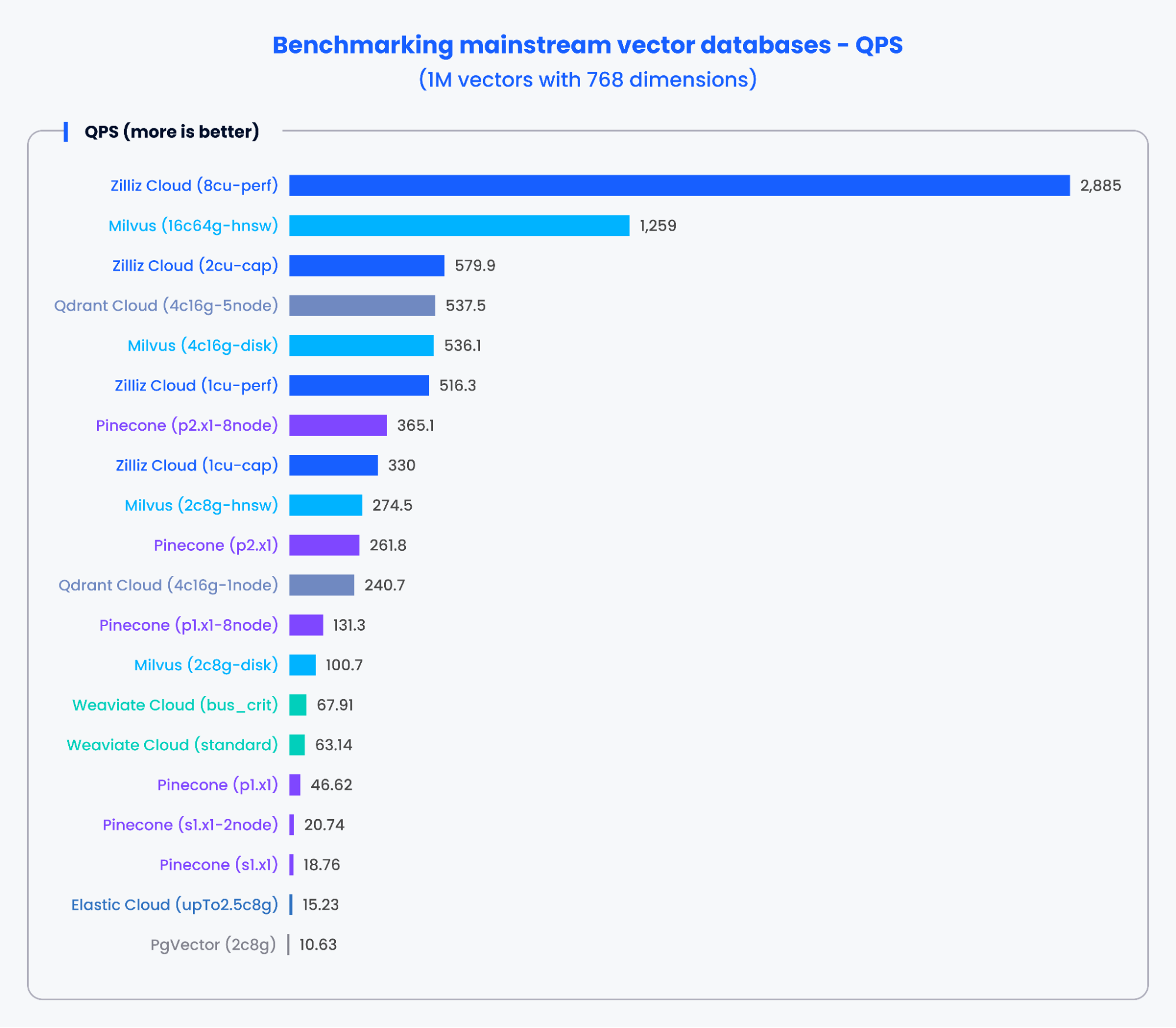
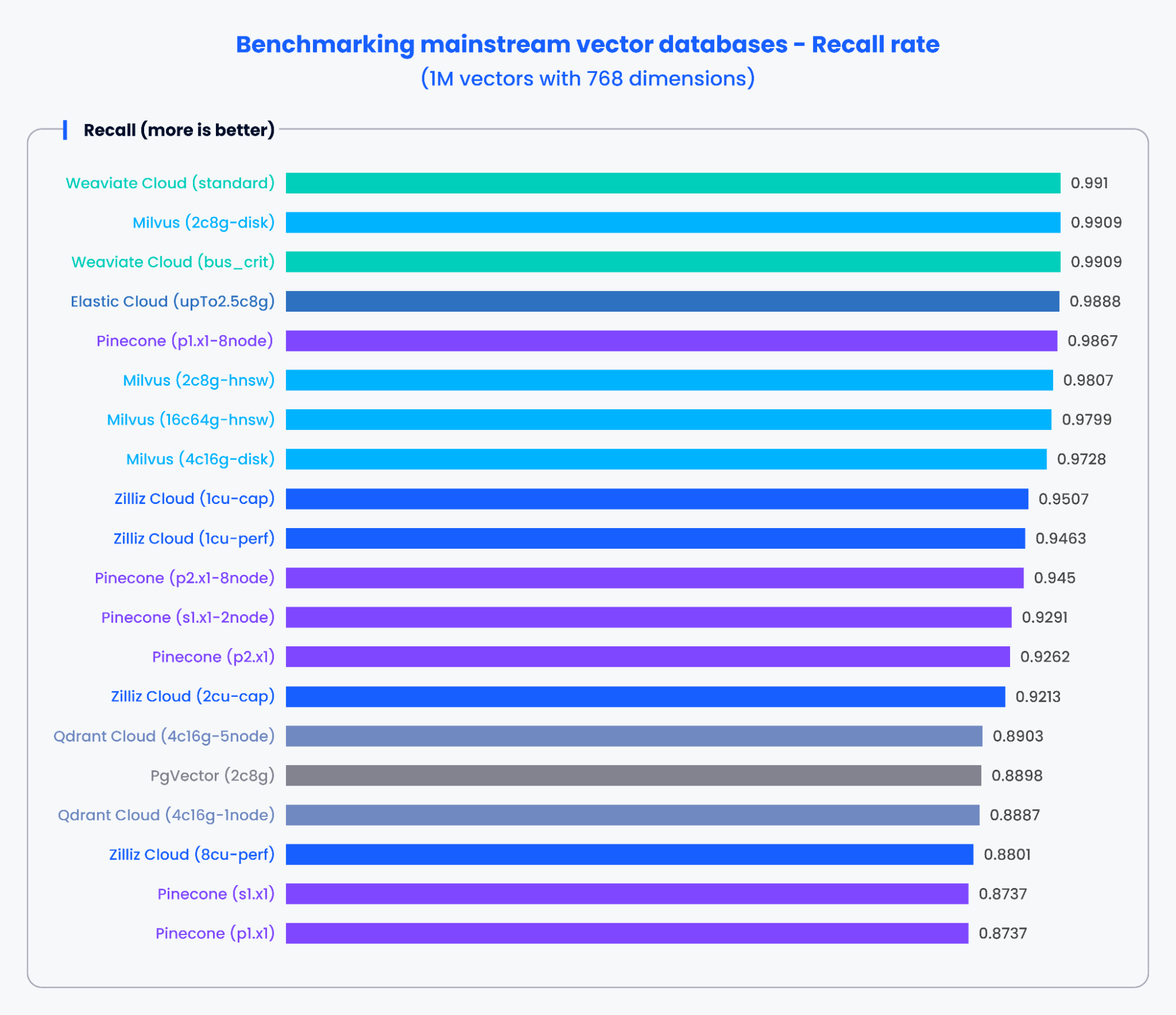
上記のグラフの結果から、MilvusやZillizのような専用に構築されたベクトルデータベースは、QPSと想起率の両方で卓越した性能を示した。これらの結果は、専用に構築されたベクトル・データベースが膨大な量のデータを迅速に処理し、より正確な結果を取り出すことができることを示している。対照的に、従来のデータベースをベースとしたベクトル検索アドオンは、より低いパフォーマンスを示した。
その他のベンチマーク結果については、VectorDBBench websiteを参照。
結論
ベクターデータベースのダイナミックな領域では、多くの製品が独自の強調点と強みを示しています。普遍的な "ベスト "ベクターデータベースはありません。したがって、ベクターデータベースのスケーラビリティ、機能性、パフォーマンス、および特定のユースケースとの互換性を評価することが重要です。

読み続けて

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.