




適切なフィットを見つける:OSS、VoyageAI、OpenAIのZillizクラウドパイプラインにAI検索のための創造(RAG)を組み込む
*この記事はクリスティ・バーグマンとジアン・チェンによって書かれました。
AI Retrieval Augmented Generation (RAG)アプリケーションに合わせた埋め込みモデルに関するブログ記事へようこそ。以下がその内容です:
RAG(検索機能付きAI)における埋め込みモデルの使われ方の紹介
最も一般的な埋め込みモデルであるSBERTの紹介
MTEB](https://zilliz.com/glossary/massive-text-embedding-benchmark-(mteb))エンベッディングモデルのリーダーボードとその使い方
Zilliz Cloud Pipelinesに自動的に含まれる6つのエンベッディングモデル
各モデルの解説と最適なエンベッディングモデル選択のヒント
それでは、さっそく見ていきましょう!
あなたのデータをRagでAIに:エンベッディングモデルとLLMの使用方法
検索拡張世代(RAG)は、質問応答ボットのための主要なアプローチとして浮上してきた。しかし、すべてのモデルに内在する知識トレーニングの締め切り日を考えると、最近のデータに対する認識が欠けている可能性がある。ほとんどのプロダクションユースケースでは、このギャップを埋めるために特定の知識でモデルを補足しています。
**あなたのAIの回答は過去にとらわれていませんか?
RAGは、あなたのデータをAIの知識に統合することで解決策を提示します。このパターンでは、埋め込みモデルと大規模言語モデル(LLM)を使用します。その仕組みは以下の通りです:
1.エンベッディング・モデルを使用したデータの準備:埋め込みモデルを使用して、すべてのドキュメントからテキストの塊のベクトル埋め込みを生成することで、RAGを開始します。これは、あなたのドメイン知識_を表すベクトル空間となり、各情報はベクトルとして表されます。
2.同じ埋め込みモデルを使ったインデックス作成と検索:知識がベクトルにエンコードされれば、コンピュータはベクトル検索を素早く実行できる。検索アルゴリズムのためにベクトルをデータ構造に整理することをインデクシングと呼ぶ。インデックスはMilvusのようなベクトル・データベースで使われる。あなたが質問をすると、データベースはインデックスを使用して、ドメイン知識ベクトル空間内であなたの質問ベクトルに最も近いベクトル(文または段落を表す)を見つけます。データを埋め込むために使用されるのと同じ埋め込みモデルを使用して、質問ベクトルを作成します。
3.LLMモデルによる回答生成:これは「生成AI」の部分です。このステップでは、ChatGPTのようなLLMモデルが、質問に答えるためにあなたの関連するドメイン知識を活用します。RAGデータは、あなたの質問、コンテキスト(Top-Kテキスト)、および「このプロンプトのコンテキスト内の知識のみを使用して質問に答える」などの指示を含むプロンプトにトップK検索テキストを注入することにより、LLMモデルに供給されます。
**RAGにより、LLMは与えられたドメイン知識に基づいて回答を生成し、瞬時に最新のデータにアクセスし、あなたの質問をよりよく理解します。
このRAGパターンは研究によってサポートされています。論文 Lost in the Middle を参照してください。この論文では、LLMによって生成された回答のRecall精度は、モデルのContextプロンプトに詰め込まれた検索テキストの数とともに低下することを示している。さらに
LLMはコンテキストのサイズに制限がある(現在、GPT-4ターボでは128K)。
トークンごとにコストがかかるため、すべての情報を常に渡すとコストが高くなる。
センテンス-BERT埋め込みモデル
最近の埋め込みモデルは、Encoder-part of transformers から派生しています。一方、LLMモデル(ChatGPTなど)は、Decoder-part of transformersから構築されています。最も一般的な埋め込みモデルクラスは、SBERT (Sentence-BERT)で、BERTをベースにしていますが、完全な文を理解することに特化しています。つまり、SBERTは、"The cat sat on the mat "と "The mat sat on the cat "の違いを見分けることができます!
意味論は、言葉の背後にある意味を指す。同じ単語が文脈、順序、または用法に基づいて異なる意味を持つことがあるため、これは LLM の文脈では特に重要である。SBERTの詳細については、興味のある読者は、そのモデルに関するこれらの優れた背景説明記事こちらを参照されたい。
ゼロからRAGアプリケーションをコーディングするとする。RAG に最も関連しているため、"Retrieval Average"(検索平均)カラムでソート(降順)された** HuggingFace MTEB Leaderboard** から埋め込みモデルを選択することから始めるのがよいでしょう。そして、最小で最高順位の埋め込みモデルを選択します。リーダーボードは常に変化している!しかし、PythonのHuggingFaceを使った埋め込みモデルの切り替えは、1つの変数を調整するのと同じくらい簡単です。
MTEBの検索性能は、Normalized Discounted Cumulative Gain at 10 (NDCG@10)によって測定されます。このメトリックは、理想的なランク付けされた順序に比例してユーザーに返されるように、より高いランク付けされたアイテムがより低いランク付けされたアイテムよりも重み付けされる比率の合計を計算することによって、トップKリストの品質を測定します。
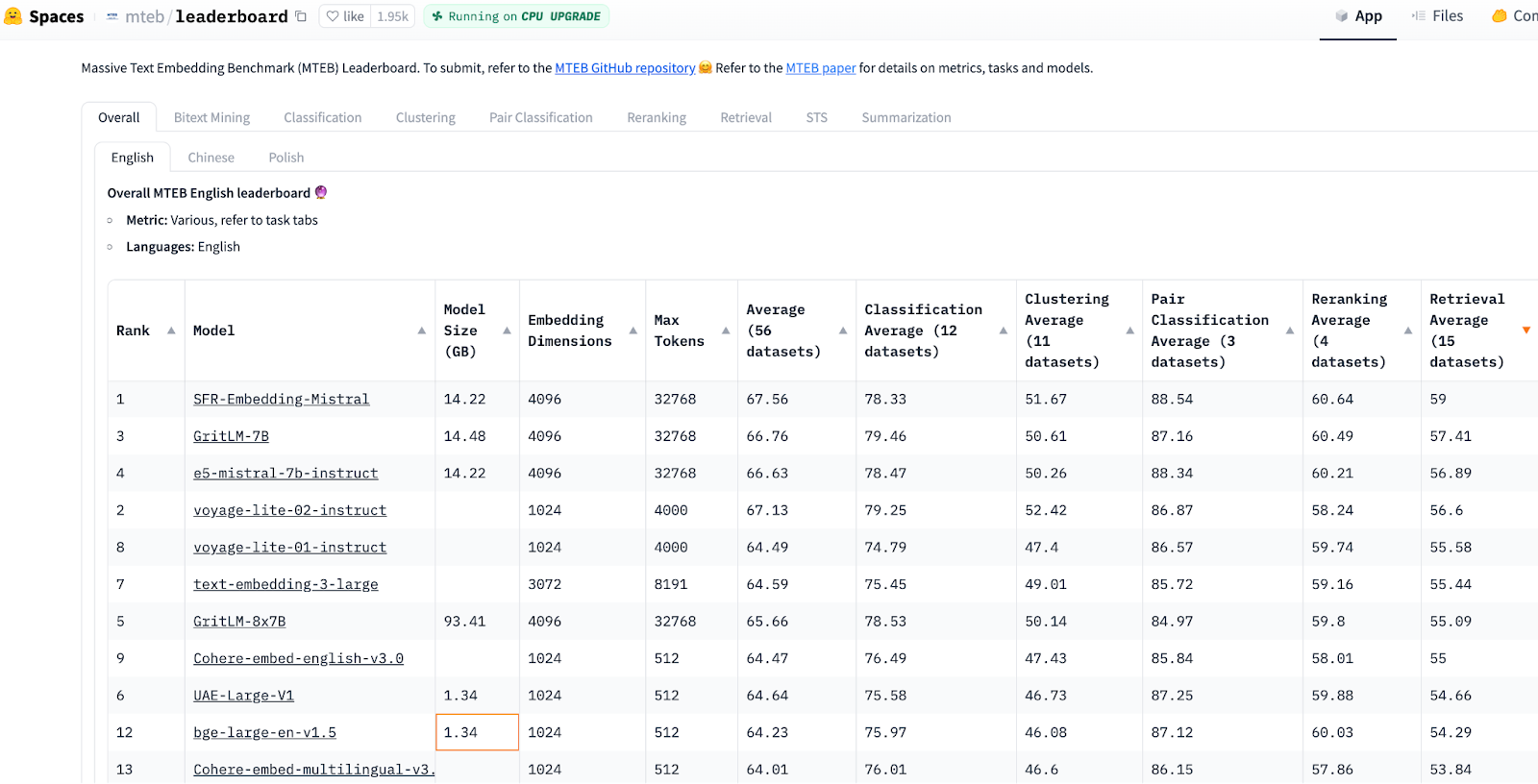
画像ソースHuggingFace MTEB Leaderboard, accessed Feb 20, 2024.
Massive Text Embedding Benchmark (MTEB)は、8つのタスクと58のデータセット(10の多言語112言語)で埋め込みモデルを評価します。8つのタスクとは、バイトテキスト・マイニング、分類、クラスタリング、ペア分類、リランキング、検索、意味的テキスト類似度(STS)、要約です。
Zillizクラウドパイプラインに組み込まれた6つの主要な埋め込みモデル
Zilliz Cloud Pipelinesは最近、埋め込みモデルの豊富な選択肢のサポートを開始した。
| ----------- | ------------------------ | -------------------- | ------------------ | ------------------------------------ | --------------- | ----------------- | | 作成者** | モデル | 埋め込み ディム | コンテキスト長 | ユースケースタスク | オープンソース | *MTEBスコア |
| BAAI|bge-base-zh-v1.5|768|512|一般的なZHテキスト|はい|69||BAAI
| VoyageAI | voyage-2 | 1024 | 4K | 高品質なRAGチャットボット|いいえ|利用不可
| OpenAI | text-embedding-3-small | 512-1536 | 8K | リアルタイム多言語テキストチャットボット|なし|62(512) 62(1536) ||あり
| OpenAI | text-embedding-3-large | 256-3072 | 8K | リアルタイム多言語テキストチャットボット|なし|65 (3072) 62 (256)
*HuggingFace MTEB Leaderboard、検索順、2024年2月26日アクセス。
**より大きなベクトルはより多くの意味を捉えるかもしれないが、ストレージ効率は悪くなるかもしれない。
コンテキストの長さ = モデルが1回の時間ステップで一度に処理できるトークンの最大数。ほとんどの埋め込みモデルの出力ベクトルは正規化されているので、ドット積とコサイン類似度は等しい。
⚠️ 注意:MTEBベンチマークが貴重なガイダンスを提供するとしても、いくつかのモデルはオーバーフィットすることが知られています! 常に独自の評価を行ってください!
Zilliz Cloud](https://cloud.zilliz.com/signup) **Pipelinesを使えば、DevOpsやMLインフラストラクチャに煩わされることなく、サインアップしてRAGアプリケーションを構築することで、無料で始めることができます。

画像ソースZilliz Cloud Pipelinesにモデルを組み込むことを発表したブログ
BAAI/bge-base-ja(or zh)-v1.5 エンベッディングモデル
これらのオープンソースSBERTモデルは、HuggingFaceで入手可能です。これらの小さなモデルにはいくつかの利点があります:
小さく、オープンソースで、CPUに優しい。
ラップトップまたは/または小さなクラウドリソースで作業するには良い選択だ。
質問されるたびにデータをチャンキングし、クエリのレイテンシを調整しながら、インジェストを最も高速に行うことができる。
APIコールは無料であり、GPUは必要ないため、費用対効果が高い。
中国語と英語の両方でトレーニング済み。
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | *MTEB Score |
| BAAI|bge-base-zh-v1.5|768|512|一般的なZHテキスト|はい|69||。
*HuggingFace MTEB Leaderboard、検索順、2024年2月26日アクセス。
VoyageAIのvoyage-2およびvoyage-code-2エンベッディングモデル
これらの独自モデルは、異なるデータに対して対比学習と重要度再サンプリングを用いて学習され、タスクごとに微調整されています。Voyage-2は対話データで学習され、会話の意図に合わせて微調整される。Voyage-code-2はコードデータで学習され、コード補完のために微調整される。
注:MTEBのリーダーボードに掲載されているVoyage-lite-02-instruct(STSまたは「多様なコーパス」カテゴリで降順にソート)は、ここで説明するプロダクションモデルvoyage-2およびvoyage-code-2とは異なるものであり、混同しないでください。
これらのモデルにはいくつかの利点がある:
技術文書のRAGチャットボットでは、voyage-01(非推奨)がより高い検索品質(NDCG@10として測定)を持つことが示された。Voyage-2は新しいバージョンです。
コードタスクでは、voyage-code-2はコード集約的なテキストに対して14%高い想起率を示している。
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | MTEBスコア |
VoyageAI|voyage-2|1024|4K| 高品質RAGチャットボット|なし|利用不可 |
OpenAIのtext-embedding-3-small(またはlarge)エンベッディングモデル
OpenAIの最新のエンベッディング・モデルは、以前のada-002よりもMTEBリーダーボードで上位にランクされています。これらの新しいエンベッディングモデルは、多言語性能(MIRACL)と低価格も向上しています。
【OpenAIのブログ】(https://openai.com/blog/new-embedding-models-and-api-updates)によると、エンベッディングの作成には、圧縮を考慮した学習が用いられた。*量子化のような従来の次元削減技術は、エンベッディングの学習後に「その場限り」で圧縮が適用されるため、スペースは節約できるが、精度は大きく損なわれる。Matryoshka Representation Learning](https://arxiv.org/pdf/2205.13147v4.pdf)のような圧縮を考慮した学習では、PCAほどではないが、多少の精度の低下はあるものの、異なるサイズ(次元)で埋め込みを学習する。
印象的なことに、どちらのモデルも、検索品質をそれほど犠牲にすることなく、より小さな埋め込みをサポートします。例えば、ベクトル次元を3072から256に小さくしても、MTEBスコアは65%から62%に低下するだけです。しかし、これは必要なメモリ量を12倍減らすことになる! 低次元化に伴う精度とコストのトレードオフはありますが、AIを搭載したチャットボットの時代には、回答の正確さよりも迅速な応答が優先されることがあります。
これらのモデルの利点
多言語機能の向上。
推論のオーバーヘッドが最も小さく、従来の2値化や積量子化よりも精度の低下がはるかに少ない低次元ベクトル。
| ----------- | ------------------------ | -------------------- | ------------------ | ------------------------------------ | --------------- | ----------------- |
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | *MTEB Score |
| OpenAI|text-embedding-3-small|512-1536|8K| リアルタイム多言語テキストチャットボット|無し|62 (512) 62 (1536)
| OpenAI|text-embedding-3-large|256-3072|8K|リアルタイム多言語テキストチャットボット|無し|65 (3072) 62 (256)
*HuggingFace MTEB Leaderboard、検索順、2024年2月26日アクセス。
以下は、新しい埋め込みモデルを呼び出すコード例です。 完全なコードはbootcamp githubにあります。
# ステップ1.
# pip install pymilvus
from pymilvus import connections, utility
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("ZILLIZ_API_KEY")
# エンドポイントURIとAPIキーを使ってZillizクラウドに接続する TOKEN.
cluster_endpoint="https://in03-xxxx.api.gcp-us-west1.zillizcloud.com:443"
connections.connect(
alias='default'、
uri=CLUSTER_ENDPOINT、
token=TOKEN、
)
次に、OpenAIのエンベッディングモデルを指定します。
# ステップ2.
import openai, pprint
from openai import OpenAI
# OpenAIの埋め込みモデル名、 `text-embedding-3-large` または `ext-embedding-3-small`.
EMBEDDING_MODEL = "テキストエンベッディング-3-small"
エンベッディングディム = 512
次に、スキーマなしのMilvusコレクションを作成し、インデックスを指定する。
# ステップ3. スキーマなしのMilvusコレクションを作成し、autoindexを使用する。
from pymilvus import MilvusClient
COLLECTION_NAME = "MilvusDocs_text_embedding_3_small"
# https://milvus.io/docs/using_milvusclient.md
mc = MilvusClient(
uri=CLUSTER_ENDPOINT、
token=TOKEN)
# コレクションが既に存在するかチェックし、存在する場合は削除します。
has = utility.has_collection(COLLECTION_NAME)
if has:
drop_result = utility.drop_collection(COLLECTION_NAME)
print(f "Successfully dropped collection: `{COLLECTION_NAME}`")
# コレクションを作成します。
mc.create_collection(COLLECTION_NAME、
EMBEDDING_DIM、
consistency_level="Eventually"、
auto_id=True、
上書き=True)
次に、LangChain技術ドキュメントをフォルダにダウンロードされた.htmlファイルとして読み込みます。 ドキュメントをチャンクして埋め込みます。 下の例ではLangChainの組み込みHTMLパーサーをチャンキング戦略として使っています。 あなたのチャンキング戦略はもっとシンプルかもしれません。
# ステップ4.チャンクと埋め込み
# ドキュメントをLangChainに読み込む。
from langchain.document_loaders import DirectoryLoader
path = "../RAG/rtdocs/pymilvus.readthedocs.io/ja/latest/"
loader = DirectoryLoader(path, glob='*.html')
docs = loader.load()
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter
from bs4 import BeautifulSoup
# HTMLHeaderTextSplitterで分割するヘッダを定義します。
headers_to_split_on = [
("h1", "ヘッダー1")、
("h2", "ヘッダー2")、
]
# HTMLHeaderTextSplitter のインスタンスを作成する。
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# チャンクサイズとオーバーラップを指定します。
チャンクサイズ = 511
chunk_overlap = np.round(chunk_size * 0.10, 0)
print(f "chunk_size: {chunk_size}, chunk_overlap: {chunk_overlap}")
# RecursiveCharacterTextSplitterのインスタンスを作成する。
child_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size、
chunk_overlap = chunk_overlap、
length_function = len、
)
# HTMLHeaderTextSplitterを使ってHTMLテキストを分割します。
start_time = time.time()
html_header_splits = [].
for doc in docs:
soup = BeautifulSoup(doc.page_content, 'html.parser')
splits = html_splitter.split_text(str(soup))
for split in splits:
# ソースURLとヘッダー値をメタデータに追加する
metadata = {} # ソースURLとヘッダー値をメタデータに追加
new_text = split.page_content
for header_name, metadata_header_name in headers_to_split_on:
# h1が存在しない場合は例外処理を行う。
try:
header_value = new_text.split("¶ ")[0].strip()[:100].
metadata[header_name] = header_value
except:
break
split.metadata = { **メタデータ
**メタデータ、
"source": doc.metadata["source"].
}
# ヘッダーをテキストに追加する
split.page_content = split.page_content
html_header_splits.extend(splits)
# ドキュメントをさらに小さな、再帰的なチャンクに分割する。
チャンク = child_splitter.split_documents(html_header_splits)
チャンクとエンベッディングをMilvusに挿入する。
# ステップ5. zillizにチャンクとエンベッディングを挿入する。
# チャンクを辞書のリストに変換する。
chunk_list = [].
for chunk in chunks:
# 埋め込みを生成する。
response = openai_client.embeddings.create(
input=chunk.page_content、
model=EMBEDDING_MODEL、
dimensions=EMBEDDING_DIM
)
embeddings = response.data[0].embedding
# 埋め込みベクトル、元のテキストチャンク、メタデータを組み立てる。
chunk_dict = {
'vector': embeddings、
'chunk': chunk.page_content、
'source': chunk.metadata['source']、
'h1': chunk.metadata['h1'][:50]、
}
chunk_list.append(chunk_dict)
# データをMilvusコレクションに挿入する。
insert_result = mc.insert(
コレクション名、
data=chunk_list、
progress_bar=True)
# 最後のエンティティが挿入された後、メモリに残っているセグメントの成長を止めるために flush を呼び出します。
mc.flush(COLLECTION_NAME)
Milvusの技術文書の埋め込みがロードされました。
# データに関するサンプル質問を定義する。
SAMPLE_QUESTION = "HNSWのパラメータは何を意味しますか?"
# 同じエンコーダを使って質問を埋め込みます。
response = openai_client.embeddings.create(
input=SAMPLE_QUESTION、
model=EMBEDDING_MODEL、
次元=EMBEDDING_DIM
)
query_embeddings = response.data[0].embedding
# 返す出力フィールドを定義する。
OUTPUT_FIELDS = ["h1", "h2", "source", "chunk"] # 出力フィールドを定義する。
# クエリとMilvusベクトルデータベースを使用して、セマンティックベクトル検索を実行します。
start_time = time.time()
results = mc.search(
コレクション名
data=[query_embeddings]、
output_fields=OUTPUT_FIELDS、
limit=2、
一貫性レベル
)
ChatGPTと取得したテキストコンテキストチャンクを使って答えを生成する。
LLM_NAME = "gpt-3.5-turbo"
温度 = 0.1
ランダムシード = 415
# 全てのコンテキストをスペースで区切る。
context_combined = '.join(context)
SYSTEM_PROMPT = f"""以下のコンテキストを使ってユーザーの質問に答えてください。明確に、事実に基づいて、完全に、簡潔に。
答えがコンテキストにない場合は、"I don't know "と答えなさい。
そうでない場合は4文以内で答え、根拠となる情報源を引用すること。
コンテキスト:context_combined
答え:質問に対する答え。
根拠となる情報源:{context_metadata[0]['source']}。
"""
# OpenAI API を使ってレスポンスを生成する。
レスポンス = openai_client.chat.completions.create(
messages=[
{"role":"system", "content":system_prompt,}、
{"role":"user", "content": f "質問:{sample_question}",}.
],
model=LLM_NAME、
temperature=TEMPERATURE、
seed=RANDOM_SEED、
)
# 質問と答えを、根拠となるソースと引用とともに表示する。
print(f "Question: {SAMPLE_QUESTION}")
for i, choice in enumerate(response.choices, 1):
pprint.pprint(f "答え:{choice.message.content}")
print("\n")
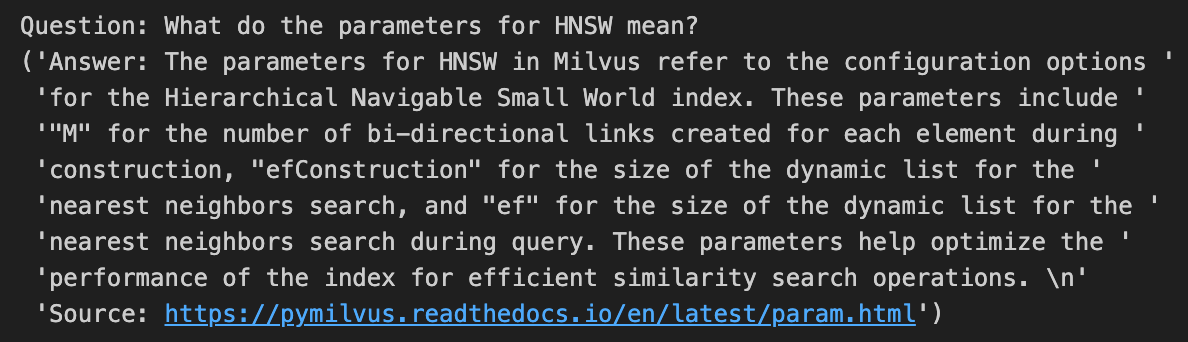
dim=256のtext-embedding-3-smallを使った答えは、少なくともこのRAGの例では、dim=1536の同じ答えに比べて完璧です!
結論
このブログでは、埋め込みモデルがRAGとSBERTでどのように使われているかを紹介しました。 埋め込みモデルのMTEBリーダーボードを示し、その使い方を説明しました。 そして、Zilliz Pipelinesに自動的に含まれる6種類のエンベッディングモデルを紹介しました。 異なるエンベッディングモデルは、異なるユースケースに最適です。 最後に、新しいOpenAIのエンベッディングモデルを呼び出すコードを紹介しました。完全なコードはbootcamp githubにあります。
参考文献
Milvus](https://github.com/milvus-io/milvus) (星をください!)
Zilliz Pipelines](https://zilliz.com/zilliz-cloud-pipelines)
チュートリアル](https://magazine.sebastianraschka.com/p/understanding-encoder-and-decoder) トランスフォーマーのエンコーダー・デコーダー部分について
SBERTエンコーダ埋め込みモデルに関するチュートリアル
埋め込みモデルのHuggingFace MTEB Leaderboard
BAAI/bg-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5)のHuggingFaceモデルカード。
埋め込みモデルのVoyageAI
OpenAI](https://platform.openai.com/docs/guides/embeddings/)埋め込みモデル

読み続けて

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.