




AIエージェントのためのコンテキストエンジニアリング戦略:開発者ガイド
信頼性の高いAIエージェントを構築することは、見た目以上に難しいものです。最初は順調に見えることが多いものの、タスクが複雑になるにつれて、ほころびが現れます。エージェントはしばしば以前の手順を見失い、自分自身の推論と矛盾したり、過剰なコンテキストの複雑さに圧倒されたりします。
この課題は、業界全体で活発な議論を巻き起こしています。最近では、Anthropic(Claude)とCognition(Devin)が、マルチエージェントの協調かシングルエージェント設計か、どちらが今後のより良い道筋なのかをめぐって対立しました。Anthropicは、マルチエージェント構成が成功率を90.2%向上させたことを示す実験を示した一方で、Cognitionは、ロングコンテキスト圧縮を備えたシングルエージェントのほうが安定性が高く、コストが低いと反論しました。
どちらの側にも妥当な主張があり、実際のところ、同じ核心的な問題を議論しています。それは、エージェントのコンテキストをいかに効果的に管理するかということです。
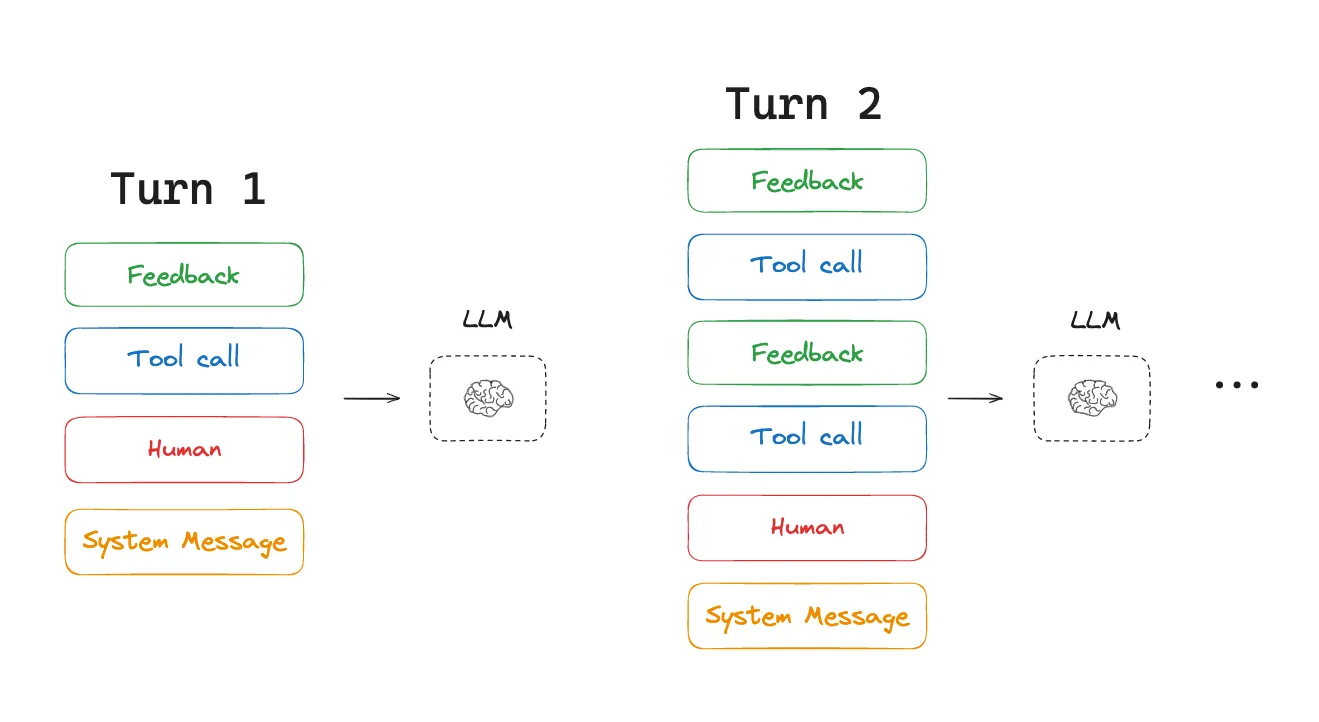
LLMをCPU、そしてそのコンテキストウィンドウをRAMだと考えてみてください。ただし、ここには落とし穴があります。ハードウェアであれば、RAMはいつでも増設できます。しかしLLMでは、コンテキスト長は設計上の上限があり、それをさらに拡張するには速度と精度の面で大きなコストが伴います。一方でエージェントは、複数ステップのワークフロー中に膨大な情報を生成し、すぐにその制限に突き当たります。これにより、重大な問題が生じます。
情報過多: コンテキストが容量を超える → エージェントがクラッシュする
コストの増大: 処理されるトークンが増えるほど、支出とレイテンシが高くなる
性能低下: 過剰な情報はエージェントを賢くするのではなく、遅くし、精度を下げる
だからこそ、コンテキストエンジニアリングは、次世代エージェントにおける中心的な設計課題となっています。業界のリーダーたちはすでに、この課題に対処するためのさまざまな方法を試しており、その多くは実際に非常にうまく機能しています。
このブログでは、LangChain、Lossfunk、Manusがこの問題にどのように異なる角度から取り組んでいるのかを探り、エージェントを高性能かつコスト効率の高い状態に保つための補完的な戦略を紹介します。
エージェントのコンテキスト課題を解決するLangChainの4つの戦略
LangChainは、エージェントのコンテキストに関する課題を、4つの一般的な失敗モードに分類しています。
コンテキスト汚染: 無関係または誤った詳細が紛れ込み、意味不明な出力につながる。
コンテキスト注意散漫: 重要な情報がノイズに埋もれてしまう。
コンテキスト混乱: 無関係なデータが多すぎて、エージェントが焦点を失う。
コンテキスト衝突: 矛盾する入力が、一貫性のない挙動につながる。
これらの課題に対処するため、LangChainはエージェントのコンテキストエンジニアリングに向けた4つの戦略フレームワーク、すなわち Write、Select、Compress、Isolate を導入しました。
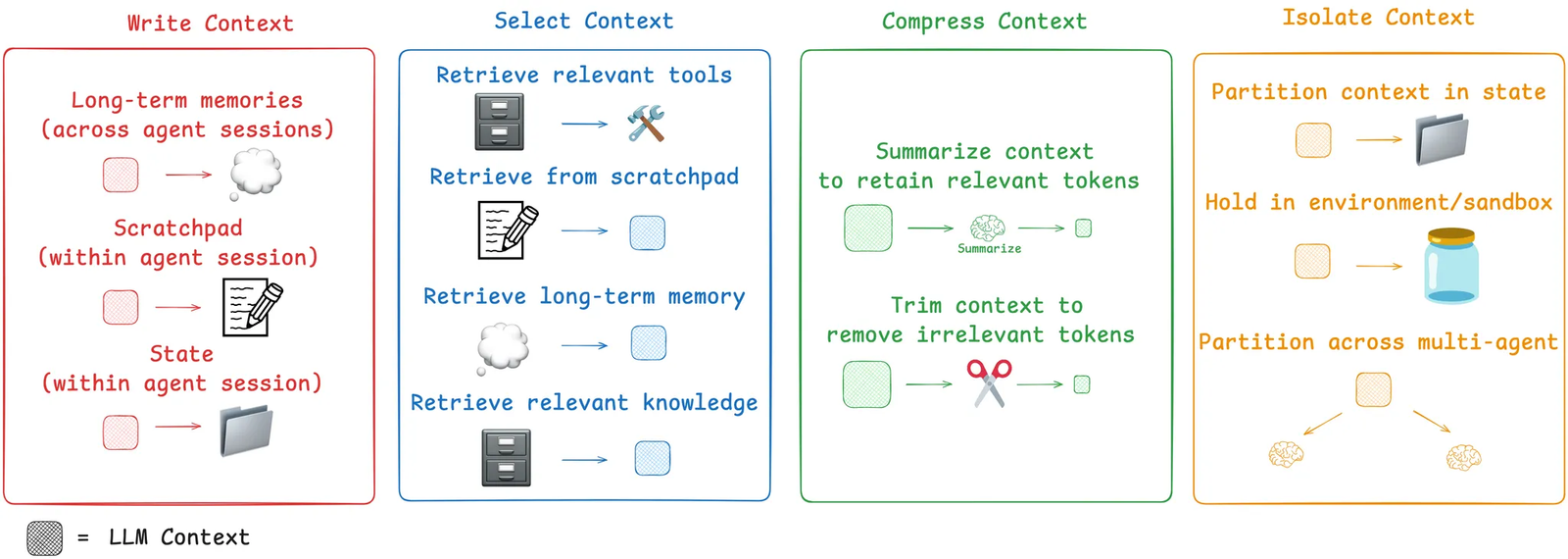
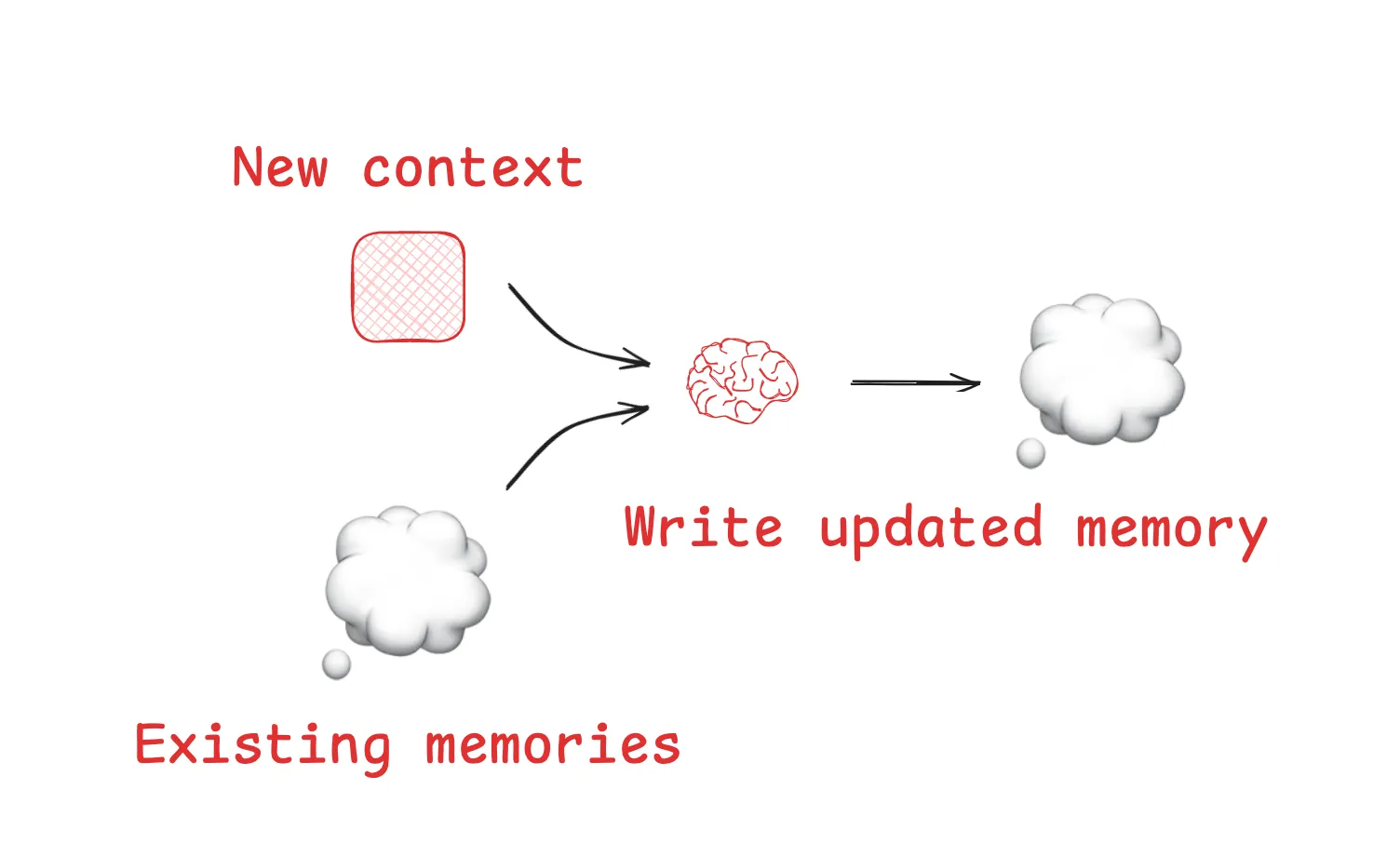
#1 コンテキストを書く: エージェントに外部記憶を与える
人間はメモを取り、知識を次に持ち越すことで問題を解決します。エージェントも同じことを学びつつあります。一般的なアプローチの1つが「スクラッチパッド」であり、中間的な推論や発見をコンテキストウィンドウの外に保存します。たとえばコードレビューでは、コードベース全体を再スキャンする代わりに、エージェントがファイルごとに問題点と修正内容を記録できます。時間が経つにつれて、これは経験とともに成長する、永続的で検索可能な記憶を構築します。
#2 コンテキストを選択する: 関連性によるフィルタリング
すべての情報が注意を向ける価値があるわけではありません。Windsurfチームは、大規模なコードベースをナビゲートするには、構文解析とナレッジグラフ検索を組み合わせる必要があることを示しました。これにより、エージェントは無関係な行に埋もれるのではなく、関連するスニペットだけを浮かび上がらせることができます。

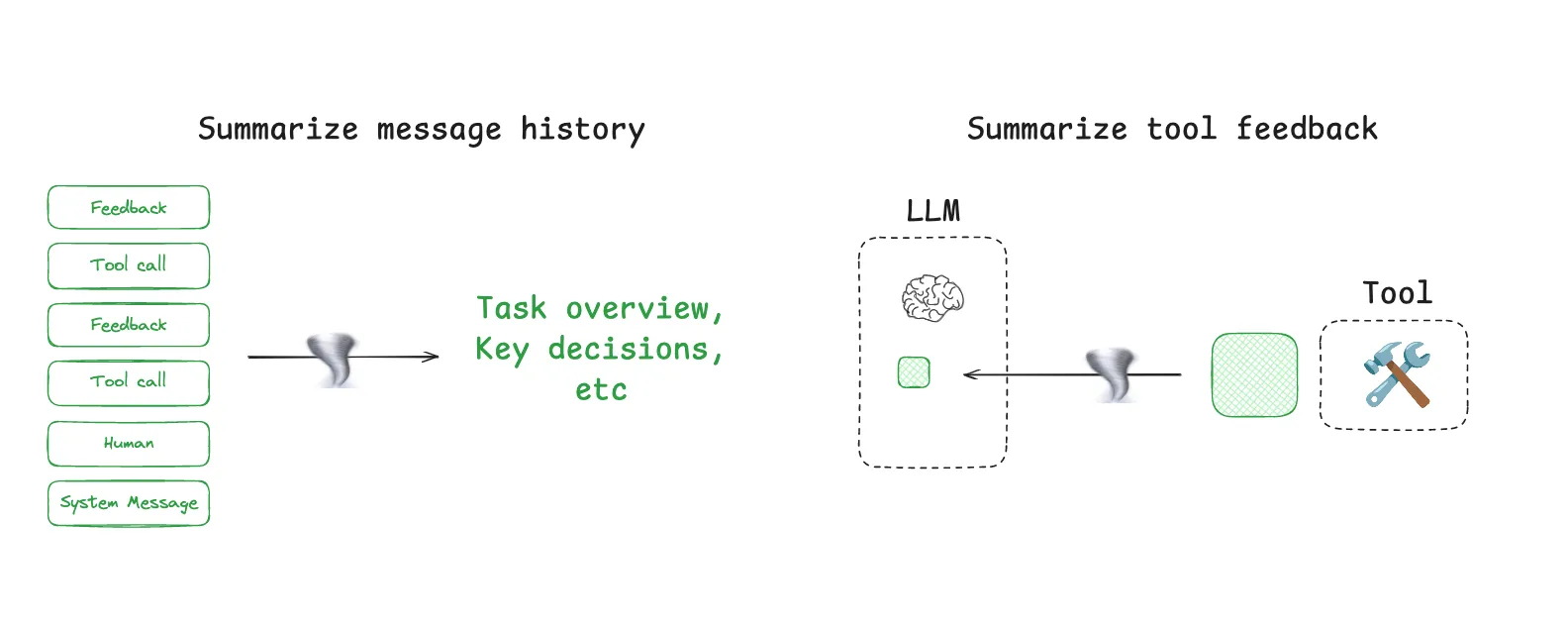
#3 コンテキストを圧縮する: 必要に応じた要約
Claude Codeは「auto-compact」機能によって、このアプローチをうまく示しています。会話がコンテキスト制限に近づくと、システムは何百ものターンを簡潔な要約に圧縮し、タスクに不可欠な詳細を保持しながら、新しい推論のためのスペースを解放します。
#4 コンテキストを分離する:モジュール型コンテキスト管理
LangGraphは、マルチエージェントアーキテクチャを通じてこの原則を適用しています。複雑なタスクはモジュールに分割され、各サブエージェントは独自のコンテキスト空間内で動作します。この分離により干渉が防がれます。あるエージェントは、別のエージェントの推論経路を汚染することなく、代替案を探索できます。
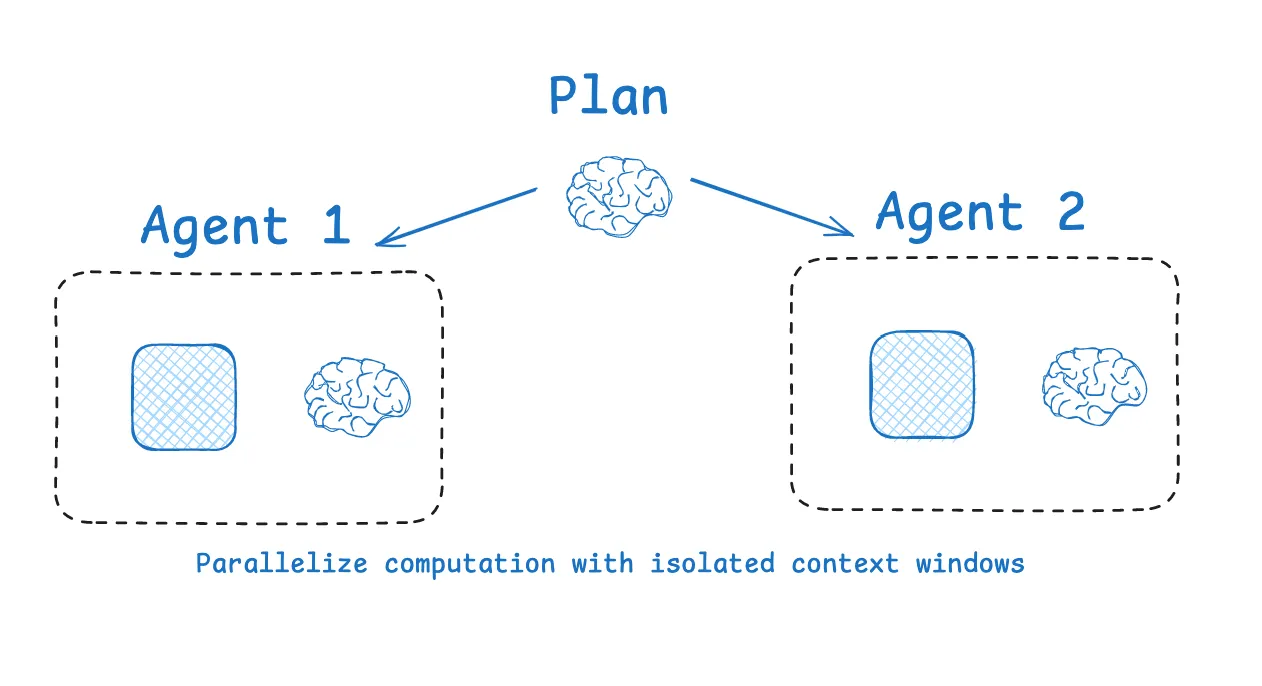
詳細については、コンテキストエンジニアリングに関するLangChainのブログを参照してください。
Lossfunkによるコンテキストエンジニアリングの6つの実践的なヒント
別の視点はLossfunkから来ています。Lossfunkは、コンテキスト管理を実世界のデプロイメントに根ざしたエンジニアリング分野として扱っています。そのアプローチは、すべての本番チームが直面する3つの制約、すなわちパフォーマンス、信頼性、コストのバランスを取ることを重視しています。Lossfunkの創設者であるParas Chopraは、コンテキストを用いて効果的なLLMエージェントを構築するための6つの実践的なヒントを概説しています。
#1 タスクを小さくすれば成功率は高くなる
複雑なタスクは、人間と同じようにエージェントを圧倒することがあります。METRの研究によると、LLMはタスクの範囲が10〜15分の作業に収まる場合に、最も高い成功率、つまり約90%を達成します。エージェントにアプリケーション全体を一度にリファクタリングするよう依頼するのではなく、プロジェクトをより小さな原子的なステップに分割します。認証モジュールを分析し、潜在的なセキュリティ問題を特定し、その後、的を絞った修正を提案する、といった具合です。これは経験豊富な開発者の進め方を反映しています。つまり、一度に1つの集中したステップを進め、進捗を段階的に積み上げていく方法です。
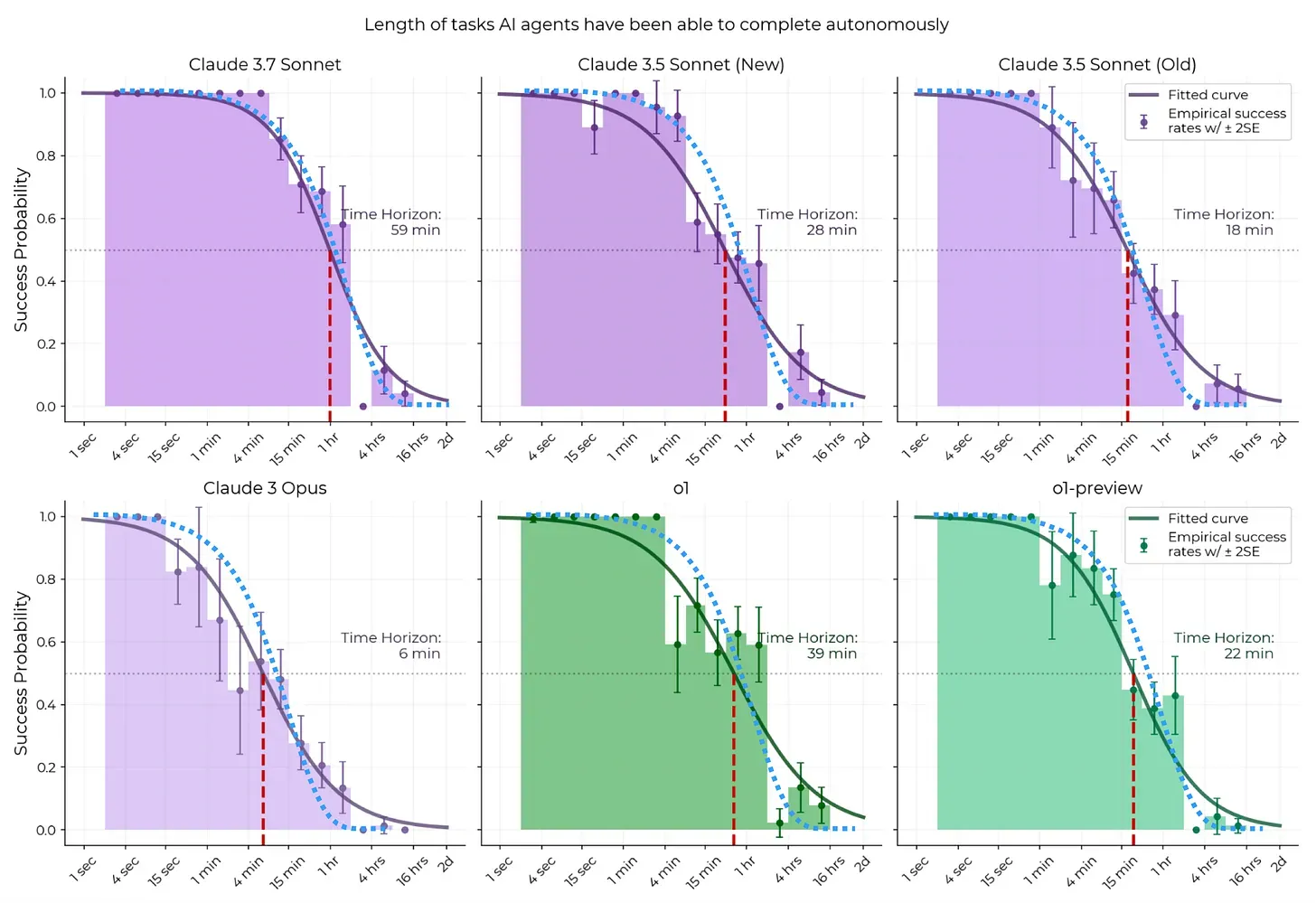
出典:Measuring AI Ability to Complete Long Tasks
#2 ファイル全体 > 断片化された検索
LangChainがフィルタリングと圧縮を重視するのとは対照的に、Parasは通常、コンテキストは多いほど良いと主張しています。彼の見解では、RAGシステムは情報を小さく不完全なチャンクに分断することが多く、それによってエージェントが混乱したり不確実になったりする可能性があります。その代わりに、完全なファイルやデータセットをコンテキストウィンドウに直接読み込ませ、モデルに全体像を与えることを提案しています。
Lossfunkは、この見方をベンチマークの証拠で裏付けています。SWE-bench-Verifiedでは、ファイル全体のコンテキストを使用したアプローチが約95%の精度を達成したのに対し、断片化された検索では約80%でした。この差は一貫性に由来します。ファイル全体があることで、モデルはばらばらの断片をつなぎ合わせるのではなく、文書全体にわたる関係性を見ることができます。
もちろん、これにはトレードオフがあります。LLMエージェントにより多くのコンテキストを提供すると、コストとレイテンシの両方が増加します。チームは、完全性の利点と長いプロンプトにかかる費用を比較検討する必要があります。このバランスは、タスクと本番環境の制約によって異なります。
#3 各タスクの後に検証ステップを追加する
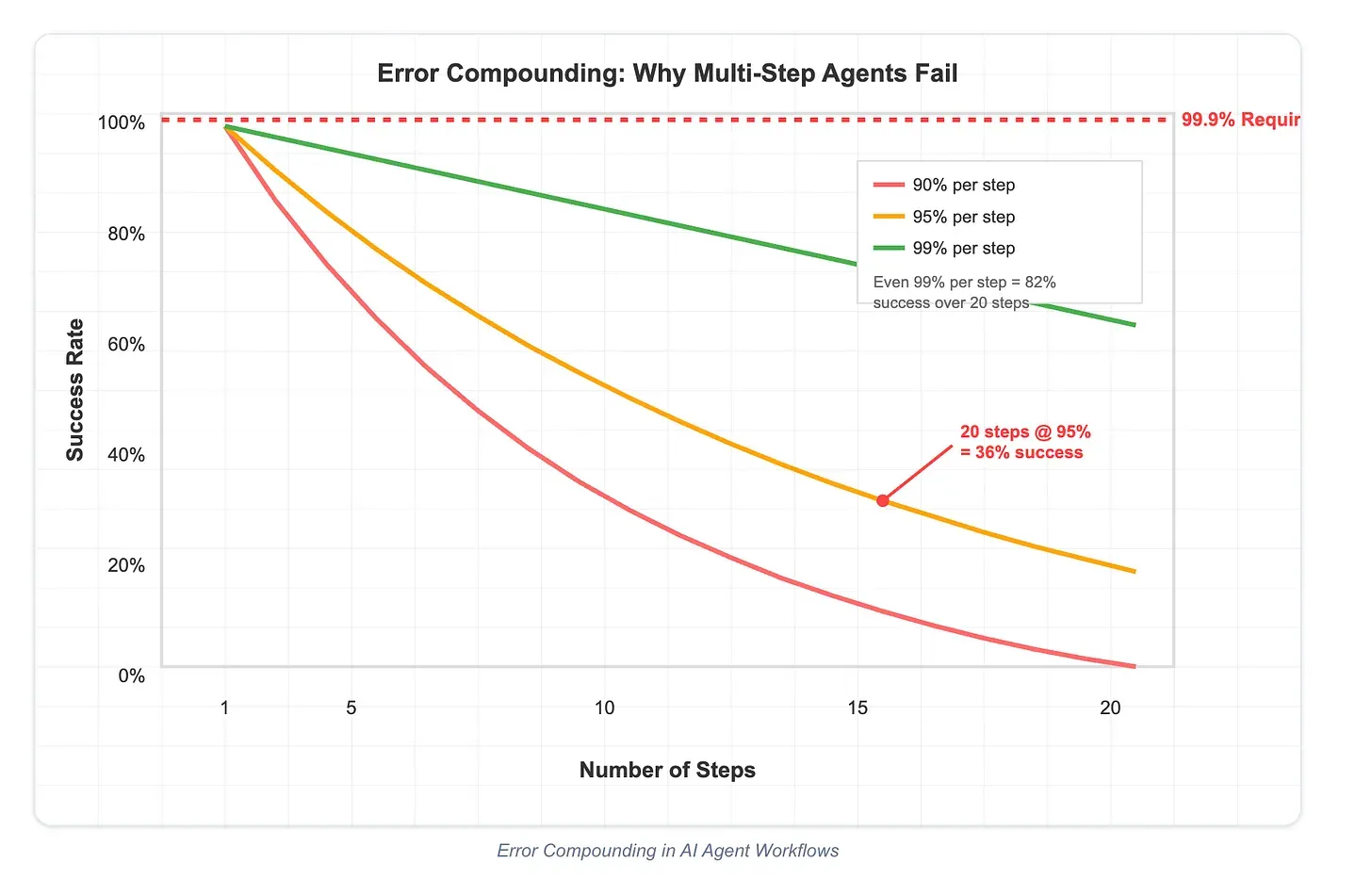
長い推論チェーンでは、エラーが積み重なりやすくなります。このリスクを減らすために、Lossfunkは、各ステップを明示的な成功/失敗チェックを持つステートレス関数として設計することを提案しています。すべてのツール呼び出しや推論アクションの後で、エージェントは操作が成功したかどうかを確認し、次のステップを明確に述べる必要があります。
このパターンは、ソフトウェア開発におけるユニットテストに似ています。小さなエラーが大きな障害へと連鎖する前に、早期に検出します。検証を組み込むことで、開発者は本番ワークフローにおいてエージェントをより回復力のあるものにする自然なリカバリーポイントを作り出せます。
#4 モデルに頻繁に思い出させる
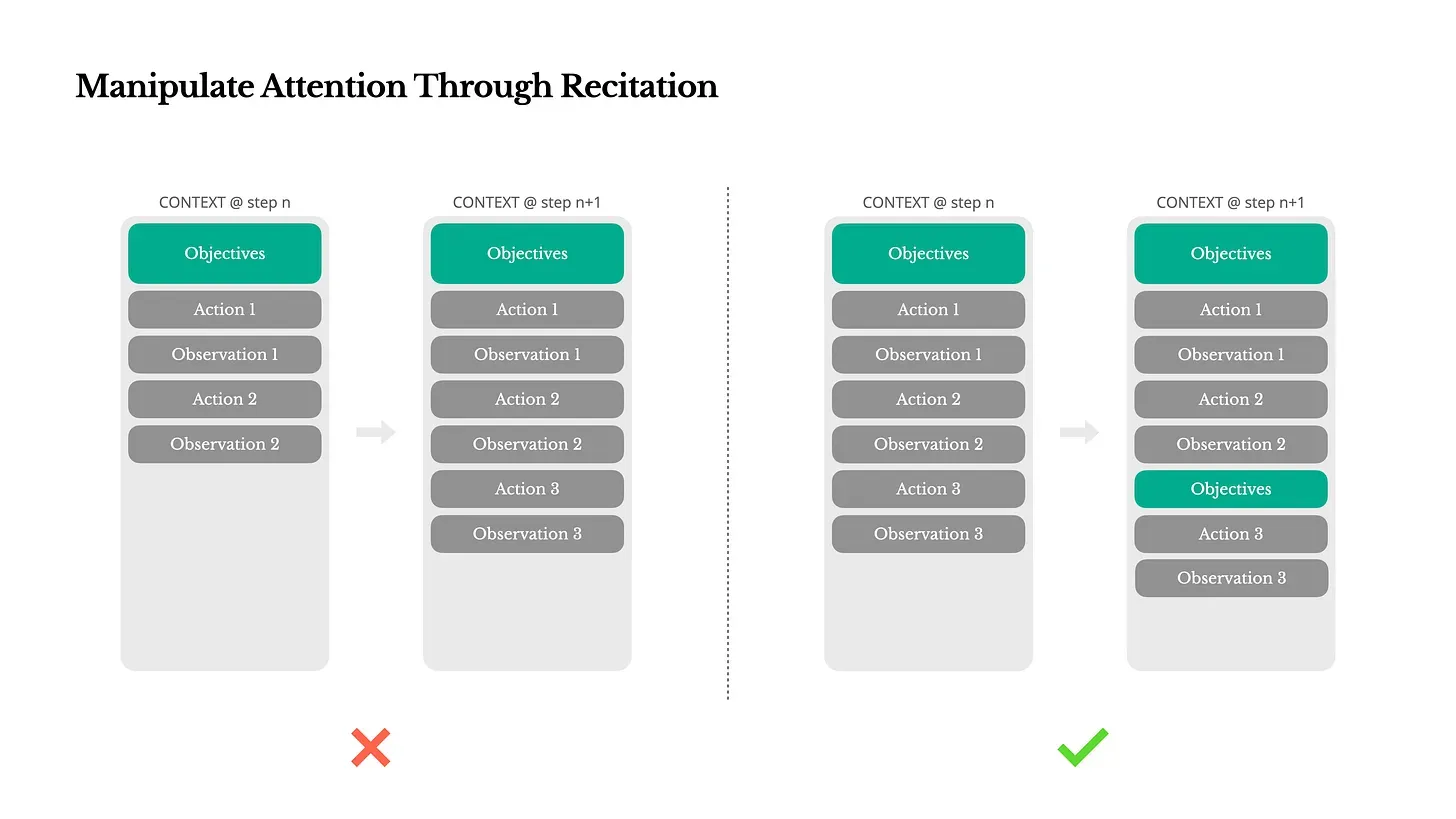
モデルは長い会話の中で初期の指示を忘れがちなため、タスクの目的と現在の状態を継続的に強化することが不可欠です。プロンプトには、タスクの要約と現在の目的を定期的に挿入してください。50回前のやり取りで何をするはずだったかをモデルが覚えていると決めつけないでください。これは制限ではなく、人間の認知がそう機能するというだけです。私たちは複雑なタスク中に軌道から外れないよう、メモやリマインダーなどの外部記憶補助を利用します。
#5 必要に応じてコンテキストを構築するため、エージェントに読み書きツールを備える
あらゆる情報をコンテキストウィンドウに詰め込むと、すぐに過負荷につながります。より良いアプローチは、エージェントに読み書きツールを与え、必要に応じて情報を取得または記録できるようにすることです。ドキュメント一式を事前にすべて読み込ませるのではなく、エージェントにファイルリーダーやデータベースコネクタを備え、必要な関連情報をオンデマンドで取り込めるようにします。
これは経験豊富な開発者の動き方を反映しています。彼らはコードベース全体を暗記しているわけではありませんが、必要になったときに適切な関数やファイルを見つける方法を知っています。外部ソースをクエリし更新する能力でエージェントを拡張することで、開発者はコンテキストをスリムに保ちながら、エージェントが必要な知識にアクセスできるようにできます。
#6 KVキャッシュを活用するためにコンテキストを不変に保つ
大きく変化するコンテキストを伴う各会話ターンは、非常に高額になる可能性があります — 場合によっては1回の応答あたり100ドルを超えることもあります。KVキャッシュの最適化を活用するには、コンテキストの可能な限り多くを不変に保ってください。各ステップでコンテキストを置き換えるのではなく、新しい情報を追記し、やり取り全体で一貫した構造化形式を維持します。
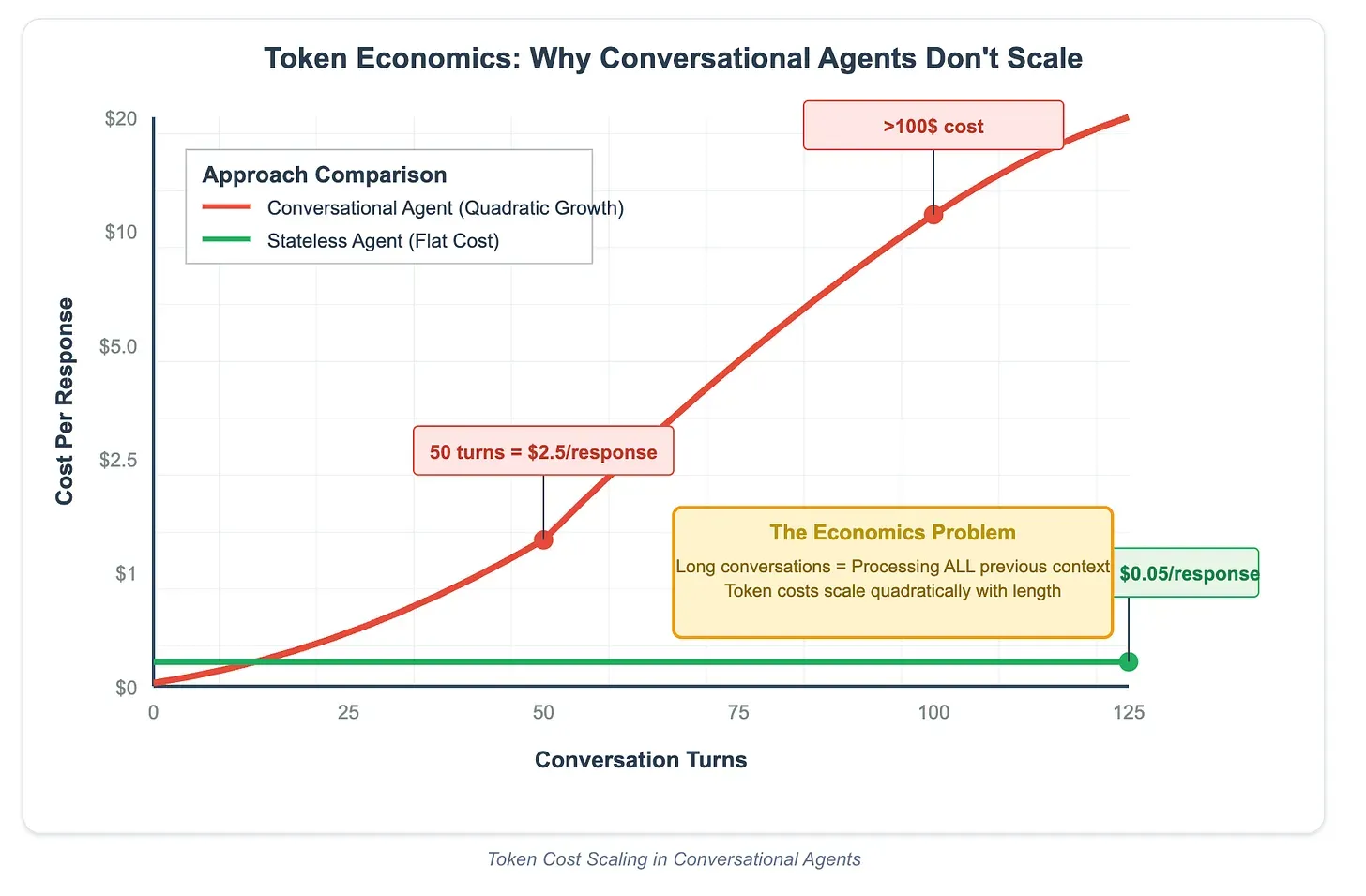
この一見小さな技術的調整は、大きなメリットをもたらし得ます。コストを1桁削減しつつ、応答時間も改善します。本番デプロイにおいて、これは開発者が適用できる最も影響の大きい低レベル最適化の1つです。
詳細については、Parasによるこのブログをご覧ください。
Manus: エージェント構築から得た7つの教訓
Manusは、リサーチからプロジェクト管理まで、最小限の人間の指示で複雑なタスクを処理するよう設計された、完全自律型のマルチエージェントAIシステムです。Manusチームはその取り組みの一環として、本番環境でシステムを運用する中で得たコンテキストエンジニアリングに関する実践的な教訓を共有しています。
#1 コスト効率のためにKV-Cacheを中心に設計する
本番グレードのエージェントにおいて、最も重要なパフォーマンス指標の1つはKVキャッシュヒット率であり、これはコストと応答時間の両方に直接影響します。現代のエージェントへの入力は、広範なコンテキストや詳細なツール呼び出し記録によって長くなり続けています。一方で出力は簡潔なままで、多くの場合、関数呼び出しに似ています。この不一致により、プリフィルコストが不均衡に高くなります。
推奨されるアプローチは、プロンプトのプレフィックスを安定させ、リクエストごとに変わるタイムスタンプのようなキャッシュを妨げる要素を避けることです。既存の内容を書き換える代わりに追記のみのコンテキスト戦略を使用し、JSONシリアライズでは決定論的な順序を徹底します。一部のモデルフレームワークでは、KVキャッシュの再利用を最大化するためにキャッシュブレークポイントを明示的に指定する必要もあります。これらの実践に従うことで、本番環境におけるコスト効率に大きな違いをもたらせます。
#2 動的ロードの代わりにツールマスキングを使用する
ツールの数が数百に増え、ユーザー定義ツールも含まれるようになると、モデルはツール選択プロセス中にエラーを起こしたり、行き詰まったりしやすくなります。動的にツールを挿入または削除すると KV キャッシュが無効になり、未定義ツールの参照エラーが発生するため、問題はさらに複雑になります。
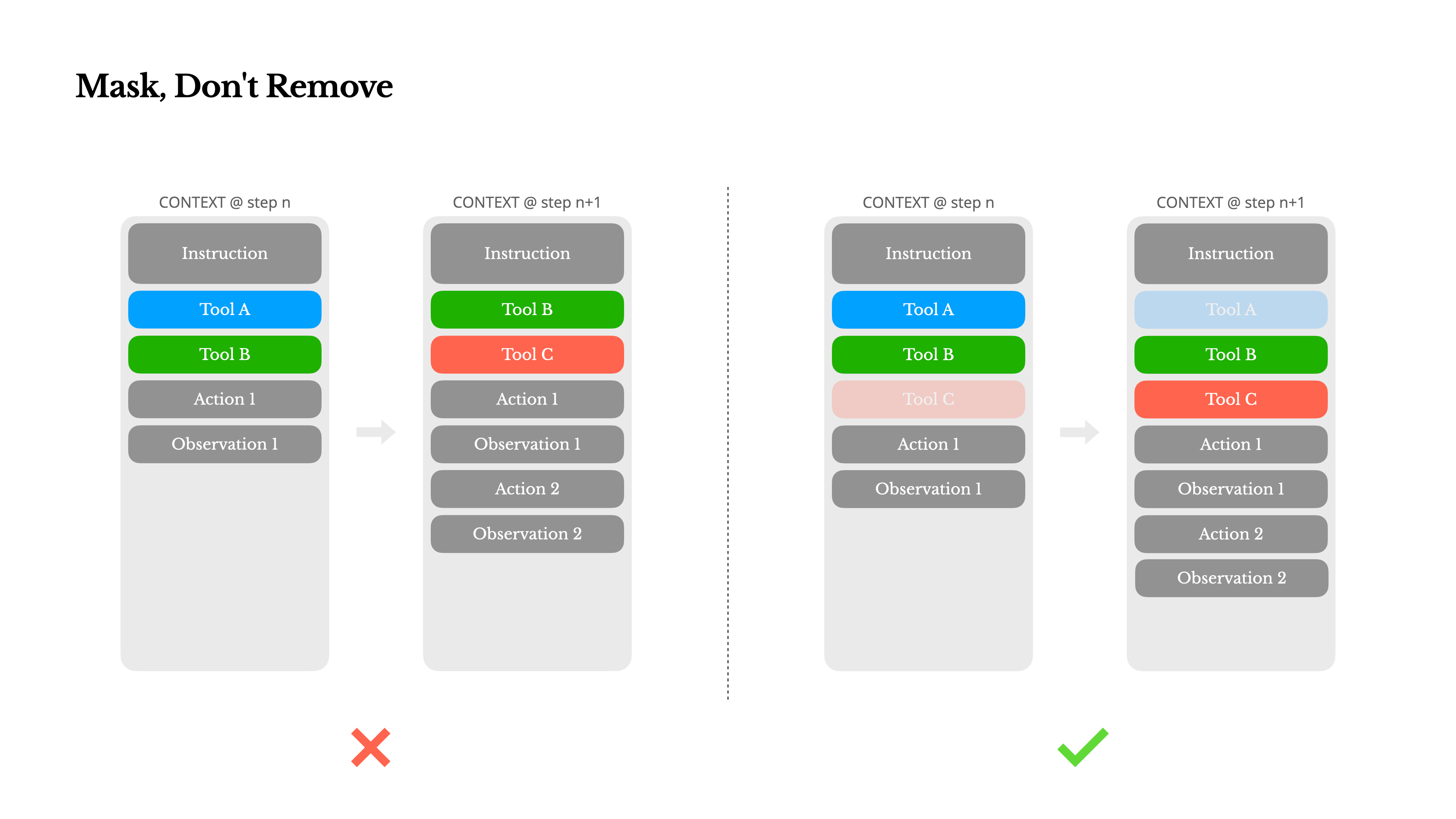
ツールを削除する代わりに、マスキングを使用します。トークンマスキング技術により、キャッシュを壊すことなく、呼び出し可能なツールセットを動的に調整できます。browser_, のような統一プレフィックスを使用してグループ化と制限を容易にし、Hermes 形式または API がサポートする function-calling prefill を活用して選択空間を制御します。
#3 ファイルシステムをコンテキストとして使用する
128K コンテキストは十分に見えますが、大規模な Web ページ、PDF、その他の非構造化データに遭遇すると窮屈になります。情報を早期に破棄する一般的な圧縮アプローチでは、将来のステップで重要なコンテキストが失われる可能性があります。
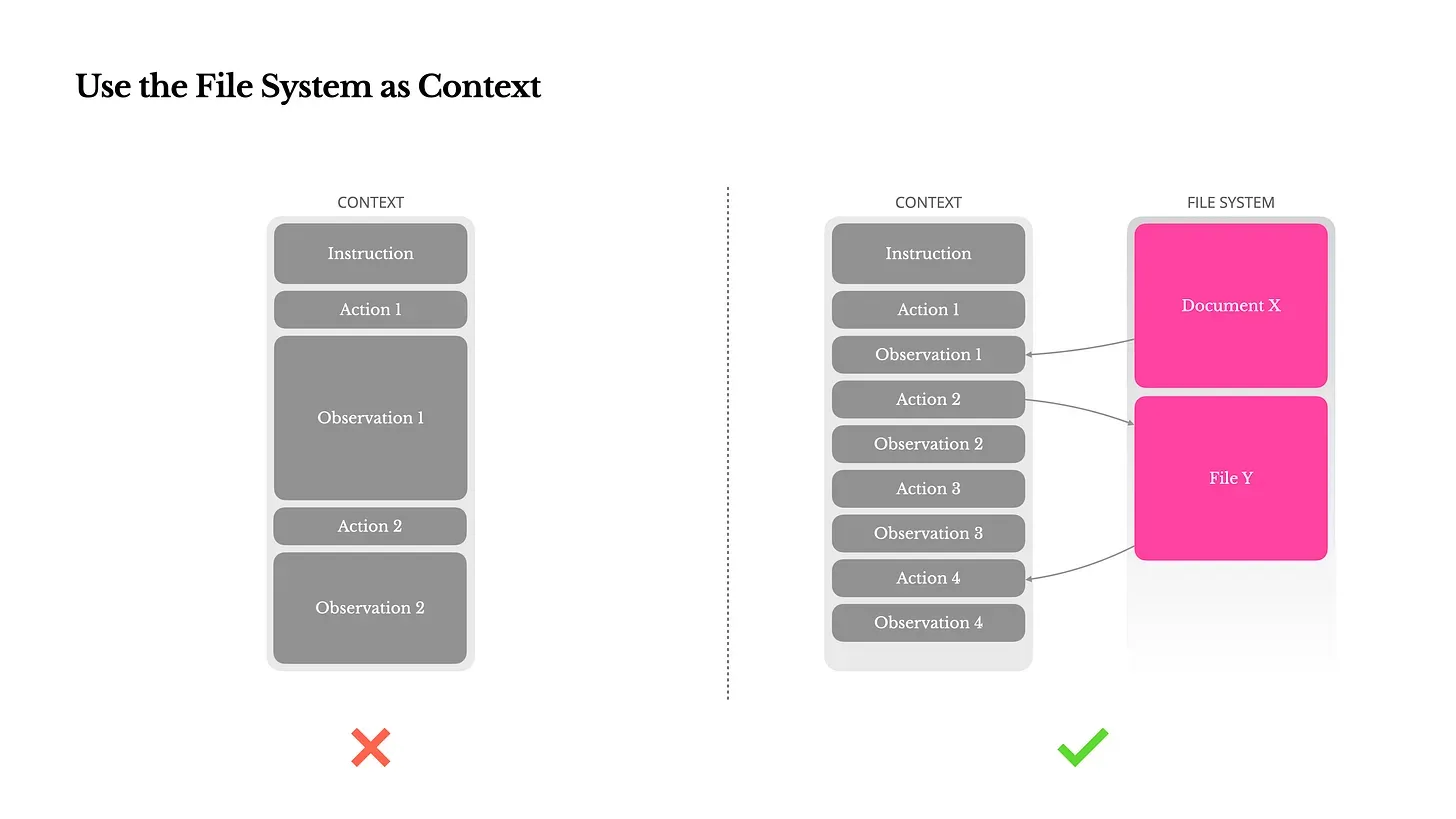
Manus のアプローチでは、エージェントがファイルシステムの読み書き操作を使ってデータを外部化できます。Web ページの内容は削除しても URL は保持し、ドキュメントは消去してもファイルパスは残すことで、情報を回復可能な状態に保ちます。これにより「長期記憶」システムが実装されると同時に、SSM のような将来のより軽量なアーキテクチャの土台が築かれます。
#4 暗唱によって注意を操作する
Manus は todo.md を継続的に更新し、未完了の目標をコンテキストの末尾で暗唱します。この技術により、「lost-in-the-middle」問題を回避し、長いプロセスの間でもモデルが目標の一貫性を維持する能力が向上します。自然言語による「自己リマインド」は、注意を捉えて維持する最も効果的な方法の 1 つであることが証明されています。
#5 学習のために失敗の痕跡を保持する
言語モデルは必然的に、ハルシネーション、環境クラッシュ、呼び出し失敗を経験します。ほとんどのシステムは習慣的に失敗の痕跡を消去し、再試行またはリセットしますが、これでは学習が起こりません。正しいアプローチは、スタックトレースや観察結果を含む失敗記録を保持し、モデルが自らの信念を調整して同じ間違いの繰り返しを避けられるようにすることです。エラー回復能力こそが、エージェント知能の正確な尺度を表します。
#6 Few-Shot の罠を避ける
Few-shot prompting は LLM の出力を改善するためのよく知られた技術ですが、Manus は、エージェントシステムではそれが微妙な問題を引き起こす可能性があると警告しています。モデルは自然にコンテキストのパターンを模倣するため、反復的な few-shot 例を大量に読み込むと、硬直した行動に固定されてしまう可能性があります。たとえば、Manus が履歴書をレビューするためにバッチプロンプティングを使用したとき、モデルは各ケースの具体性に適応するのではなく、同じ行動を機械的に繰り返し始めました。
対策は、例に変化と多様性を導入することです。形式、順序、表現を変えることで、行動–観察テンプレートを少し調整します。構造化された「ノイズ」を加えることで、エージェントが脆くなるのを防ぎ、適応性を保つのに役立ちます。これにより、モデルに有用なガイダンスを与えながらも柔軟性を維持できます。
#7 ファインチューニングよりもコンテキストエンジニアリングを優先する
BERT のようなモデルを用いた初期の取り組みにおいて、Manus はファインチューニングに大きく依存していました。そのプロセスはしばしば数週間の反復を要し、すぐに非効率でコストの高いものになりました。その経験に基づき、チームはエンドツーエンドのトレーニングから離れ、性能向上の主要なレバーとして コンテキストエンジニアリング に焦点を移しました。
その影響は大きなものでした。プロダクトの更新サイクルは数週間から数時間へと短縮されました。モデルのアップグレードは、再トレーニングや再適応なしにシームレスに統合できるようになりました。Manus はその違いを、海底に打ち付けられて変化する状況に合わせて動けない杭ではなく、進路を変えられる船のようにプロダクトを構築することだと説明しています。コンテキストエンジニアリングにより、能力を犠牲にすることなく柔軟性が得られました。
詳細については、こちらのManusブログをご覧ください。
ベクトルデータベースがコンテキストエンジニアリングを支える仕組み
AIエージェントにとって最も難しい課題の1つは、コンテキストが不足することです。エージェントが大規模な外部知識ベース、長い会話履歴、またはマルチモーダルデータを処理する必要がある場合、情報を動的に保存、検索、再利用する能力は、信頼性にとって不可欠になります。
ベクトルデータベースは実用的なソリューションを提供します。たとえば、Milvusは、テキスト、画像、動画など、10億規模のマルチモーダルデータを処理するために構築された、オープンソースの高性能システムです。この情報をベクトルとして表現することで、Milvusはエージェントが最も関連性の高い知識スニペットや過去のやり取りを、推論プロセスに即座に取り込めるようにします。LangChainやLlamaIndexなどのフレームワークと統合することで、Milvusはエージェントの知識ベースを拡張し、推論精度を向上させる検索拡張生成(RAG)システムを支えます。そのマネージドサービスであるZilliz Cloudは、自然言語クエリ、エンタープライズグレードの信頼性とセキュリティ、AWS、GCP、Azureにまたがるグローバルな可用性など、さらに高度な機能とより高いパフォーマンスを提供します。
開発者体験も同じくらい重要です。Milvusは、わずか数行のコードでベクトルを保存・クエリできる、十分に文書化されたPython SDKを提供しています。これにより技術的な障壁が下がり、チームはコンテキスト管理のクローズドループを迅速に確立し、堅牢なメモリ機能をエージェントに直接組み込むことができます。
from pymilvus import MilvusClient
# Create local Milvus instance
client = MilvusClient("demo.db")
# Create vector collection
client.create_collection(collection_name="knowledge_base", dimension=768)
# Batch insert vectorized data into knowledge base
client.insert(collection_name="knowledge_base", data=embedding_vectors)
# Retrieve most relevant context information
query_vector = embedding_fn.encode_queries(["What is Context Engineering?"])
results = client.search(
collection_name="knowledge_base",
data=query_vector,
limit=3,
output_fields=["text", "source"]
)
詳細については、以下のリソースをご覧ください。
Milvus + Loon:AIエージェント向けに設計されたインフラストラクチャ
ベクトルデータベースはコンテキストエンジニアリングの中核ですが、スタックの一部にすぎません。エージェントには、上流で扱いにくいマルチモーダルデータを処理し、実行時にそれを高速で検索する方法も必要です。だからこそ、私たちはMilvusとLoonが連携するように設計しました。一方が検索を担い、もう一方がデータを大規模に準備します。
Milvus: Milvusは、テキスト、画像、音声、動画にまたがる10億規模のワークロードに最適化された、最も広く採用されているオープンソースのベクトルデータベースです。ベクトル検索のためにゼロから構築されており、大規模でも10ミリ秒未満の検索を実現します。エージェントにとって、これは応答性に直結します。瞬時で信頼できると感じられるか、遅くてエラーが発生しやすいと感じられるかは、検索速度に左右されます。
Loon(近日公開): Loonは、マルチモーダル前処理向けに設計された、近日公開予定のクラウドネイティブなマルチモーダルデータレイクサービスです。現実世界のデータセットは扱いにくく、重複し、一貫性がなく、さまざまな形式に散在しています。LoonはRayやDaftのような分散フレームワークを使用して、そのデータをMilvusにストリーミングする前に、クレンジング、重複排除、クラスタリングします。その結果、エージェントはノイズに処理サイクルを浪費せず、初日から構造化された高品質なコンテキストを利用できます。
クラウドネイティブな弾力性: 両システムはストレージとコンピュートを独立してスケールできるため、ワークロードがギガバイトからペタバイトへ拡大する中で、チームはリアルタイム配信とオフライン分析のバランスを取ることができます。過剰なプロビジョニングも、ボトルネックもありません — あるのは、現代のAIパイプラインが求める弾力性だけです。
将来を見据えた基盤: 今日の優先事項はセマンティック検索とRAGパイプラインであり、明日の優先事項はマルチモーダル推論とエージェント駆動型ワークフローになるでしょう。MilvusとLoonを使えば、同じスタックでその両方をサポートできます。インフラを取り替えることなく進化できる柔軟性が得られ、コスト、リスク、複雑さを低減できます。
コンテキストこそがAIエージェントにとって真のフロンティア
単一エージェント設計とマルチエージェント設計をめぐる議論が示すように、今日のAIエージェントにとって本当のボトルネックは、創造性だけではありません — それはコンテキストです。LangChainの4本柱のフレームワークであれ、Lossfunkの本番環境重視のプレイブックであれ、完全自律システムの構築から得られたManusの苦労の末の教訓であれ、業界は同じ洞察へと収束しつつあります。つまり、エージェントの成否は、どれだけうまくコンテキストを設計できるかにかかっているのです。
戦略はさまざまです — 書き込みとフィルタリングを重視するものもあれば、ファイル全体のコンテキストやキャッシュを意識した設計を推奨するものもあります — しかし目標は同じであり、特にプロダクトとして利用可能なエージェントにおいては、エージェントの能力とコスト効率を両立させることです。そして、すべてを解決する単一の手法はないものの、それらは組み合わさることで、開発者が自分たちのシステムに適応できる実践知の蓄積を形成しています。
Zillizでは、Milvusのようなベクトルデータベースをこのツールキットの基盤の一つと考えています。コンテキストウィンドウを超えたスケーラブルでより正確なメモリをエージェントに提供することで、開発者はコンテキストエンジニアリングを実用的で柔軟かつ本番環境に対応したものにできます。AIエージェントの未来は、モデルを大きくすることだけで定義されるのではなく、コンテキストをより賢く設計する方法によって定義されます — そして、真のブレークスルーはそこから生まれるのです。

読み続けて

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.