




Zillizスキル分解:AIエージェントがベクトルデータベースを習得する方法
元は、独立系AI-ops実践者であり、MilvusコミュニティのアクティブなコントリビューターであるShugeXによるものです。許可を得て翻訳・再公開しています。
MilvusでRAGアプリを構築するためにClaude Codeを使っているところを想像してください。コレクションの作成、スキーマの定義、ベクトルの挿入、ハイブリッド検索の実行——すべてのステップで、正しいAPIを見つけるためにpymilvusのドキュメントをめくり、それからエディタに戻って組み込むことになります。そしてZilliz Cloudを使っている場合は、クラスタ管理、監視、バックアップ設定のためにコンソールへログインしようとブラウザにも行ったり来たりします。開発環境と運用環境は、まったく別の世界です。
Zillizが最近公開した2つのClaude Code Skillsは、まさにその断点を狙っています。 Milvus Skillは、Python SDKを通じてベクトルデータベースを操作する方法をエージェントに教えます。Zilliz Cloud Skillは、zilliz-cliを通じてクラウド側のすべてを管理する方法をエージェントに教えます。それぞれのSkillは1つの領域を扱い、両方を組み合わせることで、開発と運用を1つの連続したClaude Codeセッションに変えます。
両方のSkillsのソースコードを最初から最後まで読み通したところ、モジュール設計、安全性パターン、そしてSkillがMCPと並んでどこに位置づけられるのかなど、掘り下げる価値のある点が多く見つかりました。本記事では、それぞれを順に見ていきます。
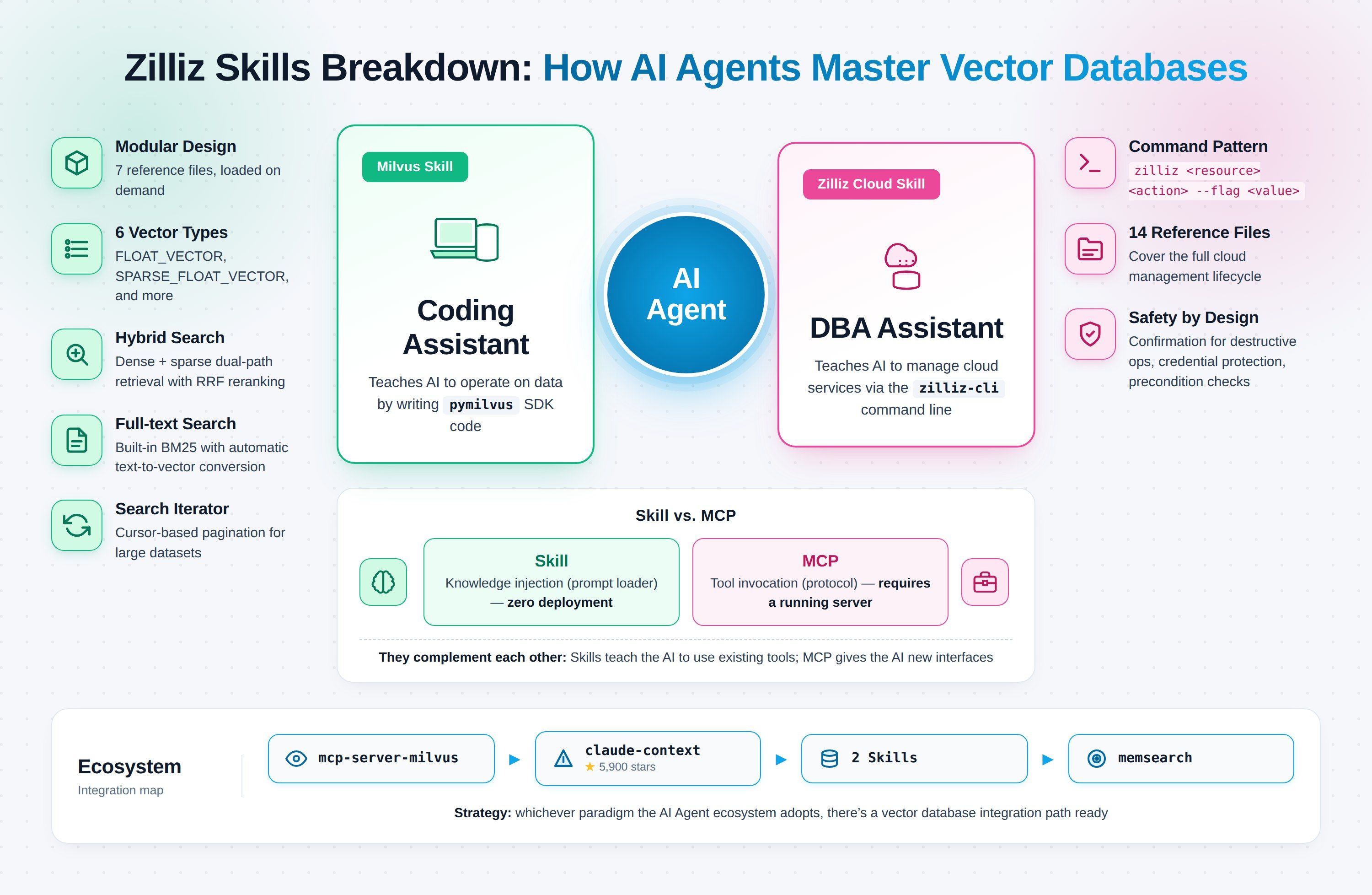
Milvus SkillとZilliz Cloud Skillがそれぞれ行うこと
この2つのSkillsは、同じものの2つのバージョンではありません。対象としているのは、2種類の異なる正しさの失敗です。
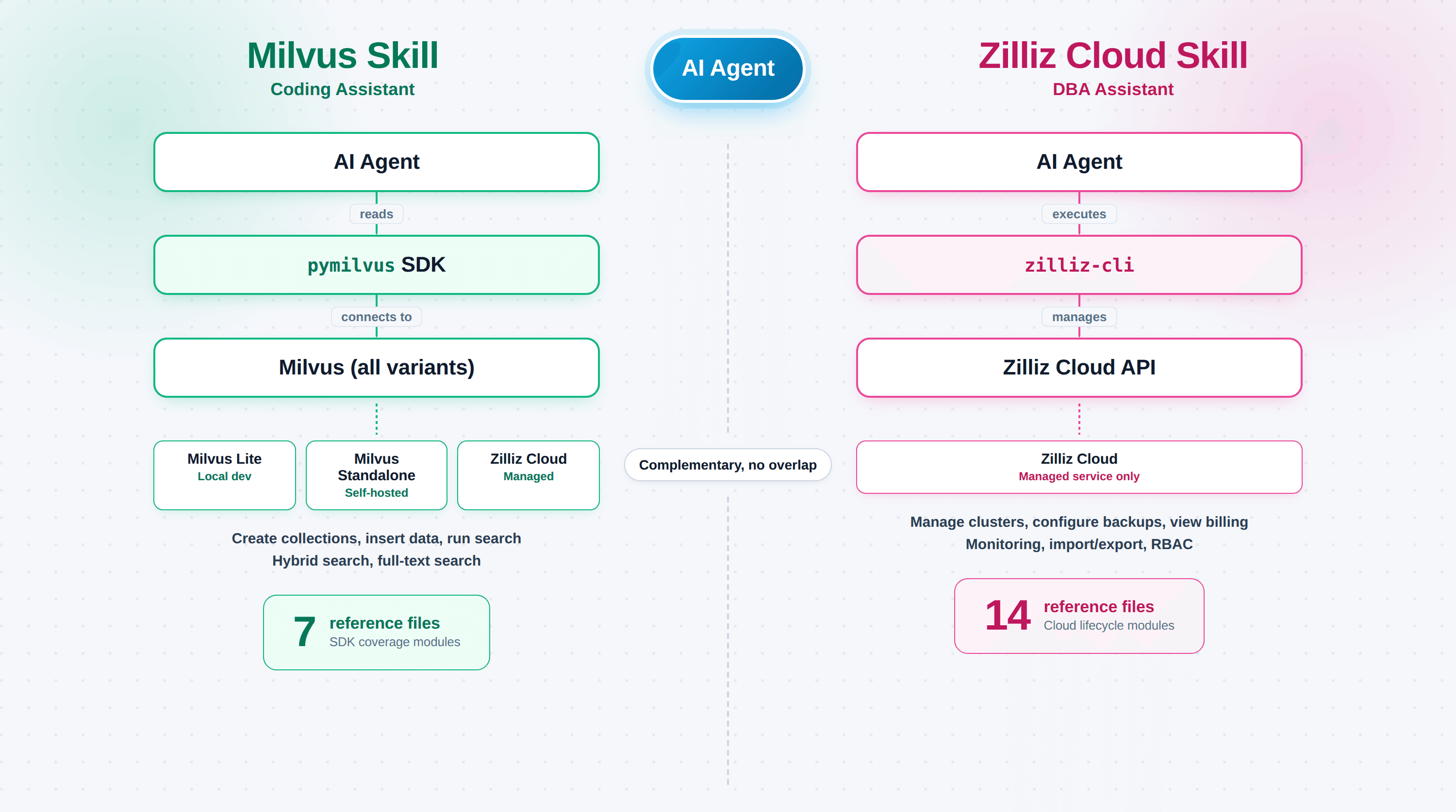
Milvus Skill(zilliztech/milvus-skill)は、接続、コレクション作成、ベクトル挿入、検索実行のためのPython SDKであるpymilvusをエージェントに教えます。これはコーディングアシスタントであり、Milvus Lite、セルフホストのStandalone/Cluster、またはZilliz Cloudなど、あらゆるMilvusデプロイメントに対して機能します。これが修正する失敗は、エージェントが古いAPI形状を使ったために、コンパイルは通るものの依頼したことを実行しないpymilvusコードです。
Zilliz Cloud Skill(zilliztech/zilliz-skill)は、クラスタ、バックアップ、監視、請求をカバーするコマンドラインツールであるzilliz-cliをエージェントに教えます。これはDBAアシスタントであり、Zilliz Cloudに対してのみ機能します(セルフホストのMilvusにはコントロールプレーンがありません)。これが修正する失敗は、本番環境のライブシステムに対する幻覚的なコマンドです。誤ったzilliz cluster deleteは、コンパイルエラーよりも大きな代償を伴います。
一言でいうと:
- Milvus Skill → エージェントがデータを操作するコードを書く
- Zilliz Cloud Skill → エージェントがサービスを管理するコマンドを実行する
| Dimension | Milvus Skill | Zilliz Cloud Skill |
|---|---|---|
| Interface | Python(pymilvus) | CLI(zilliz-cli) |
| Role | コーディングアシスタント | DBAアシスタント |
| Works against | すべてのMilvusデプロイメント + Zilliz Cloud | Zilliz Cloudのみ |
| Files | 7つのリファレンスモジュール | 14のサブスキル |
| Correctness target | 古いSDK API | ドキュメント化が不十分な運用コマンド |
| Typical task | コレクション構築、挿入、検索 | クラスタのプロビジョニング、バックアップ設定、請求確認 |
Milvus Skill: 信頼できるpymilvusを書く方法をエージェントに教える
Milvus Skillの references/ フォルダには7つのファイルがあり、それぞれが独立したpymilvusの機能領域に対応しています。 エージェントが特定のタスクを処理するとき、すべてのドキュメントをコンテキストに詰め込むのではなく、関連するファイルだけを読み込みます:
| File | Covers |
|---|---|
collection.md | データ型、フィールド定義、コレクション操作 |
vector.md | ベクトルCRUD、ハイブリッド検索、全文検索、イテレータ |
index.md | インデックスタイプ、メトリックタイプ、インデックス管理 |
partition.md | パーティション管理 |
database.md | データベース管理 |
user-role.md | RBAC |
patterns.md | 一般的なパターン(RAG、ハイブリッド検索など) |
スキーマを構築していますか?エージェントは collection.md を取り込みます。検索を実行していますか?vector.md を取り込みます。残りは対象外のままです。コンテキストウィンドウは有限です。必要に応じた読み込みは、すべてを一括投入するより優れています。
サポートされるデータ型: 予想以上に豊富
collection.md をざっと見ると、Milvus は多くの開発者が思っている以上に多くのベクトル型をサポートしています。
- スカラー:
BOOL,INT8/16/32/64,FLOAT,DOUBLE,VARCHAR,JSON,ARRAY - ベクトル:
FLOAT_VECTOR— 32 ビット浮動小数点、デフォルトFLOAT16_VECTOR— 半精度、メモリを節約BFLOAT16_VECTOR— BF16、ディープラーニングパイプラインで一般的BINARY_VECTOR— バイナリSPARSE_FLOAT_VECTOR— スパース、全文検索用INT8_VECTOR— 量子化、さらなる圧縮
ハイブリッド検索: これらの Skills が扱う最も注目すべき機能
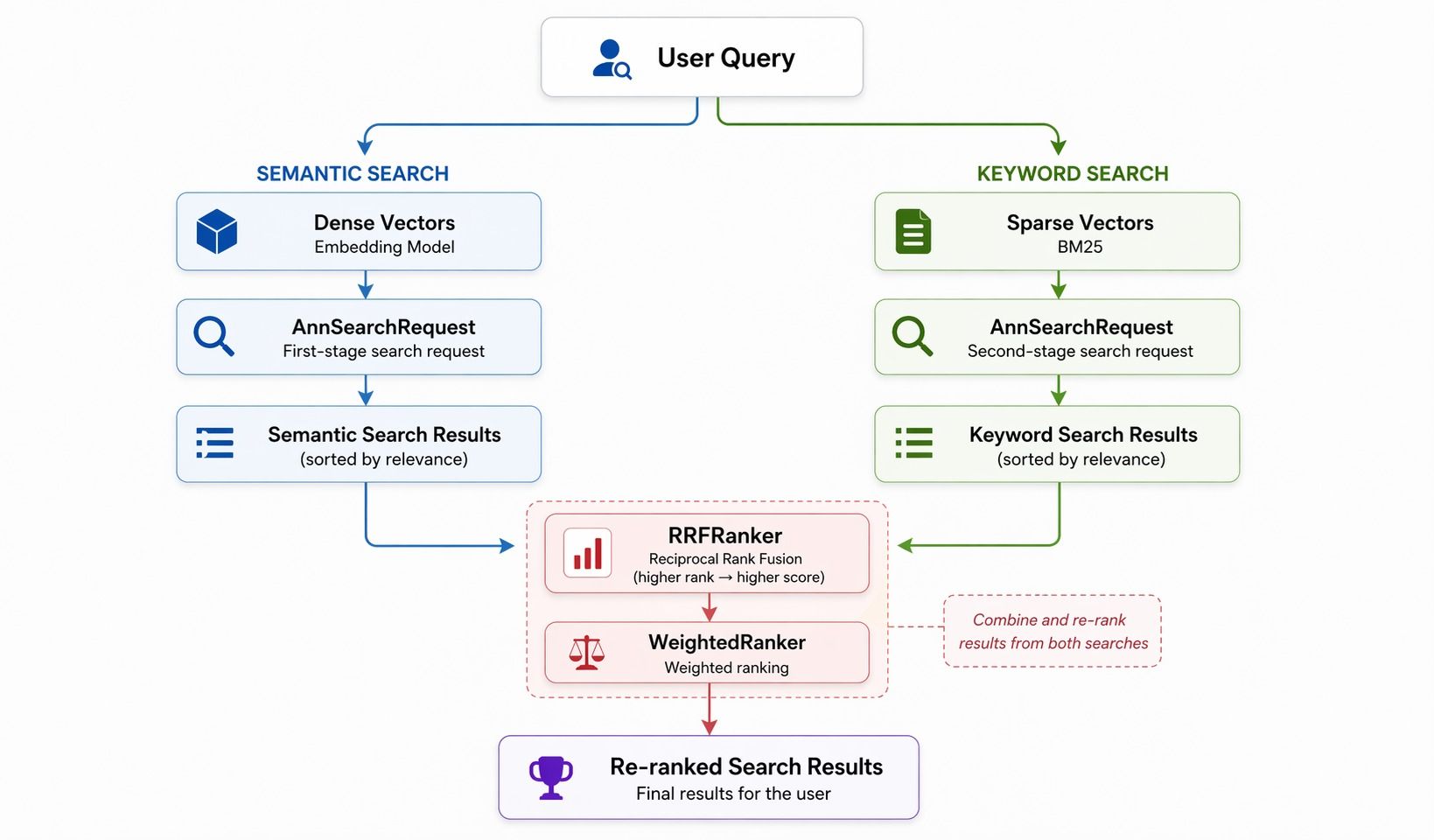
patterns.md は 4 つの一般的なパターンを文書化しています。ハイブリッド検索 は最も多くの要素を持ちます。密ベクトル検索(セマンティック)と疎ベクトル検索(キーワード)が並列に実行され、その後 RRF(Reciprocal Rank Fusion) または重み付きランキングが 2 つのリストをマージします。
3 つの構成要素:
AnnSearchRequest— 検索ブランチごとに 1 つRRFRanker/WeightedRanker— 融合戦略SPARSE_FLOAT_VECTOR— 疎ベクトルフィールド
RRF はシンプルです。各結果について、スコア = 1/rank とし、ブランチ全体で合計します。上位にランクされた項目が勝ちます。WeightedRanker はブランチごとの重み付き合計です。この Skill がこれを明文化しているため、開発者が RRF の論文を読まなくても、エージェントは使えるハイブリッド検索コードを生成できます。
Milvus の組み込み BM25 全文検索
Milvus Skill には、Milvus 2.5 の組み込み Sparse-BM25 全文検索 もエンコードされています。Function と FunctionType.BM25 と組み合わせることで、Milvus は生テキストを内部で疎ベクトルに変換し、外部の埋め込みモデルや手動の TF-IDF パイプラインを不要にします。
2.5 より前は、全文検索とはトークナイザーを扱い、TF-IDF を手作業で計算し、自分で疎ベクトルを生成することを意味していました。今では、やりたいことをエージェントに伝えれば、Skill が BM25 Function を正しく接続したコレクションを生成するよう導いてくれます。
検索イテレーター: 100 万行コレクションのためのページネーション
vector.md は search_iterator と query_iterator も扱っています。これは、100 万行または 10 億行規模のコレクション向けのカーソル形式のページネーションです。通常の search は固定サイズの結果セットを返します。イテレーターは、欠落や重複なしにページをたどるため、完全列挙に必要なものです。
Zilliz Cloud Skill: エージェントにクラウド DBA になる方法を教える
Zilliz Cloud Skill の役割は Milvus Skill とは異なります。Python を書く代わりに、エージェントは稼働中のコントロールプレーンに対して CLI 呼び出しを組み立てます。そして、不適切なコマンドは本番環境を消し去る可能性があるため、Skill はそれらの呼び出しを安全ルールで包みます。
コマンドモード: エージェントが CLI 呼び出しを組み立てる方法
Skill は一貫したコマンド形式をエンコードしています。
zilliz <resource> <action> --flag <value>
例:
zilliz cluster list— すべてのクラスターを一覧表示zilliz collection create --name my_collection— コレクションを作成zilliz backup create --name daily-backup— バックアップを作成
3 つの出力形式: json(機械可読)、table(人間に読みやすい)、text(プレーン)。エージェントは用途に合うものを選びます。
クラウドライフサイクル全体をカバーする 14 のサブ Skill
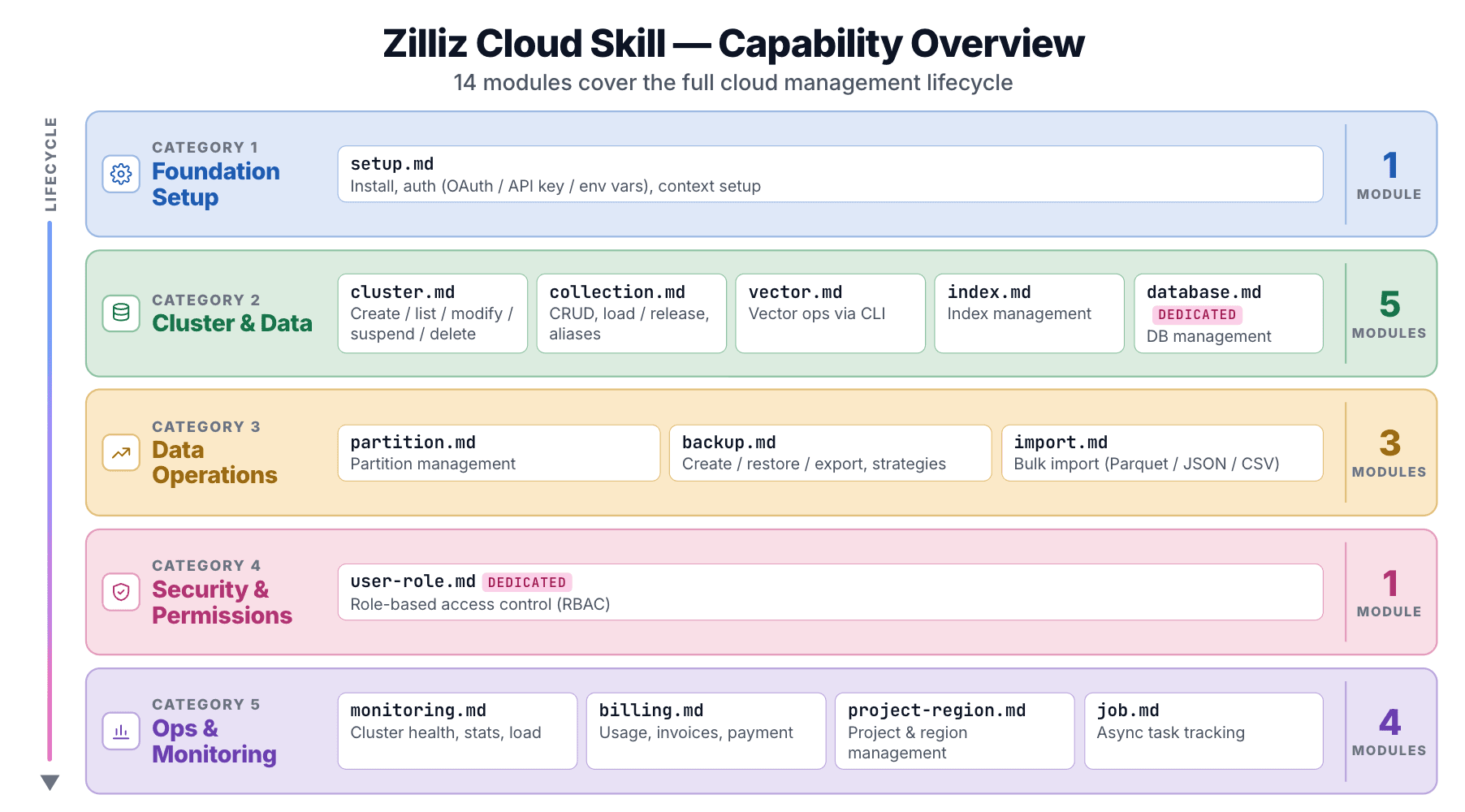
zilliz-plugin リポジトリには 14 のサブ Skill が同梱されており、それぞれ skills/<name>/SKILL.md 配下にあります。
| モジュール | 対象 |
|---|---|
setup | インストール、認証(OAuth / API Key / env var)、コンテキスト設定 |
cluster | 作成、一覧表示、変更、一時停止、再開、削除 |
collection | コレクションのCRUD、ロード/リリース、エイリアス |
vector | CLI経由のベクトル操作 |
index | インデックス管理 |
database | データベース管理(Dedicatedのみ) |
partition | パーティション管理 |
user-role | RBAC(Dedicatedのみ) |
backup | 作成、復元、エクスポート、バックアップポリシー |
import | クラウドストレージからの一括インポート(Parquet / JSON / CSV) |
billing | 使用量、請求書、支払い方法 |
monitoring | クラスターの状態、統計、ロード状態 |
project-region | プロジェクトおよびリージョン管理 |
job | 非同期タスクの追跡 |
クラスターの起動、バックアップ保持期間の設定、請求書の確認:14個のモジュールが、Zilliz Cloudコンソールのあらゆる操作をカバーします。
ティア認識が組み込まれています。databaseとuser-roleにはDedicatedのみというフラグが付いています。このSkillは、Free、Serverless、Dedicatedの各ティアで機能が異なることを認識しているため、エージェントはクラスターのティアがサポートできない操作を試みません。
すべてのモジュールに共通する3つの安全ルール
Zilliz Cloud Skillの安全設計は、Milvus Skillよりもさらに何層も深くなっています。個々のSKILL.mdファイル全体に、3つのコアルールが現れます:
- 破壊的な操作には、ユーザーの明示的な確認が必要です。 クラスターモジュールのガイダンスには、"Before deleting a cluster, always confirm with the user — this is irreversible." とあります。すべての破壊的操作(コレクション、バックアップ、データベース、ユーザー)に同じ指示があります。
- 機密性の高いコマンドは、ユーザー自身のターミナルで実行されます。
setupモジュールは明示的です:"Login commands (zilliz login, zilliz configure) require an interactive terminal and CANNOT run inside Claude Code. Always instruct the user to run these in their own terminal." 認証情報がエージェントを経由することはありません。 - 認証情報は決して表示されません。 認証は、OAuthブラウザーフロー、コンソールからのAPIキー、または
ZILLIZ_API_KEYenv varを通じて行われます。このSkillはシークレットを出力しません。
これらは基本的に聞こえますが、Cloud認証情報を持ち、確認レイヤーのないエージェントは、「テストクラスターを片付けて」という指示で本番環境を破壊してしまう可能性があります。このSkillは、破壊的なコマンドがAPIに到達する前に、指示レイヤーでそのギャップを埋めます。
前提条件ゲート:コマンド実行前の3つのチェック
すべてのサブスキルは、skills/setup/SKILL.mdで定義された3ステップのチェックを実行します:
zilliz-cliがインストール済みか? そうでない場合は、インストールする。- ユーザーはログイン済みか? そうでない場合は、認証へルーティングする。
- クラスターコンテキストは設定済みか? そうでない場合は、選択を促す。
このゲートにより、コマンドが実行される前に環境が準備できていることが保証されます。これは、手探りで実行して後からエラーをデバッグするよりも信頼性が高い方法です。
なぜ単なるMCPではなくZilliz Skillsなのか?
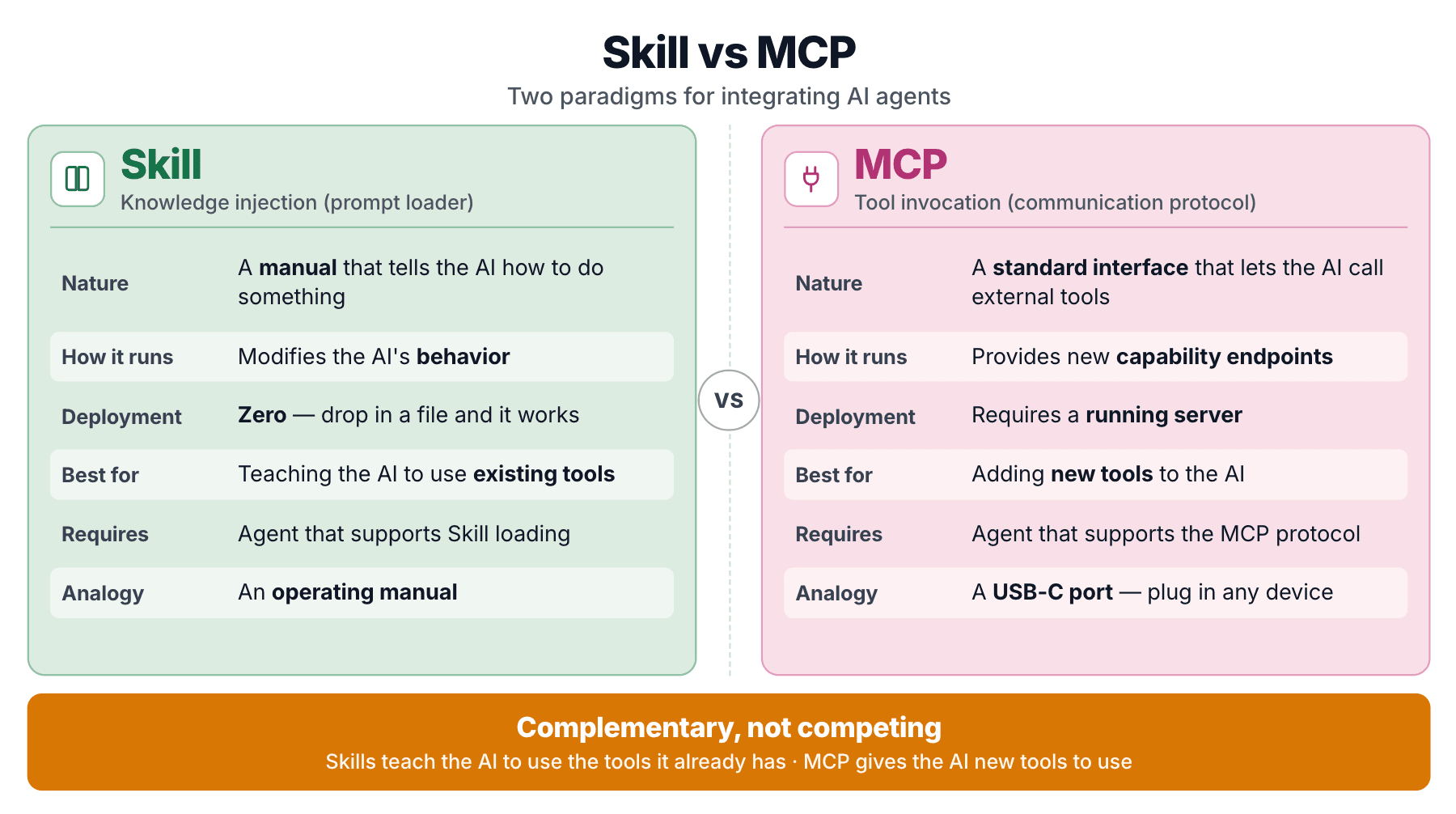
Zillizが両方を提供するのは、それぞれ異なる問題を解決するためです。 Skillは、エージェントがコードを書くときに参照する知識を注入します。MCPサーバーは、エージェントが呼び出せる呼び出し可能なエンドポイントを公開します。mcp-server-milvusはMCP側であり、Milvus Skillは知識側です。両者は競合するのではなく、レイヤーとして重なります。
Skillはプロンプトローダー
最小限のSkillは、フォルダーとSKILL.mdです:
my-skill/
├── SKILL.md # instructions + metadata
├── references/ # reference docs (optional)
├── scripts/ # executable scripts (optional)
└── assets/ # templates, resources (optional)
SKILL.mdは取扱説明書です。特定のタスクをどのように扱うかをエージェントに伝えます。実行可能コードもサーバープロセスもありません。必要に応じてモデルのコンテキストに注入される、構造化された知識だけです。
Skillはプロンプトローダーです。構造化されたプロンプトとしてパッケージ化され、動的に読み込まれるドメイン知識です。
MCPはツールプロトコル
MCP(Model Context Protocol)は異なる形を取ります。これは、エージェントが統一されたインターフェースを通じて外部ツールを呼び出せるようにする標準化されたプロトコルです。mcp-server-milvus は、milvus_text_search、milvus_create_collection などのツールエンドポイントを公開する MCP サーバーです。
MCP は「AI エージェントのための USB-C ポート」と表現されてきました。これはツールインターフェースの標準化問題を解決します。
Zilliz Skill vs zilliz MCP
| Dimension | Skill | MCP |
|---|---|---|
| Essence | 知識注入(プロンプト) | ツール呼び出し(プロトコル) |
| What it does | エージェントの振る舞いを変更する | エージェントに新しい能力を与える |
| Deploy cost | ファイルを置けば完了 | サーバープロセスが必要 |
| Fits | エージェントがすでに持っているツールの使い方を教える | エージェントが持っていないツールを与える |
| Dependency | エージェントが Skill の読み込みをサポート | エージェントが MCP をサポート |
重要な違いはこうです。Milvus Skill は、エージェントに pymilvus の使い方を教えます。pymilvus はすでに存在します。Skill は能力を追加するものではありません。エージェントがすでに持っている能力について、正確性を修正するものです。対照的に MCP は、エージェントが他の方法では到達できない呼び出し可能なエンドポイントを与えます。
Skill は、すでに所有している機械の取扱説明書です。MCP は、新しい機械を動かすリモコンです。Zilliz は "Is MCP Dead? MCP vs CLI vs Agent Skills Compared" で直接そう述べています。つまり、両方のパターンは存続します。
とはいえ、Skills は急速に普及しています。コミュニティのトラッカーによると、レジストリ全体で 700,000 以上のパッケージがあり、ClawHub だけでも 5,700 以上のスキルが掲載されています。GitHub 上のある skill-package プロジェクトは、2026 年 4 月の 5 日間で 6,600 スターを獲得しました。
実世界のシナリオ: 開発者が実際にどう使っているか
シナリオ 1: RAG アプリケーションの構築
あなたは RAG アプリを構築しています。Milvus Skill をインストールした状態で、こう言います。
"ドキュメント検索コレクションを作成して: 768 次元ベクトル、BM25 全文検索、title、body、embedding 用のフィールド。"
エージェントは collection.md と patterns.md を参照し、次のように書きます。
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="<URI>", token="<TOKEN>")
schema = client.create_schema(auto_id=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("title", DataType.VARCHAR, max_length=512)
schema.add_field("body", DataType.VARCHAR, max_length=4096, enable_analyzer=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
schema.add_field("body_sparse", DataType.SPARSE_FLOAT_VECTOR)
# Wire BM25 full-text search
schema.add_function(Function(
name="body_bm25",
input_field_names=["body"],
output_field_names=["body_sparse"],
function_type=FunctionType.BM25,
))
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", index_type="AUTOINDEX", metric_type="COSINE")
index_params.add_index(field_name="body_sparse", index_type="AUTOINDEX", metric_type="BM25")
client.create_collection("documents", schema=schema, index_params=index_params)
enable_analyzer=True、BM25 Function の配線、BM25 メトリックと AUTOINDEX の組み合わせ。これらはいずれも、エージェントに推測させたいものではありません。Skill はそれらをエンコードしています。
シナリオ 2: Zilliz Cloud クラスターの管理
"us-east-1 に Serverless クラスターを作成し、その後 768 次元ベクトルのコレクションを作成して。"
エージェントは前提条件チェックを実行し、その後 CLI コマンドを順番に発行します。または:
"すべてのクラスターのステータスとリソース使用状況を表示して。"
エージェントは zilliz cluster list と対応する zilliz monitoring コマンドを実行し、その後要約します。認証情報がターミナルの外に出ることはありません。
シナリオ 3: バックアップとデータ移行
"本番環境向けに毎日のバックアップポリシーを設定し、7 日間保持して。"
backup.md は完全なポリシー構文を文書化しています。エージェントはポリシーを直接設定します。
"test クラスターから orders コレクションを S3 にエクスポートして。"
import.md は、対応フォーマット(Parquet、JSON、CSV)を含む、クラウドストレージからの一括インポートとエクスポートについて扱います。
シナリオ 4: ハイブリッド検索へのアップグレード
「検索を RRF を使った dense + sparse ハイブリッドにアップグレードして。」
エージェントは vector.md の AnnSearchRequest と RRFRanker に関するメモを取り出し、ハイブリッド検索コードを書きます。RRF パラメータを学ぶ必要はありません。
Zilliz のエージェントスタック: 2 つの Skill がどこに位置するか
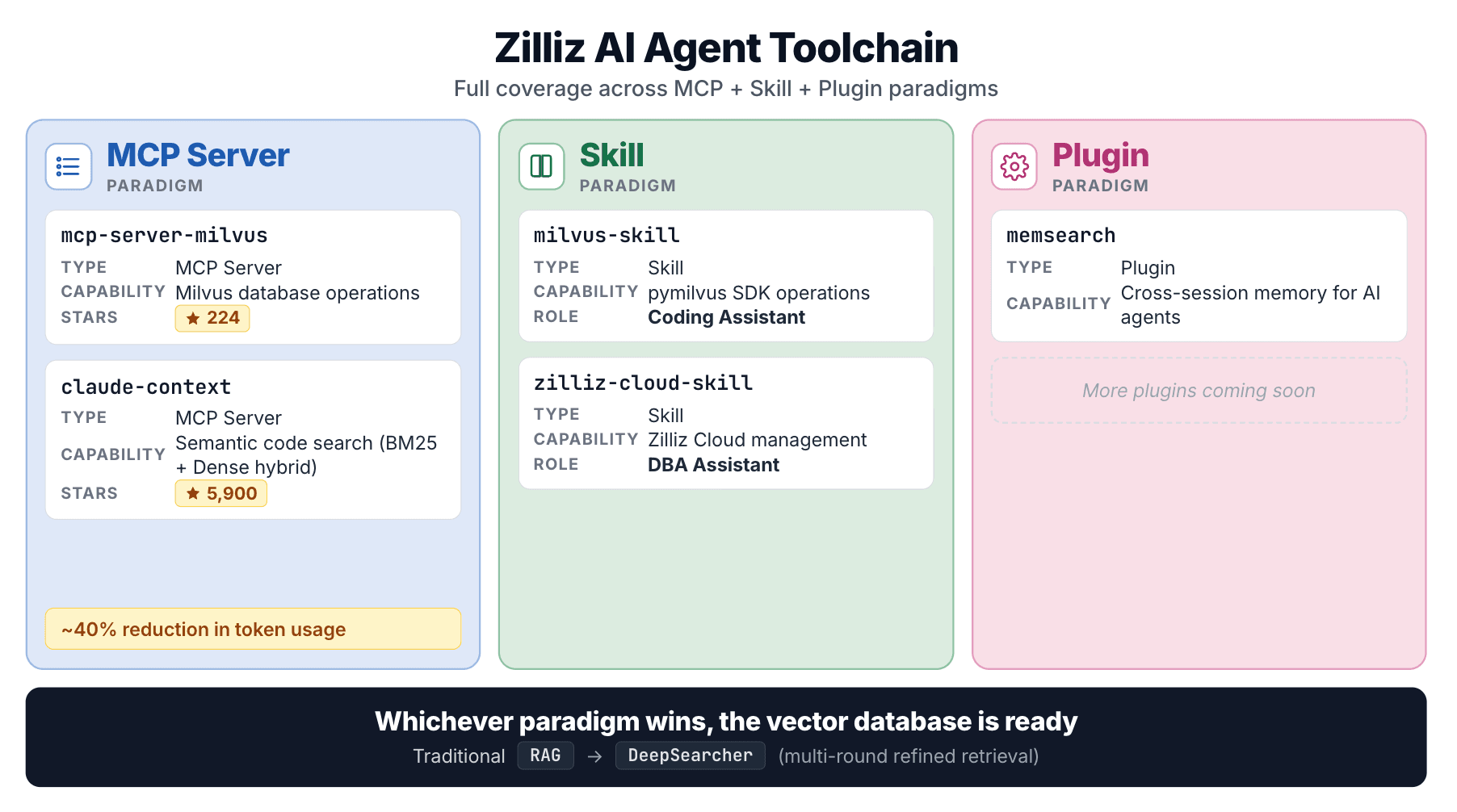
これら 2 つの Skill は、あらゆるエージェント統合パターンにまたがる、より広範な Zilliz の取り組みの中に位置しています。
| Project | Type | Covers |
|---|---|---|
| mcp-server-milvus | MCP Server | Milvus データベース操作 |
| claude-context | MCP Server | セマンティックコード検索 |
| milvus-skill | Skill | pymilvus SDK |
| zilliz-skill | Skill | Zilliz Cloud 管理 |
| DeepSearcher | エージェントフレームワーク | マルチステップのエージェント型 RAG |
claude-context は際立った存在です。コードベースをベクトル DB にインデックス化し、ハイブリッド(BM25 + dense)検索で必要に応じて関連コードを取得し、同等の取得品質のもとで約 40% のトークン削減を報告しています。
MCP から Skill、コード検索、エージェントフレームワークに至るまで、Zilliz の戦略は一貫しています。どのエージェント統合パターンが勝つにせよ、ベクトルデータベースにはファーストクラスの入口があるべきだというものです。2 つの Skill は、そのレーンへの Zilliz の参入です。
結論
Milvus Skill と Zilliz Cloud Skill は、共通する 4 つの設計上の選択に基づいています。
- 2 つの Skill には明確で重複しない役割があります。 Milvus Skill は SDK コーディング層を扱い、Zilliz Cloud Skill は CLI 操作層を扱います。両者を合わせることで、互いに干渉することなく、ベクトルデータベースのライフサイクル全体をカバーします。
- モジュール化された知識ロードによりコンテキストをスリムに保ちます。知識を 7 個および 14 個のリファレンスファイルに分割することで、エージェントはすべてのドキュメントでコンテキストウィンドウを埋め尽くすのではなく、現在のタスクに一致するファイルだけを取得できます。
- Zilliz Cloud Skill は指示レイヤーに安全性を組み込んでいます。 破壊的操作の確認、認証情報の保護、前提条件チェックは、Cloud キーを持つエージェントが本番データベースに対して何を実行できるかをチームが慎重に考えたことを示しています。
- Zilliz は勝者を選ぶのではなく、複数のパラダイムにまたがって備えています。 MCP と Skill の両方の実装を提供することで、エージェント統合エコシステムがどちらの方向に進んでも Zilliz は対応できます。
ベクトル DB を使ってエージェントを構築しているなら、次に RAG アプリを立ち上げたりクラスターを管理したりするときに、両方の Skill をインストールしてください。
はじめに
次回の Claude Code セッションで 2 つの Skill をインストールしてください。
- Milvus Skill — pymilvus の正確性。Milvus Lite、セルフホストの Standalone/Cluster、Zilliz Cloud に対応します。
- Zilliz Cloud Skill —
zilliz-cliを通じたライブクラスター管理。CLI もあわせてインストールしてください。
まだクラスターを持っていない場合は、Zilliz Cloud にサインアップ(新しい仕事用メールアカウントには無料クレジットが付与されます)するか、サインインしてから、Skill を Claude Code に貼り付ければ、あとはエージェントが進めてくれます。
さらに読む
- "MCPは死んだのか?" — CLIとSkillsがMCPと並んでどこに位置づけられるかについてのZillizの見立て。
- Milvus SDK Code Helper — Milvus Skillに対応するMCP版で、同じ古いpymilvus問題を別の角度から扱うもの。
claude-context— 約40%のトークン削減を報告しているセマンティックなコードベース検索。- 製品全体については、Milvus docsとZilliz Cloudを参照。
読み続けて

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.