




Vector Lakebaseを構築した理由:AIのための非構造化データアーキテクチャの再考
最近、私たちはZilliz Vector Lakebaseを発表しました。これは、Zilliz Cloudを純粋なベクトルデータベースシステムから、AIワークロードのための統合されたレイクネイティブなデータ基盤へと進化させる次のステップです。この発表は大きな関心を集めました。同時に、Zillizがどこへ向かっているのかについて、ほぼ即座に疑問も浮上しました。
Zillizはベクトルデータベースから離れようとしているのか? あるいは、もっと直接的に言えば、ベクトルデータベースはすでに時代遅れになりつつあるのか?
こうした疑問が出てきた理由は理解できます。長年にわたり、Zillizは本番環境対応のベクトルデータベースシステム(オープンソースのMilvusとフルマネージドのZilliz Cloud)を構築する企業として知られてきました。そのため、私たちがAIのためのレイクネイティブなデータ基盤への進化について語り始めたとき、これが方向転換を意味するのではないかと考えた人がいたのは自然なことです。
短い答えはNOです。断じて違います。 むしろ、Vector Lakebaseは、ベクトルデータベースが成功した後に何が起こるのかに対する私たちの答えです。
過去数年間で、ベクトルデータベースはAIスタックの基盤となるインフラ層の一つになりました。約10年前にMilvusを始めたときには想像できなかったほどの速さで採用が進みました。このカテゴリーは確かなものであり、セマンティック検索の必要性はますます重要になっています。
しかし同時に、私たちには別のことも明らかになりました。ベクトル検索はもはや問題のすべてではありません。
AIシステムが静的なアシスタントから継続的に稼働するエージェントへと移行するにつれ、企業は非構造化データインフラに対して、より広い機能を求めるようになっています。企業は単に情報を検索できるシステムを求めているわけではありません。データを改善し、再編成し、分析し、洗練し、その改善を本番環境へフィードバックできるシステムを求めています。これはアーキテクチャを変化させます。
この変化は、インフラの歴史における以前のサイクルを思い起こさせます。モバイルインターネット時代におけるデータベースの進化です。詳細は異なりますが、パターンは見覚えのあるものです。新しい種類のアプリケーションが新しい種類のデータ圧力を生み出す。第一世代のインフラは、目の前のサービング問題を解決する。そしてデータが増えるにつれて、アーキテクチャは拡張しなければならなくなる。
ベクトルデータベースは今まさに、その次の段階に入りつつあるのだと思います。
モバイルインターネットはすでに一度このサイクルを経験している
2010年前後、モバイルアプリケーションが爆発的に普及する中で、MongoDBはその時期を代表するインフラ製品の一つになりました。
理由は明快でした。モバイルアプリケーションは、ユーザーイベント、ソーシャル活動、デバイステレメトリ、行動シグナル、プロダクトログといった大量の半構造化データを生成しました。これらはいずれも、当時ほとんどのチームが使用していたリレーショナルデータベースのパターンにはきれいに収まりませんでした。プロダクトチームは高速にリリースを続け、スキーマは絶えず変化し、最初の課題は単に、アプリケーションの速度を落とさずにデータを受け入れることでした。MongoDBはその目の前の問題を非常にうまく解決しました。まずデータを取り込む。構造化と分析は後から行えばよい、というわけです。

数年後、業界は別の問いを投げかけ始めました。これだけのデータが存在するようになった後、企業は実際にそれをどのように活用できるのか? この変化は、SnowflakeやRedshiftのような現代的なデータウェアハウスの台頭を後押ししました。焦点は運用ストレージから分析的洞察へと移りました。企業はBIレポート、ユーザーコホート、アトリビューション、予測、成長分析を求めるようになりました。データは単なる運用上の副産物ではなくなり、ビジネス資産になりました。
そして、別のボトルネックが現れました。
トランザクションシステムと分析システムの分断は、ますます大きな痛みとなりました。OLTP環境とOLAP環境の間のデータパイプラインは脆弱で、高コストで、運用上非常に負担の大きいものでした。同じデータセットがシステム間で繰り返しコピーされ、多くの場合、同期の遅延や微妙な不整合を伴っていました。
それが、Lakehouseアーキテクチャを生み出した環境でした。Databricks、Iceberg、Hudi、および関連するシステムはすべて、同じ基本的な考え方へと収束していきました。つまり、データの単一の論理コピーが、システム間で際限なく移動することを必要とせずに、複数の計算モデルをサポートすべきだという考え方です。
振り返ってみると、その進展はほとんど必然だったように感じられます。しかし当時は、そのどれもが明らかではありませんでした。MongoDBの台頭がSnowflakeを予見していたわけではありません。SnowflakeがLakehouseを予見していたわけでもありません。それぞれの移行は、前世代のインフラが大規模に成功し、その結果として新たな制約の種類を露呈したために生まれたのです。
このパターンが重要なのは、AIインフラがますます同じような道をたどっているように見えるからです。
検索は最初の問題を解決したが、最後の問題ではなかった
2023年に大規模言語モデルが主流として普及し始めたとき、ベクトルデータベースは最も早く注目を集めたインフラカテゴリの1つになりました。その理由は実用的なものでした。RAGシステムには、埋め込みを保存し、セマンティック検索を実行するためのネイティブな方法が必要でした。従来のデータベースの多くは、高次元ベクトル検索、ANNインデックス、ハイブリッド検索、そして大規模環境での低レイテンシなフィルタリングを目的として設計されていませんでした。
多くの意味で、ベクトルデータベースは、以前にMongoDBが解決したのと同じ種類の問題を解決しました。新しいアプリケーションパターンが新しいデータ抽象化を生み出し、開発者はそれをサポートできるインフラを必要としました。今回、その抽象化はセマンティック表現でした。つまり、ニューラルモデルによって非構造化データから生成される埋め込みです。
その最初の導入フェーズは非常に急速に進みました。しかしわずか数年後、私たちが顧客から聞く質問ははるかに複雑になっています。彼らはもはや、ベクトルを効率的に検索する方法だけを尋ねているわけではありません。彼らはこう尋ねます。
- トレーニングデータを継続的に重複排除し、精緻化するにはどうすればよいか?
- クラスタリングや品質上の問題を見つけるために、数十億の埋め込みをどのように分析すればよいか?
- マルチモーダルデータセットにおけるドリフト、バイアス、または冗長性をどのように特定すればよいか?
- エージェントの実行履歴をどのように追跡し、最適化すればよいか?
- モデルの進化に合わせて、データをどのように再処理し改善すればよいか?
- すべてのコンピュートを常時稼働させ続けることなく、コールドデータをどのように検索すればよいか?
- すでにIceberg、Lance、Parquet、オブジェクトストレージに存在するデータを、複数のAIワークロードにどのように活用すればよいか?
これらはもはや純粋な検索の問題ではありません。大規模なオフライン処理、反復的な発見ワークフロー、データガバナンス、分析的探索、そしてオンラインシステムとオフライン計算の間の継続的なフィードバックループを必要とします。高度なAIチームの間で、私たちは次第に重要なことに気づくようになりました。ボトルネックはもはや単なるモデル能力ではなく、反復速度だったのです。
ある経験によって、このことは痛いほど明白になりました。大規模なベクトルデータセットを再処理しようとしているチームを目にしました。埋め込みの再クラスタリング、重複の除去、インデックスの再生成、コーパス全体の再埋め込みです。場合によっては、10億個のベクトルをあるシステムから別のシステムへ移動するだけで数日かかることもありました。数時間ではありません。数日です。
一方で、先進的なAIチーム内の反復サイクルは逆方向に進んでいます。研究者は継続的に実験したいと考えています。データエンジニアは、データセットをより速くクリーンアップし、評価し、更新するようプレッシャーを受けています。モデルは改善します。埋め込みモデルは変化します。エージェントは毎日新しいトレースを作成します。しかし、それらの下にあるインフラスタックは、非構造化データに対する継続的な精緻化ループを目的として設計されていませんでした。
そこが、業界がこの問題をあまりにも狭く捉えているのではないかと私たちが考え始めた地点でした。
非構造化データインフラは、単なる検索レイヤーではありません。それは継続的に稼働するシステムになりつつあります。
検索システムから継続的システムへ:CS/CD
社内では、このアーキテクチャをサービングと発見の間の継続的なループとして説明し始めました。時間が経つにつれて、私たちはそれをCS/CD、すなわちContinuous Serving and Continuous Discoveryと呼ぶようになりました。
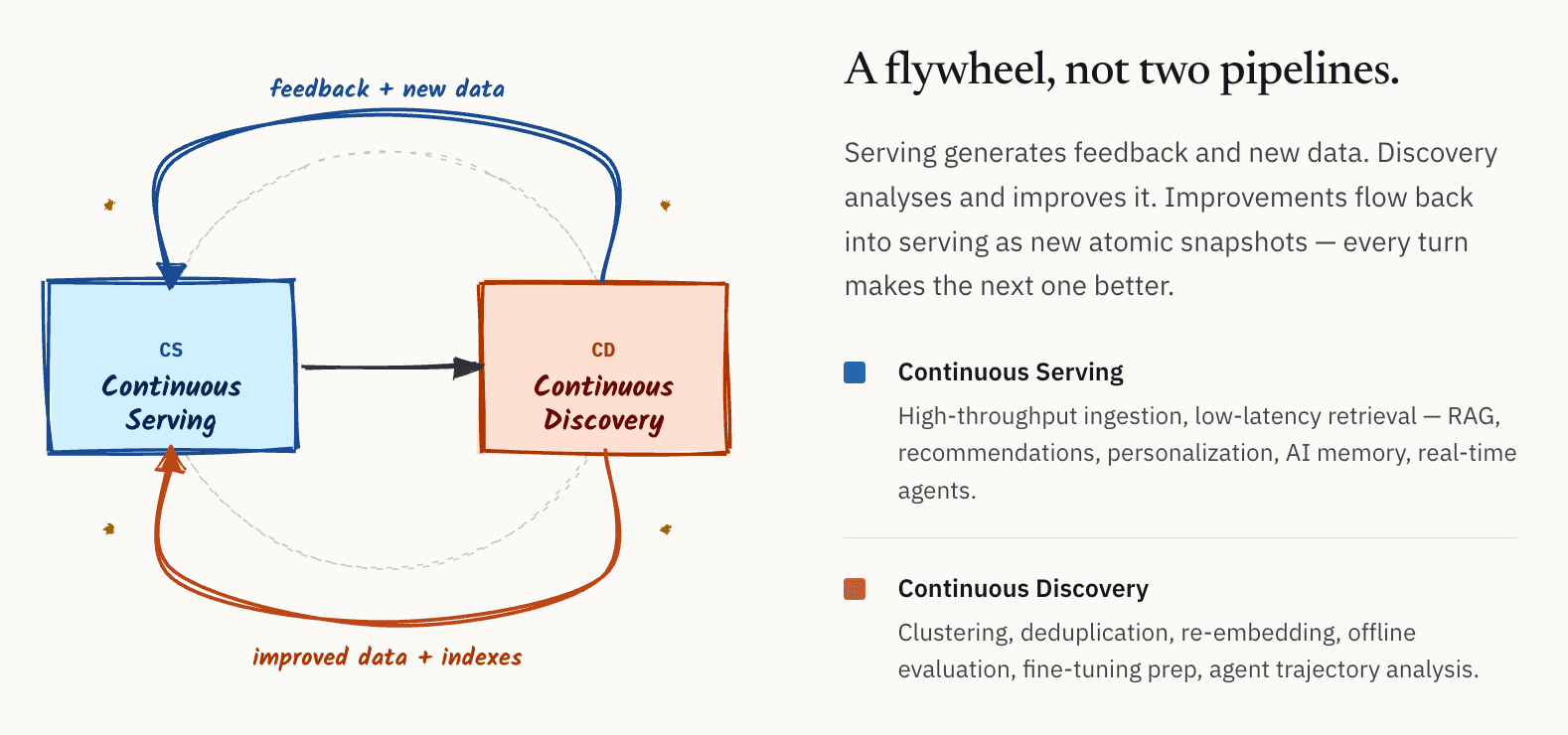
概念としてはシンプルな考え方です。
- 一方には、サービングレイヤーがあります: オンラインRAGシステム、レコメンデーションシステム、パーソナライゼーション、AIメモリ、リアルタイムエージェント向けの、高スループットな取り込みと低レイテンシな検索。
- もう一方には、ディスカバリーレイヤーがあります: クラスタリング、重複排除、再埋め込み、オフライン評価、品質分析、モデルのファインチューニング準備、エージェント軌跡分析。
重要なのは、これらが独立したワークフローではないという点です。これらはフライホイールを形成します。サービングシステムは継続的にフィードバックと新しいデータを生成します。ディスカバリーシステムはそのデータを分析し、改善します。その結果として得られる改善、つまり、より優れた埋め込み、よりクリーンなデータセット、改善されたインデックス、洗練されたメタデータが、再びサービングレイヤーに流れ込みます。
各イテレーションは次のイテレーションを改善するはずです。少なくとも理論上は。
実際には、基盤となるインフラが依然として断片化しているため、ほとんどの組織はこのループを効率的に運用できていません。
現在、チームが本番環境のベクトルデータに対して大規模なオフライン処理を行いたい場合、典型的なワークフローはいまだに非常に手作業が多いものです。まず、データをベクトルデータベースからレイクまたはバッチ環境へエクスポートしなければなりません。通常、インデックスは再利用できません。同期パイプラインは壊れやすくなります。増分更新は困難です。処理済みの結果は最終的にサービングシステムへ再インポートする必要があり、その際、新しいデータと新しいインデックスの間にアトミックな整合性保証がないことも少なくありません。
その結果、ワークフローは遅く、脆く、コストの高いものになります。そして維持コストがあまりにも高いため、多くの組織は継続的なディスカバリーを単純に避けています。データはそこに存在し、検索可能ではあるものの、大部分は探索されないままです。
これは、OLTPシステムとOLAPシステムの歴史的なギャップをますます思い起こさせるものでした。ただし現在の断片化は、オンラインのセマンティック検索とオフラインの非構造化データ処理の間にあります。
既存アーキテクチャが最終的に限界に達する理由
私たちがますます確信するようになったことの一つは、現在のインフラスタックのどちらの側も間違っているわけではないということです。
ベクトルデータベースとLakehouseシステムは、どちらも重要な問題を解決しています。問題は、それぞれのアーキテクチャが、新たに現れているワークロードの片方の半分だけを中心に最適化されていることです。
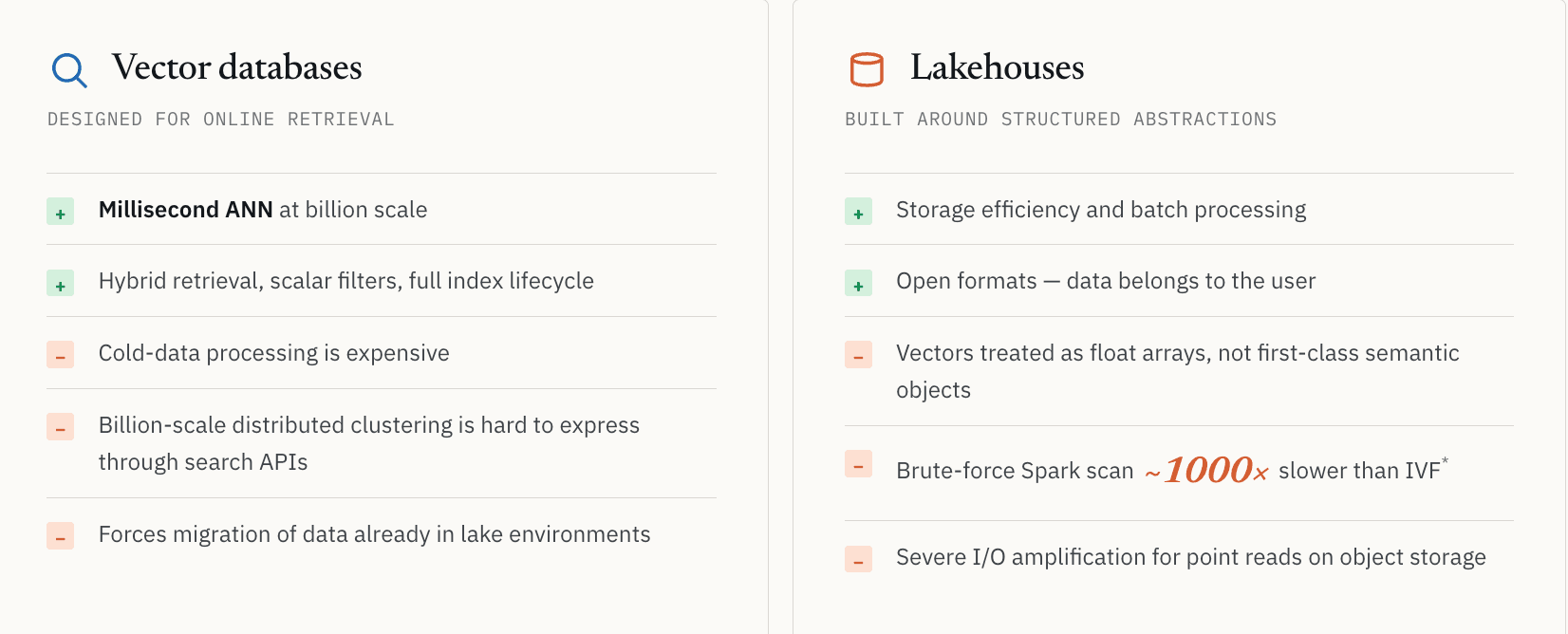
ベクトルデータベースは主にオンライン検索向けに設計されていました。
オープンソースのMilvusを例に取ってみましょう。これは大規模なベクトル検索を非常にうまく解決します。しかしワークロードがサービングを超えて大規模なディスカバリーへ移行すると、自然なアーキテクチャ上の境界が現れます。
コールドデータ処理は高コストになります。10億規模の分散クラスタリングをオンライン検索APIを通じて表現するのは困難です。多くのシステムでは、クエリ可能な状態を維持するためにはデータをオンラインインフラにロードしたままにしておく必要があると想定されています。すでに大規模な非構造化データセットをレイク環境に保存している企業は、すべてを専用の検索システムに移動するよう求められると、移行コストとガバナンスの断片化に直面します。
これらは実装上のバグではありません。低レイテンシなオンライン検索に最適化した結果です。
Lakehouseはストレージ効率とバッチ処理を解決しますが、構造化データの抽象化を中心に設計されていました
反対に、Lakehouse側から出発するアプローチでは、別のトレードオフが生じます。
Lakehouseはストレージ効率とバッチ処理を洗練された形で解決します。しかし、それらは構造化データの抽象化を中心に設計されていました。ほとんどのレイクアーキテクチャでは、ベクトルはいまだに第一級のセマンティックオブジェクトではなく、長い浮動小数点数の配列として扱われています。Parquetのようなファイル形式は、ANNインデックス、転置インデックス、低レイテンシなセマンティック検索パスを中心に設計されたものではありません。
これは、分子類似性検索を行っている製薬会社のお客様で直接確認しました。レイクデータ全体に対する総当たりの Spark スキャンは、IVF ベースの検索を用いたインデックス付きベクトル検索よりも、およそ 1000 倍遅いものでした。正確な数値は、データ分布、インデックスパラメータ、ハードウェアによって異なりますが、教訓は一貫しています。適切なインデックスがなければ、多くのセマンティックワークロードは経済的に実用的ではありません。
さらに、より基本的なストレージの問題もあります。オブジェクトストレージは、検索指向のワークロードに対して深刻な I/O 増幅を引き起こす可能性があります。セマンティック検索では多くの場合、少数の ID が見つかりますが、アプリケーションはそれらの ID の背後にある完全なレコードを必要とします。従来のカラムナ形式では、少数の小さなレコードを取得するために、大きなストレージブロックを読み取らなければならないことがあります。これはスキャンには適しています。しかし、低レイテンシのサービングには不向きです。
時間が経つにつれて、私たちの結論は避けがたいものになりました。業界は、ベクトルデータベースとレイクアーキテクチャのどちらかを選ばなければならない状況にあるべきではありません。必要なのは、検索と大規模な発見が同じ運用システムのネイティブな一部であるアーキテクチャです。
Vector Lakebase とは何か
その気づきが、現在私たちが Vector Lakebase と呼んでいるものへとつながりました。中核となる考え方は、「ベクトルデータベースにデータレイクを足したもの」ではありません。私は、その捉え方はより深いアーキテクチャ上のポイントを見落としていると思います。
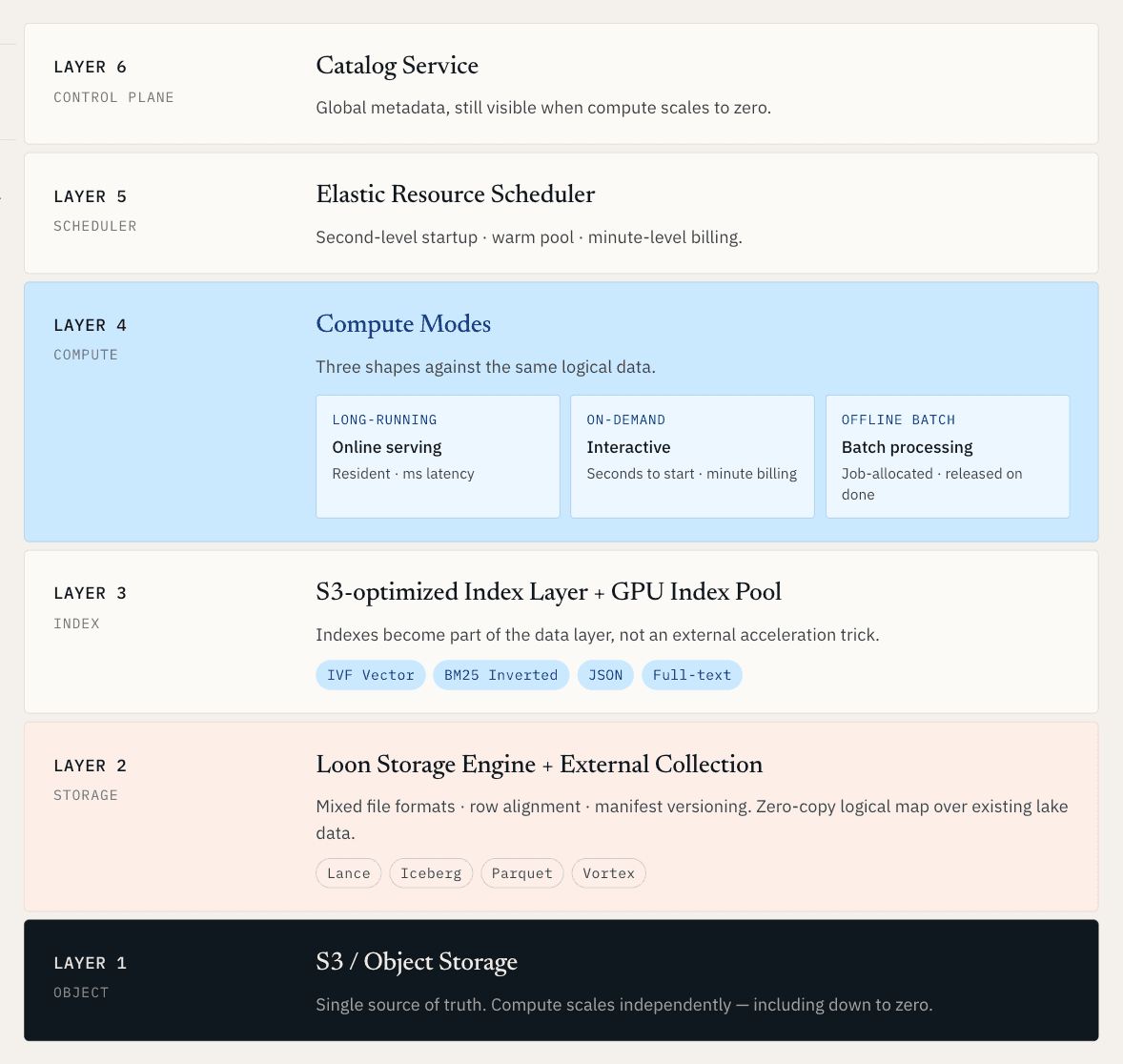
目標は、非構造化データのための統一された運用レイヤーを作ることです。そこでは、オンラインサービング、オフライン発見、エラスティックコンピュートのすべてが、同じ論理データ基盤に対して動作します。
生データについては、ベクトル、ドキュメント、メタデータ、ログ、インデックスが、レイクネイティブなストレージ上でまとめて管理されることを意味します。すでに Iceberg、Lance、Parquet、またはオブジェクトストレージに存在するデータについては、完全な移行を強制することなく、そのデータをマッピングし、インデックス化できることを意味します。
その要件から出発すると、アーキテクチャは複数の難しい問題を同時に解決しなければなりません。コンピュートはストレージから独立してスケールする必要があります。インデックスは外部の高速化トリックではなく、データレイヤーの一部になる必要があります。新しいデータと新しいインデックスは、一貫したスナップショットとして一緒に公開される必要があります。そして、既存のレイクデータは、別のコピーを作成することなく検索可能になる必要があります。
これらの考え方は単純に聞こえます。ベクトルデータベースに期待される性能を維持しながらそれを実現することこそが難しい部分です。そこで、より低レベルのエンジニアリング上の判断が重要になり始めます。
ストレージとコンピュートを分離するコストと、それにどう対処するか
ストレージとコンピュートの分離は CS/CD ループに必要ですが、無料ではありません。
遅いコールドスタート
コンピュートをゼロまでスケールダウンできる場合、オンデマンドまたはオフラインのワークフローにおける最初のクエリは、完全にコールドなデータに当たる可能性があります。ノードにはローカルインデックスも、ウォームキャッシュも、常駐データもありません。すべてをオブジェクトストレージから取得しなければなりません。
小規模なデータセットであれば、これは管理可能です。大規模なベクトルワークロードでは、すぐに受け入れがたいものになります。10 億個の 768 次元ベクトルを考えてみてください。従来の HNSW インデックスは約 340 GB になることがあります。そのインデックス全体を S3 から取得するには 4 分以上かかる可能性があります。検索を開始する前に 4 分も待ちたい人はいません。
私たちの答えは、コールドパスを大幅に小さくすることです。 RaBitQ スタイルの 1+3 ビット量子化を用いることで、およそ 340 GB のインデックスを約 13 GB まで圧縮できます。検索は 2 段階で実行されます。第 1 段階では、粗いフィルタリングに 1 ビット表現を使用し、データサイズを元の約 30 分の 1 に削減しながら、およそ 85〜90 パーセントの再現率を実現します。第 2 段階では、1+3 ビット表現を使って結果を再ランキングし、約 95 パーセントの再現率まで精緻化します。これにより、コールドスタートは数分からおよそ 5〜10 秒まで短縮されます。
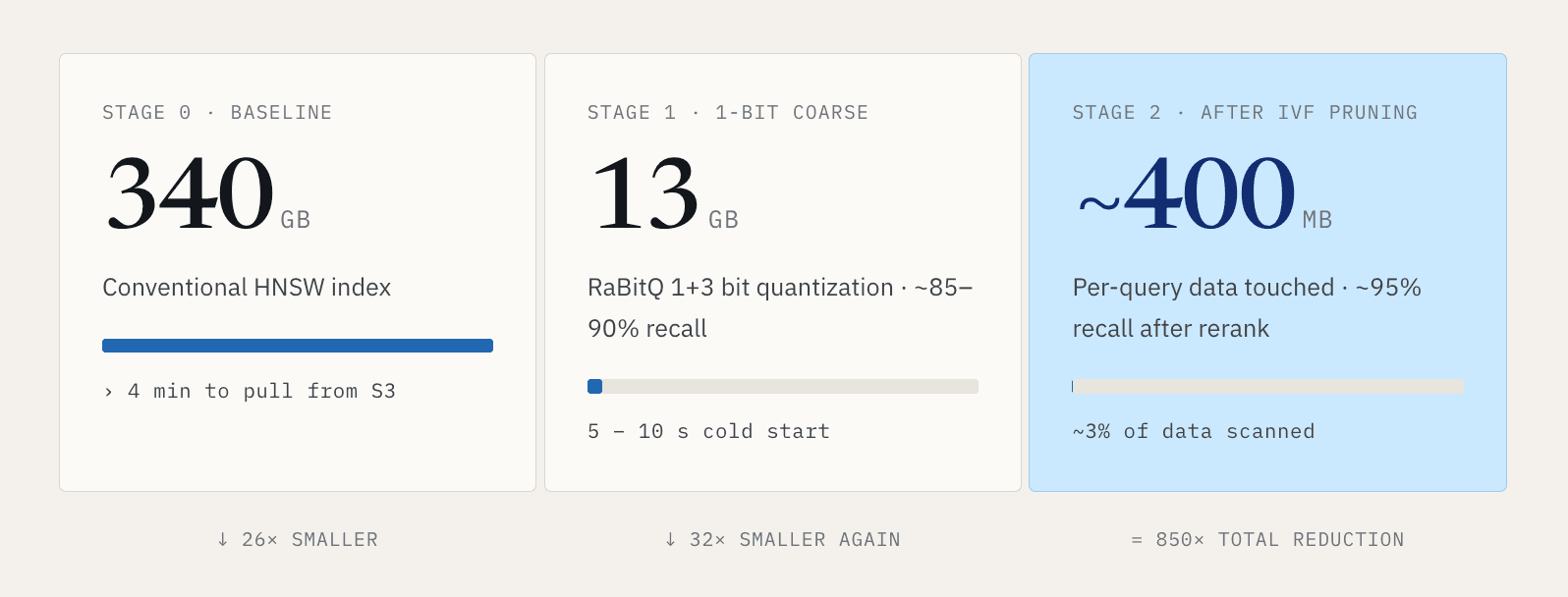
次に、クエリごとに触れるデータ量を削減するために IVF クラスタリングを使用します。代表的な構成では、各クエリはデータの約 3% をスキャンします。流れは次のようになります。従来型インデックス 340 GB を 13 GB に圧縮し、プルーニング後に単一クエリが触れるのはおよそ 400 MB です。
これは、アイデアとしての弾力的なベクトル検索と、利用可能なシステムとしての弾力的なベクトル検索の違いです。
I/O 増幅
コールドスタートは問題の一面にすぎません。もう一方はレコードアクセスです。
ベクトル検索は ID を返します。しかし、アプリケーションには完全なレコードが必要です。テキストチャンク、メタデータ、ドキュメントポインタ、権限、タイムスタンプ、画像属性、またはその他のフィールドです。標準的な Parquet レイアウトでは、小さなポイント読み取りでも、システムが大きな行グループをダウンロードせざるを得ない場合があります。クエリに必要な有用データは数キロバイトだけなのに、オブジェクトストレージから数十メガバイトを取得することになりかねません。行グループを小さくするとポイント読み取りには役立ちますが、圧縮率とスキャン効率は低下します。
だからこそ私たちは、Zilliz Vector Lakebase の背後にある再構築されたストレージエンジンである Loon を構築しました。
Loon は、混合ファイル形式、行アライメント、マニフェストベースのバージョニングを使用します。スカラー フィールドは、フィルタリングとスキャンに効率的なままのカラムナレイアウトを使用できます。ベクトル フィールドやポイントクエリが多いデータは、低レイテンシの取得により適したレイアウトを使用できます。カラムグループは行 ID を揃えるため、システムはネットワーク経由で大きな無関係のブロックを引きずることなく、必要なフィールドを取得できます。
内部では、Loon は Linux Foundation 傘下のオープンソースファイル形式である Vortex を使用しています。Vortex は、大きな無関係ブロックを展開せずにポイントクエリを実行することを含め、柔軟なレイアウトとネストされたエンコーディングをサポートします。
300 万行、128 次元ベクトル、S3 ストレージ、256 の同時リーダーを用いたある社内テストでは、Parquet のポイント読み取りは 1 回の読み取りあたり約 9.4 MB をダウンロードしました。Vortex は約 0.07 MB をダウンロードしました。これはダウンロードデータ量の 135 倍の削減です。 その構成では、フルスキャンのスループットも高くなりました。
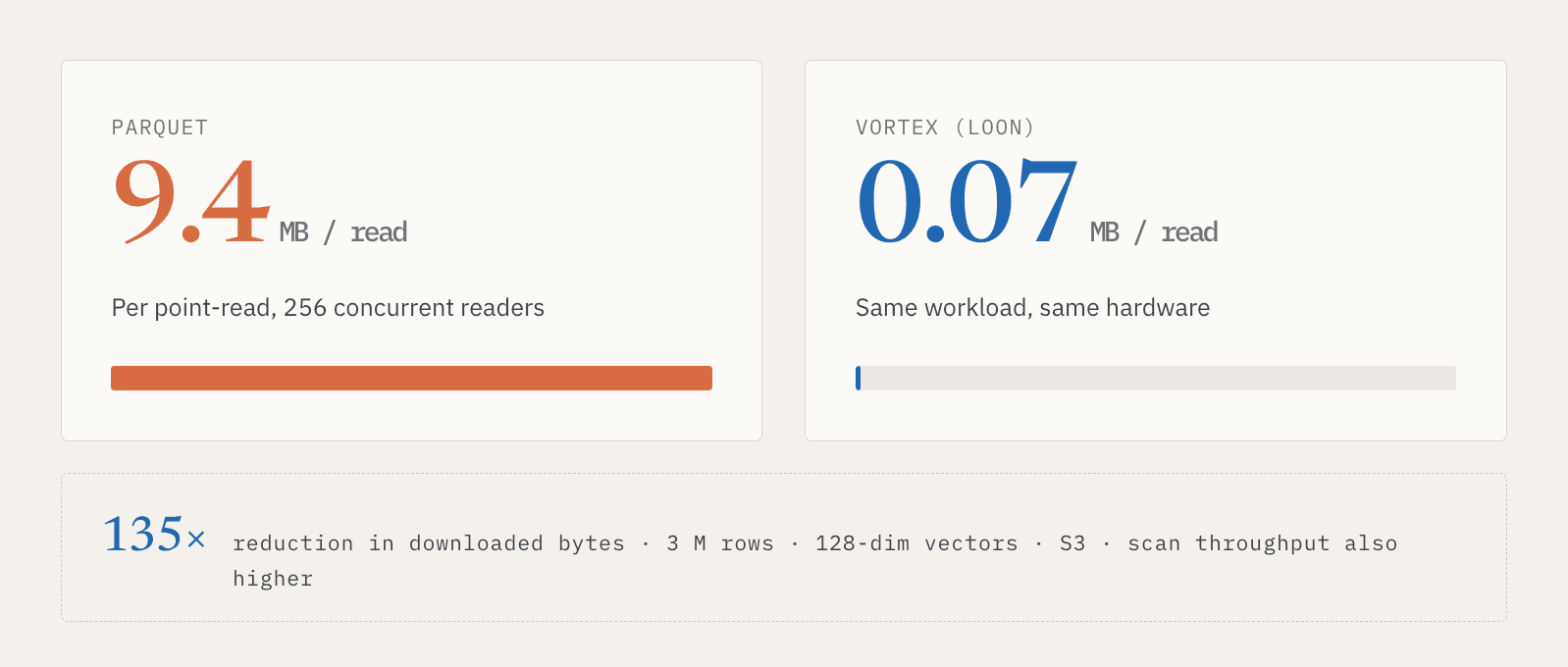
要点は、あるフォーマットがあるベンチマークで速いということだけではありません。要点は、サービングと探索が、同じ論理データに対して異なるアクセスパターンを必要とするということです。オンラインシステムには高速なポイント読み取りが必要です。バッチシステムには効率的なスキャンが必要です。Vector Lakebase は、ユーザーにデータのコピーを 2 つ維持することを強いることなく、その両方をサポートしなければなりません。
Vector Lakebase: 1 つのデータ基盤、複数のコンピュートモード
データレイヤーが共有されるようになると、コンピュートは万能型では対応できません。
AI ワークロードによって、その形は大きく異なります。終日予測可能な低レイテンシを必要とするものもあります。10 分間のインタラクティブな検索セッションを必要とするものもあります。夜間に実行されてから消える大規模なバッチジョブを必要とするものもあります。
だからこそ Zilliz Vector Lakebase は 3 つのコンピュートモードをサポートしています。
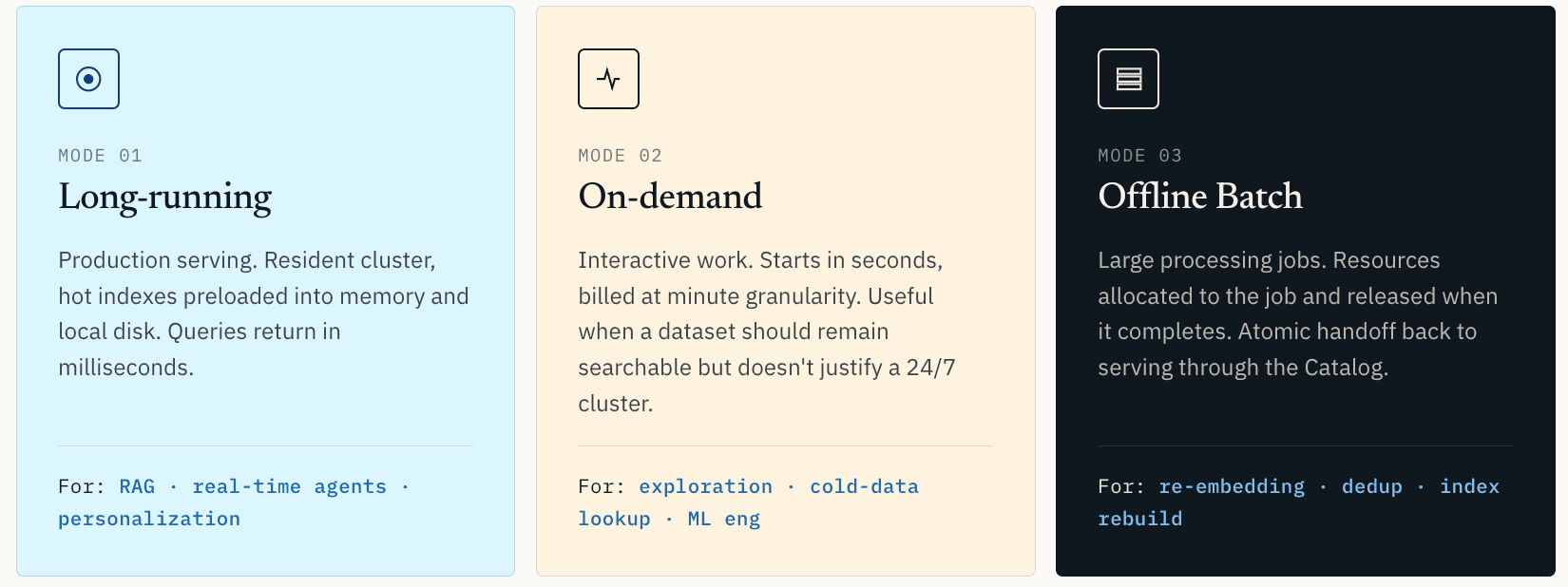
- Long-running compute は本番環境でのサービング向けです。 クラスタは常駐し続けます。ホットなインデックスとデータはメモリとローカルディスクに事前ロードされます。クエリはミリ秒単位で返ります。これは、本番 RAG、リアルタイム推薦、パーソナライゼーション、オンラインエージェント、そしてレイテンシがユーザー体験の一部となるあらゆるワークロードに適したモードです。
- On-demand compute はインタラクティブな作業向けです。数秒で起動し、分単位の粒度で課金されます。これは、類似性の探索、異常の調査、コールドデータの取得、またはデータセットを検索可能に保つべきだが 24/7 クラスタを正当化できない ML エンジニアリングワークフローに有用です。
- Offline Batch compute は大規模な処理ジョブ向けです: ベクトルクラスタリング、学習データの重複排除、全面的な再埋め込み、インデックス再構築、データ品質スキャンなどです。リソースはジョブに割り当てられ、ジョブ完了時に解放されます。
サービングへのハンドオフは、新しいスナップショットとしてCatalogを通じて行われます。サービングは、新しいデータとインデックスの準備が整うまで古いスナップショットを読み続けます。その後、新しいバージョンがアトミックに可視化されます。このアトミックな切り替えは重要です。Discoveryは、半完成のインデックスや不整合なデータを露出させることなく、改善を本番環境へ戻せる場合にのみ有用です。
 architecture.png
architecture.png
ある顧客事例は、この違いがなぜ重要なのかを示しています。ある自動運転の顧客は、10億個の768次元ベクトルを持っていましたが、オンラインクエリ時間は1日あたり約20分しか必要としていませんでした。ワークロードを長時間稼働クラスターとして実行すると、月額コストはおよそ$7,000でした。これをオンデマンドモードに移行したことで、月額コストは約$500まで削減されました。同じ顧客には重複排除ワークフローもあり、以前はANN検索を1つずつ行うのに約70時間かかっていました。これをオフラインバッチジョブとして作り直すことで、同じリソースクラス上で計算時間を約10時間まで削減しました。

教訓は、あるコンピュートモードが別のモードより優れているということではありません。教訓は、AIデータワークロードは1つの形ではなく、アーキテクチャがそれらを1つの形に押し込むべきではないということです。
リソーススケジューリングはVector Lakebaseの一部になる
3つのコンピュートモードが機能するのは、リソーススケジューリングがコンピュート自体と同じくらいエラスティックである場合に限られます。
従来のデータベーススケジューラーは通常、固定されたマシンプールを前提としています。これらのノードが与えられると、システムはデータをどこに配置するか、負荷をどう分散するかを決定します。このモデルは、ワークロードが安定している場合にはうまく機能します。しかし、オンデマンド検索セッション、コールドデータの短時間の検査、夜間の重複排除ジョブ、その後何時間も何もない、といったバースト的に現れるAIワークロードには適していません。
その世界では、より良い問いは、データをどこで実行すべきかだけではありません。そもそもコンピュートを稼働させるべきかどうかです。
これが、Vector Lakebaseがデータとリソースを一緒にスケジュールしなければならない理由です。 実際には、準備済みノードのWarm Poolを維持し、作業が到着したらデータを迅速にアタッチし、リクエスト後に短時間リソースをウォームな状態に保ち、不要になったら解放することを意味します。
これは経済性も変えます。これはリクエストごとのサーバーレス料金と同じではなく、専用の月額キャパシティとも同じではありません。多くのAIデータワークロードにとって、分単位の利用がより自然な単位です。ループが実行されている間はコンピュートに支払い、その後は消えるに任せます。
その背後には、ほぼ静的なカーネルを管理するコントロールプレーンから、リソース、キャッシュ状態、スナップショット、コストを理解するカーネルへの、より大きなアーキテクチャの変化があります。これはそれ自体で1つの記事に値します。本記事で重要な点はよりシンプルです。このリソースモデルがなければ、Long-running、On-demand、Offline Batchは、同じエラスティックなデータシステムの3つの部分ではなく、3つの別々のデプロイメント選択肢になってしまうということです。
External Collection: データがすでに存在する場所でデータに対応する
設計上、もう1つ考慮しなければならない現実がありました。
ほとんどの企業は、すでにレイク環境に大量の非構造化データを持っています。Lanceテーブル、Icebergテーブル、Parquetデータセット、オブジェクトストレージディレクトリなどです。利用できるようになる前に、すべてを新しいシステムへ移動することを求めるのは現実的ではありません。
だからこそ、私たちはZilliz Vector Lakebase内にExternal Collectionを構築しました。External Collectionは単なるゼロコピーのマッピングではありません。外部データの上に独立したインデックス層を構築します。元のデータはそのままの場所にとどまり、顧客の既存プラットフォームによって引き続きガバナンスされる一方で、Zillizは、ネイティブデータと同じ検索パスを通じてそのデータを検索可能にするために必要なベクトルインデックス、転置インデックス、JSONインデックスを構築・管理します。
私たちの内部原則はシンプルになりました。One Data. One Index. 重複ストレージなし。デュアルライトパイプラインなし。分断されたDiscoveryパスなし。
これは、CS/CDループがベクトルデータベースにすでにインポートされたデータ以上の範囲をカバーできることを意味します。企業がすでにレイクに保有している非構造化データ資産も含めることができます。
第一世代のVector Lakebaseを定義するもの
これらのアイデアは、単なる机上のアーキテクチャではありません。私たちはすでにZilliz Vector Lakebaseでこれらを提供しており、それを構築する過程で、このカテゴリーに対する私たちの見方ははるかに具体的になりました。
第一世代のVector Lakebaseは、いくつかのことを同時に正しく実現する必要があります。

- 第一に、多層キャッシュを備えたストレージとコンピュートの分離。 データはオブジェクトストレージに存在し、コンピュートはゼロまでのスケールダウンを含めて独立してスケールできます。しかし、分離だけでは十分ではありません。オンラインのベクトル検索では、ホットクエリをミリ秒レベルで高速に保つために、メモリ、ローカルディスク、ウォームノード、キャッシュを意識した実行が依然として必要です。
- 第二に、マルチモーダルな非構造化データの統合管理。 システムはベクトルだけでなく、ソースドキュメント、画像、音声、動画、埋め込み、スカラーメタデータ、権限、インデックスも管理すべきです。ベクトルだけを保存するシステムはインデックスサービスであり、データ基盤ではありません。
- 第三に、ネイティブなベクトルデータベース機能。 ミリ秒単位のANN検索、インデックスのライフサイクル管理、ハイブリッド検索、スカラーフィルタリング、全文検索、JSONフィルタリング、複数の類似度指標が組み込まれていなければなりません。Lakehouseを外部のベクトルデータベースに接続しても、断片化は解消されません。別のパイプラインが生まれるだけです。
- 第四に、複数のコンピュートモード。 オンライン提供、オンデマンドのインタラクション、オフラインのバッチ処理は、同じ論理データ上で動作する必要があります。オンデマンドコンピュートは、プロダクションでの提供と大規模なオフライン処理をつなぐ橋渡しになるため、特に重要です。
- 第五に、オープンフォーマットと強制移行なし。 ストレージ層は、Spark、Ray、Daftなどの外部エンジンから読み取れるべきです。既存のIcebergテーブル、Lanceデータセット、Parquetファイルは、不要なコピーなしにシステムに参加できるべきです。データはエンジンではなく、ユーザーに属します。
- 第六に、リソースはデータに追従すべきです。 コンピュートは不要なときには消えることができ、その一方でメタデータは可視でクエリ可能なままです。リクエストによって数秒でリソースを戻すことができます。アイドル状態のテナントは、使用していない専用コンピュートに対して料金を支払うべきではありません。これは単なるオートスケーリングではなく、エンジンがデータに関する判断と合わせてリソースに関する判断を行う必要があります。
これらは現時点での私たちの考えであり、最終的な結論ではありません。システムが成熟するにつれて、私たちはこれらを改訂し続けます。しかし、ひとつの圧力は変わりそうにありません。非構造化データは増え続ける一方で、インフラ予算は同じ速度では増えません。つまり、AIシステムはより反復的で、より効率的で、より継続的に適応できるものになる必要があります。
ベクトルデータベースは消えない
では、最初の問いに戻りましょう。これはベクトルデータベースがなくなることを意味するのでしょうか。まったくそうではありません。
むしろ、このアーキテクチャではセマンティック検索の重要性はさらに高まります。ただし、その役割は変わります。
ベクトルデータベースは、より大きな非構造化データシステムの中の提供エンジンになります。これは、トランザクショナルデータベースがより広範なLakehouse時代の中でも不可欠であり続けたのとよく似ています。OLTPシステムはLakehouseに置き換えられたわけではありません。より大きなアーキテクチャスタックの中のひとつの層になったのです。ベクトルデータベースは今、同じ移行を経験していると私は考えています。
AIインフラの下で起きているより広範な変化は、単に検索に関するものではありません。非構造化データそのものを中心に、継続的な運用ループを構築することにあります。提供はフィードバックを生みます。発見はデータ品質を向上させます。それらの改善はプロダクションへと戻っていきます。ループが一周するたびに、システムはより良くなります。
ストレージ形式、キャッシュ階層、インデックスシステム、エラスティックコンピューティングモデル、リソーススケジューリングを含むその他すべては、そのフライホイールを大規模に経済的に成立させるために存在しています。
今後5年間で Vector Lakebase が正確にどのようなものになるのか、私たちにはまだわかりません。約10年前に Milvus を始めたときも、ベクトルデータベースそのものがどこへ向かうのかを予測することはできませんでした。
しかし、今では一つ明確に感じられることがあります。非構造化データは増え続けるでしょう。モデルは変化し続けるでしょう。エージェントは、より多くのトレース、フィードバック、状態を生成するでしょう。チームは、インフラストラクチャコストを際限なく増やすことなく、データをより速く改善する必要があります。
成功するシステムは、継続的なサービングと継続的な発見を、同じ機械の一部のように感じさせるものになるでしょう。それが、私たちが構築を進めている方向です。
Zilliz Vector Lakebase のパブリックプレビューを利用できます
Zilliz Vector Lakebase のパブリックプレビューを開始しました — これは、Zilliz Cloud がマネージドベクトルデータベースから、低レイテンシのベクトルサービングとデータレイクのオープン性、スケーラビリティ、経済性を組み合わせた統合セマンティックデータプラットフォームへと進化する大きな一歩です。
Zilliz Vector Lakebase の主な機能:
- さまざまなリアルタイムのパフォーマンスとコストのトレードオフに最適化された階層型サービング
- 常時稼働のコンピューティングなしで、大規模または探索的なワークロードに対応するオンデマンド検索
- 外部データレイク検索 — 既存のレイクデータに対して直接インデックスを作成し、検索
- ベクトル、テキスト、JSON、地理空間データを横断するフルスペクトラム検索(ハイブリッド検索と再ランキングに対応)
- Vortex 上に構築された統合レイクネイティブストレージ。Lance や Parquet よりも高速かつ低コストなランダム読み取りを実現するオープンフォーマット
現在のスタックでサービングと発見が別々のシステムに分かれているなら、Vector Lakebase は検討する価値があるかもしれません。Zilliz Cloud でお試しください — 新規の仕事用メールでの登録には $100 の無料クレジットが付与されます — または、ユースケースについてお問い合わせください。
注: この記事のパフォーマンスおよびコストの数値は、オープンソースの VectorDB Benchmark の結果、社内テスト、匿名化された顧客シナリオに基づいています。実際の結果は、データ規模、分布、インデックスパラメータ、ワークロード形状、リソース構成によって異なります。

読み続けて

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.