




Milvusのデータ挿入速度に関する誤解を解く
LangChainやLlamaIndexの便利で短いAPIステップに頼っているユーザーの多くは、"Milvusへのデータ挿入は遅い "と思っているかもしれません。しかし、このような認識は、多くの場合、詳細なプロセスステップの見落としから生じています。
隠されたステップ
LangChain](https://python.langchain.com/v0.2/docs/integrations/vectorstores/milvus/)やLlamaIndexを使用する場合、これらのライブラリは非構造化データ(テキスト、画像、音声など)を埋め込みモデルを使用してベクトルに変換します。そして、これらのベクトルをMilvus Liteに挿入します。これらのライブラリは、複数の舞台裏のステップを処理することで、この複雑なプロセスを簡素化します。
この抽象化により、データ挿入処理に時間がかかっているように錯覚してしまいます。
タイムホッグ埋め込み生成
非構造化データから埋め込みデータを生成するのにかかる平均時間は、Milvusにデータを挿入するのにかかる時間よりもかなり長い。この遅さは、多くの場合、データ挿入のステップよりも、データをベクトル表現に変換する計算集約的なプロセスに起因しています。
埋め込み生成時間とデータ挿入時間の違いを説明するために、このブログで平均埋め込み時間が約5秒である例を示します。一方、Milvusベクトル・データベースの平均挿入時間は、わずか10分の1秒です。完全なコードは私のGitHubにあります。
言い換えれば、LangChainやLlamaIndexで観測される "Milvus insert "時間の約97%は埋め込み生成に費やされ、約3%は実際のデータベース挿入ステップに費やされている。
以前のブログ](https://zilliz.com/blog/how-to-connect-to-milvus-lite-using-langchain-and-llamaindex)で、LlamaIndexまたはLangChainを使ってMilvus Liteに接続する方法を紹介しました。
以下では、LlamaIndexまたはLangChainを使用したMilvus Liteへの接続方法について説明します:
LlamaIndexでMilvusにデータを挿入するコードの例
Milvusにデータを挿入するLangChainコードの例
Milvusにデータを挿入するPymilvus APIコードの例
Milvusにデータを挿入するLlamaIndexコードの例
LlamaIndexのコード例です。
from llama_index.core import (
ServiceContext、
StorageContext、
VectorStoreIndex、
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.milvus import MilvusVectorStore
インポート時間
# 埋め込みモデルを定義する。
service_context = ServiceContext.from_defaults(
# LlamaIndex local: デフォルトのHFキャッシュと同じ場所に変換される。
embed_model="local:BAAI/bge-large-en-v1.5"、
)
# ドキュメントとエンベッディングからMilvusコレクションを作成します。
embedding_dim = 1024
vectorstore = MilvusVectorStore(
uri="./milvus_llamaindex.db"、
dim=EMBEDDING_DIM、
# LlamaIndexのデフォルト値をMilvus用にオーバーライドします。
consistency_level="Eventually"、
drop_old=True、
index_params = {
"metric_type":"COSINE"、
「index_type":"AUTOINDEX"、
「params":{},}
)
storage_context = StorageContext.from_defaults(
vector_store=vectorstore
)
llamaindex = VectorStoreIndex.from_documents(
lli_docs[:1]、
storage_context=storage_context、
service_context=service_context
)
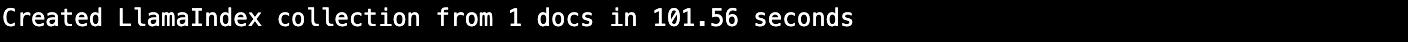
Milvusにデータを挿入するLangChainコードの例
LangChainのコード例です。
from langchain_milvus import Milvus
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
インポート時間
# 埋め込みモデルを定義する。
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cpu'}.
encode_kwargs = {'normalize_embeddings':True}とする。
embed_model = HuggingFaceEmbeddings(
model_name=model_name、
model_kwargs=model_kwargs、
encode_kwargs=encode_kwargs
)
EMBEDDING_DIM = embed_model.dict()['client'].get_sentence_embedding_dimension()
# チャンキング戦略を定義する。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=51)
# チャンキングと埋め込みを行ったドキュメントからMilvusコレクションを作成します。
start_time = time.time()
docs = text_splitter.split_documents(docs)
vectorstore = Milvus.from_documents(
documents=docs、
embedding=embed_model、
connection_args={"uri":"./milvus_demo.db"}、
# LangChainのデフォルト値をMilvus用にオーバーライドします。
consistency_level="Eventually"、
drop_old=True、
index_params = {
"metric_type":"COSINE"、
「index_type":"AUTOINDEX"、
「params":{},}
)

Milvusにデータを挿入するPymilvus APIコードの例
PymilvusのAPIコールを直接使って、便利で短いLangChainとLlamaIndexのコードの裏側で実際に何が起こっているのか見てみましょう。
上記の例では、インターネットからダウンロードしたMilvus docs webpagesを直接使用しています。 埋め込み時間と挿入時間の違いを示すために、オープンソースのmultimodal embedding modelを使って、1)画像とテキストの両方を埋め込み、2)密なベクトルをMilvusに挿入してみます。
インポート pymilvus
インポートリクエスト
from io import BytesIO
# メモリの問題を避けるために、小さなバッチで実行する。
バッチサイズ = 10
# バッチでテキストや画像を埋め込み、Milvusにデータを挿入する。
batch_embedding_times = [].
batch_insert_times = [].
for i in range(0, 300, BATCH_SIZE):
バッチ画像 = [].
batch_texts = [] (バッチテキスト)
batch_urls = [] (バッチアール)
for j in range(BATCH_SIZE):
if i + j < len(image_texts):
text = image_texts[i + j] です。
url = image_urls[i + j] です。
with Image.open(f"./images/{url}.jpg") as img:
batch_images.append(img.copy())
batch_texts.append(text)
batch_urls.append(url)
# テキストと画像の埋め込み推論。
start_time = time.time()
image_embeddings, text_embeddings = embedding_model(
batch_images=batch_images、
batch_texts=batch_texts)
end_time = time.time()
# print(f "Embedding time for batch size {len(batch_images)}:", end="")
# print(f"{np.round(end_time - start_time, 2)}秒")
batch_embedding_times.append(end_time - start_time)
# チャンクリストをmilvusかzillizに挿入する。
chunk_dict_list = [].
# チャンクdict_listを作成します。
for chunk, img_url, img_embed, text_embed in zip(
batch_texts、
バッチ_url、
image_embeddings, text_embeddings):
chunk_dict = {
'chunk': chunk、
'image_filepath': img_url、
'text_vector': text_embed、
'image_vector': img_embed
}
chunk_dict_list.append(chunk_dict)
start_time = time.time()
try:
col.insert(data=chunk_dict_list)
except:
print(f "挿入エラー:{img_url}")
end_time = time.time()
# print(f "Insert time for {len(chunk_dict_list)} vectors:", end="")
# print(f"{np.round(end_time - start_time, 4)}秒")
batch_insert_times.append(end_time - start_time)
col.flush()
# 平均埋め込み時間を計算する。
平均埋め込み時間 = np.mean(batch_embedding_times)
print(f "Average embedding time:平均埋め込み時間:{round(average_time,2)}秒")
# 平均挿入時間を計算する。
平均挿入時間を計算する。
print(f "平均挿入時間:平均挿入時間: {round(average_time,2)} 秒")
バッチ埋め込み時間の出力です。
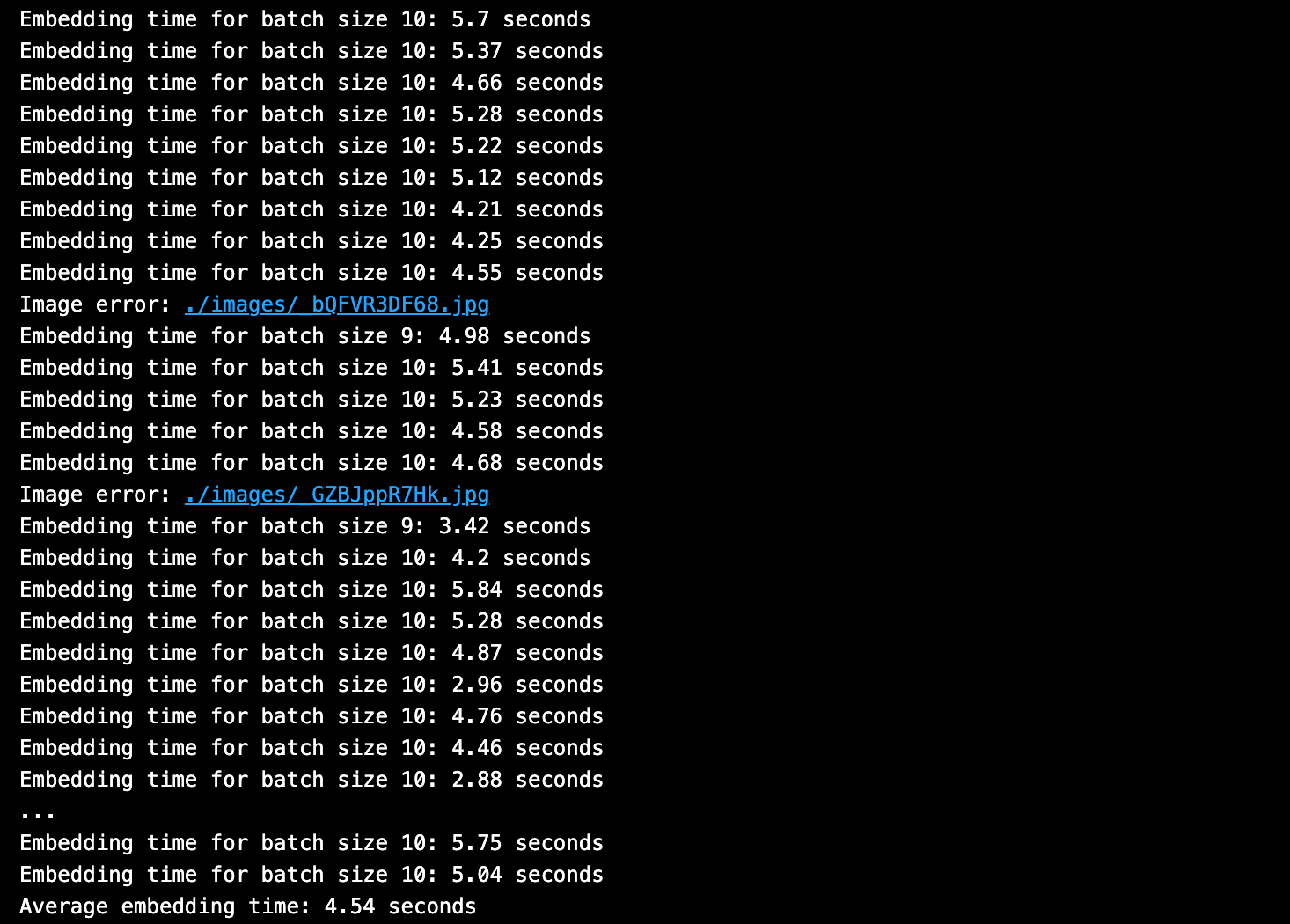
Milvus timesへの一括挿入の出力です。

平均エンベッディング時間は〜5秒、平均Milvusベクトルデータベース挿入時間は約10分の1秒でした。これは全体の約97%が埋め込み生成に費やされ、約3%がデータベース挿入に費やされたことになる。
ご覧の通り、埋め込みステップに最も時間がかかっています!
リソースと参考文献
Milvus Lite ドキュメント](https://milvus.io/docs/quickstart.md)
Milvus Lite LlamaIndexドキュメント](https://milvus.io/docs/integrate_with_llamaindex.md)
Milvus Lite LangChain ドキュメント](https://milvus.io/docs/integrate_with_langchain.md)
LlamaIndex Milvusドキュメント](https://docs.llamaindex.ai/en/latest/examples/vector_stores/MilvusIndexDemo/)
Uform マルチモーダル埋め込み](https://github.com/unum-cloud/uform)

読み続けて

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.