




MilvusによるマルチテナントRAGの設計: 拡張可能なエンタープライズ知識ベースのベストプラクティス
#はじめに
ここ数年、RAG(Retrieval-Augmented Generation)は、大組織がLLMを搭載したアプリケーション、特に多様なユーザーを抱えるアプリケーションを強化するための信頼できるソリューションとして台頭してきた。このようなアプリケーションが成長するにつれて、マルチテナンシーフレームワークの実装が不可欠になります。マルチ・テナントは、異なるユーザー・グループに対してデータへのセキュアで分離されたアクセスを提供し、ユーザーの信頼を確保し、規制基準を満たし、運用効率を向上させます。
Milvusは、高次元のベクトルデータを扱うために構築されたオープンソースのベクトルデータベースである。Milvus]()は、高次元のベクトルデータを扱うために構築されたオープンソースのベクトルデータベースである。Milvusは、データベースレベル、コレクションレベル、パーティションレベルのマルチテナンシーを含む、様々なニーズに対応した柔軟なマルチテナンシー戦略を提供しています。
この投稿では、以下の内容を取り上げます:
マルチテナンシーとは何か、なぜ重要なのか
Milvusにおけるマルチテナント戦略
例RAGを利用した企業ナレッジベースのマルチテナンシー戦略
マルチテナンシーとは何か?
マルチテナントは、「テナント」と呼ばれる複数の顧客やチームが、アプリケーションやシステムの単一のインスタンスを共有するアーキテクチャです。各テナントのデータと構成は論理的に分離され、プライバシーとセキュリティが確保されますが、すべてのテナントは同じ基盤インフラを共有します。
複数の企業にナレッジベースのソリューションを提供するSaaSプラットフォームを想像してみてください。各企業はテナントです。
テナントAは、患者向けのFAQやコンプライアンス文書を保管する医療機関です。
テナントBは、社内のITトラブルシューティングのワークフローを管理するハイテク企業。
テナントCは小売業で、返品に関するカスタマーサービスFAQを保管しています。
各テナントは完全に分離された環境で運用されており、テナントAのデータがテナントBのシステムに漏れたり、逆にテナントAのデータがテナントBのシステムに漏れたりすることはありません。さらに、リソースの割り当て、クエリのパフォーマンス、およびスケーリングの決定はテナントごとに行われるため、あるテナントでワークロードが急増しても、高いパフォーマンスが保証されます。
マルチテナントは、同じ組織内の異なるチームにサービスを提供するシステムにも有効です。ある大企業が、HR、法務、マーケティングなどの社内部門にサービスを提供するためにRAGベースのナレッジベースを使用しているとします。各部門はテナント**であり、この設定ではデータとリソースが分離されています。
マルチテナントには、コスト効率、拡張性、堅牢なデータセキュリティなどの大きなメリットがあります。単一のインフラを共有することで、サービス・プロバイダーはオーバーヘッド・コストを削減し、より効果的なリソース消費を確保することができます。また、シングル・テナント・モデルのようにテナントごとに個別のインスタンスを作成するよりも、新しいテナントを追加する際に必要なリソースがはるかに少なくて済みます。重要な点として、マルチテナントでは、テナントごとに厳重なデータ分離を行い、アクセス制御と暗号化によって機密情報を不正アクセスから保護することで、堅牢なデータセキュリティを維持します。さらに、アップデート、パッチ、新機能をすべてのテナントに同時に導入できるため、システムのメンテナンスが簡素化され、管理者の負担が軽減されるとともに、セキュリティとコンプライアンスの基準が一貫して維持されます。
Milvus におけるマルチテナント戦略
Milvusがどのようにマルチテナントをサポートしているかを理解するためには、まずユーザデータをどのように整理しているかを見ることが重要です。
Milvusのユーザデータ整理方法
Milvusはデータを3つのレイヤーに分け、大まかなものから細かいものへと分類しています:データベース**、コレクション、パーティション/パーティションキーです。
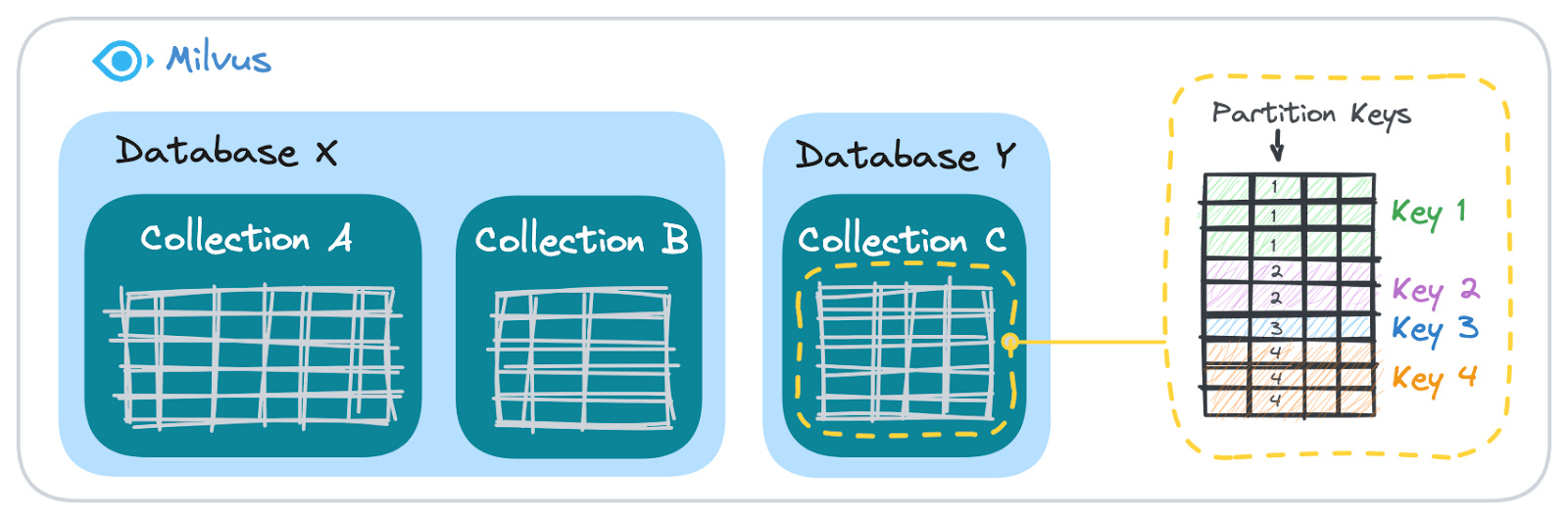 図- Milvusによるユーザーデータの整理方法.png
図- Milvusによるユーザーデータの整理方法.png
図:Milvusによるユーザデータの整理方法
データベースこれは論理コンテナとして機能し、従来のリレーショナルシステムにおけるデータベースに似ています。
コレクション**:データベース内のテーブルと同様に、コレクションはデータを管理可能なグループに整理する。
パーティション/パーティション・キー:コレクション内では、データをパーティションでさらに区分することができます。パーティション・キーを使用すると、同じキーを持つデータがグループ化されます。例えば、ユーザIDをパーティション・キーとして使用すると、特定のユーザの全データが同じ論理セグメ ントに保存されます。これにより、個々のユーザーに結びついたデータを簡単に取り出すことができます。
データベースからコレクション、そしてパーティション・キー**と進むにつれて、データ編成の粒度は徐々に細かくなっていきます。
より強固なデータセキュリティと適切なアクセス制御を実現するため、Milvusは堅牢なロールベースアクセス制御(RBAC)も提供しており、管理者は各ユーザに特定の権限を定義することができます。許可されたユーザのみが特定のデータにアクセスすることができます。
Milvusはマルチテナントを実装するための複数の戦略をサポートしており、アプリケーションのニーズに基づいた柔軟性を提供します:**データベースレベル、コレクションレベル、パーティションレベルのマルチテナンシーです。
データベースレベルのマルチテナンシー
データベースレベルのマルチテナンシーアプローチでは、各テナントは同じMilvusクラスタ内で独自のデータベースを割り当てられます。この戦略により、強力なデータ分離が実現し、最適な検索パフォーマンスが保証されます。しかし、特定のテナントが非アクティブのままである場合、非効率的なリソース利用につながる可能性があります。
コレクションレベルのマルチテナント
ここで、コレクションレベルのマルチテナントでは、2つの方法でテナントのデータを整理できます。
すべてのテナントに1つのコレクション**:すべてのテナントが1つのコレクションを共有し、テナント固有のフィールドがフィルタリングに使用されます。実装は簡単ですが、この方法ではテナントの数が増えるにつれてパフォーマンスのボトルネックが発生する可能性があります。
テナントごとに1つのコレクション**:各テナントは専用のコレクションを持つことができ、分離とパフォーマンスは向上しますが、より多くのリソースが必要になります。テナントの数がMilvusのコレクション容量を超えると、このセットアップはスケーラビリティの制限に直面する可能性があります。
パーティションレベルのマルチテナント
パーティションレベルのマルチテナントは、1つのコレクション内でテナントを整理することに重点を置いています。ここでは、テナント・データを整理する2つの方法もあります。
テナントごとに1つのパーティション**:テナントはコレクションを共有しますが、データは別々のパーティションに保存されます。各テナントに専用のパーティションを割り当てることで、データを分離し、分離と検索パフォーマンスのバランスをとることができます。しかし、このアプローチはMilvusの最大パーティション数によって制約を受けます。
パーティション・キー・ベース・マルチテナンシー**:これは、単一のコレクションがパーティション・キーを使用してテナントを区別する、よりスケーラブルなオプションです。この方法はリソース管理を簡素化し、より高いスケーラビリティをサポートしますが、一括データ挿入をサポートしません。
以下の表は、主なマルチテナンシー・アプローチの主な違いをまとめたものです。
| グラニュラリティ** | データベースレベル | コレクションレベル | **パーティション・キー・レベル |
|---|---|---|---|
| 最大テナント数|~1,000|~10,000|~10,000,000 | |||
| データ編成の柔軟性|高:ユーザーはカスタム・スキーマで複数のコレクションを定義できる。 | 中程度:カスタムスキーマを持つコレクションは1つに制限される。 | 低:すべてのユーザーがコレクションを共有し、一貫したスキーマが必要。 | |
| ユーザーあたりのコスト|高|中|低 | |||
| 物理的リソースの分離 | |||
| RBAC|あり|あり|なし|検索パフォーマンス | |||
| 検索パフォーマンス|強|中|強 |
例RAGを利用した企業知識ベースのマルチテナント戦略
RAGシステムのマルチテナント戦略を設計する際には、お客様のビジネスとテナントの具体的なニーズに合わせたアプローチが不可欠です。Milvusは様々なマルチテナント戦略を提供しており、テナントの数、要件、必要なデータ分離のレベルによって適切な戦略を選択することができます。ここでは、RAGを利用したエンタープライズナレッジベースを例に、これらの決定を行うための実践的なガイドを紹介します。
マルチテナント戦略を選択する前にテナント構造を理解する
RAGを利用したエンタープライズナレッジベースは、多くの場合、少数のテナントにサービスを提供しています。これらのテナントは通常、IT、営業、法務、マーケティングなどの独立したビジネスユニットであり、それぞれが個別のナレッジベースサービスを必要とします。例えば、人事部門は、入社案内や福利厚生方針などの機密情報を管理し、人事担当者のみがアクセスできるようにします。
この場合、各事業部門は独立したテナントとして扱われるべきであり、データベースレベルのマルチテナント戦略が最適であることが多い。各テナントに専用のデータベースを割り当てることで、組織は強力な論理的分離を実現し、管理を簡素化し、セキュリティを強化することができます。この設定はテナントに大きな柔軟性を提供します。テナントはコレクション内でカスタムデータモデルを定義し、必要な数のコレクションを作成し、コレクションのアクセス制御を独立して管理することができます。
物理リソースの分離によるセキュリティの強化
データ・セキュリティが非常に優先される状況では、データベース・レベルでの論理的な分離だけでは十分で はないかもしれません。例えば、ビジネス・ユニットによってはクリティカルなデータや機密性の高いデータを扱う場合があり、他のテナントからの干渉に対してより強固な保証が必要になります。このような場合、データベース・レベルのマルチテナント構造の上に物理的分離アプローチを実装することができます。
Milvusではデータベースやコレクションなどの論理コンポーネントを物理リソースにマッピングすることができます。この方法により、他のテナントの活動がクリティカルなオペレーションに影響を与えないことが保証されます。このアプローチが実際にどのように機能するかを探ってみよう。
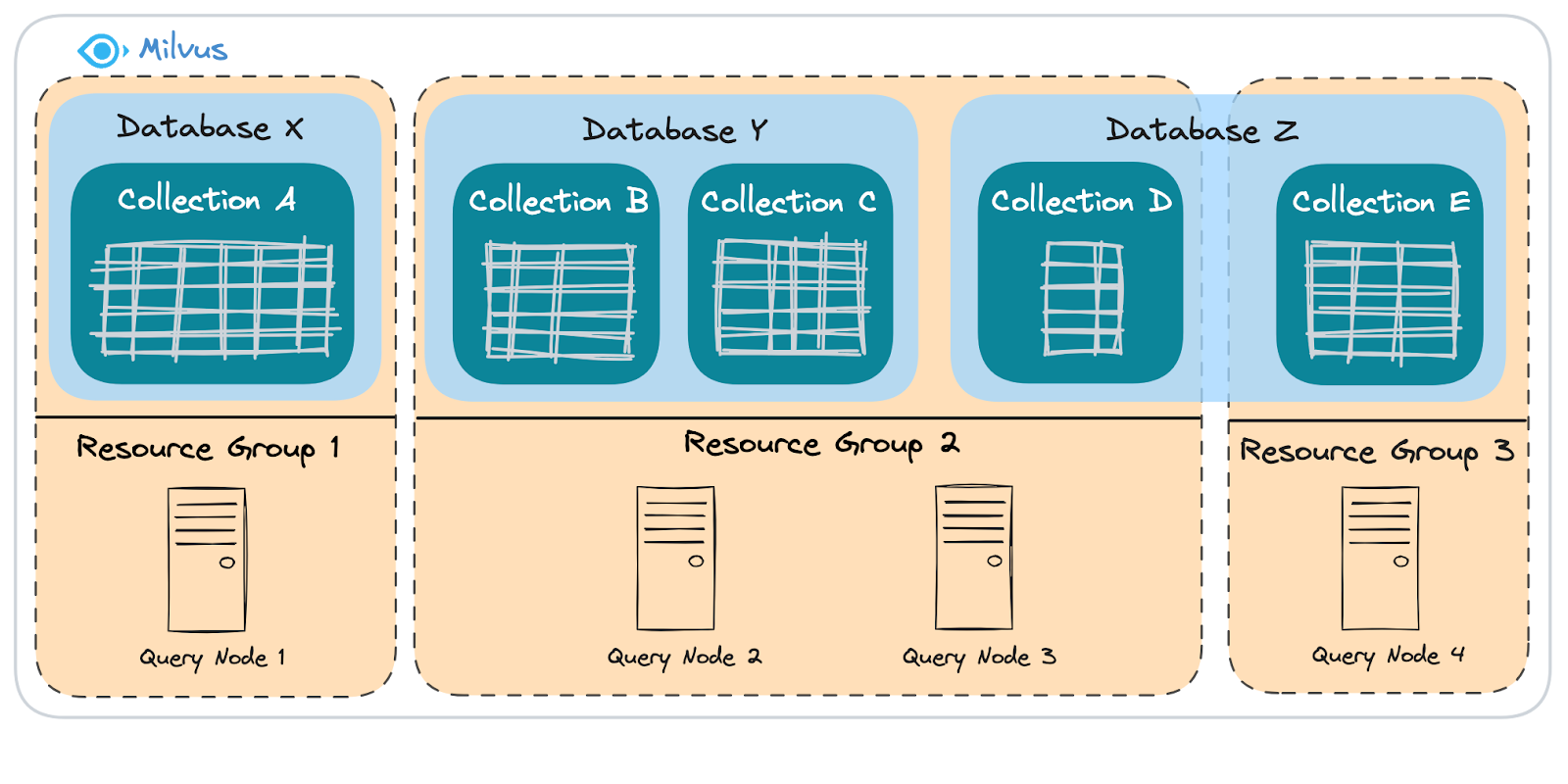 図- Milvusによる物理リソースの管理方法.png
図- Milvusによる物理リソースの管理方法.png
図Milvusの物理リソース管理方法
上図のように、Milvusのリソース管理には3つのレイヤーがあります:クエリノード、リソースグループ、データベースです。
クエリノードクエリタスクを処理するコンポーネント。物理マシンまたはコンテナ(KubernetesのPodなど)上で動作する。
リソースグループ**:論理コンポーネント(データベースとコレクション)と物理リソースの橋渡しをするQuery Nodeの集まり。1つのResource Groupに1つ以上のデータベースまたはコレクションを割り当てることができます。
上図の例では、3つの論理データベースがあります:X、Y、Z です。
データベースX:コレクションAを含む。
データベースY:コレクションBとCを含む。
データベースZ:コレクションDとEを含む。
データベースXには、データベースYまたはデータベースZ**からのロードの影響を受けたくない重要な知識ベースが格納されているとします。データの分離を確実にするために
データベース X** には独自の リソース・グループ が割り当てられ、クリティカルな知識ベースが他のデータベースからのワークロードの影響を受けないようにします。
コレクション E** も親データベース(Z)内の別のリソースグループに割り当てられています。これにより、共有データベース内の特定の重要なデータに対して、コレクション・レベルでの分離が実現します。
一方、データベースYとZの残りのコレクションは、リソースグループ2の物理リソースを共有します。
論理コンポーネントを物理リソースに注意深くマッピングすることで、組織は特定のビジネス・ニーズに合わせた柔軟でスケーラブルかつセキュアなマルチテナンシー・アーキテクチャを実現することができます。
エンドユーザーレベルのアクセスの設計
エンタープライズRAGのマルチテナント戦略を選択するためのベストプラクティスを学んだところで、このようなシステムでユーザーレベルのアクセスを設計する方法を探ってみましょう。
このようなシステムでは、エンドユーザは通常、LLMを通じて読み取り専用モードでナレッジベースと対話します。しかし、組織は、ナレッジベースの精度を向上させたり、パーソナライズされたサービスを提供したりするなどのさまざまな目的のために、ユーザーによって生成されたそのようなQ&Aデータを追跡し、特定のユーザーにリンクする必要があります。
病院のスマート相談窓口を例にとってみよう。患者は、"今日の専門医の予約は空いていますか?"とか、"今度の手術に必要な特別な準備はありますか?"といった質問をするかもしれない。これらの質問はナレッジベースに直接影響を与えるものではありませんが、病院にとってこのようなやり取りを追跡することはサービス向上のために重要です。これらのQ&Aのペアは通常、やりとりを記録する専用の別のデータベース(必ずしもベクトルデータベースである必要はない)に保存される。
図-エンタープライズRAG知識ベースのマルチテナンシーアーキテクチャ.png](https://assets.zilliz.com/Figure_The_multi_tenancy_architecture_for_an_enterprise_RAG_knowledge_base_7c9ad8d4d1.png)
図:エンタープライズRAG知識ベースのためのマルチテナンシーアーキテクチャ_(英語)
上の図は、エンタープライズRAGシステムのマルチテナンシー・アーキテクチャを示しています。
システム管理者**はRAGシステムを監督し、リソースの割り当てを管理し、データベースを割り当て、リソースグループにマッピングし、スケーラビリティを確保する。システム管理者は、図に示すように、各リソース・グループ(リソース・グループ1、2、3など)が物理サーバー(クエリー・ノード)にマッピングされている物理インフラを処理します。
テナント(データベースの所有者と開発者)**は、図に示すように、ユーザーが作成したQ&Aデータに基づいて知識ベースを反復しながら管理する。異なるデータベース(データベースX、Y、Z)には、異なるナレッジベースのコンテンツを持つコレクション(コレクションA、Bなど)が含まれます。
エンドユーザー**は、LLMを通じて読み取り専用でシステムと対話します。彼らがシステムに問い合わせると、彼らの質問は別のQ&Aレコードテーブル(別のデータベース)に記録され、継続的に貴重なデータがシステムにフィードバックされます。
この設計により、ユーザーとのやり取りからシステム管理まで、各プロセス層がシームレスに機能し、組織が強固で継続的に改善されるナレッジベースを構築できるようになります。
要約
このブログでは、マルチテナントフレームワークが、RAGを利用したナレッジベースのスケーラビリティ、セキュリティ、およびパフォーマンスにおいて、どのように重要な役割を果たすかを探りました。異なるテナントのデータとリソースを分離することで、企業はプライバシー、規制遵守、および共有インフラストラクチャ全体での最適化されたリソース割り当てを保証することができます。柔軟なマルチテナント戦略を持つMilvusは、企業が特定のニーズに応じて、データベースレベルからパーティションレベルまで、適切なデータ分離レベルを選択することを可能にします。適切なマルチテナンシー・アプローチを選択することで、企業は多様なデータやワークロードを扱う場合でも、テナントに合わせたサービスを提供することができます。
ここで説明するベストプラクティスに従うことで、企業は優れたユーザーエクスペリエンスを提供するだけでなく、ビジネスニーズの成長に合わせて容易に拡張できるマルチテナントRAGシステムを効果的に設計・管理することができます。Milvusのアーキテクチャは、企業が高レベルの分離、セキュリティ、パフォーマンスを維持できることを保証し、エンタープライズグレードのRAGを搭載したナレッジベースを構築する上で極めて重要な要素となっています。
マルチテナントRAGの詳細については## Stay Tuned for More Insights into Multi-Tenancy RAG
このブログでは、Milvusのマルチテナント戦略がどのようにテナントを管理するように設計されているかについて説明しました。エンドユーザーとのやり取りは通常アプリケーションレイヤーで行われ、ベクターデータベース自体はそのようなユーザーを意識することはありません。
あなたは疑問に思うかもしれない:各エンドユーザーのクエリ履歴に基づいてより正確な回答を提供したい場合、Milvusは各ユーザーにパーソナライズされたQ&Aコンテキストを維持する必要があるのではないでしょうか?
その答えはユースケースによって異なります。例えば、オンデマンドの相談サービスでは、クエリはランダムであり、ユーザーの過去のコンテキストを追跡することよりも、ナレッジベースの質に主眼が置かれます。
しかし、他のケースでは、RAGシステムはコンテキストを認識する必要がある。これが必要な場合、Milvusはアプリケーションレイヤーと協力して、各ユーザーのコンテキストをパーソナライズされた記憶として保持する必要がある。この設計は、大規模なエンドユーザーを持つアプリケーションでは特に重要である。さらなる洞察にご期待ください!

読み続けて

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.