




ウェビナーのまとめLlamaIndexを使用したプライベートデータでLLMを向上させる
ChatGPTの人気は、知識と推論を生成する大規模言語モデル(LLM)の能力を実証しました。しかし、ChatGPTは、一般に公開されているデータで事前にトレーニングされているため、あなたのビジネスに関連する具体的な答えや結果が得られない可能性があります。では、どのようにプライベートなデータでLLMを補強するのがベストなのでしょうか?LlamaIndexは最も人気のあるソリューションの一つです。これは、外部データとLLMをつなぐ、シンプルで柔軟な一元化されたインターフェースです。
先日のウェビナーでは、LlamaIndexの共同創設者兼CEOであるJerry Liuが、LlamaIndexがどのようにプライベートデータでLLMを後押しするかを説明しました。さらに、Zillizの機械学習アーキテクト兼オペレーション・ディレクターであるFrank Liu もLLMに関する彼の洞察を共有しました。私と一緒にこのウェビナーから重要なポイントを探り、聴衆からの未回答の質問のいくつかに取り組みましょう。
微調整と文脈内学習
「プライベート・データを使ってLLMを強化するにはどうすればいいか」というのは、LLM開発者の多くが抱く疑問だろう。ウェビナーでジェリーは、微調整と文脈内学習という2つの方法について議論した。 ファインチューニングでは、プライベートデータを使ってネットワークを再トレーニングする必要があるが、コストがかかり、透明性に欠ける。さらに、場合によっては効果的でないこともある。一方、イン・コンテキスト学習は、入力プロンプトにコンテキストを追加するために、外部知識と検索モデルで事前に訓練されたモデルをペアリングする。しかし、検索と生成の組み合わせ、適切なコンテキストの取得、膨大なソースデータの管理などに課題が生じる。LlamaIndexは、インコンテキスト学習の課題に対処するために設計されたツールキットである。
LlamaIndexとは?
LlamaIndexはオープンソースのツールで、LLMアプリケーションのデータ管理とクエリのインターフェイスを提供します。ツールキットには3つの主要コンポーネントが含まれています:
- 様々なソースからデータを取り込むためのデータコネクタ。
- さまざまなユースケースに合わせてデータを構造化するためのデータインデックス。
- プロンプトを入力し、ナレッジ補強された出力を受け取るためのクエリーインターフェース。
LlamaIndexの3つの主要コンポーネント ](https://assets.zilliz.com/Llama_Index_Webinar_Recap_1_72f6d5218b.png)
LlamaIndexは、LLMアプリケーションを開発するための貴重なツールでもある。LlamaIndexはブラックボックスのように動作し、詳細なクエリ記述を取り込み、参照とアクションを含むリッチなレスポンスを提供する。LlamaIndexはまた、正確で望ましい結果を提供するために、言語モデルとプライベートデータ間の相互作用を管理します。
LlamaIndexのコンテキスト](https://assets.zilliz.com/Llama_Index_Webinar_Recap_2_bc0fd22e17.png)
LlamaIndex のベクトルストア・インデックスの仕組み
LlamaIndexには、リストインデックス、ベクトルストアインデックス、ツリーインデックス、キーワードインデックスなど様々なインデックスがあります。JerryはLlamaIndexのインデックスがどのように機能するかを紹介するために、ウェビナーでベクトルストア・インデックスを使用しました。 ベクトルストア・インデックスは、ベクトルストアと言語モデルを組み合わせた、検索と合成の一般的なモードです。ソース・ドキュメントのセットはインジェストされ、テキスト・ノードに分割され、各ノードにエンベッディングが付加された状態でベクター・ストアに格納されます。クエリを実行すると、クエリ・エンベッディングがベクトルストアを検索して、最も類似した上位k個のノードを探し出し、これらのノードがレスポンス合成モジュールで使用されてレスポンスが生成される。
LlamaIndexへのデータ取り込み](https://assets.zilliz.com/Llama_Index_Webinar_Recap_3_cbb2561fac.png)
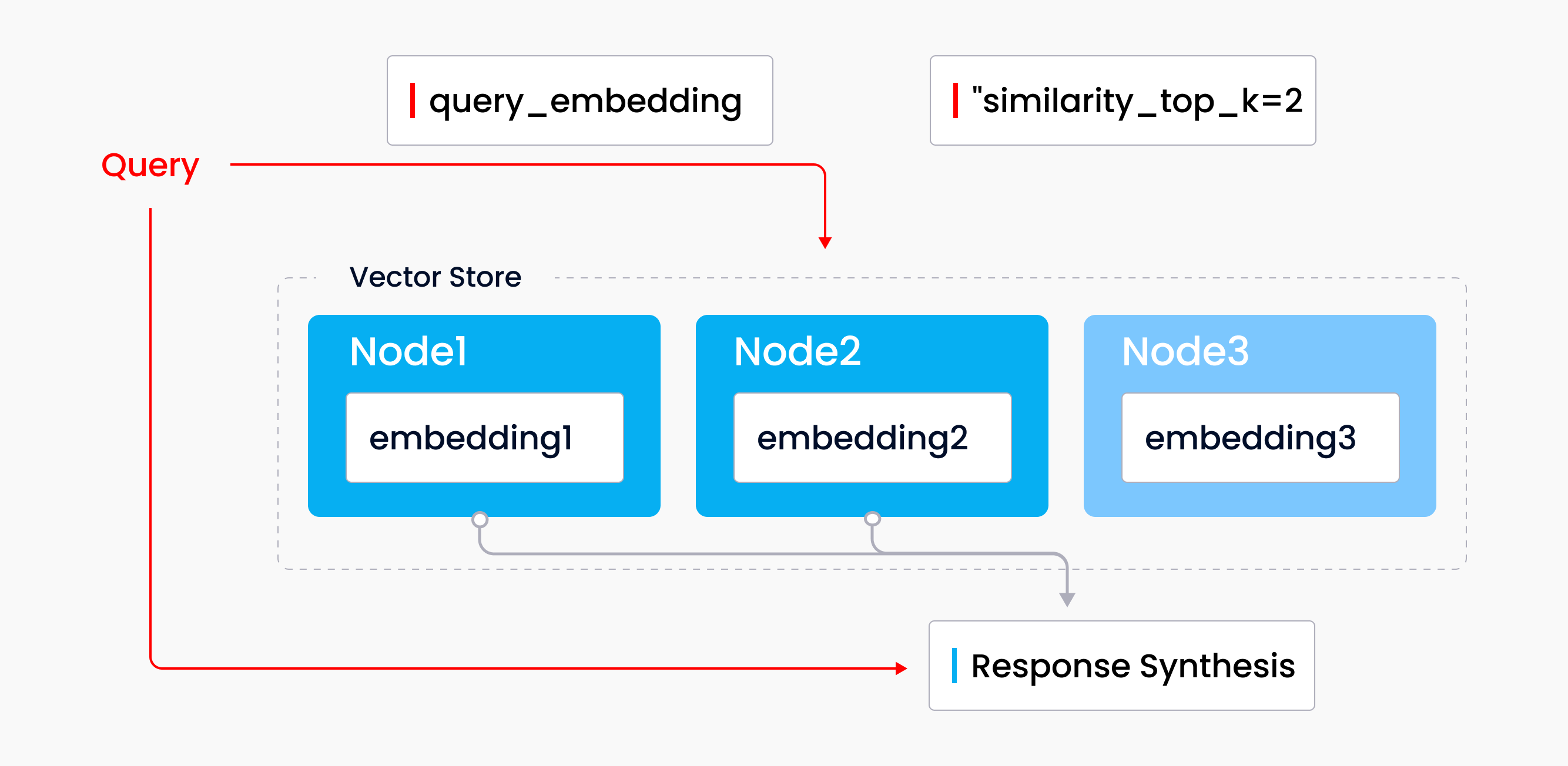 ベクトルストアのインデックスを使ったクエリ
ベクトルストアのインデックスを使ったクエリ
ベクトルストア・インデックスの使用は、LLMアプリケーションに類似性を導入するための最良のアプローチです。このインデックスタイプは、テキストを意味的類似性で比較するワークフローに最適です。例えば、ベクトルストア・インデックスは特定のオープンソースソフトウェアについて質問するのに適しているでしょう。
MilvusとLlamaIndexの統合
LlamaIndexは強力かつ軽量な統合機能を数多く提供している。ウェビナーの中で、JerryはMilvusとLlamaIndexの統合を強調した。
Milvusはベクトルデータベースで、オープンソースであり、数百万、数十億、あるいは数兆のベクトルを含む膨大なデータセットを扱うことができる。統合により、Milvusはエンベッディングとテキストのためのバックエンドベクトルストアとして機能します。統合の設定は簡単で、いくつかのパラメータを入力し、それらをストレージコンテキストでラップし、ベクトルストアのインデックスに入れるだけだ。インデックスへのクエリはクエリエンジンを通して行われ、必要な答えを得ることができる。
Zilliz Cloudは、Milvusのフルマネージドでクラウドネイティブなサービスであり、LlamaIndexとZilliz Cloudの統合も利用できる。
LlamaIndex の使用例
ウェビナーの中で、ジェリーはLlamaIndexの多くの一般的な使用例も紹介しました:
- セマンティック検索](https://zilliz.com/glossary/semantic-search)
- 要約
- テキストからSQLへの変換(構造化データ)
- 異種データの合成
- 比較/対照クエリ
- マルチステップクエリー
- 時間的関係の利用
- 再調査フィルタリング/古いノード
詳細な説明と情報については、ウェビナーの完全録画を見るを参照してください。
Q&A
ウェビナーでは聴衆から多くの質問が寄せられました。ジェリーはQ&Aセッションでいくつかの質問に答えましたが、時間の都合上、答えられなかったものもありました。以下に、最も多く寄せられた質問と未回答の質問、そしてジェリーの回答をまとめました。
Q: OpenAIのプラグインについてどう思いますか?
これはいい質問ですね。私たちは、プラグインをめぐる状況の両側面から自分たちを見ています。一方では、(ChatGPTであれ、LangChainであれ、それ以上であれ)どのような外部エージェント抽象化からも呼び出される、本当に良いプラグインだと考えています。クライアントエージェントは、私たちに入力リクエストを渡し、私たちはそのリクエストをどのように実行するのがベストかを考えます。例えば、私たちはchatgpt-retrieval-plugin repoのプラグインです。クライアント側では、chatgpt-retrieval-plugin - "vector store" abstractionを実装しているサービスとの統合をサポートしています。
Q: パフォーマンスとレイテンシーのトレードオフについて言及されました。その分野で遭遇するボトルネックや課題は何ですか?
コンテキストの量が多い+チャンクサイズが大きい=レイテンシが大きい。より大きなチャンクサイズが常により良い結果につながるかどうかについては議論があります(GPT-4は経験的にGPT-3よりも、より拡張された量のコンテキストの処理に優れています)。それでも、一般的には正の相関がある。 もう一つのトレードオフは、エージェントを含むような「高度な」LLMシステムには、連鎖したLLMコールが必要だということです。連鎖したLLM呼び出しは、本質的に実行に時間がかかります。
Q: クエリを実行するために外部モデルを使用していると理解しています。送信されるプライベートデータの安全性は?
APIサービスによって異なります。例えば、OpenAIはAPIデータを使ってモデルを訓練/改善することはありませんが、機密データをサードパーティに送信することに対する企業の懸念は残ります。私たちは最近、これを軽減するためにいくつかのPIIモジュールを追加しました。もう一つの選択肢は、ローカルモデルを使用することです。
(a) LlamaIndexにロードしてインデックスを作成し、LLMと連携する前に、Milvusのようなベクターデータベースを活用して高度な類似性検索とグラフ最適化を行う。
どちらでも可能です。私たちはこの2つをもう少し統合する予定です。Milvusをデータローダーとして使えば、既存のデータをLlamaIndexで使うことができます。これに対して、Milvusに裏打ちされたベクトル・インデックスを使う場合は、このデータの上にさらに構造体を定義することになります。前者の長所は既存のデータを使えることで、後者の長所はメタデータの定義をよりコントロールできることです。
Q: 約6,000のpdfとパワーポイントをローカルで分析する必要があります。OpenAI、LlamaIndex、llama65bを使わずに、最良の結果を得るには、何がお勧めですか?
もしライセンスに問題がなければ、Llamaを使ってみてください。GitHubの open-source models を見てみてください。
ウェビナーの録画を見る!
LlamaIndexの詳細やJerry LiuとFrank Liuの議論については、ウェビナーの録画をご覧ください。

読み続けて

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.