




Claude 3.5 Sonnet、LlamaIndex、Milvusを用いたエージェント型RAGの実装
AIシステムが急速に進化し続ける中、大規模言語モデル(LLMs)だけに頼ることは、今日の産業界の多様なニーズに応えるにはもはや十分ではありません。こうした課題の増加により、より効率的かつ効果的に問題を解決できる、より複雑なアーキテクチャの開発が求められています。
Zilliz主催のUnstructured Data Meetupで、Zillizのエンジニアリング・ディレクターであるBill Zhangは、Berkeley AI Research (BAIR) blogでも紹介されたCompound AI Systemsというコンセプトを紹介した。このモジュラーアプローチは、単一のAIモデルに依存するのではなく、様々なタスクを処理するために複数のコンポーネントを統合し、よりカスタマイズされた効率的な結果を提供する。ビルのプレゼンテーションはZilliz YouTubeチャンネルで見ることができる。
このブログでは、LLMアプリ・アーキテクチャの進化、検索拡張世代(RAG)とエージェント型RAGの概念、それらの課題と利点など、ビルの重要なポイントを振り返ります。また、Claude 3.4 Sonnet、LlamaIndex、Milvus ベクトルデータベースを使用したエージェント型RAGの構築についても説明します。LLM アプリケーションのアーキテクチャ開発
LLMは10年以上前からAIの一部であったが、この3年間で一般に利用可能な基盤モデル、特にOpenAIのChatGPTが登場したことで、LLMアプリケーションの開発が大幅に加速し、急速な拡大を牽引している。ビルはUnstructured Data Meetupで、現在のAIアーキテクチャの主要な構成要素とその開発について要約した。
図1- LLMシステムの進化.png](https://assets.zilliz.com/Figure_1_LLM_System_Evolution_dc354c9aa7.png)
図1:LLMシステムの進化
LLMの事前訓練された知識だけに頼る
LLMを使用する最も単純な方法は、LLMの "独自の "知識に頼ってクエリに答えることです。しかし、この方法には限界があります:LLMはすべてのトピックやユースケースをカバーできるわけではないので、不正確な回答や「幻覚」的な回答につながる可能性があります。この問題に対処する1つの方法は、複数のLLMを使い、それぞれが異なるタイプの質問に合わせて調整することだが、この方法ではシステムが複雑になりすぎ、拡張が難しくなる。
複合AIシステム:LLMパイプラインに追加コンポーネントを加える
では、どうすればこの問題を解決できるのでしょうか?解決策は複合AIシステムにあります。LLMパイプラインに余分なコンポーネントを追加することで、システムのパフォーマンスを向上させることができます。一般的な例は、Retrieval Augmented Generation (RAG)です。RAGは、MilvusやZilliz Cloud(管理されたMilvus)のようなベクトル・データベースに通常保存される「知識ベース」または「コンテキスト」を導入し、類似検索のために特定の情報が保存される。RAGシステムに知識を投入することで、ユースケースに合わせてカスタマイズされた情報にアクセスすることができます。RAGは、ユーザーのクエリとベクトルデータベースから取得されたコンテキストから構成されるテーラーメイドのプロンプトと組み合わされたLLMのパワーを活用し、より正確で関連性の高い応答を生成します。
エージェント
では、もっと多くのモジュールを実装する必要があるのだろうか?それは特定のユースケースによる。しかし、LLMのように、RAGも特定のモデルに依存するため、限界があります。例えば、クエリが比較タスクの実行を含んでいるにもかかわらず、モデルが要約のためにトレーニングされている場合はどうでしょうか?どのようにして異なるタイプの質問を効果的に管理できるのでしょうか?ここで追加モジュールが登場します:エージェント**である。AIエージェントは、推論、使用するツール、計画のような「人間のような」ステップをパイプラインに追加する複雑なシステムである。エージェントの利点を理解するために、まずRAGの基本を掘り下げてみよう。
検索拡張世代(RAG)
上述したように、RAGシステムは知識ベースとしてベクトルデータベースを組み込むことにより、LLMの出力を強化する。RAGシステム構築の基本的なステップは以下のようにまとめられる:
チャンキング**:Zillizクラウド](https://zilliz.com/cloud)やMilvusのようなベクトルデータベースの中核的な特徴であるセマンティック検索を用いて、ベクトルデータベースから検索されたコンテンツの関連性を向上させるために、文書をより小さな断片に分割する。
エンベッディング**](https://zilliz.com/glossary/vector-embeddings):ベクトルデータベースに取り込まれるチャンクをベクトル化する(数値表現を作成する)。
プロンプト**](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering)):LLMに対して、クエリに基づいてベクトルデータベース内を検索し、答えを得るように指示。
クエリー**:LLMに与えられた質問
これらのステップは主に類似性に基づいている。モデルはデータベース内の最も類似したチャンクを検索し、それに基づいて最も正確な応答を生成する。
図2- RAGの基本ステップ.png](https://assets.zilliz.com/Figure_2_Basic_steps_of_RAG_76336f56c2.png)
図2:RAGの基本ステップ
しかし、意味類似度検索は魔法の解決策ではない。最も似ているチャンクの精度が十分でなければ、結果として得られる答えも不十分なものになる。Billは、要約、比較、複数パートの質問など、特にLLMが最適に機能しない可能性のあるユースケースにおいて、RAGシステムの弱点をいくつか探った。
しかし、RAGの問題点、すなわち推論能力の欠如と必要なドキュメントを正確に検索できないことは、エージェントの導入によって効果的に対処することができる。これらのエンティティは、プロセス全体において重要な役割を果たし、RAGがもたらす課題に対する潜在的な解決策を提供します。
エージェント型RAG
LLMとRAGの限界を理解したところで、エージェントの利点をより深く探ることができる。下の図では、LLMエージェントは、反復プロセスで相互に作用するいくつかのコンポーネントを含んでいる。現在では、類似性だけでなく、計画、推論、ツールの使用、記憶も含まれる。
図3- LLMエージェント.png](https://assets.zilliz.com/Figure_3_LLM_Agents_17862c4542.png)
図3:LLMエージェント
エージェント的なアーキテクチャやフレームワークはいくつかあるが、最もポピュラーなものの一つはReAct(Reasoning/Acting)である。ReActは、計画/推論、行動(ツールの使用)、観察/評価、および答えの生成といういくつかのステップを含む。ビルはこれらのステップを反復プロセスの一部として強調した。
観察/評価ステップでは、モデルが答えを見つけられなかった場合、推論ステップに戻るか、あるいはユーザーに追加のプロンプトを要求することで、代替案を探し続けます。
図4- ReActフレームワーク.png](https://assets.zilliz.com/Figure_4_Re_Act_Framework_a924279b45.png)
図4:ReActフレームワーク (出典)
では、これらのエージェントをRAGパイプラインでどのように使うことができるだろうか?良い点は、下流のRAGパイプラインへのルーティング/プランニングであれ、ツールの呼び出しであれ、パイプラインの全てのステップで実装できることである。知識ベースさえも、ツールやReActフレームワークとみなすことができます。
図5- エージェントRAGの仕組み.png](https://assets.zilliz.com/Figure_5_How_An_Agentic_RAG_works_6d9712ab14.png)
図5:エージェントRAGの仕組み
講演の中で、BillはRAGパイプライン内で可能な5つのエージェント的実装について説明した:
ルーティングルーティング**:ユーザのクエリは、クエリに関連する特定の知識ベースにリダイレクトされる。
- 例ユーザが特定の種類の書籍の推薦を求めた場合、クエリはそれらの種類の書籍に関する情報を含む知識ベースにルーティングすることができます。
クエリプランニング**:クエリはサブクエリに分割され、各サブクエリは関連するRAGパイプラインに導かれます。
- 例ある会社の過去3年間の財務結果を知りたい場合、エージェントは各年のサブクエリを作成し、それぞれを適切なナレッジベースに誘導します。
ツールの使用LLMは外部APIまたはツールと対話し、対話に必要なパラメータを決定します。
- 例ユーザーが天気予報を要求した場合、LLMは天気APIを呼び出し、場所や日付などのパラメータを決定し、APIの応答を処理して答えを提供する。
ReAct:** 計画、ツールの使用、観察のステップを含む、推論と行動を組み込んだ反復プロセス。
- 例詳細な旅行日程を作成するために、システムはユーザーのニーズを推論し、APIを使用してアトラクション、食事、宿泊施設に関する情報を収集し、結果の正確性と関連性を観察し、包括的な旅行プランを提供する。
ダイナミック・クエリ・プランニング**:エージェントは、複数のタスクやサブクエリを逐次ではなく並行して実行し、結果を集約する。
例: 2つの会社の財務結果を比較し、特定の指標の差を計算したい場合、エージェントは両社のデータを並行して処理し、結果を組み合わせて比較を提供します。LLMCompiler は、並列関数呼び出しの効率的かつ効果的なオーケストレーションを可能にするフレームワークの一例です。
図6- LLMコンパイラ.png](https://assets.zilliz.com/Figure_6_LLM_Compiler_c4b717c2c2.png)
図6:LLMコンパイラ(Source)
つまり、エージェントはRAGパイプラインに追加のレイヤーを追加し、プロセスの全体的な効率を高め、改善する。しかしながら、スタンドアロンシステムとしてのLLMやRAGのように、エージェントもまた、その内部ステップを制御し、特定のユースケースに対して最良の結果を達成するためにカスタマイズするといった、いくつかの課題をもたらします。
それでは、Milvusベクターデータベースを使った簡単なエージェントパイプラインを紹介しよう。
Claude 3.5 Sonnet、LlamaIndex、Milvusを用いたエージェントRAG
以下のnotebookは、エージェントフレームワークとしてLlamaIndex、ベクトルデータベースとしてMilvus 、LLMとしてClaude 3.5 Sonnetを使って構築したエージェント型RAGパイプラインの例です。このセクションでは、このエージェントRAGの構築方法を説明します。
また、this notebook で完全なコードを確認することができます。
ステップ1:データのロード
我々のRAGではMilvus Documentation 2.4.xのFAQページを私的知識として使用する。これはシンプルなRAGパイプラインのための良いデータソースである。
pip install -qq llama-index pymilvus llama-index-vector-stores-milvus llama-index-llms-anthropic
!.wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
!unzip -q /content/milvus_docs_2.4.x_ja.zip -d /content/milvus_docs
from llama_index.core import SimpleDirectoryReader
# ドキュメントを読み込む
documents = SimpleDirectoryReader(
input_files=["/content/milvus_docs/ja/faq/operational_faq.md"].
).load_data()
print("Document ID:", documents[0].doc_id)
ステップ2:環境変数
AnthropicとOpenAIの2つのAPI KEYSをインポートする必要がある。
import os
from google.colab import userdata
os.environ["ANTHROPIC_API_KEY"] = userdata.get('ANTHROPIC_API_KEY')
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
ステップ3:データのインデックス作成
Milvusベクトルデータベースを用いて、ドキュメントのインデックスを作成する。これが我々の知識ベースとなる。LlamaIndexではOpenAIがデフォルトの埋め込みモデル(変更可能)なので、MilvusVectorStoreで同じ次元(dim = 1536)を定義する必要があります。さらに、以下のコードを実行すると、知識ベースが格納されたローカルデータベースが作成されます。
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
ステップ4:シンプルなクエリーエンジン
まず、エージェントなしのクエリーエンジンをテストしてみましょう。このエンジンはクロード3.5ソネットで動作し、インデックス内の関連するコンテンツを検索します。
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
res = query_engine.query("Milvus でサポートされているベクトルの最大次元は?")
print(res)
"""
出力します:
Milvusはデフォルトで32,768次元までのベクトルをサポートしています。しかし、さらに高い次元のベクトルを扱う必要がある場合は、'Proxy.maxDimension' パラメータの値を増やすオプションがあります。これにより、Milvusはデフォルトの制限を超える次元のベクトルに対応することができます。
"""
ステップ5:エージェントクエリーエンジン
エージェントが使用するクエリエンジンのラッパーツールとして動作します。
from llama_index.core import VectorStoreIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.llms.anthropic import Anthropic
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
query_engine_tool = QueryEngineTool(
query_engine=query_engine、
metadata=ToolMetadata(
name="knowledge_base"、
説明=(
"MilvusのFAQに関する情報を提供します。"
"詳細なプレーンテキストの質問をツールの入力として使用する。"
),
),
)
ステップ6:AIエージェントの作成
このケースで使用されるエージェントは、LlamaIndexの FunctionCallingAgentWorker である。このエージェントは、改善された回答を生成するために、クエリーエンジンツールを使用してクエリーレスポンスにcritic reflectionを採用する。
from llama_index.core.agent import FunctionCallingAgentWorker
agent_worker = FunctionCallingAgentWorker.from_tools(
[query_engine_tool], llm=llm, verbose=True
)
agent = agent_worker.as_agent()
response = agent.chat("Milvusでサポートされる最大ベクトル次元は?")
print(str(response))
"""
出力する:
ユーザーメッセージをメモリに追加しました:Milvusでサポートされる最大ベクトル次元は?
=== LLMからの回答
Milvusでサポートされる最大ベクトル次元についてのご質問にお答えするには、Milvus FAQの知識ベースを参照する必要があります。そのため、私がお答えします。
=== 呼び出し関数 ===
呼び出し関数: knowledge_base with args: {"input":"Milvusでサポートされる最大ベクトル次元は?"}.
=== 関数の出力 ===
Milvusはデフォルトで32,768次元までのベクトルをサポートしています。しかし、さらに高い次元のベクトルを扱う必要がある場合、'Proxy.maxDimension'パラメータの値を大きくするオプションがあります。これにより、Milvusはデフォルトの制限を超える次元のベクトルに対応することができます。
=== LLM レスポンス ===
MilvusのFAQナレッジベースの情報に基づき、以下のようにお答えします:
Milvusでサポートされる最大ベクトル次元はデフォルトで32,768です。つまり、Milvusはデフォルトで32,768次元までのベクトルを扱うことができ、ほとんどのアプリケーションに適しています。
しかし、Milvusはさらに高次元のベクトルを扱う必要がある場合にも柔軟に対応できるようになっています。32,768次元を超えるベクトルが必要な場合、この制限を増やすことができます。これはMilvusの設定で'Proxy.maxDimension'パラメータを調整することで可能です。
まとめると
1.デフォルトの最大寸法: 32,768
2.増やすことができる:Proxy.maxDimension'パラメータを変更することで可能。
この柔軟性により、Milvusは典型的な機械学習やAIアプリケーションから、非常に高次元のベクトルを必要とするような特殊なシナリオまで、幅広いユースケースに対応することができます。
MilvusのFAQナレッジベースの情報に基づき、以下のようにお答えします:
Milvusでサポートされる最大ベクトル次元はデフォルトで32,768です。つまり、Milvusはデフォルトで32,768次元までのベクトルを扱うことができ、ほとんどのアプリケーションに適しています。
しかし、Milvusはさらに高次元のベクトルを扱う必要がある場合にも柔軟に対応できるようになっています。32,768次元を超えるベクトルが必要な場合、この制限を増やすことができます。これはMilvusの設定で'Proxy.maxDimension'パラメータを調整することで可能です。
まとめると
1.デフォルトの最大寸法: 32,768
2.増やすことができる:Proxy.maxDimension'パラメータを変更することで可能。
この柔軟性により、Milvusは一般的な機械学習やAIアプリケーションから、非常に高次元のベクトルを必要とするような特殊なシナリオまで、幅広いユースケースに対応することができます。
"""
エージェントの出力は、情報源、答えの背後にある理由、トピックに関連するいくつかの追加提案を含む、より詳細な答えを提供します。これはLLMモデルによって与えられた答えをよりよく理解するのに役立つ。
エージェントのRAGアーキテクチャ
今作ったエージェント型RAGの完全なアーキテクチャは以下のようになっている。
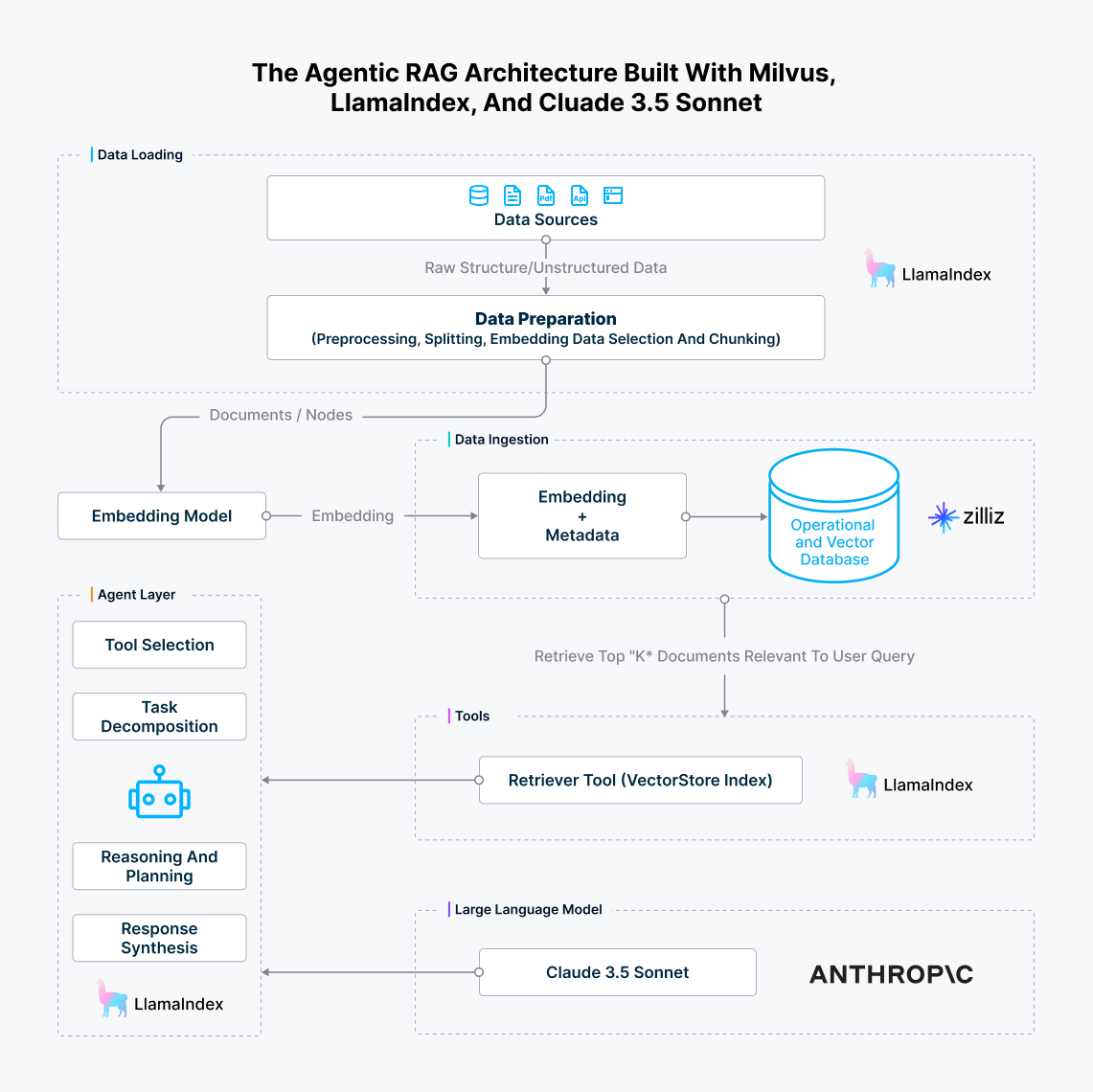 Milvus、LlamaIndex、Cluade 3.5 Sonnet.pngで構築したエージェント型RAGアーキテクチャ
Milvus、LlamaIndex、Cluade 3.5 Sonnet.pngで構築したエージェント型RAGアーキテクチャ
図7: Milvus、LlamaIndex、Cluade 3.5 Sonnetで構築されたエージェントRAGアーキテクチャ
結論
Bill Zhangは講演の中で、LLMシステムの進化する状況を探求し、スタンドアローンモデルからRAGとエージェントを組み込んだより複雑なアーキテクチャへの移行を強調した。LLM、RAG、エージェントはそれぞれ長所と短所を持っている。複合AIのコンセプトは、様々なボトルネックに対処するように設計されたモジュール式システムの構築を可能にし、パイプラインの全体的な効率を向上させる。
このような先進的なシステムの成果は有望であり、量産可能な実装が一般的になりつつあるが、特にこれらのシステム内でのエージェントの動作の管理とカスタマイズには、いくつかの課題が残っている。特定のユースケースで効率的に動作するようにこれらのコンポーネントを微調整することは、現在進行中の開発分野である。
GenAI、VectorDB、MLに関するその他のリソース
ベクターデータベースとは何か、どのように機能するのか】(https://zilliz.com/learn/what-is-vector-database)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
RAGとは】(https://zilliz.com/learn/Retrieval-Augmented-Generation)
Zillizクラウド開発者ハブ](https://docs.zilliz.com/docs/quick-start)
ベクターデータベースのチュートリアルと例](https://milvus.io/docs/tutorials-overview.md)

読み続けて

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.