




LlamaIndexによる高度な検索拡張世代(RAG)アプリの構築
#はじめに
先日のZilliz(サンフランシスコ)主催のUnstructured Data Meetupで、LlamaIndexのデベロッパーリレーション担当副社長であるLaurie Voss氏が「LlamaIndexを使った高度なRAGアプリの構築」というテーマで講演を行った。彼は、LlamaIndexを使ってRetrieval Augmented Generation (RAG)フレームワークをよりシンプルにし、プロダクションに対応させる方法についての知識を共有した。
.RAGのコンセプトを掘り下げ、LlamaIndex 🦙がRAGアプリの開発をどのように支援するかを見てみましょう。LlamaIndex(以前はGPTIndexとして知られていた)の背景を簡単に説明すると、彼らの初期の仕事の多くは、OpenAIのような堅牢なクローズドソースの技術を使って行われてきた。しかし、オープンソースのモデルが追いつき始めると、彼らはオープンソースの代替技術と統合し始めた。それがLLMであれ、埋め込みモデルであれ、再ランキング技術であれ、現在では、ユーザーが自分のデータを使ってRAGアプリケーションを構築するための多くのオプションをカバーしている。
検索拡張世代(RAG)とは?
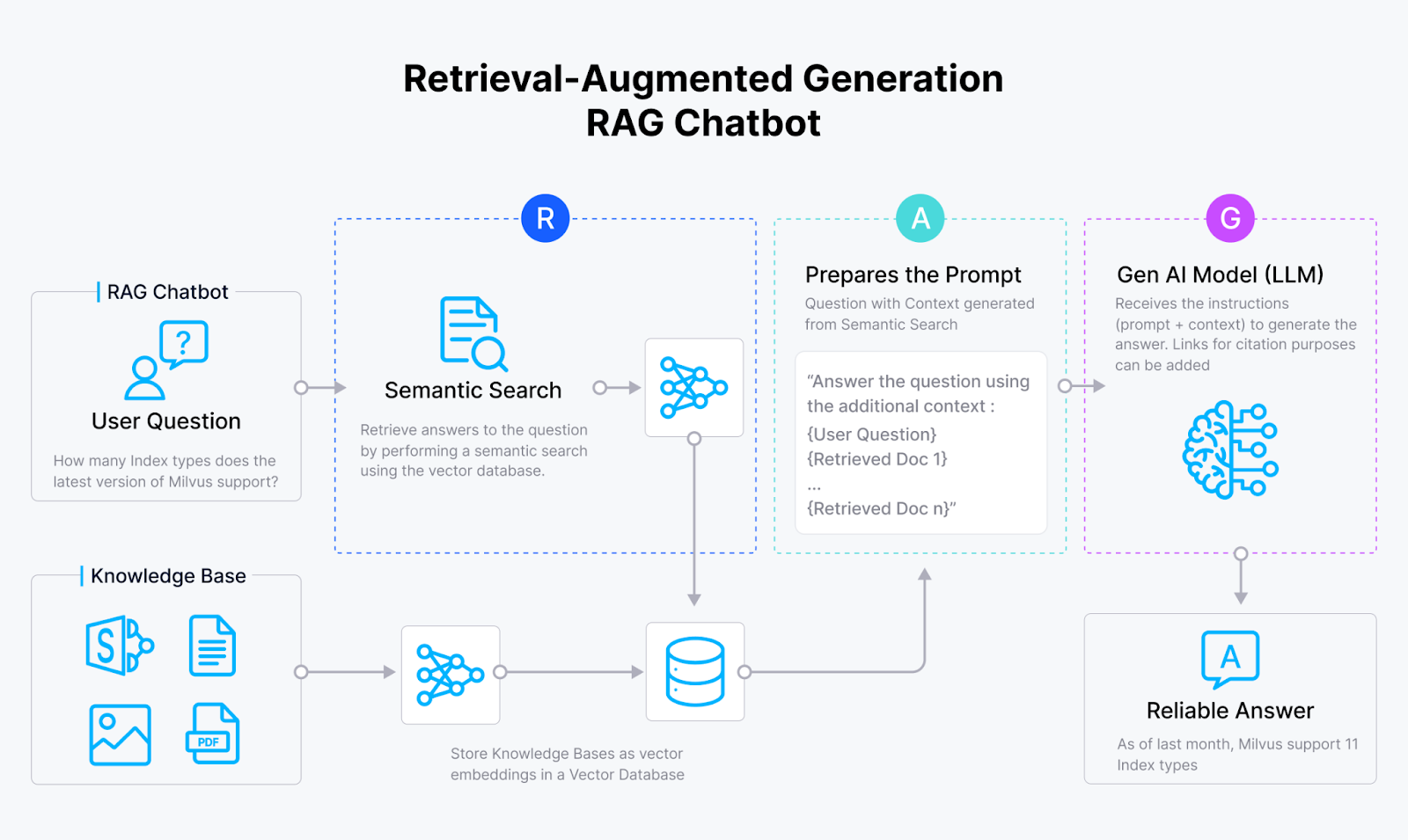
*システム化されたRAGワークフロー
RAGは、LLMの検索機能を支援することによって、LLMの限界を克服するために設計されたフレームワークである。LLMの主な欠点は、コンテキストウィンドウが限られており、組織のデータの一部しか同時に扱えないことである(一度に100万トークンを超えることはない)。RAGは、最も正確な回答を提供するために、最も関連性の高いテキスト/データのみを選択的に検索することでこの問題に対処する。
RAGの主な利点
正確さ:実装された検索方法によって関連性の高い簡潔なデータが検索され、LLMに送信されると、正確な応答が保証されます。
再帰性:なぜ企業は自社のデータを使ってLLMを訓練しないのか、という疑問を持つ人もいるかもしれない。微調整の課題は、LLMをどのような環境にも、特に高品質の環境にもロードすることは、すでにコストがかかるということである。一方、RAG(retrieval-augmented Generation)では、簡単にリアルタイムでデータを更新することができる。このため、RAGは、大規模な私立法律事務所や産業企業に見られるような、動的なデータ環境にとって実用的なソリューションとなる。
実績:RAGは情報のニッチソースを追跡することができ、これは検証可能なデータを必要とするアプリケーションにとって極めて重要です。
簡単に説明すると、子供の頃にやった理解度テストを思い出してください。RAGはそれに非常に似ている。検索されたテキストの塊は理解力として機能し、そこから子供(LLM)はクエリに答えなければならない。とても簡単なことだ。)
高度なRAGテクニック
情報検索には2つのテクニックが広く使われている。
1.キーワード検索:伝統的なキーワード検索法は、特定の用語に基づいてデータを検索するのに有効である。
2.ベクトル検索(Most Powerful):ベクトル類似検索とも呼ばれる:ベクトル検索とは、単語をベクトルと呼ばれる数値リストに変換するものだと考えてください。このベクトルは、それぞれの単語の意味の本質を捉えている。これらのベクトルを数値的な近さ(主に余弦類似度またはドット積で測定)に基づいて比較することで、類似した単語を見つけることができます。ベクトル検索は、データをより効果的かつ確実に検索するのに役立つ。ベクトル検索を実行すると、LLMはクエリに答えるために最も関連性の高いテキストにアクセスできる。
検索エンジンはRAGシステムで様々なソースから文書を検索するために使用され、関連情報の検索を強化し、AIツールの全体的な応答性を向上させる。
ベクトル検索といえば、オックスフォード辞書を思い浮かべてほしい。ただし、単語を意味ごとにグループ化するのではなく、文字の並びでグループ化する。ベクトル埋め込み](https://zilliz.com/glossary/vector-embeddings)モデルは、同じことを次元的に行う。
ベクトル埋め込み](https://assets.zilliz.com/dimension_f97e7672b3.png)
ベクトル検索を使った用語の次元グループ化と意味
また、Milvusのようなオープンソースのベクターデータベースを使えば、無料でベクターストアを構築できる!こちら](https://milvus.io/docs/quickstart.md)をご覧ください。
LlamaIndex:RAG実装の簡素化
LlamaIndexは、あなたのデータをLLMに接続するオープンソースのフレームワークで、PythonとTypeScriptで利用できる。RAGアプリケーションの作成を簡素化し、開発者は最小限のコードで機能的なRAGシステムを構築することができる。LlamaIndex](https://docs.llamaindex.ai/en/stable/getting_started/starter_example/)のおかげで、基本的なRAG機能を実装するのに必要なPythonコードはわずか5行です。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
LlamaIndex によるデータ取り込みとクエリのための高度なRAG機能
LlamaIndexは、RAGアプリケーションのための高度なデータ取り込みとクエリ機能を幅広く提供します。
データ取り込み
データコネクタ:LlamaIndexのLlamaHubは、Google Drive、Notion、Slack、PostgresやMongoDBのようなデータベースを含む様々なデータソースのコネクタを提供します。
PDF 解析:LlamaIndexは高度なPDF解析機能を提供し、複雑なPDFをMarkdownに変換します。LLMはMarkdownデータの大きな塊で学習されるため、LLMの理解をより深めることができます。
モデルの埋め込み:LlamaIndexは様々なオープンソースとクローズドソースの埋め込みモデルをサポートしており、ドメインに基づいたカスタマイズが可能です。
ベクターストア:LlamaIndex は、MilvusやZilliz Cloud,など、オープンソース、クローズドソースを問わず、複数のベクトルデータベースと統合しており、効率的な保存と検索が可能です。
クエリ
- サブクエッションクエリーエンジン
複数のシンプルなクエリを必要とする複雑な質問に対して、サブクエスチョン・クエリー・エンジンはメインのクエリをより小さなパーツに分解し、異なるソースから答えを取得し、それらを1つのレスポンスにまとめます。
より良い検索のためのクエリ分解](https://assets.zilliz.com/Query_Breakdown_for_better_retrieval_eb145345b9.png)
より良い検索のためのクエリ分解
別レスポンスコレクション](https://assets.zilliz.com/Separate_Responses_Collection_3145ca9041.png)
個別の回答集
 最終回答集
最終回答集
最終回答集
コードはこちら](https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine/)を参照。
- 小さな検索から大きな検索へ
この手法では、極めて小さなテキスト片(ユーザークエリに関連性が高く、関連する可能性が高い文)をベクトルに埋め込み、その文の周りのベクトルのウィンドウを上下に検索する。
スモール・トゥ・ビッグ検索手法の可視化](https://assets.zilliz.com/Small_to_Big_Retrieval_methodology_visualization_afbad8712d.png)
スモールからビッグへの検索手法の可視化
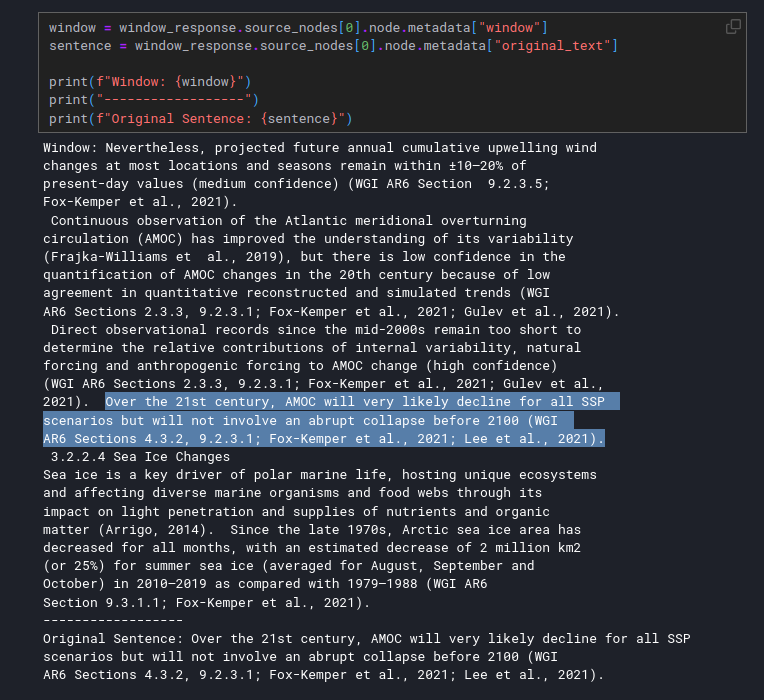 実際の実装
実際の実装
実際の実装
コードはこちら](https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo/)を参照。
- メタデータのフィルタリング](https://zilliz.com/blog/metadata-filtering-hybrid-search-or-agent-in-rag-applications)
下の例のように、文書にあらかじめメタデータ(年、ユーザー、会社、キーワードなど)をつけておくと、より正確なフィルタリングと検索が可能になり、LLMの回答の精度が高まります。この機能は、キーワード検索に役立ちます。メタデータは、テキストのカスタムプロパティのようなものだと考えてください。
Tシャツ広告](https://assets.zilliz.com/A_T_shirt_ad_464ed426f0.png)
Tシャツ広告
- ハイブリッド検索](https://zilliz.com/blog/hybrid-search-with-milvus)
キーワード検索とベクトル検索を組み合わせることで、ハイブリッド検索は指定された方法でクエリを実行する。信頼度スコアに基づいて結果をマージし、最も関連性の高いデータが検索されるようにする。Code hereに詳しい例がある。
コードはこちら](https://assets.zilliz.com/hybrid_search_85b2158d3c.jpeg)
- エージェント
LlamaIndexエージェントは、目標を達成するために様々なツールを使用する半自律的なソフトウェアである。複数の検索戦略とツールを組み合わせて、複雑なクエリに効果的に答えることができる。
このように考える:ツールは、ユーザがその機能の説明を設定できる、定義済みのユーザ機能であり、エージェントはこれらのツールで動作するエンジニアである。ユーザがLLMに2つの巨大な数の掛け算の結果を直接尋ねると、ほとんどの場合、実際の真実の答えに近い答えを返すだろうが、同じ答えは返さないだろう。しかし、セット記述に基づいて呼び出すことができる乗算ツールを与えれば、数の大小にかかわらず一貫して正しい答えを出すだろう。
シンプル・エージェント・ワークフロー](https://assets.zilliz.com/Simple_Agentic_Workflow_fe081ea88f.jpeg)
単純なエージェント型ワークフロー
同様に、ユーザはLLMにツールとその説明を与え、特定のRAGクエリに対してどれを使うかを決定させることで、Agentic RAG Workflowを構築することができる。
高度なRAGの要約
Laurieのプレゼンテーションでは、LlamaIndexを使って最小限のコード行で構築できる、RAGのための基本的で高度なアプリケーションフレームワークが紹介された。LlamaIndexはLlamaParseも提供しており、ローカルやクラウド上のMilvusのようなお気に入りのベクトルデータベースにデータをインデックスするのに役立つ。どのような使い方をするかは、最終的にはユーザー次第だ。このプレゼンテーションでは、検索と生成を最適化するために選択できる様々なRAG戦略も紹介した。
引用文献
1.Liu, Jerry."Llamahub."Llamahub, 2023, https://cloud.llamaindex.ai/parse.
2.Liu, Jerry."Starter Tutorial (OpenAI)".LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/getting_started/starter_example/.
3."ラマ・ハブ"Llama Hub, 2023, https://llamahub.ai/.
4.LlamaIndex."ハイブリッド検索".LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/vector_stores/MilvusHybridIndexDemo/.
5.LlamaIndex."LLMベースのエージェント"LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/use_cases/agents/.
6.LlamaIndex."メタデータ置換+ノード文ウィンドウ"LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo/.
7.LlamaIndex."サブ質問クエリーエンジン"LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine/.
8.Milvus."Milvus."Milvus: Vector database, 2019, https://milvus.io/.
9.Milvus."Milvus Vector Datbases".Milvus: Vector database, 2023, https://milvus.io/.
10.Milvus."クイックスタート Milvus ドキュメント"Milvus, 5 May 2024, https://milvus.io/docs/quickstart.md.

読み続けて

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.