




LLaVA: avanzamento dei modelli di visione-linguaggio attraverso la messa a punto dell'istruzione visiva
Lo stato dell'arte dei modelli linguistici di grandi dimensioni (LLMs come ChatGPT, LLAMA e Claude Sonnet ha dimostrato che le istruzioni basate sul linguaggio umano possono essere un potente strumento per migliorare la qualità delle risposte. Utilizzando tecniche come prompt engineering, possiamo guidare gli LLM a generare risposte che si adattino maggiormente ai nostri casi d'uso specifici.
Inizialmente, i LLM erano stati progettati esclusivamente per input basati sul testo. Quando venivano date istruzioni testuali, generavano una risposta corrispondente. Sebbene questo approccio abbia avuto un grande successo, l'espansione di queste capacità agli input visivi è una progressione naturale. I modelli basati sulla vista accettano come input sia un'istruzione testuale sia un'immagine, consentendo di svolgere compiti quali la sintesi del contenuto di un'immagine, l'estrazione di informazioni o la traduzione del testo all'interno di un'immagine.
In questo articolo esploreremo LLaVA (Large Language and Vision Assistant), uno degli sforzi pionieristici per implementare istruzioni basate sul testo per modelli basati sulla vista. Prima di entrare nei dettagli della sua implementazione, facciamo un passo indietro per capire l'evoluzione dei modelli basati sulla vista e come stanno trasformando il settore.
Sviluppo dei modelli basati sulla visualizzazione
Nelle prime fasi di sviluppo, la maggior parte dei modelli basati sulla visione si basava su architetture basate su reti neurali convoluzionali (CNN) per eseguire compiti visivi comuni. Nella sua forma più semplice, un modello basato sulla visione può essere costruito con una coppia di strati CNN per eseguire un semplice compito di classificazione delle immagini, come ad esempio determinare se una data immagine è di un cane o di un gatto.
Tuttavia, per classificare immagini più complesse e con più classi, è necessario costruire modelli più profondi, composti da centinaia di strati CNN. Maggiore è la profondità degli strati del modello, maggiore è il rischio di incorrere nel problema del gradiente di fuga. Il problema del gradiente che svanisce si riferisce al fenomeno che si verifica durante l'addestramento del modello quando il gradiente diventa così piccolo che il modello non è in grado di apprendere nulla e di aggiornare i suoi pesi.
Per risolvere questo problema, nell'architettura del modello sono stati implementati algoritmi sofisticati come residual connections per evitare i problemi di vanishing gradient che si verificano comunemente nei modelli di deep learning. Questo metodo si è rivelato efficace e ha portato alla nascita di ResNet, che in seguito ha ottenuto prestazioni all'avanguardia in molti set di dati di riferimento per la classificazione delle immagini.
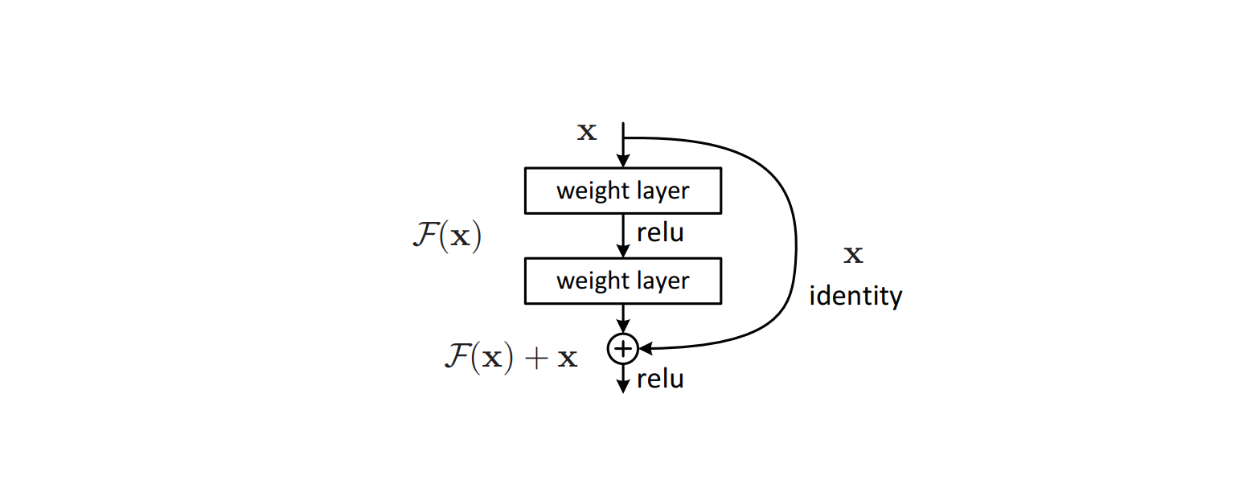
Figura: Blocco di costruzione di una connessione residua all'interno dell'architettura di un modello.
Il successo di ResNet ha ispirato altre architetture di modelli in grado di svolgere compiti di immagine più complessi. Modelli visivi come YOLO hanno implementato connessioni residue nella loro architettura per eseguire compiti di rilevamento di oggetti. Allo stesso tempo, U-Net ha utilizzato una combinazione di architettura a U e connessioni residue per eseguire compiti di segmentazione delle immagini.
Sebbene questi modelli visivi siano in grado di eseguire compiti basati sulla vista, ognuno di essi può eseguire solo un compito specifico. Se un modello è stato addestrato per la classificazione delle immagini, può essere utilizzato solo per questo scopo. Inoltre, se si chiede al modello di classificare un'immagine significativamente diversa da quelle presenti nei dati di addestramento, si può osservare una certa casualità nelle previsioni del modello.
L'introduzione del famoso modello Transformers nel 2017 ha dato il via a un rapido sviluppo dei modelli di deep learning in generale. I modelli che adottano Transformers nella loro architettura hanno superato in modo significativo i modelli più tradizionali. Inizialmente pensata solo per modelli basati sul testo, l'architettura Transformers si è dimostrata abbastanza versatile da poter essere utilizzata anche in modelli basati sulla visione.
I modelli di visione basati su Transformers, come Vision Transformers (ViT), hanno dimostrato un'elevata capacità di eseguire compiti di classificazione delle immagini. Di conseguenza, ViT è ora utilizzato da molti popolari modelli di visione testuale, come CLIP, come architettura portante.
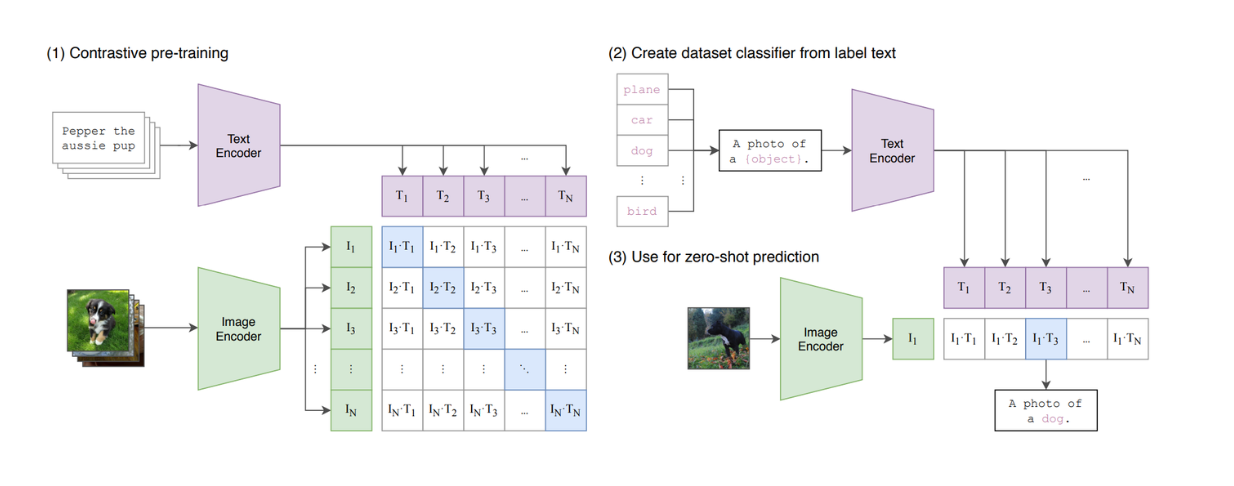
Figura: Una sintesi del modello CLIP._ Fonte_.
CLIP è un modello che combina ViT e un modello simile a BERT nella sua architettura. ViT elabora l'input di immagini, mentre il modello simile a BERT elabora l'input testuale. CLIP è stato addestrato utilizzando l'apprendimento contrastivo: quando vengono dati in ingresso un testo e un'immagine, CLIP calcola la somiglianza tra il testo e l'immagine. Tuttavia, possiamo notare che CLIP è ancora limitato in termini di capacità di imitare i LLM basati sul testo, poiché non è un modello generativo.
LLaVA è uno dei primi LLM basati sulla vista, in grado di prendere in input istruzioni testuali e immagini e di generare una risposta appropriata. Discuteremo i dettagli di LLaVA nella prossima sezione.
Che cos'è LLaVa?
LLaVA (Large Language and Vision Assistant) è un modello multimodale che combina modelli linguistici di grandi dimensioni (LLM) basati sul testo con capacità di elaborazione visiva, consentendogli di gestire input di testo e immagini. È stato progettato per svolgere compiti come la sintesi di contenuti visivi, l'estrazione di informazioni dalle immagini e la risposta a domande su dati visivi.
LLaVA si basa sul successo degli LLM incorporando la comprensione visiva e allineando le istruzioni basate sul testo con l'analisi delle immagini. Questa integrazione consente al modello di elaborare input accoppiati - suggerimenti testuali e immagini - fornendo risposte coerenti e contestualmente rilevanti.
Architettura LLaVA
L'architettura di LLaVA è relativamente semplice. Utilizza un LLM pre-addestrato per elaborare le istruzioni testuali e il codificatore visivo di CLIP pre-addestrato, un modello ViT, per elaborare le informazioni sulle immagini.
Tra i vari LLM pre-addestrati disponibili pubblicamente, gli autori di LLaVA hanno scelto Vicuna come struttura portante per elaborare le informazioni testuali e generare la risposta finale, data una coppia di input testo-immagine.
Poiché la maggior parte dei LLM testuali si basa sull'architettura Transformer, il processo di trasformazione del testo fino alla generazione della risposta è piuttosto semplice. Ogni token del testo in ingresso viene trasformato in un embedding, quindi passa attraverso diversi strati di attenzione e densità prima di produrre la caratteristica finale con una dimensione fissa.
Per elaborare le immagini in ingresso, LLaVA utilizza il modello ViT preaddestrato all'interno di CLIP per trasformare l'immagine in ingresso in una rappresentazione di caratteristiche con una dimensione fissa. Tuttavia, la dimensione della caratteristica dell'immagine di CLIP è diversa da quella della caratteristica del testo di Vicuna. Pertanto, LLaVA implementa un semplice strato denso per proiettare la caratteristica dell'immagine in modo che abbia la stessa dimensione della caratteristica testuale di Vicuna.
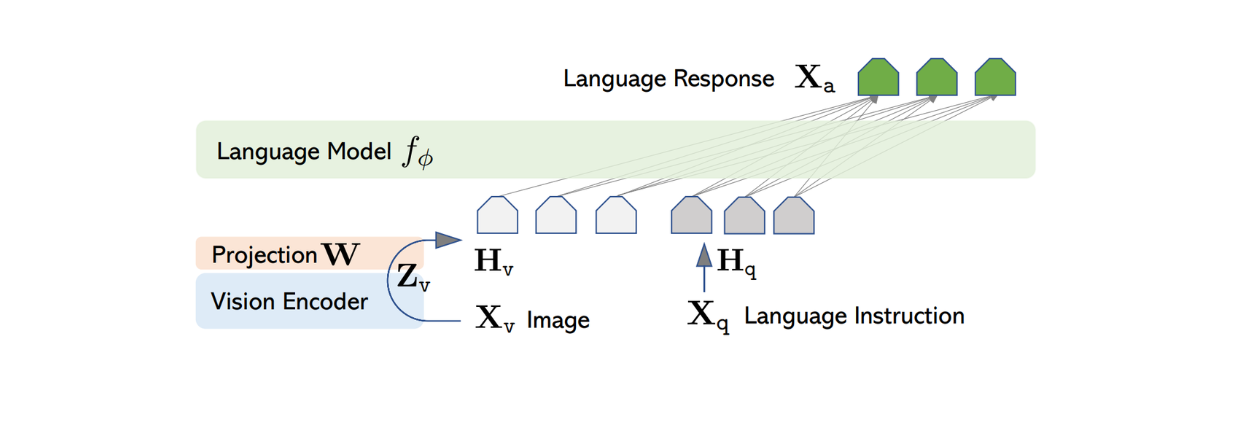
Figura: Architettura di LLaVA. Fonte.
Ora che le caratteristiche di immagine e di testo hanno la stessa dimensione, è necessario un approccio per combinare queste due caratteristiche in una sola. Esistono diversi approcci comunemente utilizzati per farlo, come la semplice preposizione della caratteristica dell'immagine davanti alla caratteristica del token ([caratteristica dell'immagine] + [caratteristica del testo]), o l'utilizzo di algoritmi più sofisticati come la gated cross-attention e il Q-former. Le caratteristiche combinate dell'immagine e del testo vengono poi inserite in Vicuna, consentendogli di generare una risposta appropriata.
Tuttavia, implementando l'approccio di cui sopra, la qualità della risposta generata da Vicuna o da qualsiasi altro LLM simile potrebbe non essere ottimale. Ciò è prevedibile in quanto i LLM sono addestrati esclusivamente su dati testuali. Pertanto, LLaVA deve essere messo a punto prima di poter generare risposte coerenti sulla base di una coppia di immagini-testo. Questo processo di messa a punto è chiamato [sintonizzazione delle istruzioni visive] (https://arxiv.org/abs/1512.03385), di cui parleremo nelle prossime sezioni.
Processo di generazione dei dati per la sintonizzazione delle istruzioni visive
Il Visual Instruction Tuning è un processo di addestramento di modelli di intelligenza artificiale multimodali per comprendere e rispondere a istruzioni basate sul testo abbinate a input visivi, come immagini o video. Questa tecnica allinea la comprensione visiva con le capacità di elaborazione del linguaggio naturale, consentendo al modello di eseguire compiti come la didascalia delle immagini, la risposta a domande visive, il riconoscimento di oggetti e l'estrazione di informazioni.
Una delle sfide principali della sintonizzazione delle istruzioni visive è la mancanza di dati multimodali disponibili pubblicamente. Sebbene esistano diversi dataset costituiti da coppie immagine-testo, come CC e LAION, non sono esattamente il tipo di dataset che vorremmo utilizzare per mettere a punto i LLM basati sulla visualizzazione per seguire le istruzioni dell'utente.
Figura: Esempio di dataset CC. Fonte.
D'altra parte, la creazione manuale di un'enorme quantità di dati di istruzioni multimodali per mettere a punto LLaVA richiederebbe un notevole sforzo e tempo. Pertanto, possiamo sfruttare GPT-4 o ChatGPT per accelerare il processo di creazione di dati multimodali di istruzioni-seguito.
Come si è visto nell'esempio dell'immagine CC di cui sopra, i comuni set di dati multimodali consistono in una coppia di testo immagine-didascalia in ogni record di dati. Con ChatGPT, data un'immagine e la sua didascalia, possiamo generare un insieme di possibili domande volte a istruire i LLM a descrivere il contenuto dell'immagine. Il formato dei dati multimodali che seguono le istruzioni sarà quindi il seguente: Umano: Xq Xv
Tuttavia, sappiamo che le precedenti iterazioni di ChatGPT accettano solo testo come input. Per poterlo utilizzare per curare un elenco di domande relative a un'immagine specifica, è necessario fornire informazioni o metadati sull'immagine. Gli autori hanno utilizzato due approcci diversi per fornire a ChatGPT le informazioni necessarie su qualsiasi immagine in ingresso: le didascalie e i riquadri di delimitazione. Le didascalie consistono solitamente in descrizioni dettagliate dell'immagine, mentre i riquadri di delimitazione forniscono a ChatGPT informazioni utili sulla posizione esatta degli oggetti nell'immagine.

Figura: Esempio di didascalia e riquadri di delimitazione per acquisire informazioni visive per GPT-4 di solo testo. Fonte.
Gli autori hanno creato tre tipi di dataset di istruzioni multimodali:
Conversazione: Consiste in una conversazione avanti e indietro tra il LLM e l'utente. Le risposte del LLM sono impostate con il tono di chi guarda l'immagine e poi risponde alle domande dell'utente. Le domande tipiche includono il contenuto visivo dell'immagine, il conteggio degli oggetti nell'immagine, la posizione relativa degli oggetti nell'immagine, ecc.
Descrizioni dettagliate: consiste in un elenco di domande volte a generare descrizioni complete di un'immagine.
Ragionamento complesso: consiste in domande che vanno oltre i due tipi precedenti. Invece di limitarsi a descrivere il contenuto visivo di un'immagine, queste domande mirano a costringere il LLM a spiegare la logica che sta dietro alle sue risposte, richiedendo un ragionamento passo dopo passo.

Figura: Esempio di tre tipi di istruzioni multimodali che seguono il dataset._ Fonte_.
Di seguito è riportato un esempio di prompt utilizzato dagli autori per generare un dataset di tipo conversazione:
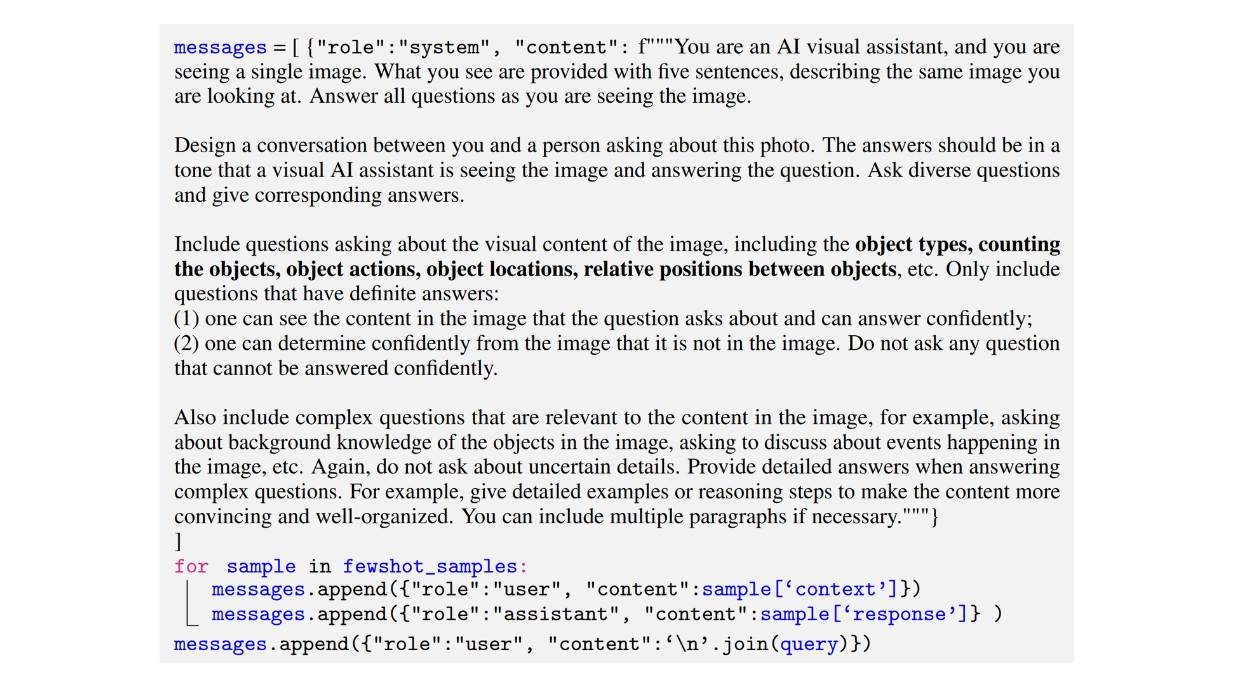
Figura: Esempio di prompt utilizzato per generare un dataset di istruzioni multimodali di tipo conversazione-seguimento._ Fonte.
Ottenere l'output desiderato con il formato corretto dai dati multimodali di istruzioni-following generati da LLM è piuttosto complicato. Per questo motivo, nel chiedere a ChatGPT di generare tutti e tre i tipi di set di dati di istruzioni multimodali, gli autori hanno utilizzato campioni di pochi scatti per sfruttare la potenza dell'apprendimento in contesto.
Con i campioni di pochi scatti, gli autori hanno fornito un paio di esempi creati manualmente di conversazioni tra il LLM e l'utente accanto al prompt. Questi esempi di pochi scatti aiutano ChatGPT a comprendere meglio la struttura dell'output atteso. Di seguito è riportato un esempio di esempio di pochi scatti implementato dagli autori nel prompt per generare un set di dati di conversazione.

Figura: Esempio di esempio di pochi scatti da passare a fianco del prompt per l'apprendimento in contesto._ Fonte.
Procedura di addestramento di LLaVA
Il totale dei dati relativi alle istruzioni multimodali generate con l'approccio di cui sopra era di circa 158K. Successivamente, è stato messo a punto un modello LLaVA con questi dati multimodali.
Nel dataset, per ogni immagine Xv, ci sono conversazioni a più turni tra il LLM e gli utenti (X1q, X1a, - - - , XTq, XTa), dove T è il numero totale di turni. Per ogni turno t, la risposta Xta è trattata come la risposta del LLM e quindi l'istruzione al turno t sarebbe:
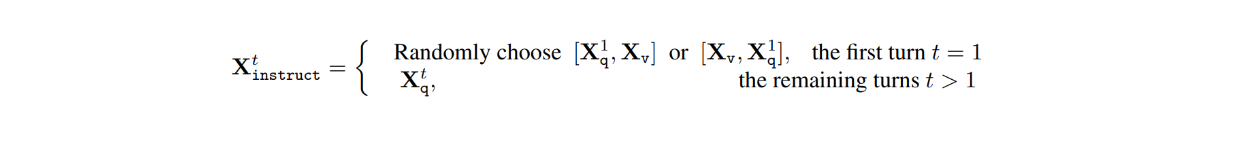
Successivamente, durante il processo di messa a punto delle istruzioni visive, sono state condotte due fasi: il pre-training per l'allineamento delle caratteristiche e il fine-tuning end-to-end.
Durante la fase di pre-addestramento per l'allineamento delle caratteristiche, lo scopo principale è quello di addestrare lo strato di proiezione che mappa l'output del modello ViT dall'encoder CLIP pre-addestrato in una caratteristica visiva finale che ha la stessa dimensione della caratteristica del testo. In questa fase, il processo di addestramento è stato effettuato utilizzando il dataset CC filtrato, che contiene 596K coppie immagine-testo. Per ogni immagine Xv, la domanda Xq viene campionata casualmente da un pool di domande e la corrispondente Xc viene utilizzata come etichetta di verità. Pertanto, le domande campionate per l'addestramento sono quelle che chiedono al LLM di descrivere brevemente l'immagine, come si può vedere nell'immagine sottostante:

Figura: Esempio di domande per spiegare brevemente il contenuto di un'immagine.
Poiché stiamo addestrando solo lo strato di proiezione, i pesi di ViT e LLM sono congelati in questa fase.
Nel frattempo, durante la seconda fase, che consiste nella messa a punto end-to-end, il modello LLaVA viene messo a punto con i dati multimodali generati da 158K che seguono le istruzioni. In questa fase, solo i pesi del ViT sono congelati, mentre i pesi dello strato di proiezione e del LLM vengono aggiornati durante il processo di messa a punto.
Risultati LLaVA
Per valutare le prestazioni di LLaVA, è stato condotto un confronto con altri modelli allo stato dell'arte, come GPT-4, e con modelli basati sulla visualizzazione, come BLIP-2 e OpenFlamingo. Per la valutazione dei risultati, gli autori hanno utilizzato GPT-4 solo testo come giudice per assegnare un punteggio alla qualità delle risposte in base a utilità, pertinenza, accuratezza e livello di dettaglio.
Come prima valutazione, sono state selezionate 30 immagini casuali dal set di dati COCO-Val-2014 e, utilizzando il processo di generazione dei dati spiegato nella sezione precedente, sono stati generati tre tipi di set di dati. Il risultato è stato un totale di 90 punti dati: 30 per le conversazioni, 30 per le descrizioni dettagliate e 30 per i ragionamenti complessi. Le risposte di LLaVA sono state poi confrontate con i risultati del modello GPT-4 solo testo, che utilizza una descrizione/caption testuale come etichetta e i riquadri di delimitazione come input visivo. I risultati sono i seguenti:
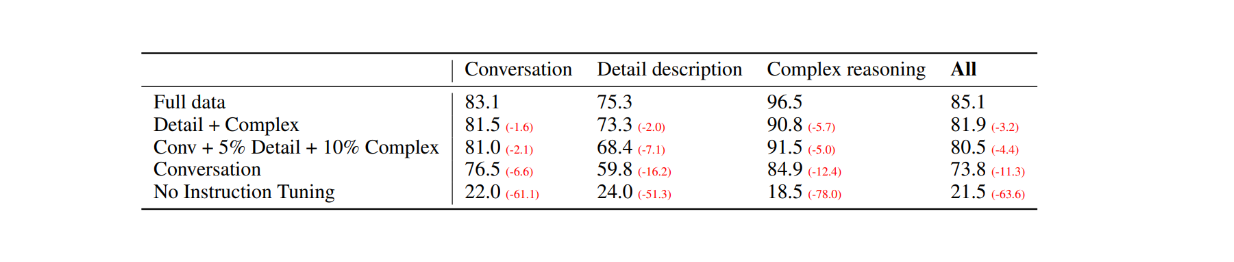
Figura: Confronto delle prestazioni tra LLaVA e GPT-4 solo testo su 30 immagini casuali._ Fonte.
Con la messa a punto delle istruzioni visive, la capacità del modello di seguire le istruzioni è aumentata di almeno 50 punti in ogni tipo di set di dati. Nel frattempo, il punteggio relativo di LLaVA non era molto distante da quello del modello GPT-4 di solo testo che utilizza le didascalie delle immagini come input visivo, come mostrano i numeri tra parentesi in ogni categoria.
Le prestazioni di LLaVA sono state confrontate anche con modelli basati sulla visualizzazione, come BLIP-2 e OpenFlamingo, prendendo prima 24 immagini casuali con 60 domande in totale. Come mostrato nella tabella seguente, le prestazioni di LLaVA sono di gran lunga superiori a quelle degli altri due modelli basati sulla visualizzazione. Questo dimostra la potenza della messa a punto delle istruzioni visive, dato che BLIP-2 e OpenFlamingo non sono stati messi a punto esplicitamente con un set di dati di istruzioni multimodali.

Figura: Confronto delle prestazioni tra LLaVA e BLIP-2 e OpenFlamingo.
Esaminiamo ora un esempio delle risposte dei modelli in azione. Consideriamo un'immagine di crocchette di pollo che formano una mappa del mondo e chiediamo: "_Puoi spiegare questo meme in dettaglio?" Di seguito sono riportati gli esempi di risposta di LLaVA, GPT-4 di solo testo, BLIP-2 e OpenFlamingo.

Figura: Esempi di risposte di LLaVA, GPT-4, BLIP-2 e OpenFlamingo.
Come si può notare, entrambi i modelli BLIP-2 e OpenFlamingo non sono riusciti a seguire le istruzioni, poiché non sono stati messi a punto con la messa a punto delle istruzioni visive. Nel frattempo, LLaVA ha dimostrato la sua capacità di ragionamento visivo nella comprensione dell'umorismo. Insieme a GPT-4, è stato in grado di fornire una risposta concisa secondo le istruzioni.
Quando è stato messo a punto sul dataset ScienceQA per circa 12 epoche, LLaVA ha ottenuto risultati molto competitivi rispetto al modello MM-CoT, che rappresenta l'attuale stato dell'arte (SOTA) su questo dataset. Come mostrato nella tabella seguente, LLaVA ha ottenuto un'accuratezza complessiva del 90,92% su diversi soggetti, rispetto al 91,68% del modello MM-CoT. Tuttavia, quando il risultato di LLaVA è stato combinato con GPT-4, le prestazioni hanno raggiunto un nuovo SOTA sul dataset ScienceQA con un'accuratezza del 92,53%.
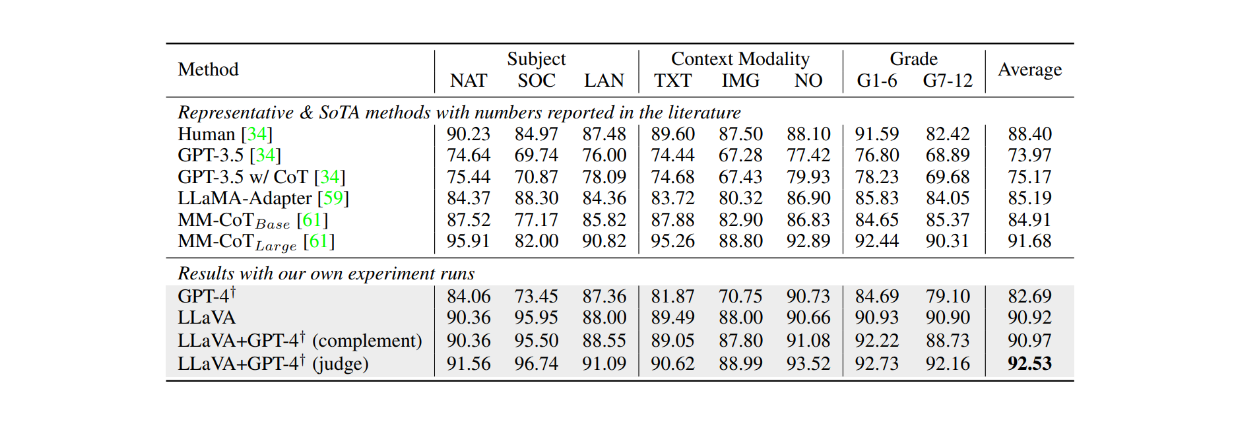
Figura: Accuratezza di LLMs sul dataset ScienceQA._ Fonte.
Conclusione
LLaVA rappresenta un primo passo avanti nello sviluppo di Large Language Models (LLM) basati sulla vista e in grado di seguire istruzioni testuali. Il modello combina un Vision Transformer (ViT) pre-addestrato di CLIP per l'elaborazione delle immagini con Vicuna come struttura portante del modello linguistico, utilizzando un livello di proiezione per allineare le dimensioni delle caratteristiche tra i due componenti. Il modello è stato poi messo a punto su 158K campioni di dati di istruzioni multimodali da seguire.
Grazie a questo approccio di sintonizzazione delle istruzioni visive, LLaVA è in grado di descrivere ed eseguire ragionamenti complessi su una data immagine in base alle istruzioni contenute nel prompt. I risultati della valutazione dimostrano l'efficacia della messa a punto delle istruzioni visive, in quanto le prestazioni di LLaVA superano costantemente quelle di altri due modelli basati sulla visualizzazione: BLIP-2 e OpenFlamingo.
Ulteriori letture
Continua a leggere

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.