




Costruire un RAG multilingue con Milvus, LangChain e OpenAI LLM
Negli ultimi due anni, la Retrieval Augmented Generation (RAG) è diventata rapidamente una delle tecniche più popolari per la costruzione di applicazioni GenAI basate su modelli linguistici di grandi dimensioni (LLM). La RAG migliora l'output di un LLM fornendo informazioni contestuali su cui il modello non è stato preaddestrato. Multilingual RAG è un RAG esteso che gestisce dati di testo in più lingue.
Yujian Tang, CEO di OSS4AI, è intervenuto di recente a un Unstructured Data Meetup organizzato da Zilliz. Ha parlato di RAG e dei suoi componenti fondamentali e ha dimostrato come costruire un RAG multilingue per affrontare le diverse sfide linguistiche del mondo reale.
In questo post, riassumeremo i punti chiave della presentazione di Yujian e vi guideremo nell'implementazione di una RAG multilingue. Se volete saperne di più sul discorso di Yujian, vi consigliamo di guardare la sua presentazione su YouTube.
Cos'è il RAG e come funziona?
Un limite fondamentale delle applicazioni basate su LLM è la loro dipendenza dai dati su cui sono state addestrate. Se l'LLM non è stato esposto a determinate informazioni o a un intero dominio di conoscenza durante il pre-addestramento, non può comprendere le relazioni linguistiche necessarie per generare risposte accurate. Questa mancanza di dati può portare l'LLM ad ammettere di non conoscere la risposta o, peggio, ad "avere le allucinazioni" (https://zilliz.com/glossary/ai-hallucination) e a fornire informazioni errate.
La RAG è una tecnica popolare che risolve i problemi di allucinazione dei LLM fornendo loro informazioni contestuali aggiuntive. Inoltre, consente agli sviluppatori e alle aziende di accedere ai loro dati privati o proprietari senza preoccuparsi dei problemi di sicurezza.
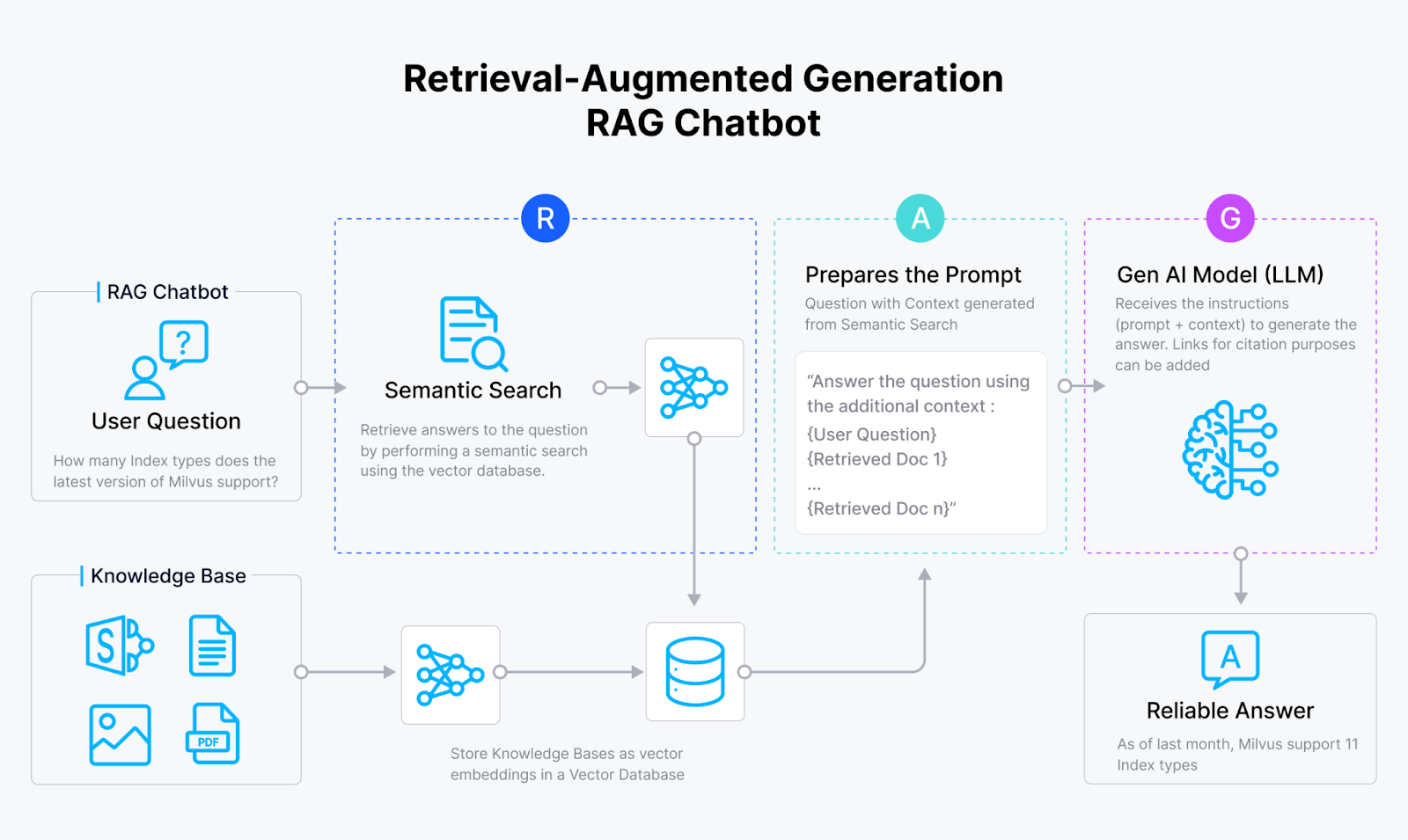 Figura 1- Come funziona RAG
Figura 1- Come funziona RAG
RAG inizia con un modello di embedding che trasforma i dati di testo in embeddings vettoriali, rappresentazioni numeriche che catturano il significato semantico del testo. Il sistema RAG memorizza poi questi vettori in un database vettoriale come Milvus o Zilliz Cloud, che li indicizza per ricerche di similaritàh.
Quando un utente invia una query, il modello di incorporazione converte anche l'input in un vettore. Quindi, il sistema RAG confronta la somiglianza di questo vettore di query con i vettori del database vettoriale calcolando la loro distanza nello spazio vettoriale ad alta dimensione. Se vengono trovati dati rilevanti, il sistema RAG recupera queste informazioni e le aggiunge alla query originale per formare un nuovo prompt per il LLM. Il LLM utilizza queste informazioni aggiuntive per generare una risposta più accurata e contestualmente rilevante, superando quella che potrebbe produrre basandosi esclusivamente sui dati di addestramento.
Che cos'è il RAG multilingue?
Il RAG multilingue espande le capacità del RAG tradizionale per supportare più lingue. Integra un modello di incorporazione addestrato in varie lingue, consentendo al sistema di elaborare e generare risposte in diverse lingue. Grazie a questo approccio multilingue, il sistema RAG è in grado di gestire interrogazioni in qualsiasi lingua, di recuperare informazioni rilevanti indipendentemente dalla lingua originale e di fornire risposte accurate e contestualmente rilevanti nella lingua preferita dall'utente.
Come costruire un'applicazione RAG multilingue: una guida passo dopo passo
Ora che abbiamo appreso i concetti e i componenti fondamentali di RAG, vediamo di implementare un'applicazione RAG multilingue passo dopo passo.
Questo esempio di applicazione contiene due parti: un web scraper e l'applicazione principale.
Il web scraper** raccoglie i dati richiesti da Internet.
L'applicazione principale** crea incorporazioni vettoriali, esegue una ricerca di similarità vettoriale e genera le risposte.
Il Web Scraper
Per prima cosa, scraperemo i dati da Wikipedia e li useremo come informazioni contestuali per questo esempio di RAG.
Si inizia con la definizione di un elenco chiamato "wiki_titoli", che contiene un elenco di città. Ogni città rappresenta un file di testo che il web scraper popolerà con il contenuto della corrispondente voce di Wikipedia. Ad esempio, "Atlanta.txt" conterrà il testo raschiato dalla pagina Atlanta di Wikipedia.
Si itera su ogni città in "wiki_titles", si fa una richiesta GET all'API di Wikipedia e si estrae il contenuto della pagina dalla risposta JSON. Il testo viene poi salvato in un file di testo corrispondente per ogni città.
da pathlib importare Path
importare richieste
wiki_titoli = [
"Atlanta",
"Berlino",
"Boston",
"Cairo",
"Chicago",
"Copenaghen",
"Houston",
"Karachi",
"Lisbona",
"Londra",
"Mosca",
"Monaco",
"Parigi",
"Pékin", il nome francese di Pechino.
"San Francisco",
"Seattle",
"Shanghai",
"Tokyo",
"Toronto",
]
data_path = Path("./french_city_data")
data_path.mkdir(exist_ok=True) # Assicurarsi che la directory esista
per titolo in wiki_titoli:
response = requests.get(
"https://fr.wikipedia.org/w/api.php",
params={
"action": "query",
"formato": "json",
"titles": titolo,
"prop": "extracts",
"explaintext": Vero,
},
).json()
page = next(iter(response["query"]["pages"].values())
wiki_text = page.get("extract", "") # Usare .get() per evitare KeyError
if wiki_text: # Controlla se l'estratto non è vuoto
con open(data_path / f"{title}.txt", "w") come fp:
fp.write(wiki_text)
altrimenti:
print(f "Nessun estratto trovato per {titolo}")
Preparazione dell'ambiente
Per prima cosa, preparate l'ambiente di sviluppo installando le librerie necessarie: Milvus vector database, LangChain, OpenAI e sentence transformers.
Inoltre, è necessario includere la propria chiave API se ci si connette a un LLM tramite un'API, come OpenAI. Questa chiave può essere memorizzata in un file .env separato e vi si può accedere usando load_dotenv() e os.
Ecco il codice per installare le librerie e caricare la chiave API:
pip install -qU pymilvus langchain sentence-transformers tiktoken openai
da dotenv importiamo load_dotenv
importare os
load_dotenv() # Carica le variabili d'ambiente dal file .env
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") # Impostazione della chiave API
Installare le librerie: Usare
pipper installarepymilvus,langchain,sentence-transformers,tiktokeneopenai.Caricare le variabili d'ambiente:** Usare
dotenvper caricare le variabili d'ambiente da un file.env.Imposta chiave API:** Recupera la chiave API di OpenAI dalle variabili d'ambiente e impostala.
Assicurarsi che il file .env contenga la chiave API OpenAI nel seguente formato:
OPENAI_API_KEY=la_tua_chiave_api_qui
Inizializzazione dell'LLM
Una volta configurato l'ambiente, il passo successivo è definire l'LLM che si utilizzerà nell'applicazione. Nello snippet di codice che segue, si ottiene questo risultato importando la libreria OpenAI e definendo l'LLM con il costruttore di OpenAI.
da langchain.llms importare OpenAI
llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Si può optare per un LLM open-source per evitare i costi associati alle chiamate API di OpenAI. Hugging Face offre centinaia di migliaia di modelli di deep-learning con cui sperimentare. Per utilizzare un LLM open-source di HuggingFace, è necessario importare la libreria Transformers.
da transformers importare pipeline
llm = pipeline('text-generation', model='gpt2') # Sostituire 'gpt2' con il modello desiderato
È possibile passare da OpenAI a un modello open-source modificando il codice di importazione e inizializzazione.
Scelta di un modello di incorporamento appropriato
Quando si costruisce un sistema RAG multilingue, la scelta del modello di incorporamento è importante quanto la scelta del LLM, poiché il modello di incorporamento deve essere compatibile con la lingua con cui si lavora. Per questo esempio, in cui la lingua è il francese, le incorporazioni predefinite di HuggingFace sono sufficienti. Tuttavia, è necessario identificare e utilizzare il modello di incorporamento più adatto per altre lingue.
La MTEB Leaderboard su HuggingFace è una risorsa preziosa per trovare modelli di incorporamento. Questa classifica elenca i modelli di incorporamento più performanti per varie lingue, come gli incorporamenti in cinese e polacco identificati da Yujian. Quando si seleziona un modello di embedding, è necessario specificare il nome del modello come parametro.
Ecco come impostare il modello di embedding:
da langchain_community.embeddings importare HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
# In alternativa, per gli embeddings cinesi, il modello viene # passato come parametro, ad es,
# HuggingFaceEmbeddings(model_name="TownsWu/PEG")
Caricare e dividere i dati in pezzi
Successivamente, carichiamo i file di dati sulle città che abbiamo recuperato da Wikipedia e li dividiamo in segmenti, o chunks. Suddividendo il testo, si evita di confrontare una query con l'intero documento, migliorando così l'efficienza del recupero delle informazioni. Quanto più piccolo è il chunk, determinato dal parametro chunk_size, tanto maggiore è l'accuratezza, ma sono necessarie più operazioni di recupero. Maggiore è la sovrapposizione tra i chunk, definita da chunk_overlap, minore è la possibilità di perdere il contesto, a costo di una maggiore ridondanza.
da langchain.text_splitter import CharacterTextSplitter
da langchain.schema import Document
files = os.listdir("./french_city_data")
file_testi = []
per file in file:
con open(f"./french_city_data/{file}") as f:
file_testo = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64,
)
testi = text_splitter.split_text(file_text)
per i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text,
metadata={"doc_title": file.split(".")[0], "chunk_num":i}))
Caricamento dei documenti in Milvus
Dopo aver suddiviso i file dei dati della città e averli memorizzati come elenco di documenti, occorre caricarli in un archivio vettoriale, in questo caso il database vettoriale Milvus. Il codice seguente gestisce il caricamento iniziale e gli aggiornamenti quando i dati della città sono memorizzati in Milvus.
da langchain_community.vectorstores import Milvus
# Per la prima esecuzione
vector_store = Milvus.from_documents(
file_testi,
embedding=embeddings,
connection_args={"host": "localhost", "port": 19530},
nome_collezione="città_francesi"
)
# se i dati sono già memorizzati in Milvus
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="città francesi"
)
Creare un recuperatore
Successivamente, inizializzeremo il nostro retriever, un'interfaccia che restituisce documenti da una particolare fonte in base a una determinata query. Il codice che segue utilizza come retriever l'archivio vettoriale creato nell'ultimo passo e lo assegna a una variabile.
retriever = vector_store.as_retriever()
Creare un modello di prompt usando LangChain
I modelli di prompt consentono di formattare con precisione l'input a un LLM all'interno della propria applicazione. Sono particolarmente utili nei casi in cui si voglia riutilizzare lo stesso schema di prompt, ma con piccoli aggiustamenti, come nel caso della nostra applicazione RAG multilingue, in cui possiamo usare lo stesso modello di prompt per diverse lingue.
I modelli di prompt consentono anche di costruire un prompt a partire da un input dinamico, ad esempio l'input dell'utente o i dati recuperati da un archivio vettoriale. Nella nostra applicazione, includeremo dinamicamente la domanda, che verrà passata direttamente nella catena, e il contesto che il retriever ha ottenuto dall'archivio vettoriale.
da langchain.prompts import ChatPromptTemplate
template="""
Siete un assistente che risponde alle domande. Utilizzate i seguenti elementi del contesto recuperato per rispondere alla domanda. Se non conoscete la risposta, dite semplicemente che non la conoscete.
Utilizzate al massimo tre frasi e mantenete la risposta concisa.
Rispondete in francese.
Domanda: {domanda}
Contesto: {contesto}
Risposta:"""
prompt = ChatPromptTemplate.from_template(template)
Concatenare i componenti per creare l'applicazione RAG
Il concatenamento è un processo che collega i componenti per creare applicazioni AI end-to-end, ed è una delle funzionalità chiave di LangChain.
Il codice seguente mostra come costruire una catena che include i seguenti elementi: il contesto dal retriever, il prompt di input elaborato dalla funzione runnablepassthrough(), il modello di prompt, l'LLM e stroutparser(), che produce la risposta dall'invocazione della catena.
da langchain_core.runnables import RunnablePassthrough
da langchain_core.output_parsers import StrOutputParser
catena = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Fare query con la catena
Una volta costruita la catena, è possibile richiamarla con varie query. Ad esempio:
response = chain.invoke("Dimmi un fatto storico su Karachi.")
Questa query produce la seguente risposta in francese!
"Karachi a été mentionnée pour la première fois dans l'ouvrage Histoire des plantes de Théophraste au IIIe siècle av. J.-C. È stata occupata dai britannici all'inizio del XIX secolo ed è diventata la capitale del Sind nel 1839. Nel 1876, il futuro fondatore del Pakistan, Muhammad Ali Jinnah, nacque ed entrò a Karachi".
Per dimostrare le capacità multilingue, ecco un'altra domanda, questa volta in francese:
response_2 = chain.invoke("Racontez-moi un fait historique sur Karachi.")
Nonostante la stessa domanda di fondo, le diverse lingue (inglese e francese) portano a incorporazioni diverse, dando luogo a un output diverso:
"Karachi è una città fondata dai britannici all'inizio del XIX secolo e diventata la capitale del Sind. È stata un importante centro economico e ha conosciuto una rapida crescita, soprattutto grazie al suo porto. A partire dagli anni 1980, la città è stata teatro di conflitti etnici e religiosi e, nel 2012, è stata il luogo dell'incendio industriale più grave della storia".
Congratulazioni! Avete costruito con successo un'applicazione RAG multilingue. Tenete presente che gli embedding sono fondamentali per l'interpretazione delle lingue da parte di LLM. Selezionare l'incorporamento più adatto a supportare più lingue e integrarlo nella propria applicazione.
Riepilogo
Wow! Questo è un post piuttosto lungo. Riassumiamo alcuni dei punti chiave.
Retrieval augmented generation (RAG) è un framework che aumenta l'output di LLM inserendo dati aggiuntivi nelle richieste di input. RAG può risolvere i fastidiosi problemi di allucinazione di LLM.
Multilingual RAG è un RAG esteso che gestisce documenti multilingue.
I modelli di incorporamento, i database vettoriali e gli LLM sono tre componenti fondamentali delle applicazioni RAG.
La considerazione chiave nello sviluppo di applicazioni RAG multilingue è la scelta del modello di incorporamento. La classifica di HuggingFace MTEB è una risorsa eccellente per trovare il modello giusto per la propria applicazione.
Ulteriori risorse
Continua a leggere

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.