




10 framework LLM open source che gli sviluppatori non possono ignorare nel 2025
Il 2024 è stato un anno di grande successo per i modelli linguistici di grandi dimensioni (LLM) e, mentre ci avviamo verso il 2025, lo slancio non mostra segni di rallentamento. Dal GPT-4 e dalle capacità multimodali di Gemini ai sistemi di IA adattivi in tempo reale, gli LLM non sono più solo all'avanguardia: sono essenziali. Stanno alimentando chatbot, motori di ricerca, strumenti per la creazione di contenuti e persino automatizzando flussi di lavoro che un tempo pensavamo potessero essere gestiti solo dagli esseri umani.
Ma il punto è che avere un LLM potente è solo metà della battaglia. Costruire applicazioni LLM scalabili, efficienti e pronte per la produzione può essere una sfida: è qui che entrano in gioco i framework LLM. Semplificano i flussi di lavoro, migliorano le prestazioni e si integrano perfettamente con i sistemi esistenti, aiutando gli sviluppatori a liberare tutto il potenziale di questi modelli con meno sforzo.
In questo post, metteremo in evidenza 10 framework LLM open-source che gli sviluppatori di intelligenza artificiale non possono ignorare in vista del 2025. Questi framework sono le armi segrete che aiutano gli sviluppatori a scalare, ottimizzare e innovare più velocemente che mai. Se siete pronti a migliorare i vostri progetti di IA, tuffatevi!
LangChain: Alimentare i flussi di lavoro dell'intelligenza artificiale in più fasi e consapevoli del contesto
LangChain è un framework open-source progettato per semplificare lo sviluppo di applicazioni basate su grandi modelli linguistici (LLM). Semplifica la creazione di flussi di lavoro che combinano gli LLM con fonti di dati esterne, API o logica computazionale, consentendo agli sviluppatori di creare sistemi dinamici e consapevoli del contesto per attività quali agenti conversazionali, analisi di documenti e sintesi.
Funzionalità chiave
Pipeline componibili**: LangChain semplifica la concatenazione di più chiamate LLM e funzioni esterne, consentendo complessi flussi di lavoro in più fasi.
Catene disponibili**: LangChain offre catene preconfigurate, assemblaggi organizzati di componenti progettati per svolgere compiti specifici di livello superiore. Queste catene "off-the-shelf" semplificano l'avvio dei progetti.
Utilità di ingegneria dei progetti: Include strumenti per la creazione, la gestione e l'ottimizzazione di prompt personalizzati per compiti specifici.
Gestione della memoria: Offre funzionalità integrate per conservare il contesto conversazionale nelle interazioni, consentendo applicazioni più personalizzate.
LangChain si è collegato con API di terze parti, database vettoriali, LLM e varie fonti di dati. In particolare, l'integrazione di LangChain con database vettoriali come Milvus e Zilliz Cloud ne aumenta ulteriormente il potenziale. Milvus è un database vettoriale open-source ad alte prestazioni per la gestione e l'interrogazione di vettori di incorporamento su scala miliardaria. Completa le funzionalità di LangChain consentendo un recupero rapido e accurato dei dati rilevanti. Gli sviluppatori possono sfruttare questa integrazione per costruire sistemi scalabili Retrieval-Augmented Generation (RAG) in cui Milvus recupera documenti contestualmente rilevanti. LangChain utilizza un modello generativo per produrre risultati accurati e significativi. Per ulteriori informazioni, consultate le seguenti risorse:
Sbloccare il potere del linguaggio: introduzione a LangChain
Come costruire una RAG multilingue con Milvus, LangChain e OpenAI
Generazione aumentata di recupero su Notion Docs tramite LangChain
LlamaIndex: Collegare i LLM a diverse fonti di dati
LamaIndex è un framework open-source che consente ai modelli linguistici di grandi dimensioni (LLM) di accedere e sfruttare in modo efficiente diverse fonti di dati. Semplifica l'ingestione, la strutturazione e l'interrogazione di dati non strutturati, facilitando la creazione di applicazioni AI avanzate come il recupero di documenti, la sintesi e i chatbot basati sulla conoscenza.
Funzionalità chiave
Connettori di dati**: Fornisce un robusto set di connettori per l'acquisizione di dati strutturati e non strutturati da fonti diverse come PDF, database SQL, API e archivi vettoriali.
Strumenti di indicizzazione**: Consente agli sviluppatori di creare indici personalizzati, comprese strutture ad albero, ad elenco e a grafo, per ottimizzare l'interrogazione e il recupero dei dati.
Ottimizzazione delle query**: Offre meccanismi di interrogazione avanzati che consentono di ottenere risposte precise e contestualmente pertinenti.
Estensibilità: Altamente modulare, facilita l'integrazione con librerie e strumenti esterni per migliorare le funzionalità.
Struttura ottimizzata per gli LLM**: Progettato per lavorare con gli LLM, garantendo un uso efficiente delle risorse computazionali per compiti su larga scala.
LlamaIndex si è integrato con diversi database vettoriali appositamente creati, come Milvus e Zilliz Cloud, per supportare flussi di lavoro RAG scalabili ed efficienti. In questa configurazione, Milvus funge da backend ad alte prestazioni per la memorizzazione e l'interrogazione dei vettori di incorporazione, mentre LlamaIndex struttura e organizza i dati recuperati per l'elaborazione da parte degli LLM. Questa combinazione consente agli sviluppatori di recuperare i punti di dati più rilevanti e permette agli LLM di fornire risultati più accurati e consapevoli del contesto. Per ulteriori informazioni, consultare le risorse seguenti:
Haystack: Semplificare le pipeline RAG per applicazioni AI pronte per la produzione
Haystack è un framework Python open-source progettato per facilitare lo sviluppo di applicazioni basate su LLM. Consente agli sviluppatori di creare soluzioni di IA end-to-end integrando gli LLM con varie fonti di dati e componenti, rendendoli adatti a compiti quali RAG, ricerca di documenti, risposta a domande e generazione di risposte.
Capacità chiave
Pipeline flessibili**: Haystack consente di creare pipeline modulari per attività come il recupero di documenti, la risposta a domande e la sintesi. Gli sviluppatori possono combinare diversi componenti per adattare i flussi di lavoro alle loro esigenze specifiche.
Architettura Retriever-Reader: Combina i retriever per un filtraggio efficiente dei documenti con i lettori (ad esempio, LLM) per generare risposte precise e consapevoli del contesto.
Backend Agnostico: Supporta diversi backend di database vettoriali, tra cui Milvus e FAISS, garantendo flessibilità nell'implementazione.
Integrazione con i modelli linguistici**: Fornisce una perfetta integrazione con i modelli linguistici, consentendo agli sviluppatori di utilizzare modelli pre-addestrati e ottimizzati per vari compiti.
Scalabilità e prestazioni**: Ottimizzato per la gestione di insiemi di dati su larga scala e di query ad alta velocità, adatto alle applicazioni aziendali.
Nel marzo 2024, Haystack ha rilasciato Haystack 2.0, introducendo un'architettura più flessibile e personalizzabile. Questo aggiornamento consente di creare pipeline complesse con funzioni come la ramificazione parallela e il looping, migliorando il supporto per gli LLM e il comportamento agonico. Il nuovo design enfatizza un'interfaccia comune per l'archiviazione dei dati, fornendo integrazioni con vari database e archivi vettoriali, tra cui Milvus e Zilliz Cloud. Questa flessibilità garantisce che i dati possano essere facilmente accessibili e gestiti all'interno delle pipeline di Haystack, supportando lo sviluppo di applicazioni di intelligenza artificiale scalabili e ad alte prestazioni. Per ulteriori informazioni, consultare le risorse riportate di seguito:
Haystack GitHub: https://github.com/deepset-ai/haystack
Integrazione: Haystack e Milvus
Tutorial: Retrieval-Augmented Generation (RAG) con Milvus e Haystack
Tutorial: Costruire una pipeline RAG con Milvus e Haystack 2.0
Dify: Semplificare lo sviluppo di app basate su LLM
Dify è una piattaforma open-source per la creazione di applicazioni AI. Combina Backend-as-a-Service con LLMOps, supportando i principali modelli linguistici e offrendo un'interfaccia di orchestrazione intuitiva. Dify fornisce motori RAG di alta qualità, un framework di agenti AI flessibile e un flusso di lavoro low-code intuitivo, consentendo sia agli sviluppatori che agli utenti non tecnici di creare soluzioni AI innovative.
Capacità chiave
Backend-as-a-Service per LLM: Gestisce l'infrastruttura di backend, consentendo agli sviluppatori di concentrarsi sulla creazione di applicazioni piuttosto che sulla gestione dei server.
Orchestrazione dei prompt: Semplifica la creazione, la verifica e la gestione di prompt personalizzati per compiti specifici.
Analisi in tempo reale**: Fornisce informazioni sulle prestazioni dei modelli, sulle interazioni degli utenti e sul comportamento delle applicazioni per ottimizzare i flussi di lavoro.
Opzioni di integrazione**: Si connette con API di terze parti, strumenti esterni e LLM popolari, offrendo flessibilità per flussi di lavoro personalizzati.
Dify si integra bene con i database vettoriali come Milvus, migliorando la sua capacità di gestire attività di recupero dati complesse e su larga scala. Abbinando Dify a Milvus, gli sviluppatori possono creare sistemi che memorizzano, recuperano ed elaborano in modo efficiente gli embeddings per attività come RAG.
Esercitazione: Distribuzione di Dify con Milvus
Letta (precedentemente MemGPT): Costruire agenti RAG con la finestra di contesto LLM estesa
Letta è un framework open-source progettato per migliorare gli LLM dotandoli di memoria a lungo termine. A differenza dei tradizionali LLM che elaborano gli input in modo statico, Letta consente al modello di ricordare e fare riferimento alle interazioni passate, consentendo applicazioni più dinamiche, consapevoli del contesto e personalizzate. Integra tecniche di gestione della memoria per memorizzare, recuperare e aggiornare le informazioni nel tempo, rendendolo ideale per creare agenti intelligenti e sistemi di conversazione che si evolvono con le interazioni degli utenti.
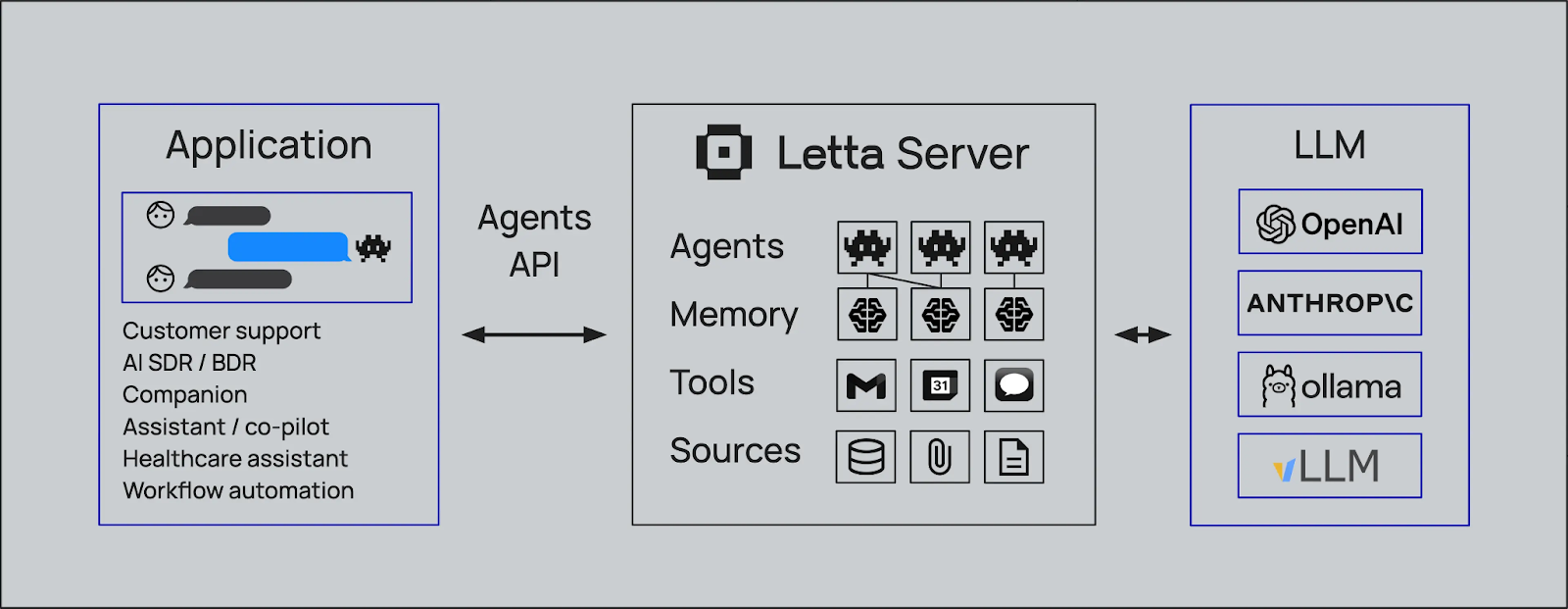 Figura - Come funziona Letta con vari strumenti di IA
Figura - Come funziona Letta con vari strumenti di IA
Capacità chiave
Memoria auto-modificante: Letta introduce la memoria auto-modificante, consentendo agli agenti di aggiornare autonomamente la propria base di conoscenze, di imparare dalle interazioni e di adattarsi nel tempo.
Agent Development Environment (ADE): Fornisce un'interfaccia grafica per la creazione, la distribuzione, l'interazione e l'osservazione di agenti AI, semplificando il processo di sviluppo e di debug.
Persistenza e gestione dello stato: Assicura che gli agenti mantengano la continuità tra le sessioni persistendo il loro stato, comprese le memorie e le interazioni, consentendo risposte più coerenti e pertinenti al contesto.
Integrazione di strumenti:** Supporta l'incorporazione di strumenti e fonti di dati personalizzati, consentendo agli agenti di eseguire un'ampia gamma di attività e di accedere a informazioni esterne, se necessario.
Architettura agnostica dei modelli:** Progettato per funzionare con diversi LLM e sistemi RAG, fornendo flessibilità nella scelta e nell'integrazione di diversi fornitori di modelli.
Letta si è integrato con i principali database vettoriali per migliorare le sue capacità di memoria e di recupero per i flussi di lavoro RAG avanzati. Sfruttando l'archiviazione vettoriale scalabile e l'efficiente ricerca di similarità, Letta consente agli agenti di intelligenza artificiale di accedere e conservare le conoscenze contestuali a lungo termine, garantendo un recupero dei dati rapido e accurato. Questa integrazione consente agli sviluppatori di creare applicazioni più intelligenti e consapevoli del contesto, adatte a domini specifici, come l'assistenza clienti o le raccomandazioni personalizzate, mantenendo una memoria persistente e scalabile. Per ulteriori informazioni, consultate le risorse riportate di seguito.
- Tutorial | MemGPT con integrazione Milvus
Blog | Introduzione a MemGPT e alla sua integrazione con Milvus
Paper | [2310.08560] MemGPT: Verso i LLM come sistemi operativi
Vanna: Abilitare la generazione di SQL con l'AI
Vanna è un framework Python open-source progettato per semplificare la generazione di query SQL attraverso input in linguaggio naturale. Sfruttando le tecniche di RAG, Vanna permette agli utenti di addestrare i modelli sui loro dati specifici, consentendo loro di porre domande e ricevere query SQL accurate e personalizzate per i loro database. Questo approccio semplifica il processo di interazione con i database, rendendolo più accessibile agli utenti che non hanno una vasta esperienza di SQL.
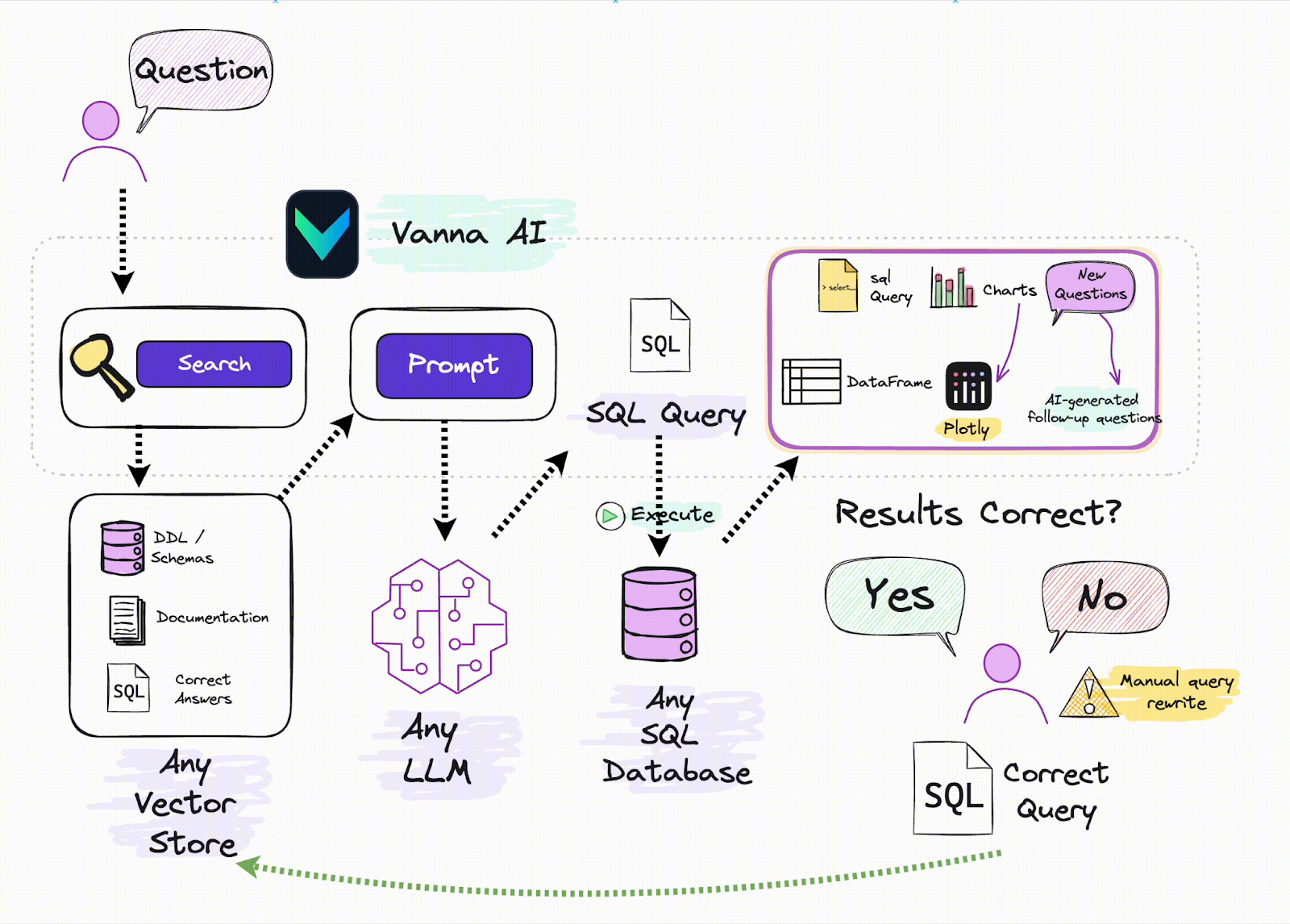 Vanna
Vanna
Capacità chiave
Conversione da linguaggio naturale a SQL: Vanna consente agli utenti di inserire domande in linguaggio naturale, che poi converte in precise query SQL eseguibili sul database collegato.
Supporto per più database: Il framework offre un supporto immediato per diversi database, tra cui Snowflake, BigQuery, Postgres e altri. Inoltre, consente una facile integrazione con qualsiasi database attraverso connettori personalizzati.
Flessibilità dell'interfaccia utente**: Vanna offre diverse opzioni di interfaccia utente, come Jupyter Notebook, Slackbot, applicazioni web e applicazioni Streamlit, consentendo agli utenti di scegliere il front-end che meglio si adatta al loro flusso di lavoro.
Vanna e i database vettoriali sono un'ottima combinazione per costruire sistemi RAG efficaci. Quando un utente inserisce una query in linguaggio naturale, Vanna utilizza un database vettoriale per recuperare i dati rilevanti basati su embeddings vettoriali pre-memorizzati. Questi dati vengono poi utilizzati per aiutare Vanna a generare una query SQL accurata, facilitando il recupero di dati strutturati da un database relazionale. Combinando la potenza della ricerca vettoriale con la generazione di SQL, Vanna semplifica il lavoro con i dati non strutturati e consente agli utenti di interagire con insiemi di dati complessi senza bisogno di conoscenze avanzate di SQL. Per ulteriori informazioni, consultate le risorse qui sotto:
Tutorial: Scrivere SQL con Vanna e Milvus
Milvus + Vanna: generazione di SQL con intelligenza artificiale
Kotaemon: Costruire una QA dei documenti alimentata dall'intelligenza artificiale
Kotaemon è un'interfaccia RAG open-source e personalizzabile per chattare con i documenti. Fornisce un'interfaccia web pulita e multiutente per la QA dei documenti che supporta modelli linguistici locali e basati su API. kotaemon offre una pipeline RAG ibrida con capacità di recupero full-text e vettoriale, consentendo una QA multimodale per documenti con figure e tabelle.
Progettato sia per gli utenti finali che per gli sviluppatori, kotaemon supporta metodi di ragionamento complessi come ReAct e ReWOO. Presenta citazioni avanzate con anteprime dei documenti, impostazioni configurabili per il recupero e la generazione e un framework estensibile per la creazione di pipeline RAG personalizzate.
 Kotaemon
Kotaemon
Capacità chiave
Facilità di distribuzione: Kotaemon offre interfacce semplici per distribuire gli LLM in produzione con una configurazione minima, consentendo una rapida scalabilità e integrazione.
Pipeline personalizzabili**: Permette agli sviluppatori di personalizzare facilmente i flussi di lavoro dell'intelligenza artificiale, combinando gli LLM con API esterne, database e altri strumenti.
Prompting avanzato**: Offre strumenti integrati per l'ingegnerizzazione e l'ottimizzazione dei prompt, facilitando la messa a punto dei risultati dei modelli per compiti specifici.
Ottimizzazione delle prestazioni**: Progettato per operazioni ad alte prestazioni, Kotaemon garantisce risposte a bassa latenza e un uso efficiente delle risorse.
Supporto per più modelli**: Il framework supporta diverse architetture LLM, dando agli sviluppatori la flessibilità di scegliere il modello migliore per il loro caso d'uso specifico.
Kotaemon si integra con database vettoriali come Milvus, consentendo il rapido recupero di dati rilevanti per attività come la Retrieval-Augmented Generation (RAG). Sfruttando le efficienti capacità di ricerca vettoriale di Milvus, Kotaemon può migliorare il contesto e la rilevanza dei risultati generati dall'IA. Questa integrazione consente agli sviluppatori di creare sistemi di IA che generano contenuti e recuperano informazioni pertinenti da grandi insiemi di dati, migliorando le prestazioni e l'accuratezza complessive.
vLLM: inferenza LLM ad alte prestazioni per applicazioni AI in tempo reale
vLLM è una libreria open-source sviluppata dallo SkyLab della UC Berkeley, progettata per ottimizzare l'inferenza e il servizio LLM. Concentrandosi sulle prestazioni e sulla scalabilità, vLLM introduce innovazioni come PagedAttention, che aumenta la velocità del servizio fino a 24 volte e dimezza l'uso della memoria della GPU rispetto agli approcci tradizionali. Questo lo rende un punto di svolta per gli sviluppatori che realizzano applicazioni di intelligenza artificiale esigenti che richiedono un utilizzo efficiente delle risorse hardware.
Funzionalità chiave:
Tecnologia PagedAttention: Migliora la gestione della memoria consentendo la memorizzazione non contigua di chiavi e valori di attenzione, riducendo lo spreco di memoria e migliorando il throughput fino a 24 volte.
Aggrega le richieste in arrivo in tempo reale, massimizzando l'utilizzo della GPU e riducendo al minimo i tempi di inattività, con conseguente aumento del throughput e riduzione della latenza.
Output in streaming:** Genera token in tempo reale, consentendo alle applicazioni di fornire immediatamente risultati parziali, ideali per le interazioni con gli utenti in tempo reale come i chatbot.
Compatibilità con i modelli: ** Supporta le architetture LLM più diffuse, come GPT e LLaMA, garantendo flessibilità per molti casi d'uso e una perfetta integrazione con i flussi di lavoro esistenti.
Server API compatibile con OpenAI:** Offre un'interfaccia API che rispecchia quella di OpenAI, semplificando la distribuzione e l'integrazione nei sistemi esistenti per gli sviluppatori che hanno familiarità con le API di OpenAI.
vLLM diventa una pietra miliare per la costruzione di sistemi RAG ad alte prestazioni se combinato con database vettoriali come Milvus. I database vettoriali memorizzano e recuperano in modo efficiente gli embedding ad alta dimensionalità, fondamentali per il reperimento di informazioni contestualmente rilevanti. vLLM completa questo aspetto offrendo un'inferenza LLM ottimizzata, garantendo che le informazioni recuperate vengano elaborate senza problemi in risposte accurate e consapevoli del contesto. Questa integrazione migliora le prestazioni delle applicazioni e risolve problemi come le allucinazioni dell'intelligenza artificiale, fondando gli output sui dati recuperati. Per ulteriori informazioni, consultate le risorse qui sotto.
Distribuzione di un sistema RAG multimodale con vLLM e Milvus
Gestione efficiente della memoria per grandi modelli linguistici con PagedAttention
Unstructured: Rendere accessibili i dati non strutturati per la GenAI
Unstructured è una libreria open-source che semplifica l'ingestione e la pre-elaborazione di dati non strutturati di diversi formati, tra cui PDF, HTML, documenti Word e immagini. Offre funzioni modulari per il partizionamento, la pulizia, l'estrazione, lo staging e il chunking dei documenti, facilitando la trasformazione dei dati non strutturati in formati strutturati. Questo toolkit è utile per ottimizzare i flussi di lavoro dei dati nelle applicazioni Large Language Model (LLM).
L'integrazione di Unstructured con un database vettoriale come Milvus crea una soluzione potente e scalabile per gestire e sfruttare i dati non strutturati nelle applicazioni di intelligenza artificiale. La piattaforma di Unstructured ingerisce, elabora e trasforma i dati non strutturati provenienti da vari tipi di file in embeddings vettoriali pronti per l'IA. Questi embeddings sono fondamentali per i flussi di lavoro avanzati di IA, ma per memorizzarli, indicizzarli e interrogarli in modo efficace è necessario un database vettoriale specializzato. La sinergia tra Unstructured e Milvus (o Zilliz Cloud) consente una pipeline end-to-end semplificata, particolarmente preziosa per la Retrieval-Augmented Generation (RAG) e per altre applicazioni orientate all'IA come i chatbot intelligenti e i sistemi di raccomandazione personalizzati.
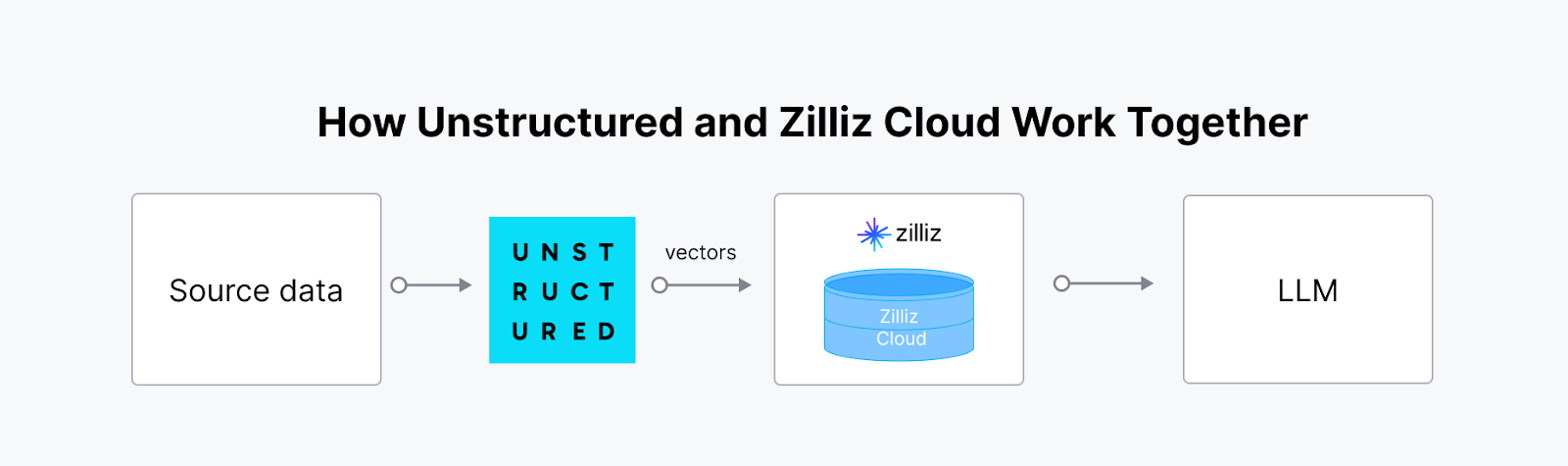 Non strutturato
Non strutturato
Tutorial | Costruire un RAG con Milvus e Unstructured
Blog | Vettorizzazione e interrogazione di contenuti EPUB con Unstructured e Milvus
Langfuse: migliore osservabilità e analisi per le applicazioni LLM
Langfuse è una piattaforma open-source per l'ingegneria LLM che assiste i team nel debug, nell'analisi e nell'iterazione collaborativa delle loro applicazioni LLM. Offre funzionalità quali osservabilità, gestione dei prompt, valutazioni e metriche, tutte integrate in modo nativo per accelerare il flusso di lavoro dello sviluppo.
Funzionalità chiave
Osservabilità end-to-end**: Traccia le interazioni con l'LLM, comprese le richieste, le risposte e le metriche delle prestazioni, per garantire trasparenza e affidabilità.
Gestione dei prompt**: Offre strumenti per la versione, l'ottimizzazione e il test dei prompt, semplificando lo sviluppo di applicazioni AI robuste.
Integrazione flessibile**: Funziona perfettamente con framework popolari come LangChain e LlamaIndex, supportando un'ampia gamma di architetture LLM.
Debug in tempo reale**: Fornisce informazioni utili su errori e colli di bottiglia, consentendo agli sviluppatori di iterare rapidamente.
L'integrazione di Langfuse con i database vettoriali migliora i flussi di lavoro RAG fornendo l'osservabilità della qualità e della rilevanza dell'incorporazione. Questa integrazione consente agli sviluppatori di monitorare e ottimizzare le prestazioni e l'accuratezza della ricerca vettoriale attraverso analisi dettagliate, assicurando che i processi di recupero siano finemente regolati e allineati alle esigenze degli utenti. Per iniziare, consultate il seguente tutorial.
Conclusione
Con l'inizio del 2025, è chiaro che i framework open-source non sono più solo utili componenti aggiuntivi: sono fondamentali per costruire applicazioni LLM robuste. Framework come LangChain e LlamaIndex hanno trasformato il modo in cui integriamo e interroghiamo i dati, mentre vLLM e Haystack stanno stabilendo nuovi parametri di riferimento per velocità e scalabilità. Framework emergenti come Langfuse e Letta apportano punti di forza unici nell'osservabilità e nella memoria, aprendo le porte a sistemi di intelligenza artificiale più intelligenti e reattivi.
Questi framework consentono agli sviluppatori di affrontare sfide complesse, sperimentare idee audaci e superare i limiti del possibile. Con questi framework a portata di mano, il 2025 è l'anno giusto per costruire applicazioni GenAI più intelligenti, veloci e d'impatto.

Continua a leggere

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.