




What is a Data Warehouse? Simplifying Your Data Management

What is a Data Warehouse? Simplifying Your Data Management
TL;DR
A data warehouse is a system that collects and stores data from different sources. It enables organizations to analyze and make informed decisions based on historical data. This article will explain what a data warehouse is, its benefits, its architecture, and its types.
Key Takeaways
A data warehouse centralizes operational data from various sources, providing a single repository for analysis and facilitating informed decision-making.
Data warehousing enhances data quality and accessibility, streamlining the decision-making process and supporting strategic initiatives through comprehensive data analysis.
Modern trends in data warehousing include the adoption of cloud technologies for enhanced scalability and cost-effectiveness, as well as the integration of AI and machine learning to improve analytics capabilities.
Data is the new oil, but it needs to be refined to generate value. Organizations require specialized structures to store and process information to unlock its full potential. A data warehouse serves as the solution for these needs.
The data warehouse is a unified storage and processing center for large-scale datasets. It integrates data from various sources, enabling businesses to execute advanced analytics to generate useful insights. A data warehouse is valuable for artificial intelligence (AI), business intelligence (BI), and fact-based decision-making systems.
Let’s discuss the concept of a data warehouse, its core components, and its characteristics. We will also evaluate the data warehouse against other storage systems and discuss its real-world applications and leading toolsets.
Understanding Data Warehouses
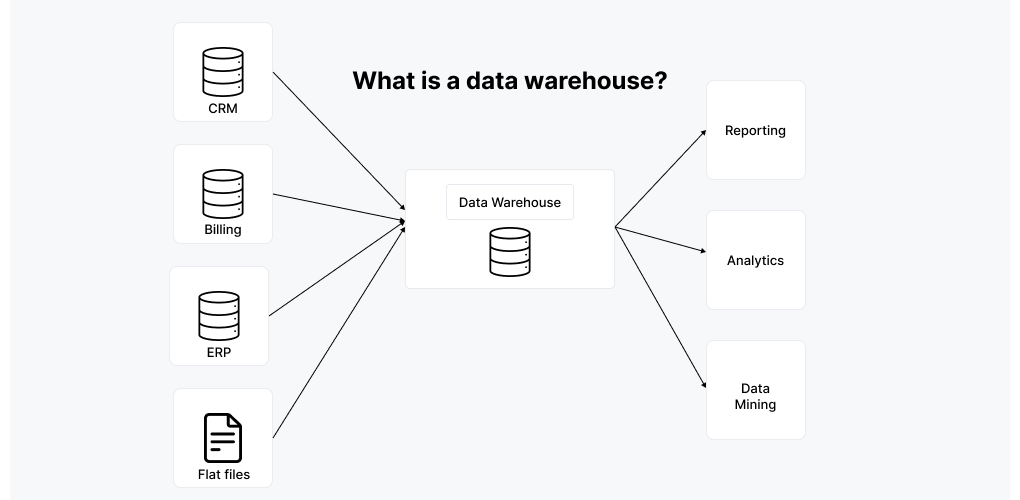 An illustration explaining what is a data warehouse, showing data flows and architecture.
An illustration explaining what is a data warehouse, showing data flows and architecture.
Figure 1: What is a data warehouse?
At its core, a data warehouse centralizes and consolidates extensive operational data from various sources, providing a single repository for analysis. Unlike operational databases that handle day-to-day transactions, data warehouses are designed to store current and historical data, allowing organizations to glean insights over time. This historical perspective is invaluable for identifying trends, forecasting future outcomes, and making informed business decisions.
Data warehouses are the backbone of business intelligence activities, facilitating analytics that drive strategic initiatives. A data warehouse serves as a reliable ‘single source of truth,’ ensuring all business units access consistent and accurate information. Such consistency eliminates data silos and improves data quality, facilitating the work of data scientists and analysts.
The architecture of a data warehouse is meticulously tailored to meet the specific needs of an organization, enhancing both reliability and trust. From data marts that cater to specific business lines to enterprise data warehouses that serve the entire organization, the design and implementation of a data warehousing architecture are critical to its success. Integrating data from various sources into a cohesive framework allows data warehouses to enable comprehensive analysis and actionable insights.
Key Characteristics of a Data Warehouse
Data warehouses differ from other data storage systems due to their features. These features enable a data warehouse to assist business intelligence and analytics. Some of the key characteristics include:
Subject-oriented: The structure inside the data warehouse is organized according to subclass business domains such as sales, marketing, and finance. For instance, a sales data warehouse collects customer transactions, product performance, and regional sales. This makes report generation easier and more focused.
Integrated: The system collects and organizes information from different sources using a schema to ensure consistency. It integrates CRM data, ERP systems, and data from other external APIs.
Time-variant: Data warehouses store older data that can analyze trends over an extended period. This is useful for planning and forecasting. For example, financial organizations can study a few years of transaction data to detect fraud.
Non-Volatile: A data warehouse stores unchanged data, ensuring stable and consistent analytics. Historical data, for example, helps spot year-on-year changes.
Key Benefits of Data Warehousing
The benefits of data warehousing are manifold, starting with enhanced data quality. Data cleansing processes inherent in data warehouse solutions address issues stemming from human errors, system failures, and incompatible formats. This results in more accurate and reliable data, which is crucial for informed decision-making.
Data warehouses significantly reduce the time required for decision-making by consolidating necessary data in a single location. This centralization facilitates easier data analysis, boosting performance and operational capabilities. With all relevant data readily accessible, organizations can manage data effectively to make timely and strategic decisions, giving them a competitive edge in their data mart.
Furthermore, data warehouses support improved decision-making by deriving valuable business insights from consolidated data. A unified view of business operations from data warehouses helps organizations identify opportunities, mitigate risks, and streamline processes. Comprehensive data analysis enhances business intelligence and drives innovation and growth.
How a Data Warehouse Works
A data warehouse is an advanced system that stores, processes, and analyzes data. It comprises several modules that work together to convert data into valuable information. Let’s uncover its core components step-by-step.
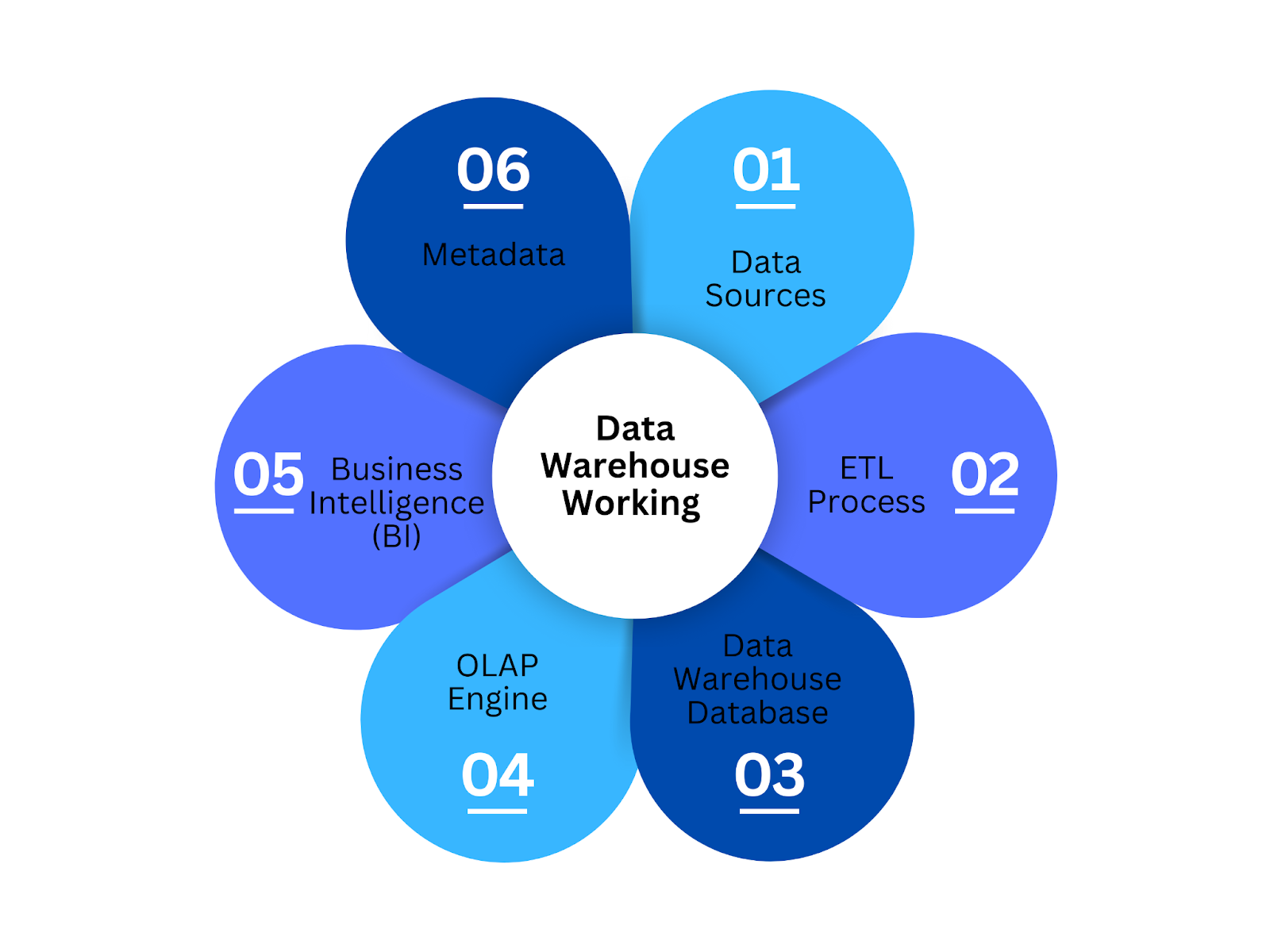 Data Warehouse Working Components
Data Warehouse Working Components
Figure 2: Data Warehouse Working Components
1. Data Sources
Organizations extract information from multiple sources, including internal and external data points. These data sources provide businesses with a complete operational understanding by breaking down data silos. A comprehensive view of operations enables strategic planning while improving operational efficiency and supporting better decisions.
2. ETL Process
The Extract Transform Load (ETL) is the core component for processing data from identified sources. The extraction phase retrieves raw data from different source systems, including transactional spreadsheets and cloud-based applications. During the transformation phase, the raw data undergoes a cleaning process.
The transformation process includes fixing data errors, combining identical records, and changing date formats. The loading phase imports transformed data into the data warehouse for analysis and query purposes. The ETL process creates accurate, reliable data storage in the warehouse while optimizing it for analysis purposes.
3. Data Warehouse Database
The database serves as the central foundation of a data warehouse. A data warehouse database differs from transactional systems because it is designed for analyzing historical data, complex queries, and reporting. In contrast, transactional systems handle real-time operations, mainly day-to-day.
The warehouse stores data through two standard organizational schemas: the star and snowflake. The schemas organize data into two categories: facts, which contain numerical data such as sales figures and dimensions, which hold descriptive information like product names, customer locations, and dates. This enables users to execute sophisticated queries and create reports effortlessly.
4. OLAP Engine
Data warehousing includes an OLAP engine, which facilitates quick multidimensional analysis capabilities. This engine allows users to see their data from multiple perspectives, which helps them detect patterns and trends more efficiently.
The OLAP engine helps recognize trends and patterns using advanced analytical functions like drill-down, roll-up, and slicing. It efficiently solves complex queries, enabling businesses to derive insights from bulky datasets. The engine also allows organizations to make actionable decisions with information transformed from raw data.
5. Business Intelligence (BI)
BI in a data warehouse involves data extraction, analysis, and presentation. BI tools create interactive dashboards, reports, and visualizations that make complex data easier to understand.
Additionally, BI facilitates real-time KPI monitoring through multi-source data integration to support trend analysis. Current BI platforms enable users to perform self-service analytics, allowing them to explore the data independently.
6. Metadata
Metadata serves as the data dictionary, encompassing different transformations done to the stored data, its structure, features, and business rules applied. It connects raw data to advanced insights by ensuring accuracy, consistency, and availability. Metadata is classified into technical, business, and process types.
Technical metadata includes table names, field names and types, index, primary and foreign keys, and dataset relationships. It also captures the ETL (Extract, Transform, Load) process, including data lineage and transformation rules.
Business metadata presents data from higher-level business concepts, definitions, and contexts of storage and use.
Process metadata tracks operational information on data changes, such as changes to modified timestamps, frequency of data loads, and other ETL logs.
Types of Data Warehouses
Data warehouses come in various forms, each suited to different organizational needs. An on-premises data warehouse is deployed on a business’s own infrastructure, allowing complete control over hardware and software. This setup is often preferred by government entities and financial institutions due to its compliance with strict data control regulations.
Cloud data warehouses offer several benefits:
Cost-effective solution with lower upfront capital expenditures
Eliminate the need for physical hardware
Provide a software-as-a-service model
Allow for on-demand scalability
Many organizations are migrating from on-premises to many data warehouses data warehouse server cloud data warehouses to take advantage of these benefits.
Another type is the data warehouse appliance, a preintegrated bundle of hardware and software designed for data warehousing. These appliances offer:
Streamlined deployment
Speed
Ease of scalability
Control over data management
They are ideal for organizations looking for a quick and efficient data warehousing solution.
Evolution of Data Warehouses
The concept of data warehousing began in the 1980s as organizations sought centralized solutions to manage increasing data volumes. Legacy systems, which could only store structured data, were unable to handle the new workloads, prompting the need for more advanced database management system solutions. This marked the beginning of the data warehousing era, aimed at improving data management and analysis.
The transition to cloud data platforms in the 2010s allowed for more flexible and scalable data management compared to traditional on-premises systems. Modern data warehouses now leverage open data lake architecture, integrating AI and machine learning to enhance analytics capabilities within a robust data warehouse infrastructure. This evolution reflects the growing need for robust data solutions that can adapt to the rapid changes in technology and business environments.
Comparison: Data Warehouse vs Other Storage Systems
The data warehouse system stands apart because it enables advanced querying, analytics, and business intelligence operations. A thorough evaluation of a data warehouse requires understanding its distinctions from other data storage systems, including databases and data lakes.
This analysis demonstrates the distinctions between data warehouses and alternative storage solutions. It highlights their unique roles in data management, analysis, and business decision processes:
| Feature | Data Warehouse | Operational Data Stores (ODS) | Data Lake |
|---|---|---|---|
| Data Type | Structured | Structured | Unstructured & Structured |
| Optimization | OLAP | OLTP | Raw Data Processing |
| Purpose | Analytics & Reporting | Operational Reporting & Transactions | Data Storage |
| Performance | Optimized for Queries | Optimized for Real-time Operations | Requires Processing |
| Data Refresh | Batch Processing | Near Real-time Updates | As Needed |
| Use Case | Business Intelligence | Consolidation of Operational Data | Data Science, Machine Learning |
Data Warehouses vs Data Lakes
Data lakes and data warehouses serve different purposes and have distinct characteristics. Data lakes:
Store data in its raw form
Allow for flexible analytics and schema-on-read, where data is interpreted upon access rather than during storage
Are ideal for data scientists and engineers who require vast amounts of unstructured and semi-structured data
Support machine learning and real-time analytics
In contrast, data warehouses store data in a structured format, requiring it to be processed and organized before use. This structured nature makes a typical data warehouse better suited for core reporting and traditional business intelligence use cases, primarily used by data analysts and warehouse professionals, especially when storing data.
While data lakes offer scalability and cost-effectiveness, data warehouses provide the reliability and performance needed for strategic decision-making.
Data Warehouse vs Database
Both data warehouses and databases store data, but they are optimized for different purposes. Data warehouses are specifically designed for analytical processing, while databases are optimized for search on massive datasets. Traditional relational databases usually perform exact searches on structured data while vector databases like Milvus and Zilliz Cloud performs similarity search on massive high-dimensional vector data.
Data Warehouses: Built for Analytics
Data warehouses are designed to handle complex analytical query operations across extensive datasets. They operate as unified storage facilities that combine data from transactional databases with CRM systems and external APIs.
The data structure gives businesses one unified perspective, revealing advanced insights about their business trends. Data warehouses implement star or snowflake schemas for their denormalized structure because they improve query speed and make data access easier.
Key features of a data warehouse include:
Optimized for Analytical Queries: Data warehouses execute advanced analytical queries, including aggregation operations, statistical analysis, and multidimensional data exploration. This is vital to performing trend analysis, forecasting, and strategic planning.
Columnar Storage: A data warehouse uses columnar storage, which surpasses row-based systems by enabling quick queries and optimized data compression capabilities. The columnar storage format delivers better performance results, particularly when analyzing particular columns within big datasets.
Batch Processing: Data warehouses use batch processing to load data while maintaining system performance for source systems. This method works well for organizations needing periodic reporting.
Historical Data Management: Data warehouses allow users to conduct time-series analysis and monitor performance over extended periods, such as months or years.
Milvus: A High-Performance Vector Database
Milvus is a purpose-built vector database that is optimized for similarity searches and the processing of high-dimensional data. Unlike traditional databases, it handles unstructured data by converting them into vectors. Widely used in AI applications like recommendation systems, NLP, and computer vision, it enables fast and accurate similarity searches. Key features include:
Optimized for Vector Search: Milvus uses Approximate Nearest Neighbor (ANN) algorithms for high-speed similarity searches. This optimization allows for retrieval of the most relevant data points regardless of the size of the dataset.
Hybrid Row-Column Storage: Milvus implements a column-oriented storage system to provide efficient data access operations on the specific fields used in query processing. The designed approach delivers better operational results, mainly when workloads rely heavily on reading data.
Real-Time Processing: The system supports dynamic data updates and real-time execution of queries. This is crucial for applications that provide immediate response, such as recommendation systems.
Scalability: Milvus features a shared-storage architecture for computing and storage. This enables horizontal scaling, which allows a business to improve data processing without affecting performance.
The Role of ETL in Data Warehousing
ETL, which stands for Extract, Transform, Load, is a critical process in preparing data for analysis in a data warehouse. The extract transform and load process involves extracting data from various sources, transforming it into a consistent format, and loading it into the data warehouse. This process ensures that the data is ready for analysis and reporting, maintaining data consistency and quality.
ETL automates the process of data integration, saving time and resources. Effective ETL processes are essential for industries that handle large volumes of data, enabling faster processing and analytics. By unifying disparate data formats into a standard structure, ETL helps maintain data quality and supports informed decision-making.
Common Data Warehouse Models
The two primary types of schema structures used in data warehouses are the star schema and the snowflake schema. These schemas help organize data for efficient access and analysis.
A star schema is a multidimensional data model that organizes data for easy understanding and analysis, consisting of one fact table and multiple dimension tables. This model offers:
Efficient data storage
Maintenance of history
Reduction of duplication of business definitions
Facilitation of fast data aggregation and filtering.
On the other hand, a snowflake schema organizes data with a fact table linked to normalized dimension tables, enhancing data integrity. While snowflake schemas offer better data integrity, they complicate queries due to multiple joins, making star schemas preferable for analytical queries.
Benefits and Challenges of Data Warehousing
Using data warehouses in real-time brings both benefits and challenges, making it essential to understand their advantages and complexities.
Benefits
Enhanced Decision-Making: A data warehouse integrates data from various sources into one source, providing accurate insight and supporting data-centric decisions to facilitate strategic planning.
Faster Queries: Data warehouses provide optimized query engines and indexing to execute complex analytical queries quickly. This decreases data retrieval and reporting time.
Data Quality: Standardized data formats provide comprehensive coverage. This ensures minimum discrepancies and improves data accuracy for analytics.
Historical Analysis: Enables storage and analysis of historical data to identify changes over time, allowing for trend analysis and future performance tracking.
Challenges
Initial Costs: Implementing data warehouses requires significant upfront expenses for hardware and software platforms.
Complexity in ETL: Managing ETL processes becomes technically complex because organizations need to clean and transform data from multiple sources.
Maintenance Overhead: The system demands ongoing maintenance updates, performance optimization, and monitoring to preserve data precision and system performance while ensuring scalability.
Use-Cases
Here are some of the key use cases where a data warehouse can be used efficiently:
Retail & E-Commerce: Evaluate customer purchases to better target promotional offers, manage stock levels, and sharpen business sales predictions.
Health Care: Analyze patient records to improve healthcare services, enhance operational efficiency, and assist in medical research and diagnosis.
Banking & Finance: Minimizes fraudulent activities through pattern recognition and assists in risk management using modeling and monitoring processes.
Telecommunications: Improves the performance of a network using business intelligence, cuts down on idle time, and enhances customer segmentation for better prospects.
Manufacturing: Improves supply chain management's accuracy, enhances demand forecasting's precision, and assists with process improvements through real-time analytics.
Tools
Data warehouse tools offer multiple features, including flexible scaling options, integration functions, and sophisticated analytic capabilities. These tools fulfill various business requirements, ranging from real-time processing to extensive data analysis needs. Popular data warehouse platforms include:
Amazon Redshift: A cloud-native, petabyte-scalable, high-performance data warehousing service optimized for big-data analytic workloads
Google BigQuery: A serverless, cloud-native, and highly scalable real-time data warehouse with inbuilt AI capabilities
Snowflake: A cloud-based platform with a one-of-a-kind infrastructure offering simple data sharing and elasticity.
Azure Synapse: Analysis service that integrates big data and warehousing for complex query processing and analysis
IBM Db2 Warehouse: A cloud-native, high-performance data warehouse optimized for deep analytic and AI workloads
Modern Data Warehouse Trends
 A visual representation of modern data warehouse trends, including cloud data solutions.
A visual representation of modern data warehouse trends, including cloud data solutions.
Cloud technologies are significantly shifting the structure and management of data warehouses. Cloud data warehouses offer flexibility, scalability, and cost-effectiveness, making them an attractive option for many organizations. AI integration into data platforms automates complex tasks and enhances data interaction via advanced analytics capabilities and data virtualization.
Machine learning algorithms are increasingly utilized for advanced analytics within modern data warehouses. However, not all data warehouses are designed for AI, which can complicate data usage for AI workloads. Despite challenges, integrating AI and machine learning in data warehousing is growing, offering new data-driven insights.
Summary
In conclusion, data warehouses are essential tools for managing and analyzing large volumes of data. They provide a centralized repository that enhances data quality, supports faster decision-making, and drives business intelligence. Understanding the architecture, types, evolution, and challenges of data warehouses is crucial for leveraging their full potential. As technology advances, the integration of AI and machine learning will continue to shape the future of data warehousing, offering even greater capabilities for data analysis and insight generation.
FAQs
1. What is the difference between a data warehouse and a data lake?
A data warehouse stores processed and organized data for efficient analytics and reporting, while a data lake holds raw, unorganized information. A data lake is flexible for big data processing and is often used in machine learning.
2. Can a data warehouse store unstructured data?
Conventional data warehouses are designed for structured information. However, modern solutions can function with a data lake, which supports storing and processing semi-structured and unstructured information in log files and files in JSON format.
3. How does a data warehouse improve business intelligence?
A data warehouse brings information from multiple sources into a centralized repository. This integration helps generate dashboards, reports, and predictive models, enhancing decision-making and rapid trend identification.
4. Is a cloud warehouse better than an on-premise warehouse?
Cloud warehouses offer better scalability, less initial cost, and ease of maintenance. However, more performance, compliance, and security requirements make on-premise ideal for businesses.
5. What is the role of ETL in a data warehouse?
ETL is the backbone of the data warehouse, enabling extraction, transformation, and loading. It stores information in a normalized state, making it ready for analysis and use in business intelligence.
Related Sources
- TL;DR
- Key Takeaways
- Understanding Data Warehouses
- Key Characteristics of a Data Warehouse
- Key Benefits of Data Warehousing
- How a Data Warehouse Works
- Types of Data Warehouses
- Evolution of Data Warehouses
- Comparison: Data Warehouse vs Other Storage Systems
- The Role of ETL in Data Warehousing
- Common Data Warehouse Models
- Benefits and Challenges of Data Warehousing
- Use-Cases
- Tools
- Modern Data Warehouse Trends
- Summary
- FAQs
- Related Sources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free