




Comprendre le Deep Reinforcement Learning (DRL) : un guide complet
Réponse courte : Le Deep Reinforcement Learning (DRL) est un domaine de l’IA dans lequel un agent apprend à prendre des décisions en interagissant avec un environnement et en s’améliorant au fil du temps grâce aux retours ou aux « récompenses ». Le DRL combine l’apprentissage par renforcement (RL), une méthode d’apprentissage par essais et erreurs, avec le deep learning, qui permet à l’agent de traiter des données complexes comme des images ou des relevés de capteurs. Le DRL peut utiliser des réseaux de neurones profonds pour apprendre aux agents à naviguer dans des tâches compliquées avec des entrées de grande dimension. Il est largement utilisé dans des applications comme la robotique et les jeux, où les méthodes d’apprentissage traditionnelles peinent en raison de la complexité et de la variabilité de l’environnement.
Comprendre le Deep Reinforcement Learning (DRL) : un guide complet
En 2016, lorsque AlphaGo a battu le champion du monde Lee Sedol au go — un jeu offrant plus de coups possibles qu’il n’y a d’atomes dans l’univers — cela a marqué un tournant majeur dans la technologie d’entreprise. Le secret derrière cette victoire ? Le Deep Reinforcement Learning — une méthode qui entraîne les ordinateurs à s’améliorer par la pratique, tout comme un joueur de tennis qui perfectionne son service après des années passées sur le court. Là où les programmes informatiques traditionnels peinent face aux changements inattendus, cette technologie excelle dans des situations qui évoluent constamment — qu’il s’agisse de diriger des robots dans des entrepôts très fréquentés ou de prendre des décisions rapides dans le trading boursier. Cette nouvelle approche de l’apprentissage automatique ouvre des perspectives aux entreprises, en s’attaquant à des problèmes autrefois trop complexes pour être résolus par des logiciels classiques.
Ce guide propose une exploration approfondie du deep reinforcement learning, en mettant en évidence ses concepts clés, ses diverses applications, ses avantages et les défis susceptibles d’apparaître lors de sa mise en œuvre.
Qu’est-ce que le Deep Reinforcement Learning ?
Le Deep Reinforcement Learning (DRL) combine deux techniques efficaces d’IA, l’apprentissage par renforcement (RL) et le Deep Learning, permettant aux agents d’IA d’apprendre des actions optimales par essais et erreurs dans des environnements complexes. Dans le RL, un agent interagit avec son environnement et ajuste son comportement en fonction des récompenses et des stratégies d’apprentissage afin de maximiser les récompenses à long terme. Le deep learning ajoute la capacité de gérer des représentations détaillées de l’état à l’aide de réseaux de neurones.
Par exemple, un robot qui navigue dans un labyrinthe se déplace d’abord au hasard, mais avec le temps, il apprend à atteindre efficacement l’objectif grâce aux retours reçus. Le DRL aide les agents à s’adapter à des environnements dynamiques et à résoudre des problèmes complexes sans instructions détaillées. Il est utile dans les jeux vidéo, les voitures autonomes et les recommandations personnalisées. En combinant l’apprentissage par renforcement et le Deep Learning, les agents DRL peuvent gérer efficacement des tâches complexes du monde réel.
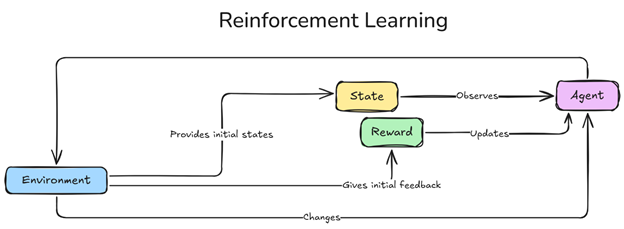 Figure 1 Cadre de l’apprentissage par renforcement.png
Figure 1 Cadre de l’apprentissage par renforcement.png
Comment fonctionne le Deep Reinforcement Learning
Pour comprendre le fonctionnement du DRL, il est important de connaître ses composants clés :
Agent
Environnement
État
Actions et récompenses
Politique
Agent
L’agent est le décideur chargé de naviguer dans l’environnement et de faire des choix afin de maximiser les récompenses cumulées au fil du temps. Grâce à des interactions répétées (épisodes d’apprentissage), l’agent affine sa stratégie en fonction des retours, ajustant son comportement pour atteindre le succès à long terme. Tout comme un joueur dans un jeu, les actions de l’agent sont guidées par une politique — un ensemble de règles apprises au fil du temps pour améliorer les performances et atteindre des résultats optimaux.
Environnement
L’environnement est l’espace structuré dans lequel l’agent opère, définissant les états, actions et récompenses possibles. Il réagit à chaque action de l’agent, fournissant des retours qui influencent les décisions futures de l’agent et façonnent son processus d’apprentissage.
État
L’état représente un instantané de l’environnement à un moment particulier, contenant des informations importantes pour la prise de décision de l’agent. Par exemple, un état peut inclure la position d’un agent et les obstacles dans un labyrinthe, ou la vitesse d’un véhicule et sa proximité avec d’autres voitures. Chaque état aide l’agent à évaluer sa situation et à sélectionner l’action la plus avantageuse.
Actions et récompenses
Les actions représentent les choix d’un agent dans chaque état, orientant son parcours dans l’environnement. Les actions peuvent être :
Actions discrètes : Des options limitées, comme se déplacer vers le haut, le bas, la gauche ou la droite, dans des environnements en grille, facilitent l’exploration et l’élaboration de politiques par les agents.
Actions continues : Celles-ci incluent une plage de valeurs, comme l’ajustement de la vitesse ou de l’angle, qui nécessitent des modèles avancés pour gérer la complexité accrue.
L’agent vise à effectuer des actions optimales au fil du temps et à maximiser les récompenses.
Les récompenses fournissent un retour d’information pour guider l’apprentissage de l’agent. Les récompenses positives signalent des actions réussies, tandis que les récompenses négatives pénalisent les erreurs. Les récompenses peuvent inclure :
Récompenses immédiates : Elles sont accordées directement après une action, comme marquer des points en capturant la pièce d’un adversaire aux échecs.
Récompenses différées : Obtenues après avoir terminé une séquence d’actions, comme parcourir un labyrinthe.
Il est important de concevoir la structure des récompenses, appelée façonnage des récompenses. Par exemple, des récompenses intermédiaires le long d’un chemin complexe peuvent accélérer l’apprentissage, motivant l’agent à prendre des mesures spécifiques vers l’objectif final.
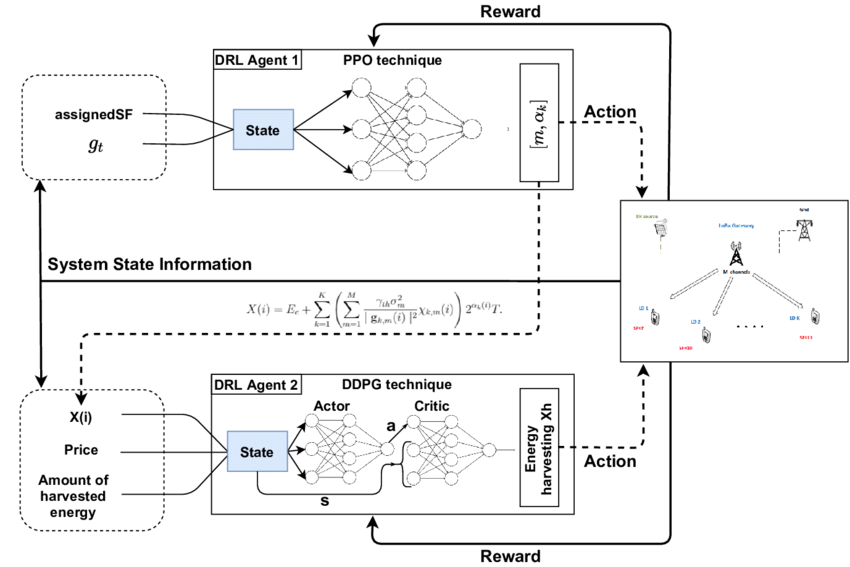 Figure- Reinforcement Learning architecture.png
Figure- Reinforcement Learning architecture.png
Figure : Architecture de l’apprentissage par renforcement
Le processus d’apprentissage
Le processus d’apprentissage ou d’entraînement de l’apprentissage profond par renforcement est un cycle itératif d’interaction, de retour d’information et d’amélioration qui implique :
Exploration
Exploitation
Réseaux neuronaux profonds
Rétropropagation
Exploration
Au départ, l’agent ne connaît pas l’environnement. Il commence par explorer aléatoirement, en essayant différentes actions et en observant les conséquences. Cette phase d’exploration est importante pour recueillir des informations sur l’environnement et découvrir des actions gratifiantes.
Exploitation
À mesure que l’agent explore et accumule de l’expérience, il commence à identifier les actions qui conduisent à des récompenses positives. Il exploite ensuite ces connaissances, en choisissant ces actions plus fréquemment afin de maximiser ses récompenses.
Réseaux neuronaux profonds
L’agent utilise des réseaux neuronaux profonds pour approximer la politique et la fonction de valeur de l’agent.
Réseau de politique : Ce réseau prend l’état actuel en entrée et produit la probabilité d’effectuer différentes actions.
Réseau de valeur : Ce réseau estime la valeur à long terme du fait de se trouver dans un état particulier, aidant l’agent à prendre des décisions qui conduisent à des récompenses cumulées plus élevées. Ces réseaux neuronaux permettent à l’agent d’apprendre des schémas et des relations environnementaux complexes, contribuant à prendre des décisions plus intelligentes.
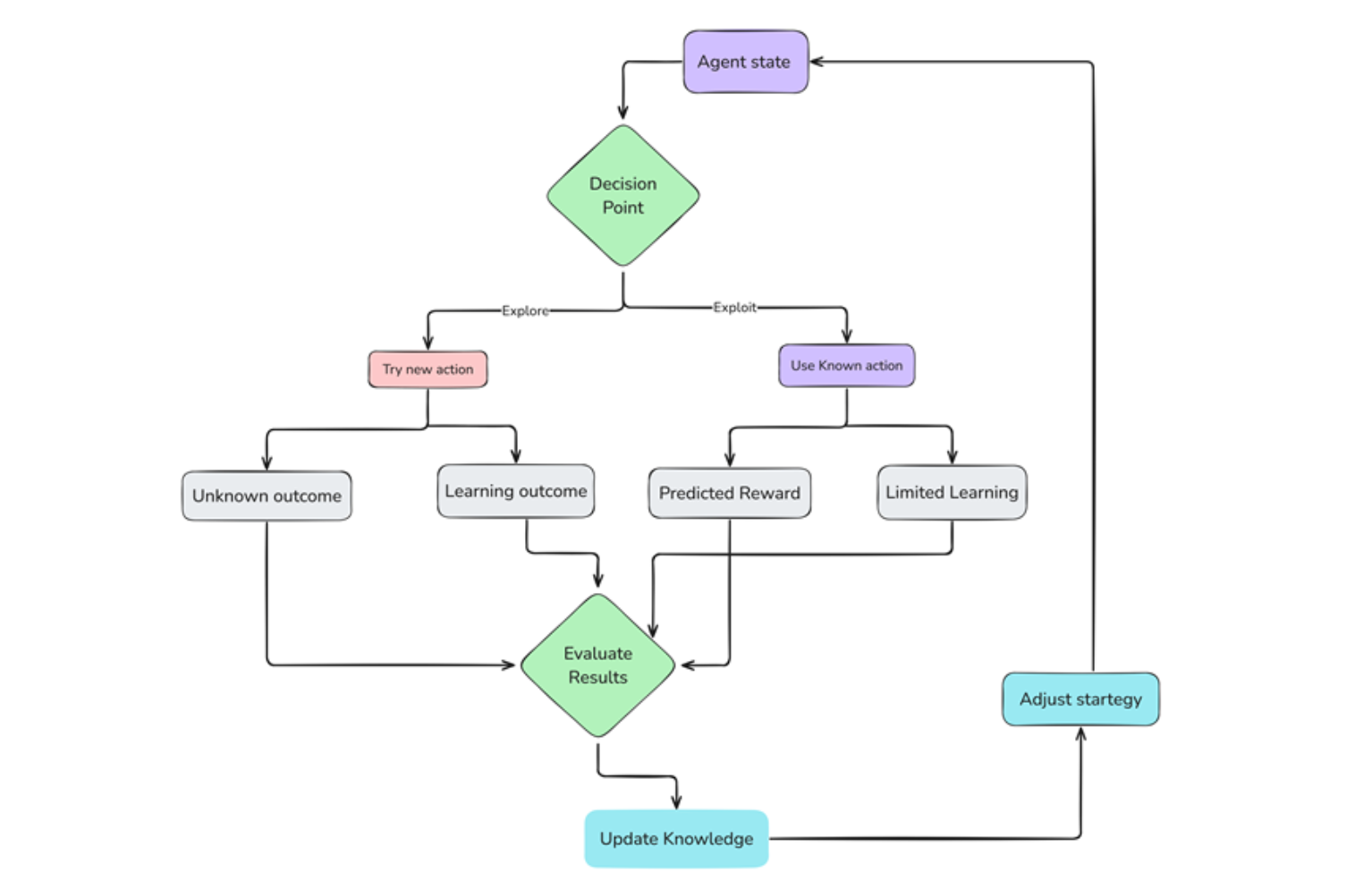 Exploration vs Exploitation Process .png
Exploration vs Exploitation Process .png
Figure 3 Processus d’exploration vs exploitation
Rétropropagation
La rétropropagation, abréviation de « propagation arrière des erreurs », est un algorithme clé dans l’entraînement des réseaux neuronaux. Elle ajuste les poids dans un réseau neuronal afin de minimiser l’erreur dans les prédictions.
La rétropropagation aide les agents à améliorer leurs modèles de prise de décision en apprenant à partir des retours. Lorsqu’un agent effectue une action, il reçoit un retour indiquant à quel point cette action était bonne ou mauvaise (sous forme de récompense). La rétropropagation ajuste ensuite les poids du réseau neuronal, réduisant l’erreur entre les résultats prédits et les récompenses réelles. En appliquant la rétropropagation de manière répétée, le réseau neuronal apprend à mieux approximer les fonctions de valeur ou de politique, ce qui conduit à des décisions plus précises. Ce processus permet à l’agent d’améliorer progressivement sa compréhension de l’environnement et de prendre, au fil du temps, des décisions de plus en plus optimales, ce qui est essentiel pour maîtriser des tâches complexes dans des environnements dynamiques et à haute dimension.
Algorithmes populaires en apprentissage par renforcement profond
Le DRL utilise une variété d’algorithmes, chacun conçu pour relever différents défis dans le processus d’apprentissage. Voici quelques-unes des méthodes les plus largement utilisées :
Q-Learning : Le Q-Learning est l’un des algorithmes fondamentaux de l’apprentissage par renforcement. Il estime la valeur des paires état-action, appelées valeurs Q, aidant l’agent à déterminer quelles actions sont préférables dans des états particuliers. L’algorithme met à jour ces valeurs Q en fonction des récompenses immédiates et des récompenses futures anticipées, affinant progressivement les choix de l’agent afin de privilégier les actions ayant une valeur à long terme plus élevée.
Deep Q-Networks (DQN) : DQN améliore le Q-learning en utilisant des réseaux neuronaux pour approximer les valeurs Q. Cette approche rend les DQN efficaces dans des environnements complexes tels que l’IA de jeu, la navigation robotique et la conduite autonome.
Policy Gradients : Contrairement aux méthodes fondées sur la valeur, les algorithmes de gradient de politique optimisent directement la politique d’un agent en ajustant les poids d’un réseau neuronal en fonction des récompenses reçues. Cette approche permet à l’agent d’améliorer ses performances en augmentant la probabilité d’actions réussies, ce qui est particulièrement important dans les tâches de contrôle nécessitant des ajustements précis, comme la manipulation d’un bras robotique.
Actor-Critic Methods : Les approches hybrides combinent les forces des méthodes fondées sur la politique, qui visent à estimer la valeur de chaque action dans un état donné, et des méthodes fondées sur la valeur, qui se concentrent sur l’apprentissage direct de la politique optimale. Dans ce cadre, l’acteur est responsable de la sélection des actions, tandis que le critique évalue ces actions et fournit un retour. Ce retour permet d’améliorer continuellement la politique.
Comparaison de l’apprentissage par renforcement profond avec d’autres concepts
L’apprentissage par renforcement profond (DRL) est souvent comparé à d’autres approches de l’IA. Pour clarifier les différences et les similitudes, examinons les aspects clés :
| ------------------------------------------------------------------------------------------------------------------------------------- | |||||
|---|---|---|---|---|---|
| Aspect | Apprentissage par renforcement profond (DRL) | Apprentissage par renforcement classique (RL) | Apprentissage supervisé | Apprentissage non supervisé | |
| Concept clé et gestion des données | Combine le RL avec des réseaux neuronaux profonds ; traite des données complexes à haute dimensionnalité | Se concentre sur le RL avec des modèles plus simples ; fonctionne bien dans des environnements à faible dimensionnalité | Apprend à partir de données étiquetées avec des sorties prédéfinies ; s’appuie sur des jeux de données étiquetés | Trouve des motifs dans des données non étiquetées ; fonctionne avec des jeux de données non étiquetés | |
| Processus d’apprentissage | Essais et erreurs via l’interaction avec l’environnement. | Essais et erreurs grâce au retour d’information de l’environnement. | Apprend des motifs à partir de paires entrée-sortie étiquetées. | Identifie des clusters ou des structures dans les données. | |
| Objectif | Maximiser les récompenses cumulées au fil du temps. | Maximiser les récompenses cumulées au fil du temps. | Prédire les sorties en fonction des données d’entrée. | Découvrir des motifs ou des regroupements cachés dans les données. | |
| Applications | Tâches complexes : IA de jeu, robotique, véhicules autonomes. | Systèmes de contrôle de base et tâches simples de prise de décision. | Classification, régression, modélisation prédictive. | Clustering, réduction de dimensionnalité, détection d’anomalies. |
Avantages et défis de l’apprentissage par renforcement profond
L’apprentissage par renforcement profond offre de nombreuses possibilités, mais il est important de savoir dans quels domaines il excelle et où il peut présenter des limites. Examinons certains des principaux avantages et défis du DRL.
Avantages :
Adaptabilité : L’un des principaux avantages du DRL est son adaptabilité. Les agents DRL peuvent gérer des situations nouvelles et inattendues sans nécessiter de programmation supplémentaire. Par exemple, un véhicule autonome alimenté par le DRL peut réagir à des changements soudains sur la route, tels que des obstacles ou des conditions météorologiques défavorables, en ajustant son comportement pour naviguer en toute sécurité.
Prise de décision optimale : Le DRL permet également une prise de décision plus intelligente, souvent plus efficace. Contrairement aux systèmes traditionnels fondés sur des règles, les modèles DRL peuvent découvrir des stratégies que même les concepteurs humains pourraient négliger. Dans la finance, par exemple, le DRL a été appliqué avec succès pour créer des robots de trading qui prennent fréquemment des décisions plus rentables que les systèmes conventionnels.
Potentiel d’automatisation : Le DRL permet l’automatisation de tâches dans des domaines comme le transport de marchandises, les soins médicaux et l’assistance aux clients. Dans ces domaines souvent complexes et en constante évolution, le DRL contribue à simplifier les choses en les automatisant.
Défis :
Efficacité des échantillons : L’un des plus grands défis du DRL est son besoin de vastes quantités de données d’entraînement. Les modèles DRL nécessitent généralement des données étendues pour bien fonctionner, ce qui peut être coûteux et long à collecter. Des techniques comme la relecture d’expériences aident en permettant aux modèles d’apprendre à partir de données passées, mais des améliorations de l’efficacité des données sont encore nécessaires pour rendre le DRL plus pratique.
Conception des récompenses : Un autre défi réside dans la conception de fonctions de récompense efficaces. Définir les bonnes récompenses est crucial, car des récompenses mal conçues peuvent entraîner des comportements d’agents involontaires et parfois problématiques. Par conséquent, la conception des récompenses en DRL nécessite une planification minutieuse afin de garantir que les agents agissent de manière alignée avec leurs objectifs prévus.
Stabilité et convergence : Enfin, l’entraînement du DRL peut être instable. Parfois, les modèles restent bloqués dans des stratégies moins qu’idéales ou ne parviennent pas à atteindre une solution stable. Améliorer la stabilité de l’entraînement est essentiel pour rendre les modèles DRL plus fiables, en particulier pour les applications à enjeux élevés où la cohérence est essentielle.
Applications concrètes de l’apprentissage par renforcement profond
Maintenant que nous avons exploré le fonctionnement de l’apprentissage par renforcement profond (DRL), concentrons-nous sur ses applications pratiques. Le DRL est utilisé pour résoudre des problèmes concrets dans divers domaines. Notamment :
Jeux : Le DRL a permis la création d’agents d’IA avancés qui excellent dans des jeux comme les échecs, le Go et Dota 2. Pour ceux qui souhaitent une exploration pratique, Unity ML-Agents fournit une boîte à outils accessible pour expérimenter l’apprentissage basé sur les jeux.
Robotique : En robotique, le DRL enseigne aux machines des compétences telles que la navigation et la manipulation d’objets. Le DRL s’avère très efficace dans les entrepôts, permettant aux robots de s’adapter à de nouvelles configurations et à des tâches changeantes, améliorant ainsi l’efficacité des opérations.
Véhicules autonomes : Dans les voitures autonomes, le DRL joue un rôle crucial dans la prise de décisions en une fraction de seconde pour changer de voie, éviter les obstacles ou ajuster la vitesse. Waymo, par exemple, utilise le DRL pour aider ses véhicules à faire des choix sûrs dans des situations de circulation complexes.
Trading financier : Le DRL est également largement utilisé dans la finance pour développer des robots de trading qui réagissent aux évolutions du marché. En utilisant des approches comme le Deep Q-Learning, les robots de trading alimentés par le DRL analysent les tendances historiques et les données en temps réel afin de prendre des décisions éclairées d’achat, de conservation ou de vente, obtenant souvent de meilleurs résultats que les stratégies de trading manuelles.
Recommandations personnalisées : Le DRL alimente des systèmes de recommandation de plus en plus avancés. Pour fournir des recommandations sur mesure, les algorithmes de DRL analysent le comportement et les préférences des utilisateurs sur les services de streaming, les boutiques en ligne et les plateformes de médias sociaux. En observant les actions des utilisateurs, le DRL peut recommander du contenu ou des produits qui correspondent plus étroitement aux préférences individuelles.
FAQ sur l’apprentissage par renforcement profond
- Comment un agent apprend-il dans l’apprentissage par renforcement profond ?
Dans le DRL, un agent apprend en effectuant des actions dans un environnement et en recevant des retours sous forme de récompenses. L’agent utilise l’exploration (essayer de nouvelles actions) pour découvrir des stratégies efficaces et l’exploitation (utiliser des actions connues) pour maximiser les récompenses. Les réseaux neuronaux profonds aident l’agent à généraliser à partir de ses expériences et à s’adapter à des scénarios complexes.
- Comment les modèles d’apprentissage par renforcement profond équilibrent-ils l’exploration et l’exploitation ?
Les modèles de DRL équilibrent l’exploration (essayer de nouvelles actions pour découvrir de meilleures stratégies) et l’exploitation (utiliser des actions connues pour maximiser les récompenses) grâce à des algorithmes comme epsilon-greedy ou Thompson Sampling. Ces techniques aident à maintenir un équilibre, garantissant que l’agent découvre de nouvelles stratégies tout en maximisant les récompenses connues.
- Comment fonctionnent les fonctions de valeur dans l’apprentissage par renforcement profond ?
Les fonctions de valeur estiment la récompense attendue du fait de se trouver dans un certain état (fonction de valeur d’état) ou d’effectuer une action spécifique dans un état donné (fonction de valeur d’action). Elles aident l’agent à prioriser les états et les actions qui mènent à des récompenses plus élevées, guidant ainsi la prise de décision.
- Comment le DRL peut-il être utilisé avec Milvus pour les applications d’IA ?
Milvus peut stocker et gérer les représentations d’état à haute dimension générées par les agents de DRL. Il peut servir de tampon de relecture pour les expériences passées ou aider au stockage des représentations d’état, améliorant l’efficacité de l’optimisation de politique et de l’estimation de valeur.
- Quelles sont les préoccupations éthiques liées à l’utilisation de l’apprentissage par renforcement profond ?
Les préoccupations éthiques comprennent les biais potentiels dans les données d’entraînement, les comportements involontaires découlant de fonctions de récompense mal conçues et les problèmes d’équité dans les applications sensibles. Pour atténuer ces risques, il est crucial de mettre en œuvre des tests robustes, la transparence et une IA explicable.
Ressources connexes
Pour approfondir le sujet, consultez ces ressources :
Article : [1811.12560] An Introduction to Deep Reinforcement Learning
Comprendre la régularisation des réseaux neuronaux et les principales techniques de régularisation
Que sont les bases de données vectorielles et comment fonctionnent-elles ?
Introduction à la recherche par similarité vectorielle - Zilliz blog
Modèles d’IA les plus performants pour vos applications GenAI | Zilliz
- Qu’est-ce que le Deep Reinforcement Learning ?
- Comment fonctionne le Deep Reinforcement Learning
- Algorithmes populaires en apprentissage par renforcement profond
- Comparaison de l’apprentissage par renforcement profond avec d’autres concepts
- Avantages et défis de l’apprentissage par renforcement profond
- Applications concrètes de l’apprentissage par renforcement profond
- FAQ sur l’apprentissage par renforcement profond
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement