




Funciones de activación en redes neuronales

Funciones de activación en redes neuronales
 Activation Functions.png
Activation Functions.png
Los avances recientes en inteligencia artificial (IA ) han sido increíbles, particularmente en el reconocimiento de imágenes, el procesamiento del lenguaje natural (NLP) y los coches autónomos. Un factor clave que contribuye a estos logros es la capacidad de las redes neuronales artificiales para estimar funciones complejas y no lineales que a menudo están presentes en los datos del mundo real. Esta capacidad se atribuye principalmente a las funciones de activación, que introducen no linealidad en las redes neuronales, permitiéndoles modelar relaciones y patrones complejos.
Entendamos en profundidad las funciones de activación, su propósito, cómo funcionan y por qué son importantes para las redes neuronales.
¿Qué son las funciones de activación?
Las funciones de activación son funciones matemáticas utilizadas en redes neuronales para determinar la salida de una neurona, introduciendo no linealidad en el modelo. Se aplican a las entradas de los nodos (neuronas), las unidades fundamentales de una red neuronal, para producir la salida del nodo. Una red neuronal calcula la suma ponderada de las entradas, añade un sesgo y luego pasa esta suma por la función de activación, que genera un valor modificado. Este valor se pasa a la siguiente capa de la red o se convierte en la salida final.
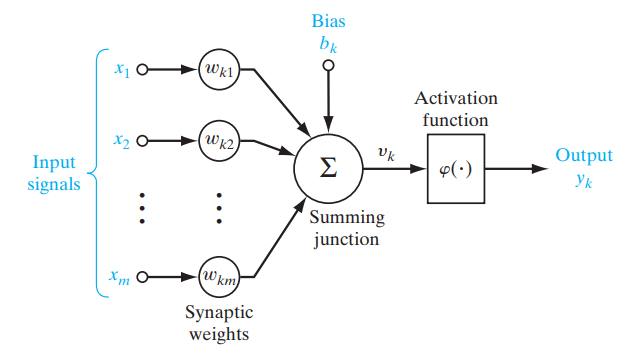 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
Figura: Papel de una función de activación en una red neuronal. | Fuente
¿Por qué importa la no linealidad?
Para entender por qué las funciones de activación son esenciales, es importante saber por qué los modelos lineales tienen limitaciones. Un modelo lineal representa una relación de línea recta entre entradas y salidas. Funciona bien en tareas simples, pero falla cuando los datos son más complejos y tienen patrones no lineales.
La no linealidad permite a las redes neuronales crear límites de decisión que no son líneas rectas. Por lo tanto, las redes neuronales pueden comprender patrones no lineales en los datos que no pueden ser representados por modelos lineales.
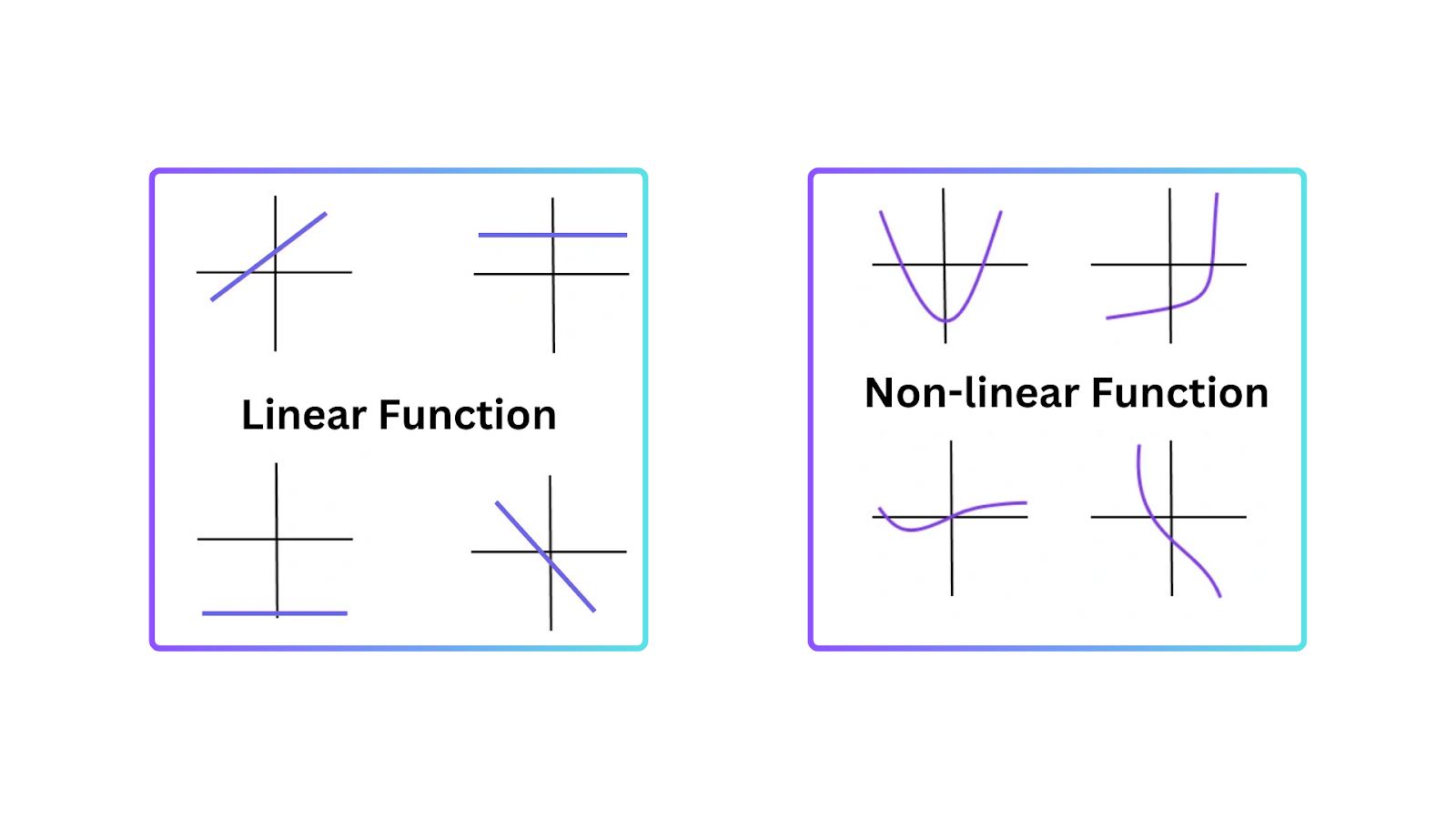 Figure- Types of Functions.png
Figure- Types of Functions.png
Figura: Tipos de funciones
Cómo funcionan las funciones de activación
Ahora que hemos introducido las funciones de activación, veamos cómo estas funciones funcionan matemáticamente para convertir la señal de entrada en una señal de salida, un rango a menudo entre 0 y 1 o -1 y 1. En cada neurona de una red neuronal, los datos fluyen a través de los siguientes pasos:
Entrada: Cada neurona de una red neuronal recibe una o más entradas. Estas entradas pueden provenir de los datos originales que alimentan la red (en el caso de la capa de entrada) o de las salidas de las neuronas de la capa anterior.
Cálculo de la suma ponderada: Las entradas se multiplican por los pesos correspondientes para determinar su importancia. Luego, las entradas ponderadas se suman y se devuelve un único valor, conocido como la suma ponderada.
Aplicación de la función de activación: Una vez calculada la suma ponderada, se pasa por una función de activación, y el resultado de la función de activación se convierte en la salida de la neurona.
Este proceso se repite en cada neurona a través de las capas de la red para transformar los datos de maneras más complejas.
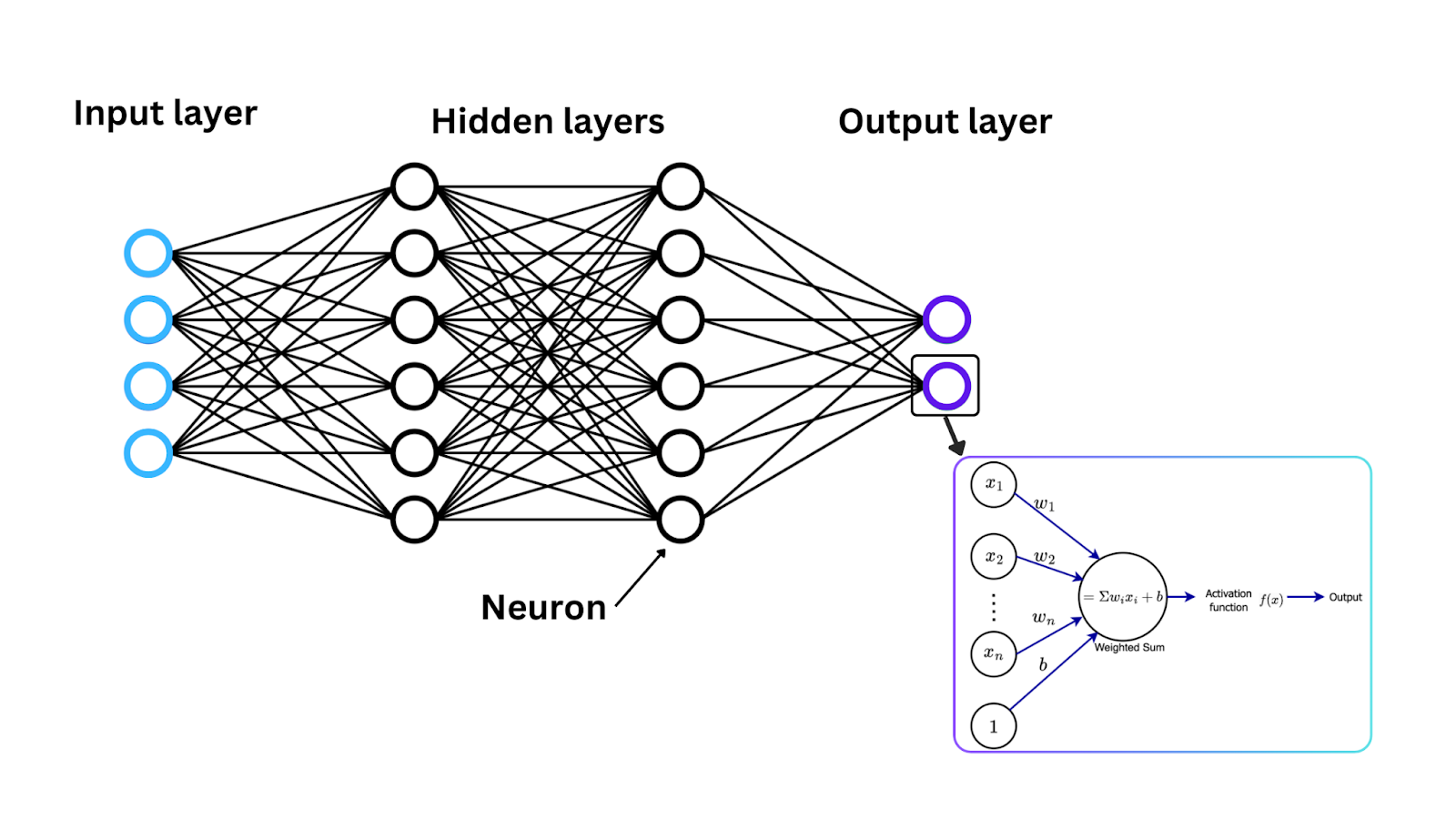 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figura: Arquitectura de red neuronal, función de activación y actualizaciones de pesos de neuronas.
Las redes neuronales utilizan diferentes tipos de funciones de activación. Cada función tiene sus propias fortalezas y es más adecuada para tareas específicas. Por ejemplo, la función sigmoide es óptima para problemas de clasificación binaria, softmax es útil para la predicción multiclase, y ReLU ayuda a superar el problema del gradiente que se desvanece.
Elegir la función de activación correcta acelera el entrenamiento y mejora el rendimiento. Ahora, veamos algunas de las funciones de activación comunes:
Activación sigmoide
Activación ReLU (Rectified Linear Unit)
Activación Tanh (tangente hiperbólica)
Activación Leaky ReLU
Activación sigmoide
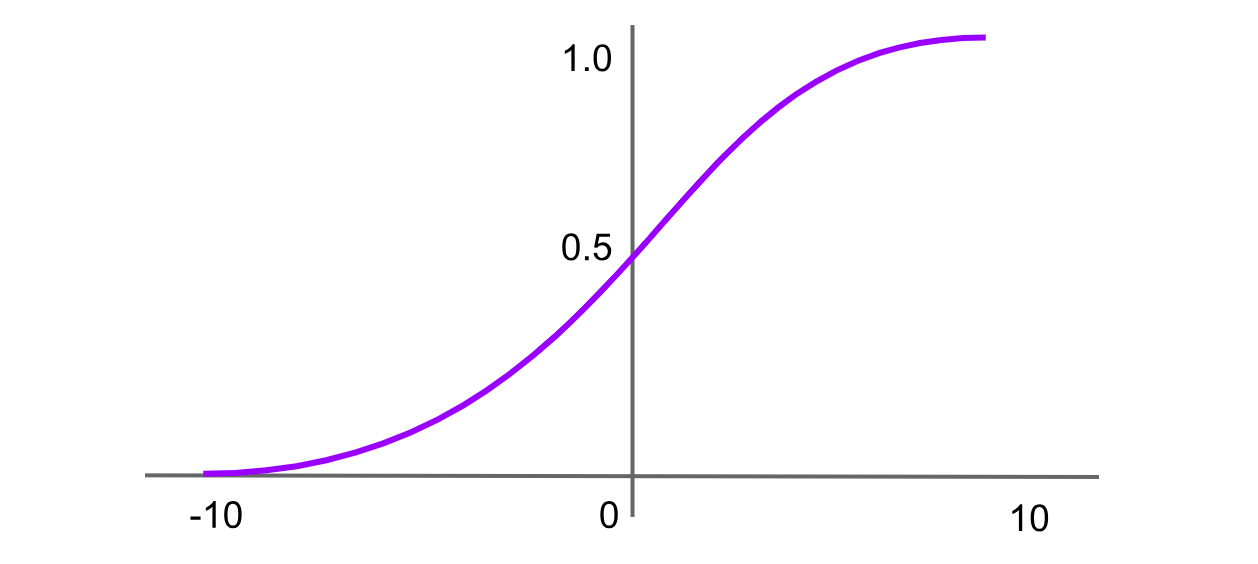 Figura- Función de activación sigmoide.png
Figura- Función de activación sigmoide.png
Figura: Función de activación sigmoide
La función sigmoide, también conocida como función logística, es una de las funciones de activación más antiguas y más conocidas. Asigna cualquier valor de entrada a un rango entre 0 y 1, produciendo una curva en forma de "S". La fórmula de la función sigmoide es:
Sigmoide = σ(x) = 1 / (1 + exp(-x))
Aquí está el código para definir la función sigmoide en Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Las funciones sigmoides son útiles para modelos en los que necesitamos predecir la probabilidad como salida. Por ejemplo, en problemas de clasificación binaria, queremos que la salida se interprete como una probabilidad entre 0 y 1.
Sin embargo, la sigmoide tiene un problema de gradiente que se desvanece. Durante la retropropagación (cuando la red aprende actualizando pesos), los gradientes sigmoides se vuelven muy pequeños, lo que provoca un aprendizaje lento en capas más profundas.
Activación softmax
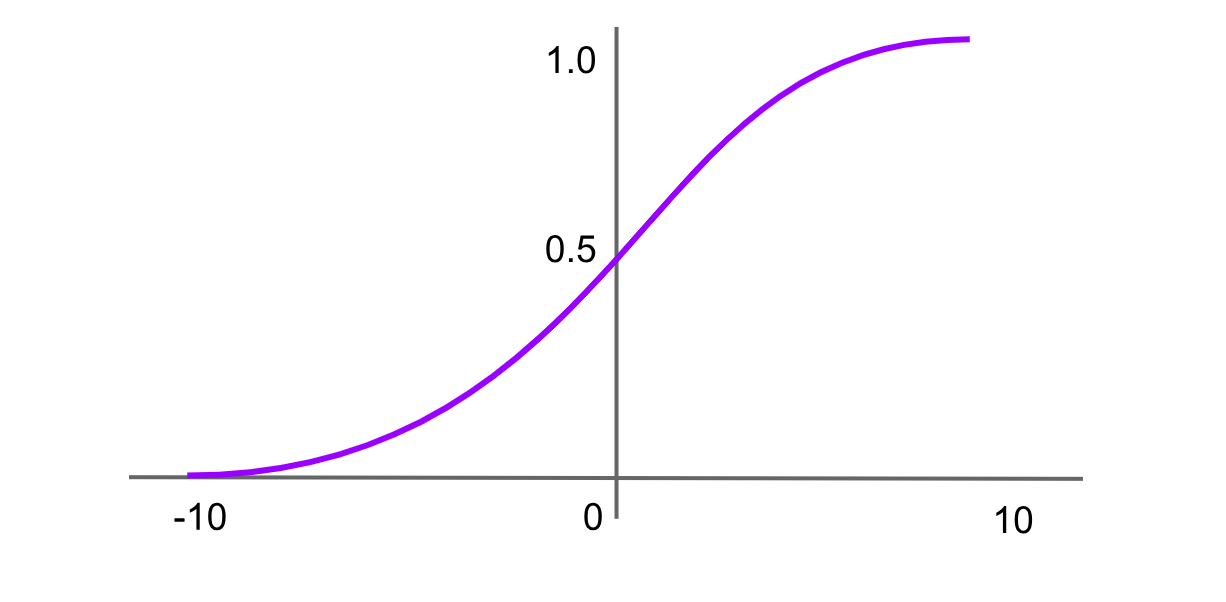 Figura- Función de activación softmax.png
Figura- Función de activación softmax.png
Figura: Función de activación softmax
La función softmax se utiliza comúnmente en la capa de salida de las redes neuronales para problemas de clasificación multiclase. Toma un vector de números reales como entrada y lo normaliza en una distribución de probabilidad sobre las clases. Cada salida está entre 0 y 1, y todas las salidas suman 1. La fórmula de la función softmax es:
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Programemos esto en Python.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
Sin embargo, Softmax puede ser computacionalmente costosa, especialmente en redes grandes, ya que requiere calcular exponenciales y normalizarlas a través de todas las salidas.
Activación ReLU (Rectified Linear Unit)
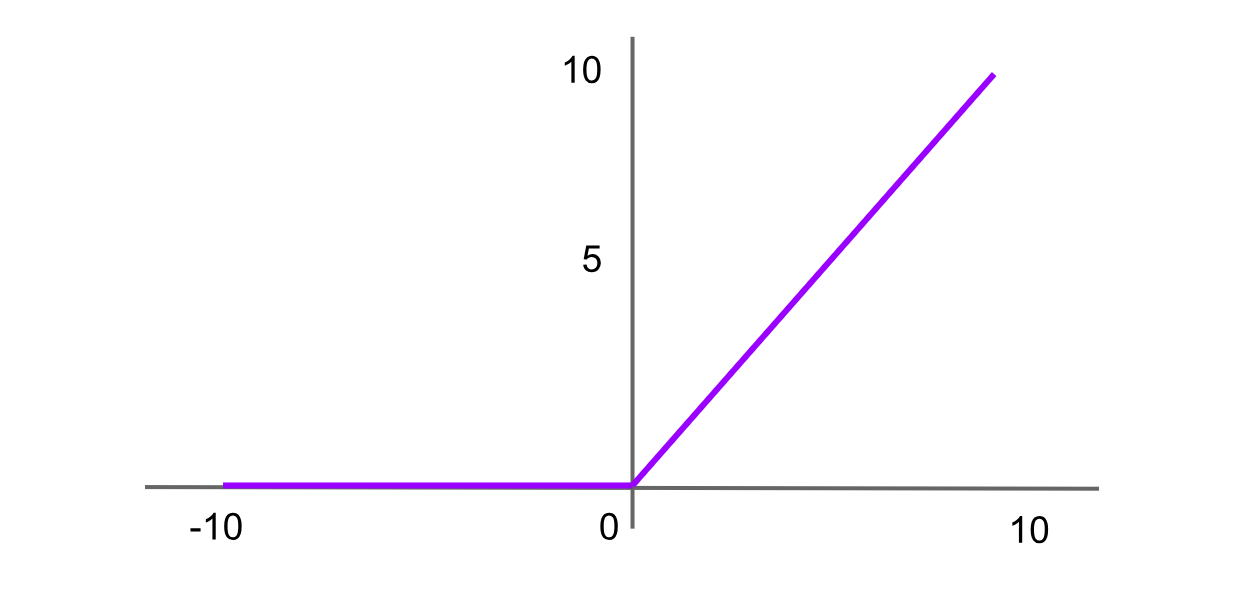 Figura- Función de activación ReLU.png
Figura- Función de activación ReLU.png
Figura: Función de activación ReLU
ReLU es una de las funciones de activación más utilizadas en redes neuronales avanzadas. Devuelve 0 para cualquier entrada negativa, y para valores positivos, devuelve el valor en sí. La fórmula de la función ReLU es:
ReLU = f(x) = max(0,x)
Aquí está la función de Python para ReLU:
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU se utiliza en capas ocultas de redes neuronales, particularmente en tareas de visión por computadora. Es computacionalmente eficiente porque no tiene operaciones exponenciales ni de división. En comparación con la sigmoide, también se ve menos afectada por el problema del gradiente que se desvanece. Sin embargo, hay una desventaja de ReLU, que es el problema de “ReLU muerta”. Si una neurona produce constantemente cero para todas las entradas, se vuelve inactiva y ya no puede contribuir al aprendizaje.
Activación Tanh (tangente hiperbólica)
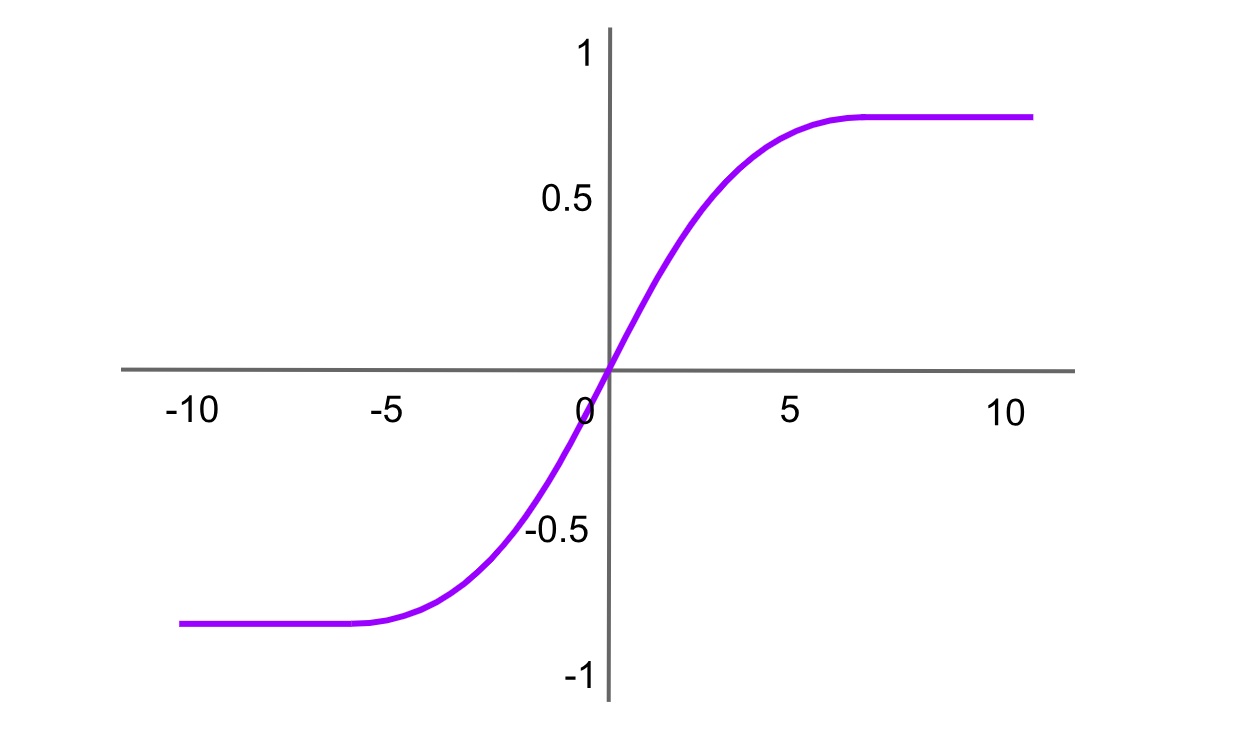 Figura- función de activación Tanh .png
Figura- función de activación Tanh .png
Figura: función de activación Tanh
La función tangente hiperbólica es similar a la función sigmoide, pero genera valores entre -1 y 1. La fórmula de la función Tanh es:
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
O
tanh(x)= f(x)=2sigmoid(2x)-1
Aquí está el código Python para la misma:
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
La tangente hiperbólica se utiliza en las capas ocultas de las redes neuronales, particularmente en tareas de procesamiento del lenguaje natural (NLP). Comparte algunas similitudes con la función sigmoide, pero tiene la ventaja de estar centrada en cero, lo que puede acelerar el aprendizaje en ciertas redes. Sin embargo, al igual que la función sigmoide, tanh también se ve afectada por el problema del gradiente desvaneciente.
Activación Leaky ReLU
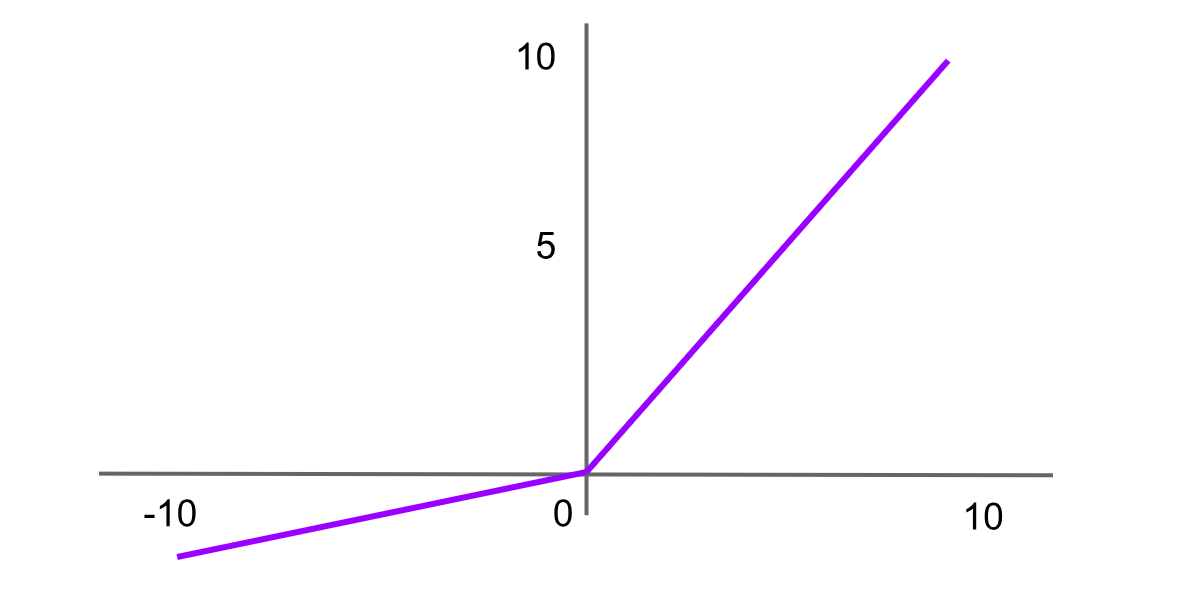 Figura- función de activación Leaky ReLU .png
Figura- función de activación Leaky ReLU .png
Figura: función de activación Leaky ReLU
Leaky Rectified Linear Unit, o Leaky ReLU, es una variante de ReLU diseñada para resolver el problema de “ReLU moribunda” introduciendo una pequeña pendiente para los valores negativos en lugar de una pendiente plana. Esto ayuda a que las neuronas sigan aprendiendo en lugar de quedar permanentemente inactivas. La fórmula de la función Leaky ReLU es:
Leaky ReLU = f(x)=max(αx,x)
Aquí, 𝛼 α es una pequeña constante positiva (por ejemplo, 0.01) para garantizar que la neurona genere un pequeño valor negativo en lugar de cero para entradas negativas. Dado que Leaky ReLU es una variante de ReLU, el código Python se puede implementar con una pequeña modificación.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Comparación
Para obtener una mejor comprensión de las funciones de activación, es útil compararlas con otros componentes clave de las redes neuronales:
Funciones de activación vs. funciones de pérdida
Las funciones de activación definen cómo responden las neuronas de una red a las señales entrantes. Se aplican a las salidas de las neuronas (o capas) para introducir no linealidad, lo que ayuda a la red a comprender patrones y relaciones en los datos.
Por otro lado, las funciones de pérdida se utilizan para determinar qué tan bien coinciden las predicciones de la red neuronal con los valores objetivo reales (la verdad fundamental). Calculan el error entre la salida predicha y los resultados reales. Además, los algoritmos de optimización ajustan los pesos de la red durante el entrenamiento para minimizar este error. Las funciones de pérdida incluyen:
Error cuadrático medio (MSE) se usa comúnmente para tareas de regresión.
Pérdida de entropía cruzada se utiliza para tareas de clasificación.
Funciones de activación vs. normalización
Las funciones de activación controlan cómo se mueven los datos de una capa a otra y cómo las neuronas "disparan" en función de las entradas.
Sin embargo, la normalización, como la normalización por lotes, ayuda a que el entrenamiento sea más efectivo. Funcionan modificando la distribución de las entradas a una capa para acelerar el aprendizaje de la red y evitar gradientes desvanecientes o explosivos. La normalización por lotes normaliza la entrada a cada capa para que tenga una media y una varianza consistentes y ayuda a que la convergencia de la red sea más fácil. Otras técnicas de normalización incluyen:
Normalización de capas: Normaliza a través de cada capa.
Normalización de instancias: Usualmente utilizada en el procesamiento de imágenes, normaliza cada instancia por separado.
Beneficios y desafíos de las funciones de activación
Las funciones de activación ofrecen varias ventajas a las redes neuronales, pero también presentan desafíos que deben abordarse. Primero, analicemos los beneficios de las funciones de activación.
No linealidad: El beneficio más importante de las funciones de activación es que introducen no linealidad en la red. Esto ayuda a las redes a capturar patrones no lineales en los datos y es ideal para tareas como el reconocimiento de imágenes y la comprensión del lenguaje natural.
Rango de salida: Las funciones de activación como sigmoid y softmax delimitan las salidas dentro de un rango específico (0-1 para sigmoid y entre -1 y 1 para tanh). Esto hace que sea mucho más sencillo comprender las salidas, especialmente en tareas de clasificación.
Cálculo eficiente: Algunas funciones, como ReLU, son computacionalmente eficientes, lo que permite que las redes escalen y se apliquen a grandes conjuntos de datos.
Ahora, analicemos los desafíos de las funciones de activación.
Problema del gradiente desvaneciente: es común en redes neuronales profundas, principalmente cuando se utilizan funciones de activación como sigmoid y tanh. Durante la retropropagación, los gradientes pueden volverse muy pequeños a medida que se propagan a través de múltiples capas de la red, lo que provoca la convergencia lenta de la red y dificulta el aprendizaje efectivo.
Gradientes explosivos: Los gradientes explosivos son un problema en el que se acumulan grandes gradientes de error, lo que da lugar a actualizaciones muy grandes de los pesos de los modelos de redes neuronales durante el proceso de entrenamiento. Esto hace que el modelo sea inestable e incapaz de aprender de los datos de entrenamiento.
Elección de la función: Elegir la función de activación óptima para una tarea o red neuronal puede ser desafiante y, por lo general, requiere algo de experimentación. Depende del tipo de problema que estamos tratando de resolver.
Casos de uso de las funciones de activación
Las funciones de activación son componentes importantes de varias arquitecturas de redes neuronales que realizan diferentes tareas. Estas son algunas aplicaciones clave:
Clasificación de imágenes: Las redes neuronales convolucionales (CNNs) utilizan la activación ReLU en sus capas ocultas para procesar datos de píxeles y softmax en la capa de salida para la clasificación multiclase.
Procesamiento del lenguaje natural (NLP): Las redes neuronales recurrentes (RNNs), Long Short-Term Memory (LSTM) y Transformers utilizan activaciones tanh o ReLU en sus capas ocultas para procesar datos secuenciales.
Modelos generativos: Las redes generativas antagónicas (GANs) suelen utilizar ReLU o LeakyReLU en la red generadora para introducir no linealidad y generar salidas realistas, y sigmoid en la red discriminadora.
Varios frameworks de aprendizaje profundo, incluidos TensorFlow y PyTorch, proporcionan una amplia gama de funciones de activación integradas e implementaciones para crear las tuyas personalizadas.
Preguntas frecuentes sobre las funciones de activación
- ¿Qué es la función de activación?
Las funciones de activación son bloques de construcción fundamentales de las redes neuronales que les permiten aprender patrones complejos en los datos de entrada. Convierten la señal de entrada de un nodo (neurona) en una señal de salida, que luego se pasa a la siguiente capa de la red neuronal.
- ¿Por qué se utiliza la función de activación ReLU?
La función de activación ReLU introduce no linealidad en una red neuronal, lo que ayuda a reducir el problema del gradiente desvaneciente durante el entrenamiento de modelos de machine learning.
- ¿Cuáles son las funciones de activación más utilizadas?
ReLU, Leaky ReLU, Softmax y Swish son funciones de activación populares.
- ¿Para qué se utiliza la función de activación?
El propósito principal de una función de activación es transformar la entrada ponderada sumada de un nodo en un valor de salida, que luego se pasa a la siguiente capa oculta o se utiliza como salida final.
- ¿Puedes tener múltiples funciones de activación?
Sí, es común tener diferentes funciones de activación en distintas capas de una red neuronal. Por ejemplo, una configuración estándar podría usar la activación ReLU en las capas ocultas y softmax en la capa de salida para un problema de clasificación multiclase.
Recursos adicionales
- ¿Qué son las funciones de activación?
- Cómo funcionan las funciones de activación
- Comparación
- Beneficios y desafíos de las funciones de activación
- Casos de uso de las funciones de activación
- Preguntas frecuentes sobre las funciones de activación
- Recursos adicionales
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis