




Multimodale künstliche Intelligenz verstehen

Multimodale künstliche Intelligenz verstehen
Die Einführung von ChatGPT und vielen anderen großen Sprachmodellen (LLMs) war ein entscheidender Meilenstein in der KI-Entwicklung. In dieser Zeit gelangten KI-Modelle von Nischenanwendungen zu alltäglichen Anwendungen wie Schreiben, Codieren, Kundendienst und Erstellung von Inhalten. Ein Großteil dieses Fortschritts war jedoch auf eine einzige Modalität beschränkt: Text.
Die Konzentration auf nur eine Modalität reicht nicht aus, um die Vision einer allgemeinen künstlichen Intelligenz (AGI) zu erreichen. AGI erfordert ihrer Definition nach die Fähigkeit, über mehrere Bereiche hinweg zu verstehen, zu denken und zu handeln, von der Sprache über das Sehen bis hin zu auditiven und sensorischen Eingaben. So wurde die Multimodalität geboren; dieser Artikel wird Sie durch diese Technik führen.
Was ist multimodale KI?
Systeme der künstlichen Intelligenz sind multimodal, wenn sie Informationen aus mehreren Modalitäten verarbeiten und analysieren, z. B. Text, Bilder, Audio und Videos. Andererseits ist KI, die nur eine Art von Modalität verarbeiten kann, unimodal.
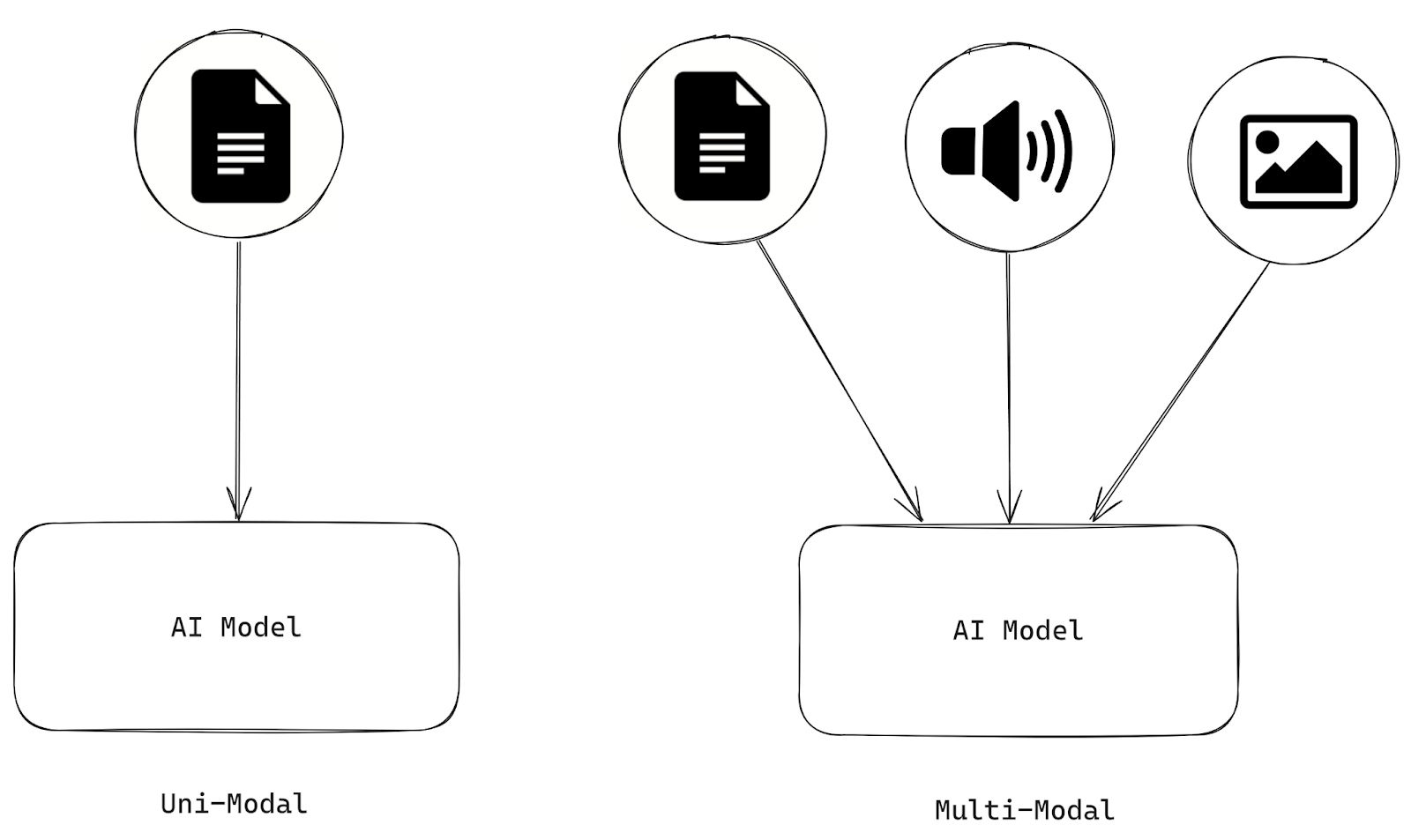 Abbildung 1- Unterschiede zwischen uni- und multimodaler KI.png
Abbildung 1- Unterschiede zwischen uni- und multimodaler KI.png
Abbildung 1: Unterschiede zwischen uni- und multimodaler KI
Es ist wichtig, den Unterschied zwischen zwei oft verwechselten Begriffen zu klären: multimodal und multi-modal. Multimodal bezieht sich auf Systeme, die Informationen aus mehreren Datentypen integrieren und verarbeiten. Im Gegensatz dazu beschreibt multimodal die Verwendung mehrerer unabhängiger Modelle, die parallel oder in Kombination arbeiten, um eine Aufgabe zu bewältigen. Diese Modelle können mit denselben oder unterschiedlichen Datentypen arbeiten, bleiben aber getrennt und nicht integriert.
Multimodale KI kann viele Anwendungen erheblich beeinflussen. So kann ein multimodales KI-Gesundheitssystem beispielsweise medizinische Bilder, Sprachaufzeichnungen von Patienten und klinische Notizen verwenden, um eine genauere Diagnose zu erstellen, als dies ein System könnte, das sich nur auf eine Datenquelle stützt. In dieser Hinsicht kommen multimodale KI-Systeme der menschlichen Kognition sehr viel näher und sind bei Aufgaben, bei denen es auf ein übergreifendes Verständnis ankommt, sehr effektiv.
Multimodal kann eine oder mehrere der folgenden Formen annehmen:
Eingabe und Ausgabe erfolgen in verschiedenen Modalitäten, z. B. Text zu Bild oder Bild zu Text.
Die Eingaben sind multimodal (z. B. Text und Bilder).
Die Ausgaben sind multimodal, z. B. ein System, das Text und Bilder ausgibt.
Im folgenden Abschnitt wird erörtert, wie multimodale Systeme funktionieren.
Wie funktioniert multimodale KI?
In einem multimodalen Modell arbeiten verschiedene Komponenten zusammen. Hier sind die wichtigsten Elemente und ihre Funktionsweise:
Datentypen: Multimodale KI integriert mehrere Datentypen, darunter Text, Bilder, Audio und Videos, und ermöglicht so ein umfassendes Verständnis und eine modalitätsübergreifende Erstellung von Inhalten.
Darstellung: Multimodale Repräsentationen beim maschinellen Lernen kombinieren Daten aus verschiedenen Modalitäten zu aussagekräftigeren Merkmalen, die Modelle nutzen können. Um dies zu erreichen, werden zwei verschiedene Ansätze verwendet.
Gemeinsame Repräsentationen: Daten aus verschiedenen Modalitäten werden in einen einheitlichen Repräsentationsraum umgewandelt, der geeignet ist, wenn multimodale Daten während des Trainings und der Inferenz verfügbar sind. Zu den Standardtechniken gehören [neuronale Netze] (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) und probabilistische grafische Modelle. Diese Methoden können zwar die Leistung verbessern, haben aber mit fehlenden Daten zu kämpfen.
Koordinierte Repräsentationen: Jede Modalität wird separat verarbeitet, wobei Beschränkungen erzwungen werden, um sie in einem gemeinsamen Raum auszurichten.
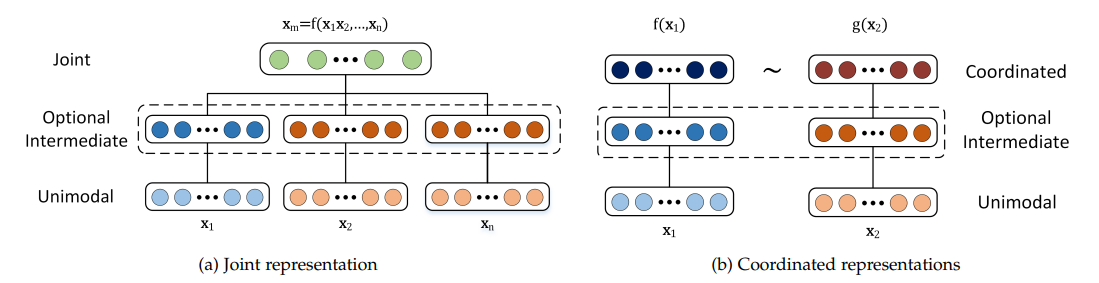 Abbildung 2- Struktur gemeinsamer und koordinierter Darstellungen.png
Abbildung 2- Struktur gemeinsamer und koordinierter Darstellungen.png
Abbildung 2: Struktur gemeinsamer und koordinierter Repräsentationen | Quelle
Merkmalsextraktion: Für die Extraktion von Merkmalen aus den einzelnen Datentypen werden spezialisierte Techniken eingesetzt, z. B. Natural Language Processing (NLP) für Text, Computer Vision für Bilder und Signalverarbeitung für Audio.
Datenfusion: Bei der Fusion werden Informationen aus zwei oder mehr Modalitäten für eine Vorhersageaufgabe kombiniert. Die Ansätze sind wie folgt:
Early Fusion: Die Daten werden vor der Analyse integriert, typischerweise in einem niedrigdimensionalen Unterraum unter Verwendung von Methoden wie PCA (Principal Component Analysis) oder ICA (Independent Component Analysis). Dieser Ansatz erfordert eine Synchronisierung der Modalitäten, was aufgrund unterschiedlicher Datenformate und Abtastraten eine Herausforderung darstellen kann. Er ist zwar effizient für die Merkmalsextraktion, kann aber zu Datenverlusten und Synchronisationsproblemen führen.
Spätfusion: Einzelne Modalitätsergebnisse werden auf der Entscheidungsebene mit Ensemble-Methoden wie Bagging, Boosting oder regelbasierten Ansätzen (z. B. Bayes-, Max- oder Durchschnittsfusion) kombiniert. Diese Methode eignet sich besonders gut für unkorrelierte Modalitäten und bietet eine Flexibilität, die der menschlichen Kognition ähnelt.
Modellierung: Neuronale Netze, die in der Lage sind, mehrere Modalitäten zu verarbeiten, wie z. B. Transformatoren oder neuronale Faltungsnetze (CNNs), werden verwendet, um aus verschiedenen Eingaben zu lernen. Es gibt anspruchsvollere Modelle, die bessere Ergebnisse liefern und oft als LMMs (Large Multimodal Models) bezeichnet werden.
Beliebte multimodale Modelle und ihre Architekturen
Auf dem Markt gibt es viele multimodale Modelle. Im Folgenden sind beliebte Modelle und Architekturen aufgeführt.
Video-Audio-Text-Transformator (VATT)
Der Video-Audio-Text-Transformer (VATT) ist eine faltungsfreie Architektur, die für die Verarbeitung mehrerer Modalitäten (Video, Audio und Text) unter Verwendung eines einheitlichen Transformer-basierten Rahmens entwickelt wurde. VATT beginnt mit der Einspeisung jeder Modalität in eine Tokenisierungsschicht, in der die Roheingabe in einen Einbettungsvektor projiziert wird, den ein Transformer anschließend verarbeitet.
Es gibt zwei Hauptkonfigurationen: eine, bei der für jede Modalität separate Transformatoren mit eigenen Gewichten verwendet werden, und eine andere, bei der ein einziger Transformer-Backbone mit gemeinsamen Gewichten für alle Modalitäten zuständig ist.
Unabhängig von der Konfiguration extrahiert der Transformer modalitätsspezifische Darstellungen und ordnet sie einem gemeinsamen Raum für weitere Aufgaben zu. Die Architektur folgt der Standard-Transformer-Pipeline, die häufig in [NLP] (https://zilliz.com/learn/nlp-technologies-in-deep-learning) und [Vision Transformers (ViT)] (https://zilliz.com/learn/understanding-vision-transformers-vit) verwendet wird, und verwendet Eingabe-Token.
Zusätzlich beinhaltet VATT einen lernbaren relativen Bias für Text, was es mit Modellen wie T5 kompatibel macht. Mit diesem Ansatz kann VATT multimodale Daten für Aufgaben wie Klassifizierung effektiv modellieren.
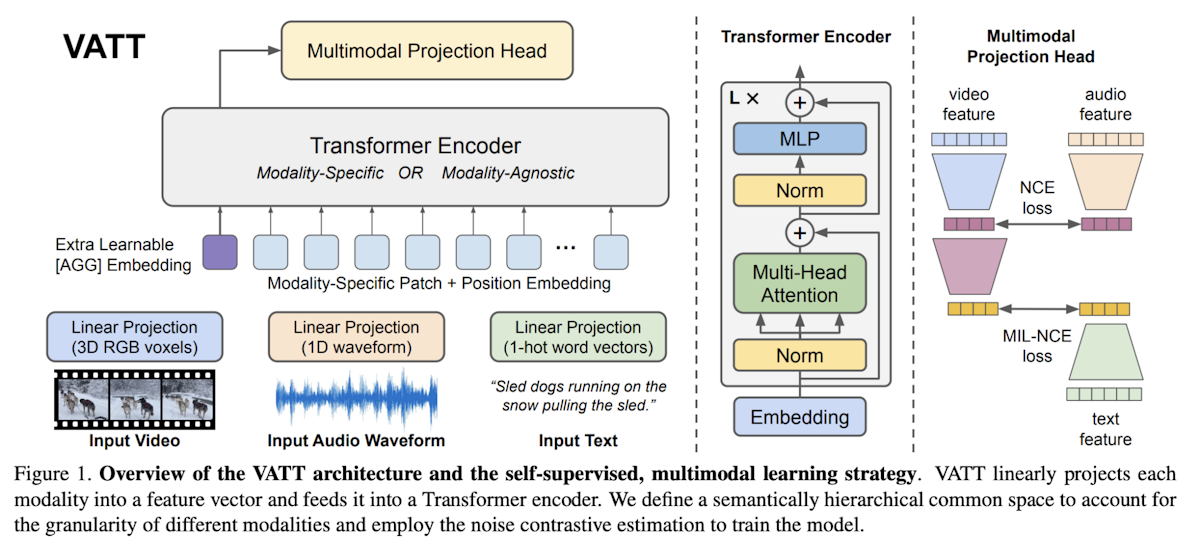 Abbildung 3- Vision Transformers for Multimodal Learning.png
Abbildung 3- Vision Transformers for Multimodal Learning.png
Abbildung 3: Bildverarbeitungstransformatoren für multimodales Lernen | Quelle
Multimodaler Variations-Autoencoder (MVAE)
Die Multimodal Variational Autoencoder (MVAE) Architektur wurde entwickelt, um eine einheitliche Darstellung von Text und Bildern zu lernen. Der MVAE besteht aus drei Hauptkomponenten: einem Encoder, einem Decoder und einem Anwendungsmodul (in diesem Fall ein Fake-News-Detektor).
 Abbildung 4- Multimodal Variational Autoencoder Architecture.png
Abbildung 4- Multimodal Variational Autoencoder Architecture.png
Abbildung 4: Multimodale Variations-Autoencoder-Architektur | Quelle
Encoder: Diese Komponente verarbeitet Text- und Bildeingaben, um eine gemeinsame latente Repräsentation zu erzeugen. Sie besteht aus zwei Unterkodierern:
Textueller Encoder: Konvertiert eine Folge von Wörtern aus einem Beitrag in Worteinbettungen unter Verwendung eines vorab trainierten tiefen Netzwerks.
Visueller Encoder: Dieser Prozess extrahiert visuelle Merkmale aus Bildern mithilfe von CNNs (wie VGG-19), um räumliche und objektbezogene Semantik zu erfassen.
Decoder: Der Decoder rekonstruiert den ursprünglichen Text und das Bild aus der gemeinsamen latenten Repräsentation. Er spiegelt die Struktur des Encoders wider und ist unterteilt in:
Textueller Decoder: Dieser Decoder rekonstruiert den Text, indem er die latente Repräsentation durch bidirektionale LSTM-Einheiten und eine voll verknüpfte Schicht leitet und die Wahrscheinlichkeit jedes Worts vorhersagt.
Visueller Decoder**: Kehrt die visuelle Kodierung um, indem er die VGG-19-Bildmerkmale durch vollständig verknüpfte Schichten rekonstruiert.
Fake News Detektor: Diese Komponente sagt anhand der gemeinsamen multimodalen latenten Repräsentation voraus, ob ein Nachrichtenbeitrag echt oder gefälscht ist.
CLIP (Contrastive Language-Image Pretraining)
Das CLIP (Contrastive Language-Image Pretraining)-Modell wurde entwickelt, um gemeinsame Repräsentationen von Bildern und Text zu lernen, indem es auf einem umfangreichen Datensatz von Bild-Text-Paaren trainiert wird. CLIP verwendet zwei separate neuronale Netze: eines für Bilder (oft ein Vision Transformer oder ein CNN) und eines für Text (typischerweise ein Transformer).
Diese Netze kodieren Bilder und Text in Vektoren fester Länge in einem gemeinsamen Einbettungsraum. Während des Trainings nutzt CLIP ein kontrastives Lernziel, das die Einbettungen von übereinstimmenden Bild-Text-Paaren zusammenführt und die von nicht übereinstimmenden Paaren auseinander treibt.
Durch diesen Prozess lernt CLIP, visuelle und textuelle Informationen zu korrelieren. Dieser Ansatz ermöglicht es dem Modell, eine Zero-Shot-Bildklassifizierung durchzuführen, so dass es Objekte in Bildern auf der Grundlage von Beschreibungen in natürlicher Sprache erkennen kann, ohne dass ein aufgabenspezifisches Training erforderlich ist. Diese leistungsstarke Architektur kann bei textbasierten Aufgaben eingesetzt werden, um die Generalisierungsfähigkeit zu verbessern.
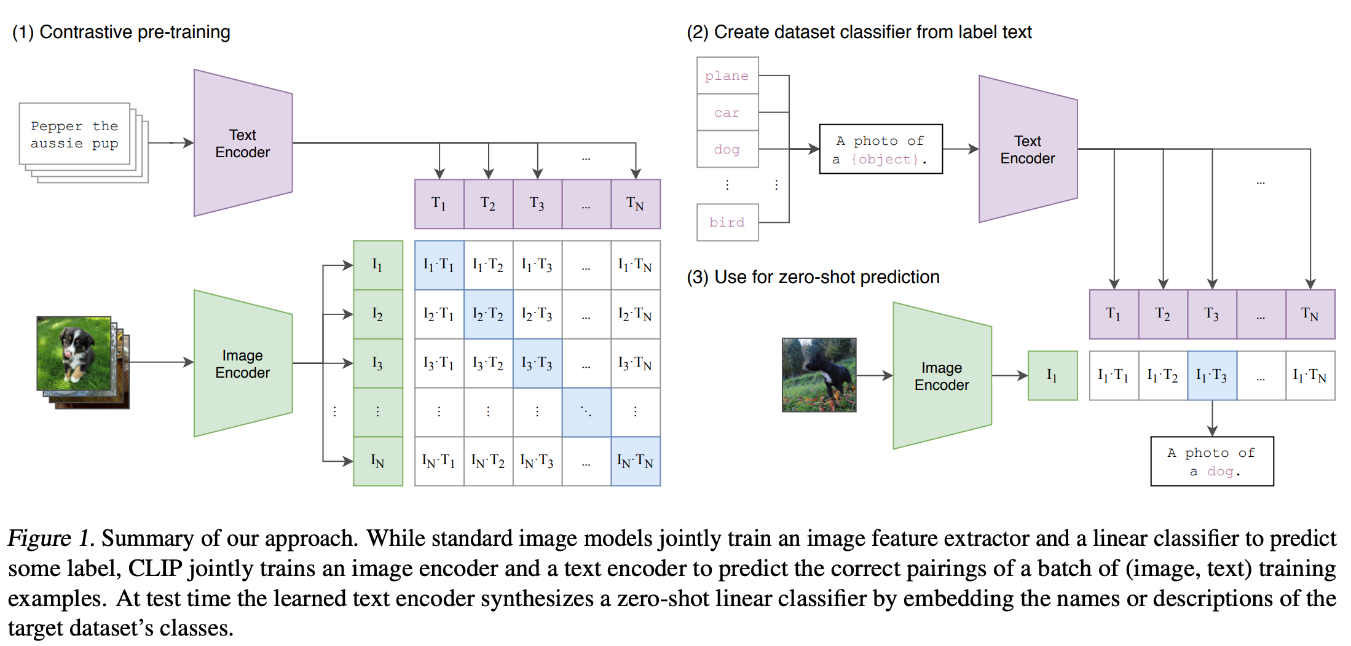 Abbildung 4- Architektur des CLIP-Modells.png
Abbildung 4- Architektur des CLIP-Modells.png
Abbildung 4: Architektur des CLIP Modells
Einige Closed-Source-Modelle dieser Architekturen umfassen:
Google Gemini: Ein multimodales LLM, das in den Bereichen Text, Bilder, Video und Audio hervorragende Leistungen erbringt und GPT-4 in mehreren Benchmarks übertrifft.
ChatGPT (GPT-4V): Unterstützt Text, Sprache und Bilder und ermöglicht es Nutzern, mit KI-generierten Stimmen zu interagieren und Bilder über DALL-E 3 zu erzeugen.
Inworld AI: Erstellt intelligente NPCs für digitale Welten und ermöglicht die Kommunikation durch natürliche Sprache, Stimme und Emotionen.
Meta ImageBind: Verarbeitet sechs Modalitäten und kombiniert Daten für Aufgaben wie die Erstellung von Bildern aus Audio und ermöglicht es Maschinen, ihre Umgebung wahrzunehmen.
Runway Gen-2: Erzeugt und bearbeitet Videos aus Text, Bildern oder vorhandenen Videos und bietet vielseitige Möglichkeiten zur Erstellung von Inhalten.
In diesem Beitrag finden Sie weitere [multimodale Modelle] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know).
Multimodale RAG: Mehr als nur Text
Retrieval Augmented Generation (RAG) ist eine Methode zum Abrufen von Kontextinformationen für große Sprachmodelle aus externen Quellen und zur Erzeugung genauerer Ergebnisse. Sie trägt auch dazu bei, KI-Halluzinationen zu mildern und einige Datensicherheitsprobleme zu lösen. Die traditionelle RAG hat sich bei der Verbesserung des LLM-Outputs als äußerst effektiv erwiesen, bleibt aber auf Textdaten beschränkt. In vielen realen Anwendungen geht das Wissen über Text hinaus und umfasst Bilder, Diagramme und andere Modalitäten, die einen wichtigen Kontext liefern.
Im Folgenden finden Sie einen Überblick über einen typischen textbasierten RAG-Workflow:
Der Benutzer sendet eine Textabfrage an das System.
Die Anfrage wird in eine Vektoreinbettung umgewandelt, die dann zum Durchsuchen einer Vektordatenbank , wie Milvus, verwendet wird, in der Textpassagen als Einbettungen gespeichert sind. Die Vektordatenbank sucht auf der Grundlage der Vektorähnlichkeit nach Passagen, die mit der Anfrage übereinstimmen.
Die relevanten Textpassagen werden dem LLM als zusätzlicher Kontext übergeben und bereichern dessen Verständnis der Anfrage.
Der LLM verarbeitet die Anfrage zusammen mit dem bereitgestellten Kontext und generiert eine fundiertere und genauere Antwort.
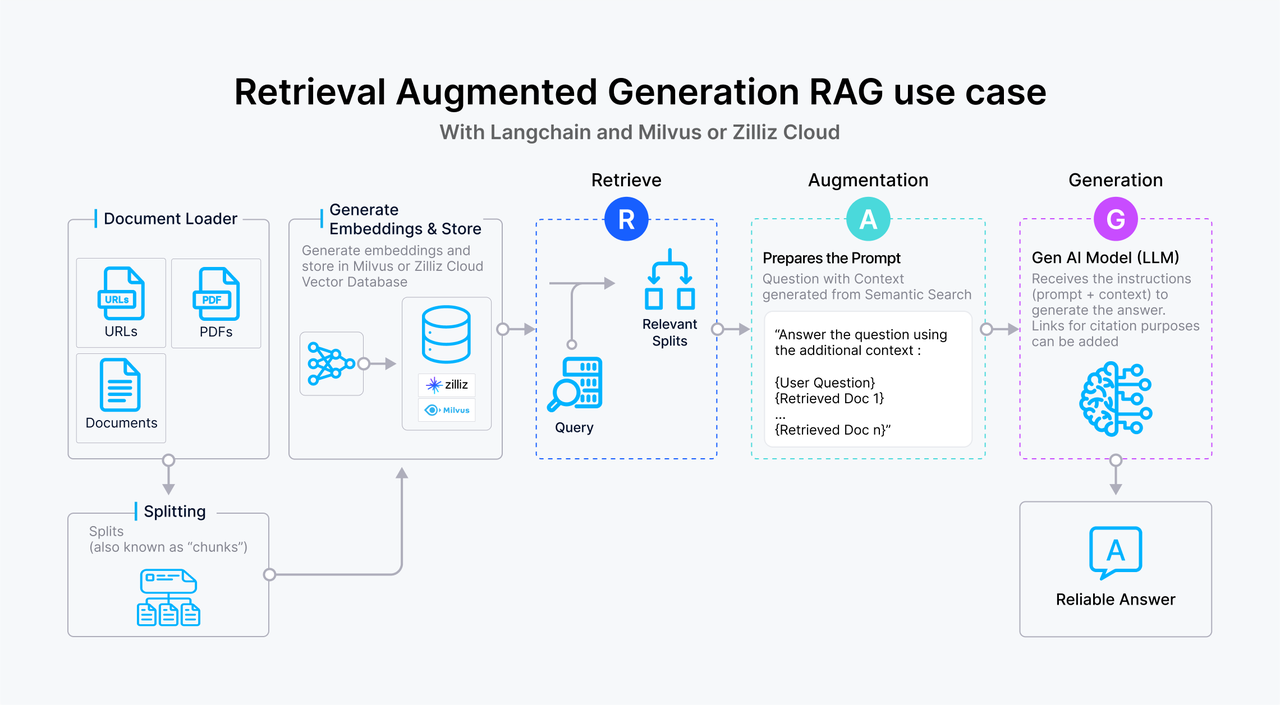 Abbildung 1- So funktioniert RAG.png
Abbildung 1- So funktioniert RAG.png
Abbildung: Funktionsweise der RAG
Multimodale RAG behebt die oben genannte Einschränkung, indem sie die Verwendung verschiedener Datentypen ermöglicht und den LLMs einen besseren Kontext bietet. Einfach ausgedrückt, in einem multimodalen RAG-System sucht die Retrieval-Komponente nach relevanten Informationen in verschiedenen Datenmodalitäten, und die Generierungskomponente generiert genauere Ergebnisse auf der Grundlage der abgerufenen Informationen.
Um ein solches System aufzubauen, müssen wir multimodale Modelle verwenden, um Einbettungen zu generieren, und LLMs mit multimodalen Fähigkeiten, wie z.B. LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, usw., um Antworten zu erzeugen.
Es gibt mehrere Möglichkeiten, wie wir multimodale RAG implementieren können:
Verwenden Sie ein multimodales Einbettungsmodell wie CLIP, um Texte und Bilder in Einbettungen umzuwandeln. Anschließend wird der relevante Kontext durch eine Ähnlichkeitssuche zwischen der Anfrage und den Text-/Bildeinbettungen ermittelt. Schließlich übergeben Sie den Rohtext und/oder das Bild des relevantesten Kontexts an unser multimodales LLM.
Verwenden Sie einen multimodalen LLM, um Textzusammenfassungen von Bildern oder Tabellen zu erstellen. Anschließend wandeln Sie diese Textzusammenfassungen mit einem textbasierten Einbettungsmodell in Einbettungen um. Dann führen Sie eine Textähnlichkeitssuche zwischen der Abfrage und den Zusammenfassungseinbettungen durch. Schließlich wird das Rohbild der relevantesten Zusammenfassung an unser LLM zur Generierung von Antworten weitergeleitet.
Wenn Sie mehr darüber erfahren möchten, wie Sie eine multimodale RAG-Anwendung erstellen, sehen Sie sich unsere Tutorien zu den verschiedenen unten aufgeführten Ansätzen an:
Erstellen eines multimodalen RAG mit Gemini, BGE-M3, Milvus und LangChain
Bessere multimodale RAG-Pipelines mit FiftyOne, LlamaIndex und Milvus erstellen
Multimodales RAG lokal mit CLIP und Llama3 ](https://zilliz.com/blog/multimodal-RAG-with-CLIP-Llama3-and-milvus)
Multimodale RAG: Ausweitung über Text hinaus für intelligentere KI ](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai)
Multimodales RAG mit Milvus | Milvus Dokumentation](https://milvus.io/docs/multimodal_rag_with_milvus.md)
Evaluieren Sie Ihre multimodale RAG mit Trulens ](https://zilliz.com/blog/evaluating-multimodal-rags-in-practice-trulens)
Vergleich zwischen unimodal und multimodal
Multimodale Systeme unterscheiden sich von traditionellen (unimodalen) Systemen durch die gleichzeitige Verarbeitung und Integration von Daten aus verschiedenen Eingabemodalitäten (z.B. Text, Bilder und Audio).
Multimodale Systeme haben einen Vorteil beim Verstehen von Kontexten, weil sie Informationen aus zwei Quellen extrahieren: aus dem Sehen und aus der Sprache. Traditionelle Ansätze sind einfacher und konzentrieren sich auf bestimmte Anwendungsbereiche. Die folgende Tabelle veranschaulicht einige entscheidende Unterschiede zwischen unimodalen und multimodalen Systemen.
| Aspekt | Traditionelle KI | Multimodale KI |
| Eingabeart | Verwendet eine einzige Eingabeart (z. B. nur Text, nur Bild) | Verarbeitet mehrere Eingabearten (z. B. Text, Bilder, Audio) |
| Verarbeitungsschwerpunkt | Konzentriert sich auf eine Sinnes- oder Datenmodalität | Integriert und verknüpft Informationen über mehrere Modalitäten hinweg |
| Komplexität | Einfacher und oft domänenspezifisch | Komplexer aufgrund der Notwendigkeit, verschiedene Datentypen zu integrieren |
| Kontextverständnis | Begrenzt auf Informationen, die in einer einzigen Modalität verfügbar sind | Kann den Kontext besser verstehen, wenn verschiedene Modalitäten verwendet werden |
| Anwendungen | Textklassifizierung, Objekterkennung, Spracherkennung, etc. | Mensch-Computer-Interaktion, Robotik, autonome Fahrzeuge, Augmented Reality etc. |
Vorteile und Herausforderungen der multimodalen KI
In diesem Abschnitt werden einige wichtige Vorteile und damit verbundene Herausforderungen bei der Entwicklung und Bewertung multimodaler Systeme aufgeführt.
Vorteile
Im Folgenden werden einige der Vorteile der multimodalen KI aufgeführt:
Erweiterter Kontext: Multimodale Systeme erfassen einen breiteren Kontext, indem sie ergänzende Informationen aus verschiedenen Quellen integrieren, z. B. durch die Kombination von visuellen Hinweisen mit Sprache zur besseren Interpretation.
Verbesserte Leistung: Durch die Einbeziehung von Daten aus verschiedenen Modalitäten kann die multimodale KI genauere Vorhersagen und Entscheidungen treffen. So könnte beispielsweise ein medizinisches Diagnosesystem unter Berücksichtigung von Patientenbildern und Krankenakten zuverlässiger sein.
Vielseitigkeit: Multimodale KI kann auf verschiedene komplexe Aufgaben angewandt werden, z. B. auf Bildunterschriften, die Beantwortung visueller Fragen, medizinische Diagnosen, autonomes Fahren usw., was sie sehr anpassungsfähig für verschiedene Bereiche macht.
Mehr menschenähnliches Verstehen: Multimodale KI kann die menschliche Kognition besser nachahmen und ermöglicht eine bessere Mensch-Computer-Interaktion in Echtzeitanwendungen durch die Verarbeitung von Daten aus verschiedenen Sinnesbereichen (Modalitäten).
Herausforderungen
Einige Herausforderungen im Zusammenhang mit dem Einsatz von multimodaler KI sind:
Darstellung: Die Methode oder das Format, in dem Modalitäten dargestellt werden, extrahiert die komplementären oder redundanten Informationen zwischen mehreren Modalitäten. Die Darstellung multimodaler Daten ist sehr wichtig, aber aufgrund ihrer heterogenen Natur auch eine Herausforderung. So ist beispielsweise der Ton ein Signal und das Bild eine 3D-Darstellung mit unterschiedlichen Maßstäben und Dimensionen, die es darzustellen gilt. Ein wesentlicher Punkt bei der Umsetzung ist die Frage, wie man sie in denselben gemeinsamen Darstellungsraum bringt.
Translation: Das Verfahren kann erklären, wie Daten von einer Modalität in eine andere umgewandelt oder transformiert werden können, sobald sie heterogen sind. Die Beziehung zwischen verschiedenen Modalitäten ist hauptsächlich subjektiv. Zum Beispiel die Übersetzung eines Videos in seine entsprechende Textbeschreibung.
Fusion: Bezieht sich auf die Kombination von Daten aus mehreren Modalitäten für verbesserte Vorhersagen. Bei der audiovisuellen Spracherkennung wird zum Beispiel die visuelle Beschreibung der Lippenbewegung mit dem Sprachsignal integriert, um gesprochene Wörter vorherzusagen. Die Informationen können aus verschiedenen Modalitäten stammen und haben verschiedene Stufen der Vorhersagestärke, Bedeutung, des Beitrags und der Rauschtopologie. In mindestens einer der Modalitäten fehlen Datenwerte.
Erklärbarkeit: Ein neuerer Begriff, Explainable AI (XAI), zielt darauf ab, sinnvolle Erklärungen und Überlegungen zu einem Modell zu erklären. Im Falle mehrerer Modalitäten ist es schwieriger zu verstehen, wie Modelle mit unterschiedlichen Datenquellen zu Schlussfolgerungen kommen.
FAQ zur multimodalen KI
- Was ist multimodale KI?
Multimodale KI ist eine Art von künstlichem Intelligenzsystem, das Informationen aus verschiedenen Modalitäten verarbeiten und analysieren kann, darunter Text, Bilder, Audio und Video.
- Welche Datentypen kann multimodale KI verwenden?
Multimodale KI nutzt verschiedene Datentypen, darunter Text-, Bild-, Audio-, Video-, Sensor- und Graphikdaten.
- Ersetzt multimodale KI die traditionelle KI?
Multimodale KI ersetzt nicht die herkömmliche KI, sondern erweitert ihre Möglichkeiten durch die Integration mehrerer Datenmodalitäten. Es ist eine Erweiterung. Herkömmliche Methoden bleiben unverzichtbar, während multimodale KI zusätzliche Möglichkeiten bietet.
- Was sind einige typische Anwendungen der multimodalen KI?
Typische Anwendungen der multimodalen KI sind Bildunterschriften, die Beantwortung visueller Fragen, die Erkennung von Emotionen und autonomes Fahren.
- Welche Vorteile bietet die multimodale KI?
Multimodale KI hat mehrere Vorteile, darunter Robustheit, Effizienz, Kontextbewusstsein, ein vielfältiger Anwendungsbereich und eine verbesserte Mensch-Maschine-Interaktion.
Verwandte Ressourcen
Was ist eine Vektordatenbank und wie funktioniert sie?](https://zilliz.com/learn/what-is-vector-database)
Erstellen von KI-Anwendungen mit Milvus: Tutorials & Notebooks](https://zilliz.com/learn/milvus-notebooks)
Leistungsstarke KI-Modelle für Ihre GenAI-Anwendungen | Zilliz
- Was ist multimodale KI?
- Wie funktioniert multimodale KI?
- Beliebte multimodale Modelle und ihre Architekturen
- Multimodale RAG: Mehr als nur Text
- Vergleich zwischen unimodal und multimodal
- Vorteile und Herausforderungen der multimodalen KI
- FAQ zur multimodalen KI
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren