




Was ist ein Kontextfenster in der KI?

Was ist ein Kontextfenster in der KI?
In der KI definiert ein Kontextfenster, wie viel Text das Modell auf einmal verarbeiten kann, gemessen in Tokens. Das Verständnis des Kontextfensters ist entscheidend, da es die Fähigkeit eines KI-Modells beeinflusst, genaue und kohärente Antworten zu generieren. Dieser Leitfaden untersucht, was ein Kontextfenster ist, seine Bedeutung in KI-Modellen und die Herausforderungen beim Verwalten größerer Kontextfenster.
Tokens verstehen
Bevor wir das Kontextfenster besprechen, lernen wir zunächst das Konzept der Tokens.
Tokens sind die kleinsten Dateneinheiten, die KI-Modelle verwenden, um Text zu verarbeiten und daraus zu lernen. Sie sind im Wesentlichen die Bestandteile eines Satzes – wie einzelne Wörter oder Satzzeichen –, die ein Computer verwendet, um Sprache zu verstehen und zu verarbeiten. Wenn ein Computer einen Satz liest, zerlegt er ihn in kleinere Teile (Tokens), um ihn zu verstehen. Im Satz "It's sunny!" wären die Tokens beispielsweise "It's", "sunny" und "!". Dieser Prozess, genannt Tokenisierung, hilft dem Computer, Text für Aufgaben wie das Übersetzen von Sprachen, das Erkennen von Spam oder das Beantworten von Fragen zu analysieren.
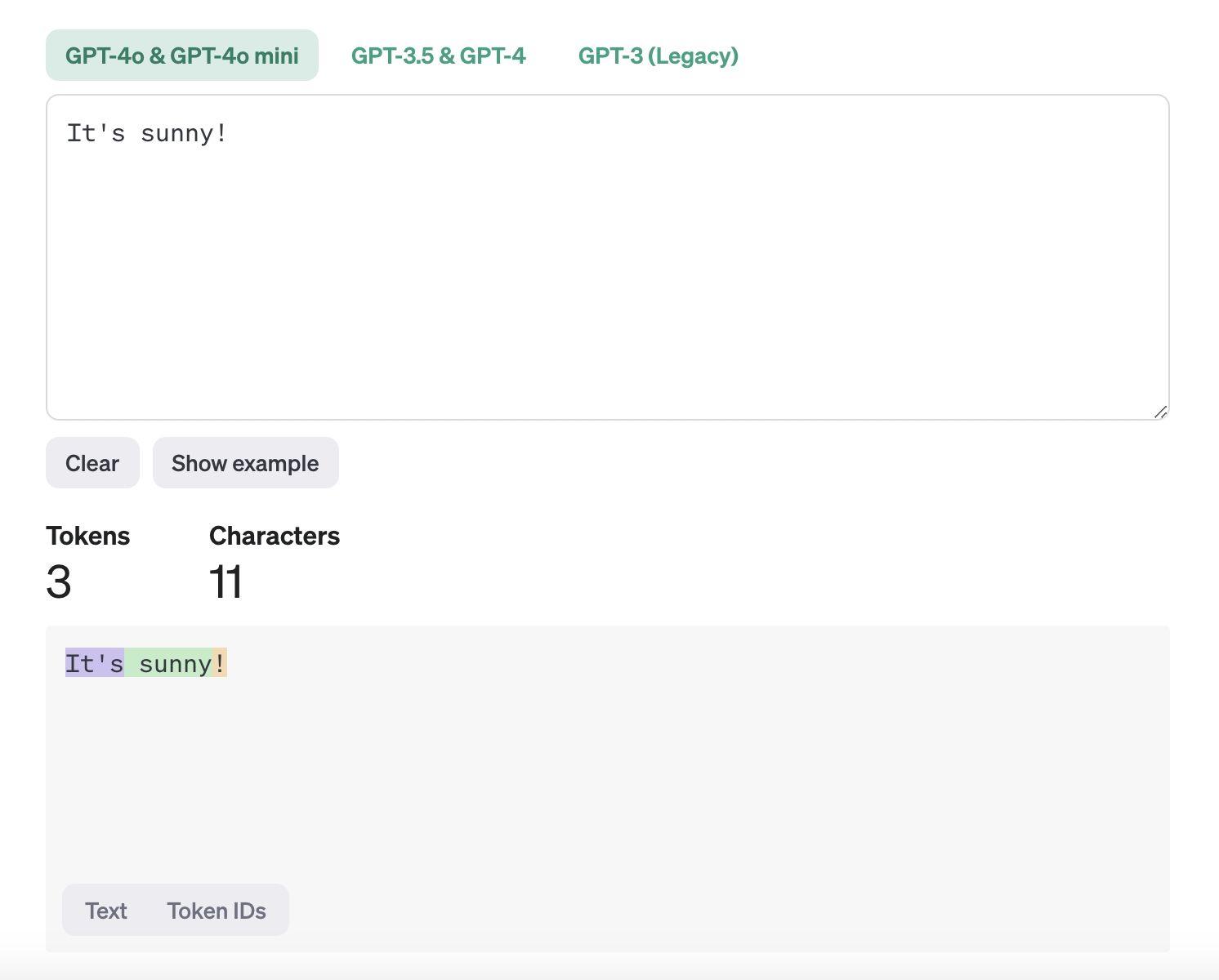 Was sind Tokens.jpeg
Was sind Tokens.jpeg
Was ist ein Kontextfenster in der KI?
Das Kontextfenster ist ein grundlegendes Konzept in der KI, insbesondere bei großen Sprachmodellen (LLMs). Es bezeichnet die maximale Textmenge, gemessen in Tokens, die ein KI-Modell während einer Konversation beim Generieren einer Antwort behalten und verwenden kann.
Stellen Sie sich ein Kontextfenster wie die Kurzzeitgedächtnisspanne des Modells vor. Wenn ein Modell wie ChatGPT beispielsweise ein Kontextfenster von 4.096 Tokens hat, kann es sich an die Informationen aus den letzten 4.096 Tokens (Wörter oder Satzzeichen) „erinnern“, die es verarbeitet hat. Das ähnelt der Art und Weise, wie eine Person beim Lesen oder Zuhören nur eine bestimmte Menge an Informationen im Blick behalten kann. Wenn dieses Token-Limit erreicht ist, beginnen die frühesten Informationen zu „verblassen“, während neue Informationen hinzukommen, was die Fähigkeit des Modells beeinträchtigt, sich auf frühere Teile der Konversation zu beziehen. Dieses Konzept ist entscheidend dafür, wie gut ein Modell den Kontext über lange Diskussionen oder Dokumente hinweg aufrechterhalten kann.
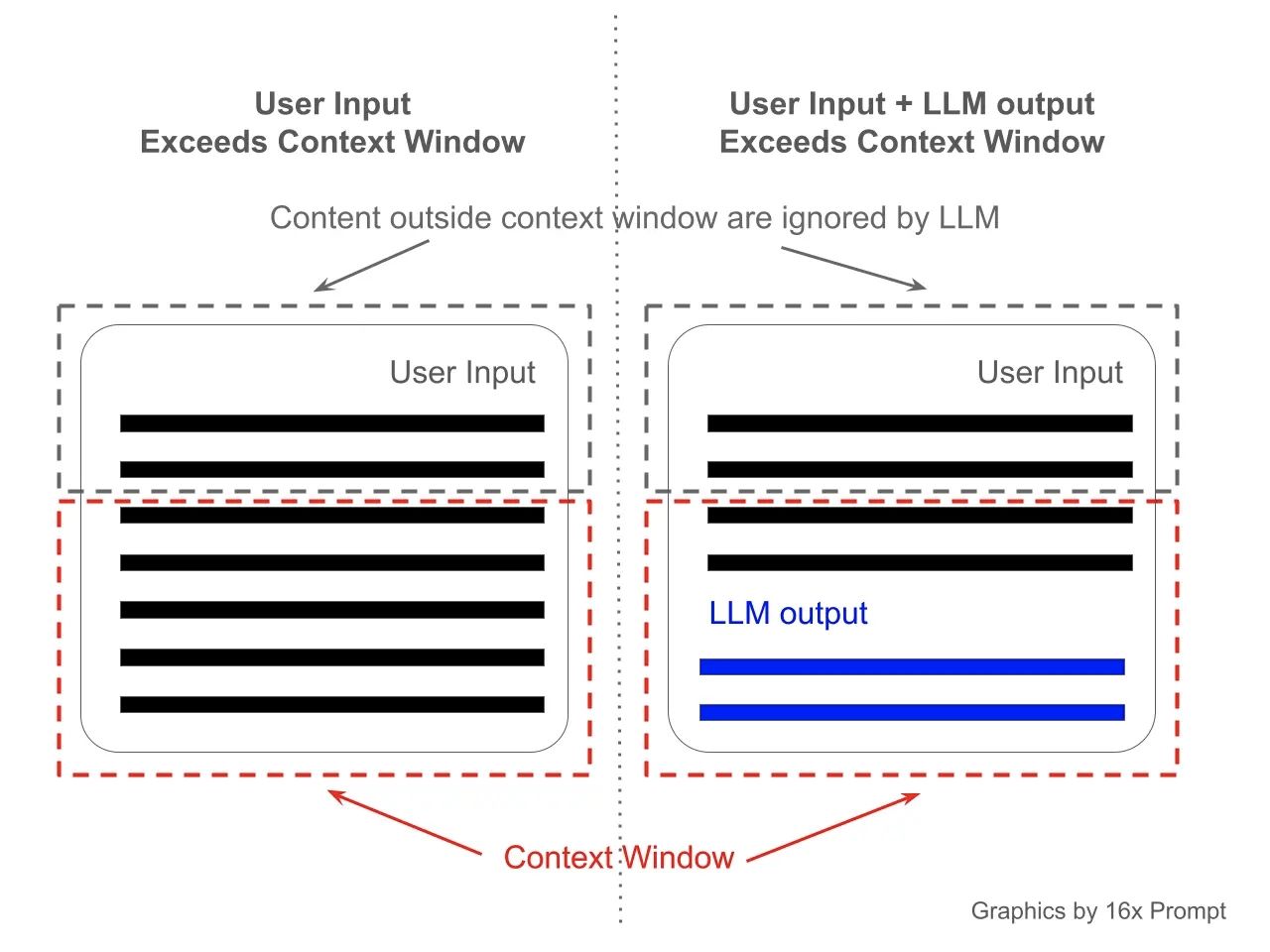 Kontextfenster visualisiert, Quelle 16x Prompt.jpeg
Kontextfenster visualisiert, Quelle 16x Prompt.jpeg
Das Kontextfenster gilt nicht nur für die Eingabe oder den laufenden Konversationsverlauf, sondern auch für die vom Modell generierten Antworten. Wenn eine Antwort selbst beispielsweise 500 Tokens enthält, wird diese Anzahl von den insgesamt für die Verarbeitung des Konversationsverlaufs verfügbaren Tokens abgezogen. Folglich werden, wenn man sich dem Token-Limit nähert, die frühesten 500 Tokens der Konversation möglicherweise bei der laufenden Verarbeitung nicht berücksichtigt.
Token-Limits innerhalb des Kontextfensters
Die Größe des Kontextfensters, oder das Token-Limit, ist die Gesamtzahl der Tokens, die das Modell auf einmal berücksichtigen kann. Wenn die Konversation dieses Limit überschreitet, bleiben nur die neuesten Tokens erhalten und ältere Tokens werden verworfen. Beispielsweise bietet das fortschrittliche Modell GPT-4o von OpenAI ein deutlich größeres Kontextfenster von bis zu 128.000 Tokens, was eine umfassendere und tiefere Auseinandersetzung mit dem Text ermöglicht.
 Kontextfenster und Ausgabe-Token-Limit von GPT-4o.jpeg
Kontextfenster und Ausgabe-Token-Limit von GPT-4o.jpeg
Ausgabe- und Eingabe-Token-Limits
Neben dem Kontextfenster haben KI-Modelle spezifische Token-Limits für Ausgaben und Eingaben:
- Ausgabe-Token-Limit: Dies ist die maximale Anzahl von Tokens, die das Modell in einer einzelnen Antwort generieren kann. Beispielsweise hat OpenAIs GPT-4o-mini ein Ausgabe-Token-Limit von 16.348 Tokens. Wenn die generierte Antwort dieses Limit erreicht, stoppt das Modell die Token-Generierung, wodurch die Antwort möglicherweise abgeschnitten wird.
 Ausgabe-Token-Limit von GPT-4o-mini .jpeg
Ausgabe-Token-Limit von GPT-4o-mini .jpeg
- Eingabe-Token-Limit: Dies bestimmt, wie viele Tokens aus der Eingabe auf einmal verarbeitet werden können. Das Überschreiten dieses Limits bedeutet, dass das Modell die Eingabe in kleinere Teile segmentieren muss, was die Kohärenz und Genauigkeit der Antwort beeinträchtigen kann.
Ausbalancieren von Token-Limits
Der Umfang des Token-Limits beeinflusst die Leistung eines Modells erheblich und bestimmt dessen Fähigkeit, komplexe Informationen effektiv zu parsen und zu interpretieren. Das Ausbalancieren der Anzahl der Tokens mit der Verarbeitungsleistung des Modells ist entscheidend, da umfassendere Verarbeitungskapazitäten es ermöglichen, komplexe Ideen effektiver zu handhaben, wenn auch mit notwendigen Kompromissen bei Tokenisierung und Verarbeitungsstrategien.
Bedeutung größerer Kontextfenster in KI-Modellen
 Eine visuelle Darstellung der Bedeutung größerer Kontextfenster in KI..jpeg
Eine visuelle Darstellung der Bedeutung größerer Kontextfenster in KI..jpeg
Größere Kontextfenster verbessern die Fähigkeit einer KI, umfangreiche Dokumente zu verstehen und zu analysieren, erheblich und machen sie in Bereichen wie der juristischen und medizinischen Forschung unverzichtbar. In der juristischen Forschung kann KI beispielsweise relevante Informationen effizient aus großen Datensätzen extrahieren und schnell wertvolle Erkenntnisse liefern. Ebenso erleichtern große Kontextfenster in der medizinischen Forschung die Zusammenfassung komplexer wissenschaftlicher Arbeiten und unterstützen Forscher dabei, zeitnah Erkenntnisse zu gewinnen.
Die erhöhte Kapazität, über eine Million Tokens zu verarbeiten, ermöglicht es KI-Modellen, vielfältige Aufgaben effektiv zu bewältigen, von der Datenverarbeitung bis zur Codegenerierung. Claude 3.5 Sonnet verfügt beispielsweise über eine Kontextfenstergröße von 200.000 Tokens, wodurch es komplexe Anweisungen und nuancierte Aufgaben mit bemerkenswerter Präzision bewältigen kann. Diese Fähigkeit unterstreicht die entscheidende Rolle größerer Kontextfenster bei der Verbesserung der KI-Leistung.
Größere Kontextfenster in KI-Modellen selbst gehen jedoch mit Kompromissen einher. Sie können zu höheren Betriebskosten führen und erfordern robuste Datenstrategien, um die effektive Nutzung relevanter Trainingsdaten sicherzustellen. Darüber hinaus kann die Verwaltung eines größeren Kontextfensters zu Informationsüberlastung führen, wodurch die Effektivität des Modells bei der Identifizierung zentraler Punkte abnimmt. Daher ist ein ausgewogener Ansatz unerlässlich, um das volle Potenzial größerer Kontextfenster auszuschöpfen und gleichzeitig die damit verbundenen Herausforderungen zu mindern.
Im folgenden Abschnitt werden wir die Herausforderungen bei der Erweiterung von Kontextfenstern untersuchen.
Herausforderungen bei der Erweiterung von Kontextfenstern in KI-Modellen
Die Erweiterung von Kontextfenstern in KI-Modellen bringt verschiedene Kompromisse mit sich, die sorgfältig berücksichtigt werden müssen. Die Ermöglichung längerer Eingaben und Ausgaben kann die Reichhaltigkeit der generierten Antworten erhöhen, steigert aber auch die Komplexität der Verarbeitung. Das Gleichgewicht zwischen längeren Kontextfenstern und effizienter Verarbeitung ist entscheidend, um potenzielle Nachteile für die KI-Leistung zu mindern.
Rechenressourcen
Mit zunehmender Größe der Kontextfenster steigt der Bedarf an Verarbeitungsleistung erheblich, was zu langsameren Inferenzzeiten führt. Die Komplexität der Skalierung bei der Vergrößerung von Kontextfenstern entsteht dadurch, dass Parameter quadratisch zunehmen, was erhebliche Herausforderungen mit sich bringt. Wenn sich die Länge von Textsequenzen verdoppelt, vervierfachen sich der Speicher- und Rechenbedarf, was die erhöhten Anforderungen größerer Kontextfenster verdeutlicht.
Um diese Herausforderungen zu bewältigen, wurden Techniken wie Ring Attention implementiert, um die Effizienz von Modellen zu verbessern, die mit erweiterten Kontextfenstern arbeiten. Die Theorie der „Zone of Proximal Development“ legt jedoch nahe, dass eine Überlastung von Sprachmodellen mit Informationen, die über ihre aktuellen Fähigkeiten hinausgehen, ihre Effektivität verringern kann. Daher ist eine sorgfältige Abwägung erforderlich, um Rechenressourcen effektiv zu verwalten.
Kostenimplikationen
Längere Kontextfenster können zu erheblichen Rechen- und finanziellen Kosten führen, die Organisationen effektiv verwalten müssen. Die Erweiterung des Kontextfensters von 4K auf 8K Tokens kann zu einem exponentiellen Anstieg der Betriebskosten führen. Daher müssen Organisationen die Vorteile einer verbesserten Leistung von KI-Modellen gegen die erhöhten Kosten längerer Kontextfenster abwägen.
Effektive Kostenmanagementstrategien sind für Organisationen, die eine Erweiterung der Kontextfenster in KI-Modellen in Betracht ziehen, entscheidend. Die Umsetzung dieser Strategien hilft Organisationen, erweiterte KI-Fähigkeiten mit den damit verbundenen finanziellen Auswirkungen in Einklang zu bringen und nachhaltige sowie effiziente KI-Operationen sicherzustellen.
Datenmanagement
Die Verwaltung größerer Mengen an Trainingsdaten stellt KI-Modelle vor erhebliche Herausforderungen, insbesondere bei der Optimierung der Leistung, ohne das System zu überlasten. Forschungsergebnisse zeigen, dass die Bereitstellung einer fokussierten Auswahl relevanter Dokumente für Sprachmodelle zu einer besseren Leistung führt, als sie mit einem übermäßigen Umfang ungefilterter Informationen zu überfluten. Dieser Ansatz stellt sicher, dass die KI effektiv verarbeiten und reagieren kann und die Relevanz ihrer Ausgaben beibehält.
Das Filtern und Verwalten des Kontexts von Trainingsdaten ist unerlässlich, um genaue Antworten und eine effiziente Modellleistung zu ermöglichen. Durch die strategische Auswahl und Organisation relevanter Daten können KI-Modelle auch bei größeren Kontextfenstern kontextuell angemessene und aussagekräftige Ausgaben liefern.
RAG: Verbesserung von KI-Modellen mit einer externen Wissensbasis für erweitertes Gedächtnis
Größere Kontextfenster sind in KI-Modellen entscheidend für ein verbessertes Verständnis und die Bearbeitung komplexer Aufgaben. Sie ermöglichen es Modellen, umfangreichere Informationen beizubehalten und zu nutzen, wodurch Kontinuität und Relevanz in den Antworten verbessert werden. Dies erweist sich als besonders vorteilhaft bei der Bearbeitung komplexer Aufgaben. Die Aufrechterhaltung eines großen Kontextfensters kann jedoch die Rechenanforderungen, Kosten und die Komplexität des Datenmanagements erhöhen.
Um KI-Modelle mit Langzeitgedächtnisfähigkeiten auszustatten und gleichzeitig diese Herausforderungen zu bewältigen, haben Forschende innovative Ansätze wie Retrieval-Augmented Generation (RAG). untersucht. Diese Technik verbessert die Ausgabe von KI-Modellen, indem sie sie mit einer externen Wissensbasis verbindet, die in einer Vektordatenbank gespeichert ist. Dadurch stellt sie Modellen einen breiteren kontextuellen Hintergrund bereit, ohne den mit großen internen Kontextfenstern verbundenen Aufwand. Diese externe Wissensbasis fungiert als erweitertes Gedächtnis und unterstützt Modelle dabei, dynamisch auf einen riesigen Informationspool zuzugreifen, was für die Verarbeitung komplexer Abfragen und die Verbesserung der Tiefe und Genauigkeit von Antworten entscheidend ist.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) kombiniert die generative Leistungsfähigkeit von Sprachmodellen mit dem dynamischen Abruf externer Dokumente. Dieser Ansatz erweitert das Potenzial von LLMs, indem er auf ein breiteres Spektrum an Informationen zugreift und diese integriert, wodurch die Relevanz und Genauigkeit der generierten Antworten verbessert werden.
Ein standardmäßiges RAG-System integriert in der Regel ein Embedding-Modell, eine Vektordatenbank wie Milvus oder dessen verwaltete Version Zilliz Cloud sowie ein LLM (oder ein multimodales Modell), wobei das Embedding-Modellden Text in Vektor-Embeddings umwandelt, die Vektordatenbank Kontextinformationen für Benutzeranfragen speichert und abruft und das LLM Antworten basierend auf dem abgerufenen Kontext generiert.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Die Nutzung von RAG ermöglicht es KI-Modellen, während des Generierungsprozesses dynamisch relevante Dokumente oder Datenpunkte abzurufen, wodurch sichergestellt wird, dass Ausgaben kontextreich und an der Nutzerabsicht ausgerichtet sind. Diese Technik ist besonders nützlich in Szenarien, die detaillierte und präzise Informationen erfordern, wie etwa juristische Recherche oder wissenschaftliche Analyse.
Vergleich der Kontextfenstergrößen beliebter Modelle
 A comparison chart of context window sizes across popular AI models
A comparison chart of context window sizes across popular AI models
Verschiedene LLMs verfügen über unterschiedliche Kontextfenstergrößen, die auf verschiedene Anforderungen und Aufgaben zugeschnitten sind. GPT-4o beispielsweise bietet eine Kontextfenstergröße von 128.000 Token, was seine Fähigkeit, umfangreiche Eingaben zu verarbeiten und kontextrelevante Antworten zu generieren, erheblich verbessert. Gemini 1.5 Pro kann hingegen ein Kontextfenster von mehr als 2 Millionen Token nutzen und bietet damit erhebliche Vorteile beim Umgang mit großen Datensätzen.
Claude 3.5 Sonnet und Llama 3.2 weisen ebenfalls unterschiedliche Kontextfenstergrößen auf, jeweils mit eigenen Stärken und Einschränkungen. Claude 3.5 Sonnet hat eine Kontextfenstergröße von 200.000 Token, wodurch es umfangreiche Informationen in einer einzigen Interaktion verarbeiten kann. Im Gegensatz dazu unterstützt Llama 3.2 ein Kontextfenster von 128.000 Token.
| Modell | Kontextfenster | Max. Ausgabe-Token |
|---|---|---|
| GPT-4o | 128.000 Token | 16.384 Token |
| GPT-4-turbo | 128.000 Token | 4.096 Token |
| GPT-4 | 8.192 Token | 8.192 Token |
| Gemini 1.5 Pro | 2.097.152 Token | 8.192 Token |
| Claude 3.5 Sonnet | 200.000 Token | 8192 Token |
| Llama 3.2 | 128.000 Token | 2048 Token |
Zusammenfassung
Zusammenfassend ist die Beherrschung des Kontextfensters entscheidend für die Weiterentwicklung von KI-Fähigkeiten. Größere Kontextfenster verbessern die Fähigkeit von KI, umfangreiche Dokumente zu verarbeiten und zu analysieren, und machen sie in Bereichen wie der juristischen und medizinischen Forschung unverzichtbar. Die Erweiterung von Kontextfenstern bringt jedoch Herausforderungen mit sich, darunter erhöhte Rechenanforderungen, höhere Kosten und komplexe Anforderungen an das Datenmanagement.
Durch die Implementierung von Techniken wie Retrieval-Augmented Generation (RAG) und Vektordatenbanken können KI-Modelle die Nutzung langer Kontextfenster mit einer externen Wissensbasis optimieren, die von Vektor-Datenbanken unterstützt wird, und so kontextrelevante und präzise Antworten sicherstellen. Mit Blick auf die Zukunft wird es entscheidend sein, die Größe des Kontextfensters mit Effizienz in Einklang zu bringen und innovative Strategien zu erkunden, um fortschrittliche KI-Anwendungen zu entwickeln, die komplexe Aufgaben effektiv bewältigen können. Die Reise zur Beherrschung von Kontextfenstern dauert an, und die Möglichkeiten sind grenzenlos.
Häufig gestellte Fragen
Was ist ein Kontextfenster in der KI?
Ein Kontextfenster in der KI ist der Textbereich um ein Ziel-Token herum, den das Modell zur Generierung von Antworten verwendet, und bestimmt die Menge an Informationen, die es auf einmal verarbeiten kann. Das Verständnis dieses Konzepts ist entscheidend für die Optimierung von KI-Interaktionen.
Warum sind größere Kontextfenster wichtig?
Größere Kontextfenster sind entscheidend, da sie das Verständnis und die Fähigkeit eines KI-Modells, umfangreiche Dokumente zu analysieren, erheblich verbessern, was zu kohärenteren und kontextrelevanteren Antworten führt. Dieser Fortschritt verbessert letztlich die gesamte Interaktionsqualität.
Wie wirken sich Token-Limits auf KI-Modelle?
Token-Limits wirken sich entscheidend auf KI-Modelle aus, indem sie die maximale Eingabegröße bestimmen, die sie verarbeiten können. Das Überschreiten dieser Limits führt zu unvollständigen oder ungenauen Ausgaben, was die Aufteilung von Text in kleinere Teile erforderlich macht.
Welche Herausforderungen bringt die Erweiterung von Kontextfenstern mit sich?
Die Erweiterung von Kontextfenstern bringt erhebliche Herausforderungen mit sich, darunter erhöhte Rechenanforderungen und gestiegene Betriebskosten. Darüber hinaus erschwert sie das Datenmanagement und erfordert eine sorgfältige Abwägung vor der Implementierung.
Wie können KI-Modelle mit langen Kontextfenstern verbessert werden?
KI-Modelle können mit langen Kontextfenstern verbessert werden, indem Techniken wie Retrieval-Augmented Generation (RAG) und die Integration von Vektor-Datenbanken genutzt werden, die dazu beitragen, kontextuell relevante und genaue Antworten sicherzustellen. Dieser Ansatz verbessert die Leistung des Modells beim Umgang mit umfangreichen Informationen erheblich.
Weitere Ressourcen
- Tokens verstehen
- Was ist ein Kontextfenster in der KI?
- Bedeutung größerer Kontextfenster in KI-Modellen
- Herausforderungen bei der Erweiterung von Kontextfenstern in KI-Modellen
- RAG: Verbesserung von KI-Modellen mit einer externen Wissensbasis für erweitertes Gedächtnis
- Vergleich der Kontextfenstergrößen beliebter Modelle
- Zusammenfassung
- Häufig gestellte Fragen
- Weitere Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren