




Einführung in die Vektorähnlichkeitssuche
In den vorherigen Tutorials haben wir uns unstrukturierte Daten, Vektordatenbanken und Milvus angesehen – die weltweit beliebteste Open-Source-Vektordatenbank, die für Ähnlichkeitssuche verwendet wird. Außerdem haben wir kurz die Idee von Embeddings angesprochen, hochdimensionalen Vektoren, die als hervorragende semantische Repräsentationen von unstrukturierten Daten dienen. Ein wichtiger Hinweis, den man sich merken sollte: Embeddings und Vektorrepräsentationen, die „nah“ beieinander liegen, repräsentieren semantisch ähnliche Datenelemente.
In dieser Einführung in die Vektorsuche (auch Ähnlichkeitssuche genannt) definieren wir, was sie ist, und beantworten einige grundlegende Fragen dazu. Anschließend bauen wir auf diesem Wissen auf, indem wir ein Beispiel für Word Embeddings durchgehen und sehen, wie semantisch ähnliche Elemente unstrukturierter Daten „nahe“ beieinander liegen, während unähnliche Elemente unstrukturierter Daten „weit“ voneinander entfernt sind. Dies führt zu einem Überblick auf hoher Ebene über die Nearest-Neighbor-Suche, ein Rechenproblem, bei dem es darum geht, basierend auf einer einheitlichen Distanzmetrik den/die nächstgelegenen Vektor(en) zu einem Abfragevektor zu finden. Wir werden einige bekannte Methoden (Vektorähnlichkeitssuchalgorithmen) für die Nearest-Neighbor-Suche (einschließlich meines Favoriten – ANNOY) sowie häufig verwendete Distanzmetriken durchgehen.
Tauchen wir ein.
Was ist Vektorsuche oder Vektorähnlichkeitssuche?
Vektorsuche, auch bekannt als Vektorähnlichkeitssuche oder Nearest-Neighbor-Suche oder semantische Suche, ist eine Technik, die in Datenabruf- und Informationsabrufsystemen verwendet wird, um Elemente oder Datenpunkte zu finden, die einem gegebenen Abfragevektor ähnlich sind oder eng mit ihm zusammenhängen. Im Gegensatz zur traditionellen Stichwortsuche, die exakte Wörter oder Phrasen abgleicht, versteht die semantische Suche die Absicht und die kontextuelle Bedeutung hinter einer Abfrage, sodass sie relevantere Ergebnisse zurückgeben kann, selbst wenn die exakten Schlüsselwörter im Inhalt nicht vorhanden sind. Bei der Vektorsuche stellen wir Datenpunkte wie Bilder, Texte und Audio als Vektoren in einem hochdimensionalen Raum dar. Das Ziel der Vektorsuche ist es, die relevantesten Vektoren, die einem Abfragevektor ähnlich oder am nächsten sind, effizient zu suchen und abzurufen.
Typischerweise messen Distanzmetriken wie die euklidische Distanz oder Kosinusähnlichkeit die Ähnlichkeit zwischen Vektoren. Die Nähe des Vektors im Vektorraum bestimmt, wie ähnlich er ist. Um Suchergebnisse für Vektoren effizient zu organisieren und anzuzeigen, verwenden Vektorsuchalgorithmen Indexierungsstrukturen wie baumbasierte Strukturen oder Hashing-Techniken.
Vektorsuche ist zentral für Vektordatenbanken und hat verschiedene Anwendungen, darunter Empfehlungssysteme, Bild- und Videoabruf, Verarbeitung natürlicher Sprache, Anomalieerkennung sowie Frage-und-Antwort-Chatbots. Durch die Verwendung semantischer Suche wird es möglich, relevante Elemente, Muster oder Beziehungen innerhalb hochdimensionaler Daten zu finden, was einen genaueren und effizienteren Informationsabruf ermöglicht.
Vektorsuche ist eine leistungsstarke Methode zur Analyse und zum Abruf von Informationen aus hochdimensionalen Räumen. Sie ermöglicht es Benutzern, ähnliche oder eng verwandte Elemente zu einer gegebenen Abfrage zu finden, was sie in verschiedenen Bereichen entscheidend macht. Hier sind die Vorteile der Vektorsuche:
Ähnlichkeitsbasierter Abruf— Semantische Suche ermöglicht ähnlichkeitsbasierten Abruf und erlaubt es Benutzern, ähnliche oder eng verwandte Elemente zu einer gegebenen Abfrage zu finden. Ähnlichkeitsbasierter Abruf ist in verschiedenen Bereichen entscheidend, etwa in Empfehlungssystemen, in denen Benutzer personalisierte Empfehlungen basierend auf ihren Präferenzen oder Ähnlichkeiten zu anderen Benutzern erwarten.
Analyse hochdimensionaler Daten — Mit der zunehmenden Verfügbarkeit hochdimensionaler Daten, wie Bildern, Audio- und Textdaten, werden traditionelle Suchmethoden weniger effektiv. Die Vektorsuche bietet eine leistungsstarke Möglichkeit, Informationen aus hochdimensionalen Räumen zu analysieren und abzurufen, und ermöglicht so eine genauere und effizientere Datenexploration.
Nearest-Neighbor-Suche — Effiziente Nearest-Neighbor-Suchalgorithmen finden die nächsten Nachbarn zu einem gegebenen Abfragevektor. Die Nearest-Neighbor-Suche ist praktisch für kritische Aufgaben wie die Ähnlichkeitssuche nach Bildern oder Dokumenten, inhaltsbasierte Retrieval oder Anomalieerkennung, bei denen die nächsten Übereinstimmungen oder ähnliche Elemente gefunden werden müssen.
Verbesserte Benutzererfahrung— Durch die Nutzung der semantischen Suche können Anwendungen den Benutzern relevantere und personalisierte Ergebnisse liefern. Ob es darum geht, relevante Empfehlungen bereitzustellen, visuell ähnliche Bilder abzurufen oder Dokumente mit ähnlichem Inhalt zu finden: Die Vektorsuche verbessert die gesamte Benutzererfahrung, indem sie gezieltere und aussagekräftigere Ergebnisse liefert.
Skalierbarkeit — Vektorsuchalgorithmen und Indexierungsstrukturen verarbeiten groß angelegte Datensätze und hochdimensionale Räume effizient. Sie ermöglichen schnelle Such- und Abrufoperationen und machen es so praktikabel, ähnlichkeitsbasierte Abfragen in Echtzeit durchzuführen, selbst bei riesigen Datensätzen.
Wie funktioniert eine Vector Search Engine?
Mit der Popularität von AI und LLMs erweitert jedes Entwicklertool, jede Suchmaschine und jede Datenbank ihren Funktionsumfang um Vektorsuchfunktionen, und aus diesem Grund werden die Begriffe Vektor-Engine und Vector Search Engines oft synonym mit Vector Databases verwendet. Vector Search Engines führen eine Vektor-semantische Suche durch (manchmal als Vector Search bezeichnet). Die Vektorsuche ist eine Technik zum Finden ähnlicher Elemente oder Datenpunkte in einem Datensatz auf der Grundlage ihrer Darstellung als Vektoren in einem hochdimensionalen Raum. Jedes Element wird einem Punkt in diesem Raum zugeordnet, wobei jede Vektordimension ein bestimmtes Merkmal darstellt. Der Vektorsuchprozess umfasst Indexierung, Abfrage, Ranking und Abruf.
Um eine Vektorsuche durchzuführen, stellen Sie Ihre Datenelemente zunächst als Vektoren dar, indem Sie Techniken wie Word2Vec oder für Textdaten verwenden. Eine Indexdatenstruktur speichert diese Vektoren effizient für einen schnellen Abruf, unter Verwendung von Methoden wie KD-trees oder hash tables. Wenn ein Benutzer ein Abfrageelement einreicht, wird es in eine Vektordarstellung umgewandelt, mit den indexierten Vektoren anhand von Ähnlichkeitsmetriken wie Kosinus-Ähnlichkeit oder euklidischer Distanz verglichen, und die ähnlichsten Elemente werden abgerufen und eingestuft.
Anwendungsfälle der Vektorsuche
- Ähnlichkeitssuche für Bilder, Videos und Audio
- AI-gestützte Wirkstoffforschung
- Semantische Suchmaschine
- Klassifizierung von DNA-Sequenzen
- Frage-Antwort-System
- Empfehlungssystem
- Anomalieerkennung
- Retrieval Augmented Generation (RAG)
Nachdem wir nun die Grundlagen der Vektorsuche behandelt haben, schauen wir uns die technischeren Details anhand eines Word-Embedding-Beispiels an und schließen mit einem allgemeinen Überblick über die Nearest-Neighbor-Suche ab.
Embeddings vergleichen
Sobald Benutzer entscheiden, dass sie in ihrer Lösung mit dem Aufbau einer Vektorsuche beginnen möchten, lautet die nächste Frage, die sie oft stellen: „Welches Machine-Learning-Modell sollte ich verwenden, um Vector Embeddings zu erstellen.“ Bevor Sie ein Modell auswählen können, ist es wichtig, Vektor-Embeddings zu verstehen, indem Sie einige Beispiele vergleichen. Gehen wir ein paar Beispiele für Word Embeddings durch. Der Einfachheit halber verwenden wir word2vec, ein älteres Modell, das eine Trainingsmethodik auf Basis von skipgrams verwendet. BERT und andere moderne transformerbasierte Modelle können Ihnen stärker kontextualisierte Word Embeddings liefern, aber der Einfachheit halber bleiben wir bei word2vec. Jay Alammar bietet ein großartiges Tutorial zu word2vec, falls Sie daran interessiert sind, Machine-Learning-Modelle etwas intensiver zu nutzen.
Einige Vorbereitungsarbeiten
Bevor wir beginnen, müssen wir die gensim-Bibliothek installieren und ein word2vec-Modell laden.
% pip install gensim --disable-pip-version-check
% wget https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz
% gunzip GoogleNews-vectors-negative300.bin
Requirement already satisfied: gensim in /Users/fzliu/.pyenv/lib/python3.8/site-packages (4.1.2)
Requirement already satisfied: smart-open>=1.8.1 in /Users/fzliu/.pyenv/lib/python3.8/site-packages (from gensim) (5.2.1)
Requirement already satisfied: numpy>=1.17.0 in /Users/fzliu/.pyenv/lib/python3.8/site-packages (from gensim) (1.19.5)
Requirement already satisfied: scipy>=0.18.1 in /Users/fzliu/.pyenv/lib/python3.8/site-packages (from gensim) (1.7.3)
--2022-02-22 00:30:34-- https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz
Resolving s3.amazonaws.com (s3.amazonaws.com)... 52.216.20.165
Connecting to s3.amazonaws.com (s3.amazonaws.com)|52.216.20.165|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1647046227 (1.5G) [application/x-gzip]
Saving to: GoogleNews-vectors-negative300.bin.gz
GoogleNews-vectors- 100%[===================>] 1.53G 2.66MB/s in 11m 23s
2022-02-22 00:41:57 (2.30 MB/s) - GoogleNews-vectors-negative300.bin.gz saved [1647046227/1647046227]
gunzip: GoogleNews-vectors-negative300.bin: unknown suffix -- ignored
Nachdem wir nun alle Vorarbeiten erledigt haben, die zum Erzeugen von Wort-zu-Vektor-Embeddings erforderlich sind, laden wir das trainierte word2vec-Modell.
>>> from gensim.models import KeyedVectors
>>> model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Beispiel 0: Marlon Brando
Schauen wir uns an, wie word2vec den berühmten Schauspieler Marlon Brando interpretiert.
>>> print(model.most_similar(positive=['Marlon_Brando']))
[('Brando', 0.757453978061676), ('Humphrey_Bogart', 0.6143958568572998), ('actor_Marlon_Brando', 0.6016287207603455), ('Al_Pacino', 0.5675410032272339), ('Elia_Kazan', 0.5594002604484558), ('Steve_McQueen', 0.5539456605911255), ('Marilyn_Monroe', 0.5512186884880066), ('Jack_Nicholson', 0.5440199375152588), ('Shelley_Winters', 0.5432392954826355), ('Apocalypse_Now', 0.5306933522224426)]
Marlon Brando arbeitete mit Al Pacino in Der Pate und mit Elia Kazan in Endstation Sehnsucht. Außerdem spielte er in Apocalypse Now mit.
Beispiel 1: Wenn alle Könige ihre Königinnen auf dem Thron hätten
Vektoren können addiert und voneinander subtrahiert werden, um zugrunde liegende semantische Veränderungen zu demonstrieren.
>>> print(model.most_similar(positive=['king', 'woman'], negative=['man'], topn=1))
[('queen', 0.7118193507194519)]
Wer sagt, dass Ingenieure nicht ab und zu ein bisschen Dance-Pop genießen können?
Beispiel 2: Apple, das Unternehmen, die Frucht, ... oder beides?
Das Wort „apple“ kann sich sowohl auf das Unternehmen als auch auf die köstliche rote Frucht beziehen. In diesem Beispiel sehen wir, dass Word2Vec beide Bedeutungen beibehält.
>>> print(model.most_similar(positive=['samsung', 'iphone'], negative=['apple'], topn=1))
>>> print(model.most_similar(positive=['fruit'], topn=10)[9:])
[('droid_x', 0.6324754953384399)]
[('apple', 0.6410146951675415)]
„Droid“ bezieht sich auf Samsungs erstes 4G-LTE-Smartphone („Samsung“ + „iPhone“ - „Apple“ = „Droid“), während „apple“ das 10. nächstgelegene Wort zu „fruit“ ist.
Vektorsuchstrategien
Nachdem wir nun die Leistungsfähigkeit von Vektor-Embeddings gesehen haben, werfen wir einen kurzen Blick auf einige der Möglichkeiten, wie wir eine Nearest-Neighbor-Suche durchführen können. Dies ist keine umfassende Liste; wir gehen lediglich kurz auf einige gängige Methoden ein, um einen allgemeinen Überblick darüber zu geben, wie Vektorsuche im großen Maßstab durchgeführt wird. Beachten Sie, dass sich einige dieser Methoden nicht gegenseitig ausschließen – es ist zum Beispiel möglich, Quantisierung in Verbindung mit Raumaufteilung zu verwenden.
(Wir werden außerdem jede dieser Methoden in zukünftigen Tutorials im Detail behandeln, also bleiben Sie dran.)
Lineare Suche
Der einfachste, aber naivste Algorithmus zur Suche nach nächsten Nachbarn ist die gute alte lineare Suche: Dabei wird die Distanz von einem Anfragevektor zu allen anderen Vektoren in der Vektordatenbank berechnet.
Aus offensichtlichen Gründen funktioniert die naive Suche nicht, wenn wir versuchen, unsere Vektordatenbank auf Dutzende oder Hunderte Millionen von Vektoren zu skalieren. Wenn jedoch die Gesamtzahl der Elemente in der Datenbank klein ist, kann dies tatsächlich die effizienteste Methode zur Durchführung einer Vektorsuche sein, da keine separate Datenstruktur für den Index erforderlich ist, während Einfügungen und Löschungen relativ einfach implementiert werden können.
Aufgrund der fehlenden Speicherkomplexität sowie des konstanten Speicher-Overheads, der mit der naiven Suche verbunden ist, kann diese Methode die Raumaufteilung oft übertreffen, selbst wenn über eine moderate Anzahl von Vektoren abgefragt wird.
Raumaufteilung
Raumaufteilung ist kein einzelner Algorithmus, sondern vielmehr eine Familie von Algorithmen, die alle dasselbe Konzept verwenden.
K-dimensionale Bäume (kd-Bäume) sind in dieser Familie vielleicht die bekanntesten und funktionieren, indem sie den Suchraum kontinuierlich halbieren (die Vektoren in „linke“ und „rechte“ Buckets aufteilen), ähnlich wie binäre Suchbäume.
Der Inverted File Index (IVF) ist ebenfalls eine Form der Raumaufteilung und funktioniert, indem jeder Vektor seinem nächsten Zentroid zugewiesen wird – Suchen werden dann durchgeführt, indem zunächst der nächstgelegene Zentroid des Anfragevektors bestimmt und die Suche in dessen Umgebung durchgeführt wird, wodurch die Gesamtzahl der zu durchsuchenden Vektoren erheblich reduziert wird. IVF ist eine recht beliebte Indexierungsstrategie und wird häufig mit anderen Indexierungsalgorithmen kombiniert, um die Leistung zu verbessern.
Quantisierung
Quantisierung ist eine Technik zur Verringerung der Gesamtgröße der Datenbank durch Reduzierung der Präzision der Vektoren.
Skalare Quantisierung (SQ) funktioniert beispielsweise, indem hochpräzise Gleitkommavektoren mit einem Skalarwert multipliziert werden und anschließend die Elemente des resultierenden Vektors auf ihre nächstgelegenen Ganzzahlen umgewandelt werden. Dies reduziert nicht nur die effektive Größe der gesamten Datenbank (z. B. um den Faktor acht bei der Umwandlung von float64_t zu int8_t), sondern hat auch den positiven Nebeneffekt, dass Berechnungen der Vektordistanz zwischen Vektoren beschleunigt werden.
Produktquantisierung (PQ) ist eine weitere Quantisierungstechnik, die ähnlich wie Wörterbuchkompression funktioniert. Bei PQ werden alle Vektoren in gleich große Untervektoren aufgeteilt, und jeder Untervektor wird anschließend durch einen Zentroid ersetzt.
Hierarchical Navigable Small Worlds (HNSW)
Hierarchical Navigable Small Worlds ist ein graphbasierter Indexierungs- und Abrufalgorithmus.
Dies funktioniert anders als Produktquantisierung: Anstatt die Durchsuchbarkeit der Datenbank durch Verringerung ihrer effektiven Größe zu verbessern, erstellt HNSW aus den ursprünglichen Daten einen mehrschichtigen Graphen. Obere Schichten enthalten nur „lange Verbindungen“, während untere Schichten nur „kurze Verbindungen“ zwischen Vektoren in der Datenbank enthalten (siehe den nächsten Abschnitt für einen Überblick über Metriken der Vektordistanz). Einzelne Graphverbindungen werden à la Skip Lists erstellt.
Mit dieser Architektur wird die Suche recht unkompliziert – wir durchlaufen gierig den obersten Graphen (denjenigen mit den längsten Verbindungen zwischen Vektoren) nach dem Vektor, der unserem Anfragevektor am nächsten liegt. Anschließend machen wir dasselbe für die zweite Schicht und verwenden das Ergebnis der Suche in der ersten Schicht als Ausgangspunkt. Dies wird fortgesetzt, bis wir die Suche in der untersten Schicht abschließen, deren Ergebnis zum nächsten Nachbarn des Anfragevektors wird.
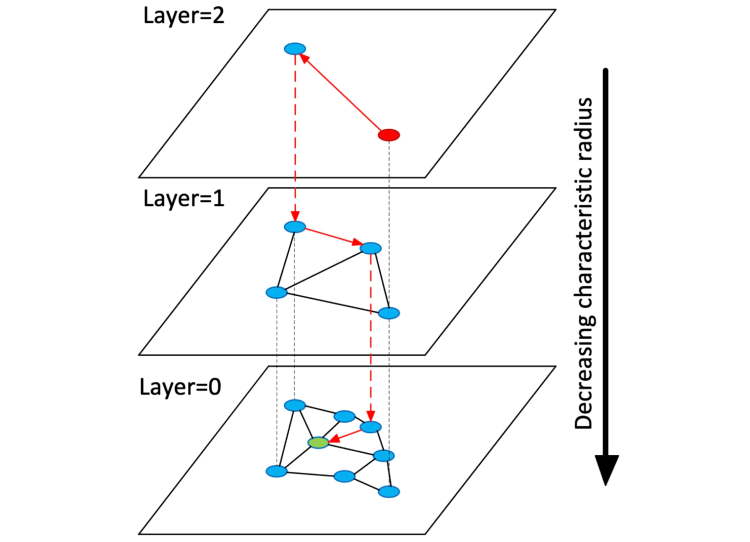 HNSW, visualisiert. Bildquelle: https://arxiv.org/abs/1603.09320
HNSW, visualisiert. Bildquelle: https://arxiv.org/abs/1603.09320
Approximate Nearest Neighbors Oh Yeah
Dies ist vermutlich mein Lieblings-ANN-Algorithmus, einfach wegen seines verspielten und nicht intuitiven Namens. Approximate Nearest Neighbors Oh Yeah (ANNOY) ist ein baumbasierter Algorithmus, der durch Spotify populär gemacht wurde (er wird in ihrem Musikempfehlungssystem verwendet). Trotz des seltsamen Namens ist das zugrunde liegende Konzept hinter ANNOY eigentlich recht einfach – binäre Bäume.
ANNOY funktioniert, indem es zunächst zufällig zwei Vektoren in der Datenbank auswählt und den Suchraum entlang der Hyperebene halbiert, die diese beiden Vektoren trennt. Dies geschieht iterativ, bis es weniger als einen vordefinierten Parameter NUM_MAX_ELEMS pro Knoten gibt. Da der resultierende Index im Wesentlichen ein binärer Baum ist, ermöglicht uns dies, unsere Suche mit O(log n)-Komplexität durchzuführen.
 ANNOY, visualisiert. Bildquelle: https://github.com/spotify/annoy
ANNOY, visualisiert. Bildquelle: https://github.com/spotify/annoy
Häufig verwendete Ähnlichkeitsmetriken
Die allerbesten Vektordatenbanken sind ohne Ähnlichkeitsmetriken nutzlos – Methoden zur Berechnung der Distanz zwischen zwei Vektoren. Es gibt zahlreiche Metriken, daher werden wir hier nur die am häufigsten verwendete Teilmenge besprechen.
Ähnlichkeitsmetriken für Gleitkomma-Vektoren
Die häufigsten Ähnlichkeitsmetriken für Gleitkomma-Vektoren sind, in keiner bestimmten Reihenfolge, L1-Distanz, L2-Distanz und Kosinus-Ähnlichkeit. Die ersten beiden Werte sind Distanzmetriken (niedrigere Werte bedeuten mehr Ähnlichkeit, während höhere Werte weniger Ähnlichkeit bedeuten), während die Kosinus-Ähnlichkeit eine Ähnlichkeitsmetrik ist (höhere Werte bedeuten mehr Ähnlichkeit).
Die L1-Distanz wird auch häufig als Manhattan-Distanz bezeichnet, passend benannt nach der Tatsache, dass man sich, um in Manhattan von Punkt A nach Punkt B zu gelangen, entlang einer von zwei senkrechten Richtungen bewegen muss. Die zweite Gleichung, die L2-Distanz, ist einfach die Distanz zwischen zwei Vektoren im euklidischen Raum. Die dritte und letzte Gleichung ist die Kosinus-Distanz, äquivalent zum Kosinus des Winkels zwischen zwei Vektoren. Beachte, dass die Gleichung für die Kosinus-Ähnlichkeit dem Skalarprodukt zwischen normalisierten Versionen der Eingabevektoren a und b entspricht.
Mit ein wenig Mathematik können wir außerdem zeigen, dass L2-Distanz und Kosinus-Ähnlichkeit bei der Ähnlichkeitsrangfolge für Vektoren mit Einheitsnorm effektiv äquivalent sind:
Erinnere dich daran, dass Vektoren mit Einheitsnorm eine Länge von 1 haben:
Damit erhalten wir:
Da wir Vektoren mit Einheitsnorm haben, ergibt sich die Kosinus-Distanz als das Skalarprodukt zwischen a und b (der Nenner in Gleichung 3 oben ergibt 1):
Im Wesentlichen sind L2-Distanz und Kosinus-Ähnlichkeit für Vektoren mit Einheitsnorm funktional äquivalent! Denke immer daran, deine Embeddings zu normalisieren.
Ähnlichkeitsmetriken für binäre Vektoren
Binäre Vektoren haben, wie ihr Name nahelegt, keine auf Arithmetik basierenden Metriken à la Gleitkomma-Vektoren. Ähnlichkeitsmetriken für binäre Vektoren beruhen stattdessen entweder auf Mengenlehre, Bit-Manipulation oder einer Kombination aus beidem (schon okay, ich hasse diskrete Mathematik auch). Hier sind die Formeln für zwei häufig verwendete Ähnlichkeitsmetriken für binäre Vektoren:
Die erste Gleichung wird Tanimoto-/Jaccard-Distanz genannt und ist im Wesentlichen ein Maß für das Ausmaß der Überschneidung zwischen zwei binären Vektoren. Die zweite Gleichung ist die Hamming-Distanz und zählt die Anzahl der Vektorelemente in a und b, die sich voneinander unterscheiden.
Sie können diese Ähnlichkeitsmetriken höchstwahrscheinlich bedenkenlos ignorieren, da die Mehrheit der Anwendungen die Kosinus-Ähnlichkeit über Gleitkomma-Embeddings verwendet.
Zusammenfassung
In diesem Tutorial haben wir uns die Vektorsuche sowie einige gängige Vektorsuchalgorithmen und Distanzmetriken angesehen. Hier sind einige wichtige Erkenntnisse:
Embedding-Vektoren sind leistungsstarke Repräsentationen, sowohl im Hinblick auf den Abstand zwischen den Vektoren als auch im Hinblick auf Vektorarithmetik. Durch die Anwendung einer großzügigen Menge an Vektoralgebra auf Embeddings können wir skalierbare semantische Analysen nur mit grundlegenden mathematischen Operatoren durchführen.
Semantische Vektorsuche überwindet die Einschränkung der Stichwortsuche, indem sie es Ihnen ermöglicht, auf Grundlage der Bedeutung Ihrer Abfrage zu suchen. Sie ermöglicht das schnelle Abrufen von Antworten durch die Durchführung einer Vektorsuche.
Es gibt eine große Vielfalt an Algorithmen für die approximative Suche nach nächsten Nachbarn und/oder Indextypen, aus denen Sie wählen können. Der heute am häufigsten verwendete ist HNSW, aber ein anderer Indexierungsalgorithmus kann für Ihre spezielle Anwendung besser funktionieren, abhängig von der Gesamtzahl der Vektor-Embeddings, die Sie haben, zusätzlich zur Länge jedes einzelnen Vektors.
Die beiden wichtigsten heute verwendeten Distanzmetriken sind L2-/Euklidische Distanz und Kosinus-Distanz. Diese beiden Metriken sind, wenn sie auf normalisierte Embeddings angewendet werden, funktional äquivalent.
Vielen Dank, dass Sie bei diesem Tutorial dabei waren! Vektorsuche ist ein zentraler Bestandteil von Milvus und wird es auch weiterhin bleiben. In zukünftigen Tutorials werden wir uns eingehender mit den am häufigsten verwendeten ANNS-Algorithmen beschäftigen – HNSW und ScaNN.
Werfen Sie einen weiteren Blick auf die Kurse zu Vector Database 101
- Einführung in unstrukturierte Daten
- Was ist eine Vektordatenbank?
- Vergleich von Vektordatenbanken, Vektorsuchbibliotheken und Vektorsuch-Plugins
- Einführung in Milvus
- Milvus Quickstart
- Einführung in die Vektorähnlichkeitssuche
- Grundlagen von Vektorindizes und der Inverted File Index
- Skalare Quantisierung und Produktquantisierung
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (ANNOY)
- Den richtigen Vektorindex für Ihr Projekt auswählen
- DiskANN und der Vamana-Algorithmus
Weiterlesen

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.