




Die 10 wichtigsten Context-Engineering-Techniken, die Sie für Production RAG kennen sollten
Wenn wir zum ersten Mal eine RAG- oder Agent-Demo erstellen, funktionieren die Dinge normalerweise gut. Mit einem kleinen Datensatz, ein paar Prompts und einfacher Retrieval können wir oft innerhalb weniger Stunden einen Prototyp zum Laufen bringen.
Die eigentliche Herausforderung entsteht, wenn wir versuchen, das System in Produktion zu betreiben. Mit zunehmender Nutzung treten schnell Probleme auf. Retrieval wird langsamer, Antworten werden weniger zuverlässig, die Latenz steigt und die Kosten nehmen zu. Was in einer kleinen Demo funktioniert hat, bricht oft zusammen, wenn echte Daten, echte Nutzer und längere Kontexte ins Spiel kommen.
An diesem Punkt erkennen wir meist, dass das Problem nicht nur das Modell ist. Es geht auch darum, wie Kontext vorbereitet und an das Modell übergeben wird. Hier kommt Context Engineering ins Spiel. Es konzentriert sich darauf, die Informationen abzurufen, zu organisieren, zu verfeinern und zu verwalten, die ein Sprachmodell zur Generierung von Antworten verwendet.
In diesem Artikel erklären wir, wie Context Engineering in der Praxis funktioniert. Wir betrachten aktuelle Ansätze zum Aufbau von Kontext, zu seiner effizienten Verarbeitung und zu seiner langfristigen Verwaltung. Diese Techniken helfen dabei, einfache Demos in Systeme zu verwandeln, die zuverlässig in Produktion laufen können.
Hinweis: Dieser Artikel basiert hauptsächlich auf dem Paper https://arxiv.org/html/2507.13334v1.
Was ist Context Engineering?
Context Engineering konzentriert sich darauf, die Informationen zusammenzustellen, die ein Large Language Model benötigt, um eine Frage gut zu beantworten. Diese Informationen sind nicht auf den Prompt beschränkt. Sie umfassen auch die Anfrage des Nutzers, abgerufene Dokumente, den Gesprächsverlauf und andere relevante Daten. Ziel ist es, die Genauigkeit zu verbessern, die Antwortzeit zu verkürzen und die Kosten zu kontrollieren.
Diese Arbeit erfolgt größtenteils automatisch durch Algorithmen. Context Engineering kombiniert Prompt Engineering, Retrieval-Augmented Generation (RAG) und Multi-Agent-Techniken zu einem einzigen System, anstatt sie getrennt zu verwenden.
In der Praxis besteht ein Context-Engineering-Setup aus zwei Teilen. Der erste besteht aus grundlegenden Komponenten, die Datenabruf, Verarbeitung und Orchestrierung übernehmen. Die zweite Ebene besteht aus komplexeren Systemen, die diese Komponenten zu vollständigen Anwendungen kombinieren. Teams können diese Teile kombinieren und wiederverwenden, um sie an unterschiedliche Produktionsszenarien anzupassen.
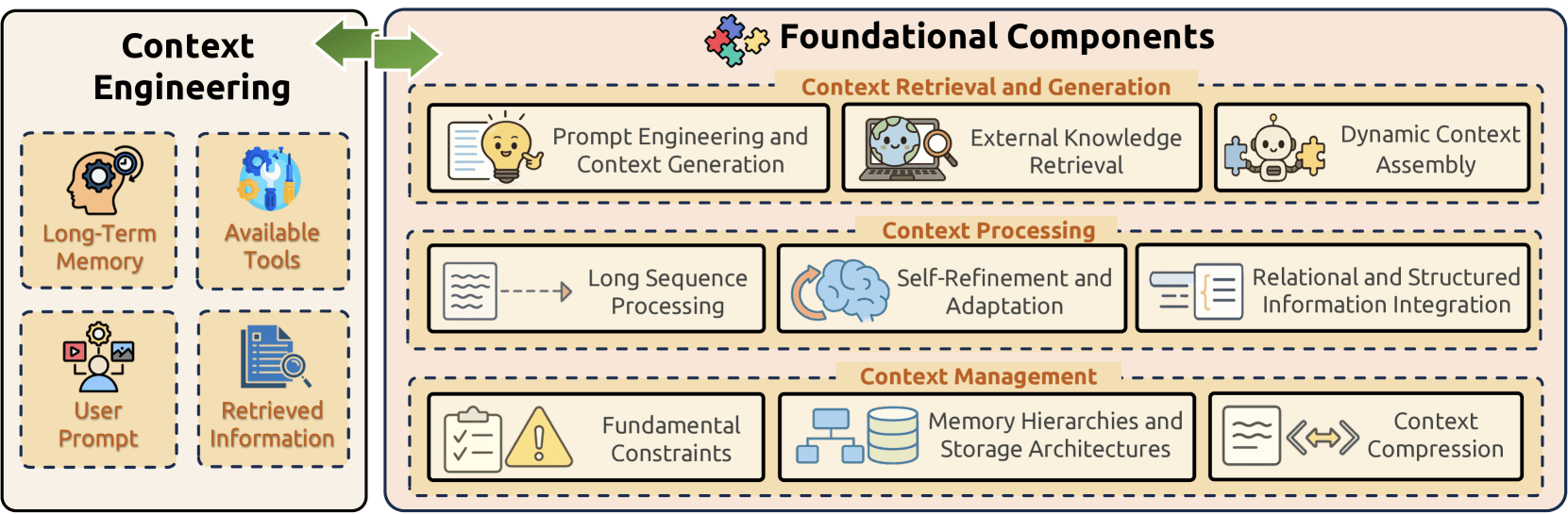
Grundlegende Komponenten
Context Engineering baut auf drei grundlegenden Komponenten auf, die gemeinsam die zentralen Herausforderungen des Informationsmanagements in Large Language Models adressieren:
- Context Retrieval and Generation beschafft geeignete Kontextinformationen durch Prompt Engineering, externen Wissensabruf und dynamische Kontextzusammenstellung;
- Context Processing transformiert und optimiert erfasste Informationen durch Verarbeitung langer Sequenzen, Selbstverfeinerungsmechanismen und Integration strukturierter Daten;
- Context Management befasst sich mit der effizienten Organisation und Nutzung von Kontextinformationen, indem es grundlegende Einschränkungen adressiert, ausgefeilte Speicherhierarchien implementiert und Kompressionstechniken entwickelt.
Komplexe Systeme in der Praxis
Auf Grundlage dieser grundlegenden Komponenten wird Context Engineering über mehrere gängige Arten komplexer Systeme angewendet.
Retrieval-Augmented Generation (RAG) ermöglicht es einem Modell, Informationen in einer Wissensdatenbank nachzuschlagen, bevor es eine Frage beantwortet. Dies trägt dazu bei, sicherzustellen, dass die Antwort auf echten, aktuellen Daten basiert, statt dass das Modell rät. In der Praxis kann RAG als einfache modulare Pipelines aufgebaut werden, von Agenten gesteuert werden, die den Abruf kontrollieren, oder mit Knowledge Graphs für reichhaltigeren Kontext kombiniert werden.
Memory systems ermöglichen es Modellen, Informationen über Interaktionen hinweg zu verfolgen. Das Kurzzeitgedächtnis hält Details aus der aktuellen Unterhaltung fest, während das Langzeitgedächtnis frühere Gespräche und erlerntes Wissen speichert. Dadurch werden Multi-Turn-Unterhaltungen konsistenter und das System kann sich im Laufe der Zeit verbessern.
Werkzeugintegriertes Reasoning ermöglicht es Modellen, externe Werkzeuge wie Taschenrechner, Suchmaschinen oder APIs zu verwenden, anstatt sich nur auf textbasiertes Reasoning zu verlassen. Ein wichtiger Teil dieses Setups besteht darin, Werkzeugergebnisse zum richtigen Zeitpunkt wieder in den Kontext einzufügen, damit das Modell sie effektiv nutzen kann.
Multi-Agenten-Systeme verwenden mehrere Modelle, die zusammenarbeiten, um komplexe Aufgaben zu bewältigen. Jeder Agent hat eine spezifische Rolle, und das System koordiniert, wie sie kommunizieren, Informationen teilen und synchron bleiben, um ein konsistentes Ergebnis zu erzeugen.
Kontextverarbeitung
Zuvor haben wir die drei Hauptbestandteile des Context Engineering vorgestellt: Kontextabruf und -generierung, Kontextverarbeitung und Kontextmanagement. Diese bilden die grundlegenden Bausteine eines praktischen Kontextsystems.
Kontextverarbeitung ist besonders wichtig. Sie nimmt rohe abgerufene Informationen und bereinigt, formt und organisiert sie so, dass das Modell sie effizienter verstehen und nutzen kann.
In diesem Abschnitt betrachten wir, wie Kontextverarbeitung in realen Systemen durchgeführt wird und welche Ansätze üblicherweise verwendet werden.
Verarbeitung langer Kontexte
Die Verarbeitung sehr langer Kontexte ist teuer, weil Transformer-Modelle Self-Attention verwenden, die mit zunehmender Eingabelänge schlecht skaliert. Wenn die Sequenz länger wird, steigen Rechenaufwand und Speicherverbrauch schnell an, wodurch in Produktionssystemen echte Engpässe entstehen.
Zum Beispiel erhöht die Erweiterung der Eingabelänge von Mistral-7B von 4K auf 128K Token die Rechenkosten um etwa das 122-Fache. Auch der Speicherverbrauch steigt sowohl beim Prefilling als auch beim Decoding stark an. In der Praxis können Modelle wie Llama 3.1 8B bis zu 16 GB Speicher für eine einzelne Anfrage mit 128K Token benötigen.
Um diese Grenzen zu umgehen, verwenden Forschende hauptsächlich drei Ansätze.
Einer besteht darin, neue Modellarchitekturen wie Mamba zu entwickeln, die von Natur aus günstiger auszuführen sind. Ein anderer besteht darin, Techniken wie Positionsinterpolation zu verwenden, damit bestehende Modelle deutlich längere Eingaben verarbeiten können. Der dritte Ansatz verbessert, wie Berechnungen durchgeführt werden, indem redundante Arbeit vermieden und Speicher effizienter genutzt wird, sodass die Verarbeitung langer Kontexte schneller ist und weniger Ressourcen verbraucht.
(1) Architektonische Innovationen für lange Kontexte
Um mit den quadratischen Kosten von Transformern umzugehen, haben Forschende neue Modellarchitekturen entwickelt, die die Verarbeitung langer Sequenzen günstiger und effizienter machen.
- State Space Models (SSMs) behalten durch Hidden States fester Größe eine lineare Rechenkomplexität und konstante Speicheranforderungen bei, wobei Modelle wie Mamba effiziente rekurrente Berechnungsmechanismen bieten, die effektiver skalieren als traditionelle Transformer.
- Dilated Attention Ansätze wie LongNet verwenden aufmerksamkeitsbasierte Felder, die mit zunehmender Token-Distanz exponentiell erweitert werden, und erreichen lineare Rechenkomplexität bei gleichzeitiger Beibehaltung logarithmischer Abhängigkeiten zwischen Tokens, wodurch es möglich wird, Sequenzen mit mehr als einer Milliarde Tokens zu verarbeiten.
- Toeplitz Neural Networks (TNNs) modellieren Sequenzen mit Toeplitz-Matrizen, die relative Positionen codieren, reduzieren die Raum-Zeit-Komplexität auf log-linear und ermöglichen die Extrapolation von 512 Trainings-Tokens auf 14.000 Inferenz-Tokens.
- Linear Attention Mechanismen reduzieren die Komplexität von O(N²) auf O(N), indem sie Self-Attention als lineare Skalarprodukte von Kernel-Feature-Maps ausdrücken, und erreichen bei der Verarbeitung sehr langer Sequenzen eine Beschleunigung von bis zu 4000×.
Alternative Ansätze wie Non-Attention-LLMs durchbrechen quadratische Barrieren, indem sie rekursive Memory Transformer und andere architektonische Innovationen einsetzen.
(2) Positionsinterpolation und Kontexterweiterung
Positionsinterpolationstechniken ermöglichen es Modellen, Sequenzen jenseits der ursprünglichen Begrenzungen des Kontextfensters zu verarbeiten, indem Positionsindizes intelligent neu skaliert werden, anstatt auf ungesehene Positionen zu extrapolieren.
- Neural-Tangent-Kernel-(NTK)-Ansätze bieten mathematisch fundierte Frameworks für die Kontexterweiterung, wobei YaRN (Yet another RoPE-based Interpolation method) NTK-Interpolation mit linearer Interpolation und Korrektur der Aufmerksamkeitsverteilung kombiniert.
- Zweistufige Ansätze: LongRoPE erreicht Kontextfenster von 2048K Token durch zweistufige Ansätze: zunächst die Feinabstimmung von Modellen auf eine Länge von 256K, anschließend die Durchführung positionaler Interpolation, um die maximale Kontextlänge zu erreichen.
- Position Sequence Tuning (PoSE) demonstriert beeindruckende Erweiterungen der Sequenzlänge auf bis zu 128K Token, indem mehrere Strategien der positionalen Interpolation kombiniert werden.
- Self-Extend-Techniken ermöglichen es LLMs, lange Kontexte ohne Feinabstimmung zu verarbeiten, indem sie zweistufige Aufmerksamkeitsstrategien einsetzen—gruppierte Aufmerksamkeit und Nachbarschaftsaufmerksamkeit—um Abhängigkeiten zwischen entfernten und benachbarten Token zu erfassen.
(3) Optimierungstechniken für effiziente Verarbeitung
Ohne die Kernarchitektur des Modells zu verändern, haben Forschende außerdem eine Reihe von Optimierungstechniken entwickelt, um die Verarbeitung langer Kontexte effizienter zu gestalten.
Grouped-Query Attention (GQA) unterteilt Query-Heads in Gruppen, die Key- und Value-Heads gemeinsam nutzen, und schafft so ein Gleichgewicht zwischen Multi-Query Attention und Multi-Head Attention, während die Speicheranforderungen während des Decodings reduziert werden.
FlashAttention nutzt die asymmetrische GPU-Speicherhierarchie, um eine lineare Speicherskalierung statt quadratischer Anforderungen zu erreichen, wobei FlashAttention-2 durch reduzierte Nicht-Matrixmultiplikationsoperationen und optimierte Arbeitsverteilung etwa die doppelte Geschwindigkeit bietet.
Ring Attention mit Blockwise Transformers ermöglicht die Verarbeitung extrem langer Sequenzen, indem die Berechnung über mehrere Geräte verteilt wird, wobei blockweise Berechnung genutzt und Kommunikation mit der Aufmerksamkeitsberechnung überlappt wird.
Sparse attention-Techniken umfassen Shifted sparse attention (S²-Attn) in LongLoRA und SinkLoRA mit SF-Attn, die 92 % der Perplexitätsverbesserung vollständiger Aufmerksamkeit bei erheblichen Recheneinsparungen erreichen.
Speicherverwaltung und Kontextkompression reduzieren die Kosten langer Eingaben. Rolling Buffer Cache begrenzt das Aufmerksamkeitsfenster, um den KV-Cache-Speicher zu verkleinern, während StreamingLLM lange Sequenzen unterstützt, indem nur Schlüssel-Token und der jüngste Kontext beibehalten werden. Andere Methoden wie Infini-attention und H2O verbessern die Effizienz durch kompressiven Speicher und intelligentere Cache-Verdrängung.
Kontextuelle Selbstverfeinerung und Anpassung
Selbstverfeinerung ermöglicht es LLMs, Ausgaben durch zyklische Feedbackmechanismen zu verbessern, die menschliche Überarbeitungsprozesse widerspiegeln, indem Selbstbewertung durch konversationelle Selbstinteraktion via Prompt Engineering genutzt wird, was sich von Reinforcement-Learning-Ansätzen unterscheidet.
Die Idee ist einfach: Bei komplexen Aufgaben ist es leichter, eine erste Version zu schreiben und sie anschließend zu korrigieren, als alles auf einmal richtig zu machen. Wenn Modelle lernen, ihre eigene Arbeit zu überprüfen und sie Schritt für Schritt zu verbessern, schneiden sie bei Schlussfolgern, Code schreiben und kreativen Aufgaben besser ab und passen sich leichter an neue Situationen an.
(1) Grundlegende Frameworks der Selbstverfeinerung
- Das Self-Refine-Framework verwendet dasselbe Modell als Generator, Feedbackgeber und Verfeinerer und zeigt, dass das Erkennen und Beheben von Fehlern oft einfacher ist als die Erstellung perfekter Ausgangslösungen.
- Reflexion hält reflektierenden Text in episodischen Speicherpuffern für zukünftige Entscheidungsfindung durch sprachliches Feedback fest, während strukturierte Anleitung sich als wesentlich erweist, da vereinfachtes Prompting häufig keine zuverlässige Selbstkorrektur ermöglicht.
- Das N-CRITICS-Framework implementiert ensemblebasierte Bewertung, bei der anfängliche Ausgaben sowohl von generierenden LLMs als auch von anderen Modellen bewertet werden, wobei zusammengeführtes Feedback die Verfeinerung leitet, bis aufgabenspezifische Stoppkriterien erfüllt sind.
(2) Meta-Learning und autonome Evolution
In einer fortgeschritteneren Phase konzentriert sich die Kontext-Selbstverfeinerung auf Meta-Lernen und autonome Verbesserung. Ziel ist es, dem Modell nicht nur dabei zu helfen, Aufgaben zu lösen, sondern auch zu lernen, wie es im Laufe der Zeit besser lernen kann.
SELF vermittelt LLMs Meta-Fähigkeiten (Selbst-Feedback, Selbstverfeinerung) anhand begrenzter Beispiele und lässt das Modell sich anschließend kontinuierlich selbst weiterentwickeln, indem es eigene Trainingsdaten generiert und filtert. Selbstbelohnungsmechanismen ermöglichen es Modellen, sich durch iterative Selbstbeurteilung autonom zu verbessern, wobei ein einzelnes Modell Doppelrollen als Ausführender und Richter übernimmt und die Belohnungen maximiert, die es sich selbst zuweist.
Das Creator Framework erweitert dieses Paradigma, indem es LLMs ermöglicht, durch einen Vier-Modul-Prozess, der Erstellung, Entscheidungsfindung, Ausführung und Erkennung umfasst, eigene Tools zu erstellen und zu nutzen.
Das Self-Developing Framework stellt den autonomsten Ansatz dar, indem es LLMs ermöglicht, durch iterative Zyklen ihre eigenen Verbesserungsalgorithmen zu entdecken, zu implementieren und zu verfeinern, wobei algorithmische Kandidaten als ausführbarer Code generiert werden.
Multimodaler Kontext
Multimodale große Sprachmodelle (MLLMs) gehen über Text hinaus, indem sie mit Eingaben wie Bildern, Audio und 3D-Daten arbeiten. Sie kombinieren diese verschiedenen Informationstypen zu einem einzigen Kontext, über den das Modell schlussfolgern kann.
Dadurch werden fortgeschrittenere Anwendungen möglich, zugleich entstehen jedoch auch neue Herausforderungen, etwa die Integration verschiedener Modalitäten, das Schlussfolgern über sie hinweg und der Umgang mit langen, komplexen Eingaben.
(1) Multimodale Kontextintegration
Kontextintegration ist der Kern der multimodalen Kontextverarbeitung. Sie zielt darauf ab, Informationen aus verschiedenen Modalitäten, wie Bildern, Text und Audio, zu einer einzigen Repräsentation zu kombinieren, mit der ein Modell schlussfolgern kann.
Ein grundlegender Ansatz wandelt Bilder mithilfe von Encodern wie CLIP in Tokens um und hängt sie anschließend an Text-Tokens an, bevor alles an das Sprachmodell gesendet wird. Dies ist einfach zu implementieren, doch die verschiedenen Modalitäten bleiben häufig nur lose verbunden.
Fortgeschrittenere Methoden verbessern die Integration. Cross-modale Aufmerksamkeit ermöglicht es dem Modell, direkte Beziehungen zwischen visuellen und Text-Tokens innerhalb des Modells zu lernen, was für Aufgaben wie Bildbearbeitung und visuelles Schlussfolgern wichtig ist.
Um auf lange oder komplexe Eingaben zu skalieren, verarbeiten hierarchische Designs jede Modalität in Stufen. Einige Systeme führen außerdem Informationen aus mehreren Bildern oder Eingaben zusammen, bevor sie an das Modell weitergegeben werden, anstatt jede einzeln zu behandeln.
Andere Arbeiten vermeiden es ganz, reine Textmodelle anzupassen, indem sie von Anfang an gemeinsam auf multimodalen Daten und Text trainieren. Cross-modales Schlussfolgern baut darauf auf und erfordert, dass das Modell nicht nur jede Modalität für sich versteht, sondern auch die Bedeutung, die entsteht, wenn sie kombiniert werden, etwa Sarkasmus, der sowohl durch ein Bild als auch durch Text ausgedrückt wird.
(2) Externe multimodale Encoder und Alignment-Module
Multimodale Kontextintegration beruht auf zwei Hauptbestandteilen: externen multimodalen Encodern und den Alignment-Modulen , die sie mit dem Sprachmodell verbinden.
In den meisten aktuellen Systemen wird jeder Datentyp von einem dedizierten Encoder verarbeitet. Beispielsweise werden Bilder von Modellen wie CLIP verarbeitet, und Audio wird von Modellen wie CLAP behandelt. Diese Encoder wandeln Rohdaten, wie Pixel oder Schallwellen, in Merkmalsvektoren um.
Alignment-Module konvertieren diese Merkmale anschließend in den Einbettungsraum des Sprachmodells, sodass sie zusammen mit Text-Tokens funktionieren können. Einige Systeme verwenden einfache Abbildungen wie MLPs, während andere Q-Former nutzen, der mithilfe lernbarer Query-Tokens die für den Text relevantesten visuellen Merkmale auswählt.
Dieser modulare Aufbau macht Systeme leichter wartbar. Encoder können aktualisiert oder ausgetauscht werden, ohne das gesamte Sprachmodell neu zu trainieren, was für den Einsatz in der realen Welt wichtig ist.
Relationaler und strukturierter Kontext
Große Sprachmodelle stoßen aufgrund textbasierter Eingabeanforderungen und Einschränkungen der sequenziellen Architektur auf grundlegende Beschränkungen bei der Verarbeitung relationaler und strukturierter Daten, einschließlich Tabellen, Datenbanken und Wissensgraphen.
Linearisierung gelingt es oft nicht, komplexe Beziehungen und strukturelle Eigenschaften zu bewahren, wobei die Leistung abnimmt, wenn Informationen über Kontexte hinweg verstreut sind.
Um dieses Problem zu lösen, haben Forschende nach Möglichkeiten gesucht, strukturierte Daten in einer Form darzustellen, die Sprachmodelle nutzen können. Ziel ist es, Modellen zu helfen, bei Aufgaben, die komplexes Schlussfolgern und Faktenprüfung erfordern, bessere Leistungen zu erzielen.
(1) Knowledge-Graph-Embeddings und neuronale Integration
Fortgeschrittene Kodierungsstrategien adressieren strukturelle Einschränkungen durch Knowledge-Graph-Embeddings, die Entitäten und Beziehungen in numerische Vektoren umwandeln und so eine effiziente Verarbeitung innerhalb von Sprachmodellarchitekturen ermöglichen.
Graph Neural Networks erfassen komplexe Beziehungen zwischen Entitäten und erleichtern Multi-Hop-Schlussfolgern über Knowledge-Graph-Strukturen hinweg durch spezialisierte Architekturen wie GraphFormers, die GNN-Komponenten neben Transformer-Blöcken einbetten.
(2) Verbalisierung
Ein gängiger Ansatz besteht darin, strukturierte Daten – wie Knowledge Graphs, Tabellen oder Datenbankeinträge – in natürlichsprachlichen Text umzuwandeln, sodass sie direkt von bestehenden Sprachmodellen genutzt werden können, ohne deren Architektur zu verändern. Andere Methoden reorganisieren Eingabetext auf Grundlage linguistischer Beziehungen in strukturierte Schichten oder extrahieren Schlüsselinformationen und stellen sie explizit als Graphen, Tabellen oder relationale Schemata dar.
In manchen Fällen funktioniert die Darstellung strukturierter Daten mithilfe von Programmiersprachen besser als natürliche Sprache. Beispielsweise führt die Verwendung von Python-Code für Knowledge Graphs oder SQL für Datenbanken oft zu einer stärkeren Leistung bei komplexen Schlussfolgerungsaufgaben, weil diese Formate Struktur klarer bewahren. Es gibt auch ressourceneffiziente Ansätze, die kompakte Matrixdarstellungen verwenden, um strukturierte Daten mit weniger Parametern zu verarbeiten und dabei eine gute Leistung beizubehalten.
(3) Hybride Architekturen
Um strukturierte Daten mit komplexen Beziehungen zu verarbeiten, etwa Tabellen und Knowledge Graphs, haben Forschende hybride Architekturen untersucht, die große Sprachmodelle mit Komponenten kombinieren, die für graphstrukturierte Daten entwickelt wurden, wie etwa Graph Neural Networks.
Es werden mehrere praktische Ansätze verwendet. GraphToken macht Beziehungen explizit, indem spezielle Tokens hinzugefügt werden, was Modellen hilft, über Graphen zu schlussfolgern. Heterformer verarbeitet Text und Graphstruktur gemeinsam in einem Framework, wobei Beziehungsinformationen erhalten bleiben und zugleich die Rechenkosten kontrolliert werden.
Andere Methoden integrieren Wissen auf unterschiedliche Weise. K-BERT fügt während des Trainings Knowledge-Graph-Informationen hinzu, sodass das Modell diese Beziehungen im Voraus lernt. KAPING ruft relevantes Wissen zur Inferenzzeit ab, ohne erneutes Training. Fortgeschrittenere Designs verwenden Adapter und Attention, um Graphinformationen direkt in das Modell einzubinden, was zu einer engeren Integration führt.
Fazit
Context Engineering bietet eine nützliche Möglichkeit zu verstehen, wie LLM-Systeme in der Produktion funktionieren. Im Allgemeinen umfasst es drei Hauptprozesse: Kontextabruf und -generierung, Kontextverarbeitung und Kontextmanagement. Zusammen bestimmen diese Schritte, wie Informationen gesammelt, vorbereitet und an das Modell weitergegeben werden.
Unter ihnen ist Kontextverarbeitung besonders wichtig, weil sie entscheidet, wie abgerufene Informationen bereinigt, organisiert und komprimiert werden, bevor sie das Modell erreichen. Aufgrund von Platzbeschränkungen konzentrierte sich dieser Artikel hauptsächlich auf diesen Teil und überprüfte mehrere Ansätze, die in realen Systemen verwendet werden. Abruf und Kontextmanagement sind ebenfalls wichtige Bereiche und können in zukünftigen Diskussionen weiter untersucht werden.
Wenn Sie RAG- oder Agentensysteme entwickeln und in der Produktion auf Probleme mit Kontext, Kosten oder Latenz stoßen, treten Sie unserem Slack Channel bei, um Context Engineering mit anderen Engineers zu diskutieren. Sie können auch eine kurze persönliche Sitzung buchen, um über die Milvus Office Hours praktische Anleitung für den Übergang von Demos zu produktionsreifen Systemen zu erhalten.
Weiterlesen

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.