




So wählen Sie 2026 das beste Embedding-Modell für RAG aus: 10 Modelle im Benchmark
TL;DR: Wir haben 10 Embedding-Modelle in vier Produktionsszenarien getestet, die öffentliche Benchmarks nicht abdecken: cross-modale Retrieval, cross-linguale Retrieval, Retrieval von Schlüsselinformationen und Dimensionskompression. Kein einzelnes Modell gewinnt überall. Gemini Embedding 2 ist der beste Allrounder. Open-Source Qwen3-VL-2B schlägt Closed-Source-APIs bei cross-modalen Aufgaben. Wenn Sie Dimensionen komprimieren müssen, um Speicherplatz zu sparen, wählen Sie Voyage Multimodal 3.5 oder Jina Embeddings v4.
Warum MTEB für die Auswahl eines Embedding-Modells nicht ausreicht
Die meisten RAG-Prototypen beginnen mit OpenAIs text-embedding-3-small. Es ist günstig, einfach zu integrieren und funktioniert für englisches Text-Retrieval gut genug. Aber Produktions-RAG wächst schnell darüber hinaus. Ihre Pipeline verarbeitet Bilder, PDFs, mehrsprachige Dokumente — und ein reines Text-Embedding-Modell reicht dann nicht mehr aus.
Das MTEB-Leaderboard zeigt Ihnen, dass es bessere Optionen gibt. Das Problem? MTEB testet nur einsprachiges Text-Retrieval. Es deckt kein cross-modales Retrieval ab (Textabfragen gegen Bildsammlungen), keine cross-linguale Suche (eine chinesische Abfrage findet ein englisches Dokument), keine Genauigkeit bei langen Dokumenten und auch nicht, wie viel Qualität verloren geht, wenn man Embedding-Dimensionen kürzt, um Speicherplatz in Ihrer Vektordatenbank zu sparen.
Welches Embedding-Modell sollten Sie also verwenden? Das hängt von Ihren Datentypen, Ihren Sprachen, Ihren Dokumentlängen und davon ab, ob Sie Dimensionskompression benötigen. Wir haben einen Benchmark namens CCKM entwickelt und 10 Modelle getestet, die zwischen 2025 und 2026 veröffentlicht wurden, und zwar genau entlang dieser Dimensionen.
Was ist der CCKM-Benchmark?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) testet vier Fähigkeiten, die Standard-Benchmarks übersehen:
| Dimension | Was getestet wird | Warum es wichtig ist |
|---|---|---|
| Cross-modales Retrieval | Textbeschreibungen dem richtigen Bild zuordnen, wenn nahezu identische Ablenkungen vorhanden sind | Multimodal RAG-Pipelines benötigen Text- und Bild-Embeddings im selben Vektorraum |
| Cross-linguales Retrieval | Das richtige englische Dokument anhand einer chinesischen Abfrage finden und umgekehrt | Produktions-Wissensdatenbanken sind häufig mehrsprachig |
| Retrieval von Schlüsselinformationen | Eine bestimmte Tatsache finden, die in einem Dokument mit 4K–32K Zeichen verborgen ist (Nadel im Heuhaufen) | RAG-Systeme verarbeiten häufig lange Dokumente wie Verträge und Forschungsarbeiten |
| MRL-Dimensionskompression | Messen, wie viel Qualität das Modell verliert, wenn Embeddings auf 256 Dimensionen gekürzt werden | Weniger Dimensionen = geringere Speicherkosten in Ihrer Vektordatenbank, aber zu welchem Qualitätsverlust? |
MTEB deckt nichts davon ab. MMEB ergänzt Multimodalität, lässt aber schwierige Negativbeispiele aus, sodass Modelle hohe Werte erzielen, ohne zu beweisen, dass sie subtile Unterschiede beherrschen. CCKM wurde entwickelt, um das abzudecken, was ihnen fehlt.
Welche Embedding-Modelle haben wir getestet? Gemini Embedding 2, Jina Embeddings v4 und mehr
Wir haben 10 Modelle getestet, die sowohl API-Dienste als auch Open-Source-Optionen abdecken, plus CLIP ViT-L-14 als Baseline von 2021.
| Modell | Quelle | Parameter | Dimensionen | Modalität | Haupteigenschaft |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Nicht offengelegt | 3072 | Text / Bild / Video / Audio / PDF | Alle Modalitäten, breiteste Abdeckung | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Text / Bild / PDF | MRL + LoRA-Adapter |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Nicht offengelegt | 1024 | Text / Bild / Video | Ausgewogen über Aufgaben hinweg |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Text / Bild / Video | Open Source, leichtgewichtig multimodal |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Text / Bild | Modernisierte CLIP-Architektur |
| Cohere Embed v4 | Cohere | Nicht offengelegt | Fest | Text | Enterprise-Retrieval |
| OpenAI text-embedding-3-large | OpenAI | Nicht offengelegt | 3072 | Text | Am weitesten verbreitet |
| BGE-M3 | BAAI | 568M | 1024 | Text | Open Source, 100+ Sprachen |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Text | Leichtgewichtig, auf Englisch fokussiert |
| nomic-embed-text | Nomic AI | 137M | 768 | Text | Ultraleichtgewichtig |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Text / Bild | Baseline |
Cross-Modal Retrieval: Welche Modelle beherrschen Text-zu-Bild-Suche?
Wenn Ihre RAG-Pipeline Bilder neben Text verarbeitet, muss das Embedding-Modell beide Modalitäten im selben Vektorraum platzieren. Denken Sie an E-Commerce-Bildsuche, gemischte Bild-Text-Wissensdatenbanken oder jedes System, bei dem eine Textanfrage das richtige Bild finden muss.
Methode
Wir haben 200 Bild-Text-Paare aus COCO val2017 genommen. Für jedes Bild erzeugte GPT-4o-mini eine detaillierte Beschreibung. Dann schrieben wir 3 harte Negative pro Bild — Beschreibungen, die sich nur in ein oder zwei Details von der korrekten unterscheiden. Das Modell muss die richtige Übereinstimmung in einem Pool aus 200 Bildern und 600 Ablenkern finden.
Ein Beispiel aus dem Datensatz:
 Vintage braune Lederkoffer mit Reiseaufklebern einschließlich California und Cuba, auf einem Metall-Gepäckträger vor blauem Himmel platziert — verwendet als Testbild im Cross-Modal-Retrieval-Benchmark
Vintage braune Lederkoffer mit Reiseaufklebern einschließlich California und Cuba, auf einem Metall-Gepäckträger vor blauem Himmel platziert — verwendet als Testbild im Cross-Modal-Retrieval-Benchmark
Korrekte Beschreibung: "Das Bild zeigt vintage braune Lederkoffer mit verschiedenen Reiseaufklebern, darunter 'California', 'Cuba' und 'New York', die auf einem Metall-Gepäckträger vor einem klaren blauen Himmel platziert sind."
Hartes Negativ: Derselbe Satz, aber "California" wird zu "Florida" und "blauer Himmel" wird zu "bewölkter Himmel." Das Modell muss die Bilddetails tatsächlich verstehen, um diese zu unterscheiden.
Bewertung:
- Embeddings für alle Bilder und alle Texte erzeugen (200 korrekte Beschreibungen + 600 harte Negative).
- Text-zu-Bild (t2i): Jede Beschreibung durchsucht 200 Bilder nach der nächsten Übereinstimmung. Es gibt einen Punkt, wenn das Top-Ergebnis korrekt ist.
- Bild-zu-Text (i2t): Jedes Bild durchsucht alle 800 Texte nach der nächsten Übereinstimmung. Es gibt nur dann einen Punkt, wenn das Top-Ergebnis die korrekte Beschreibung ist, nicht ein hartes Negativ.
- Endergebnis: hard_avg_R@1 = (t2i accuracy + i2t accuracy) / 2
Ergebnisse
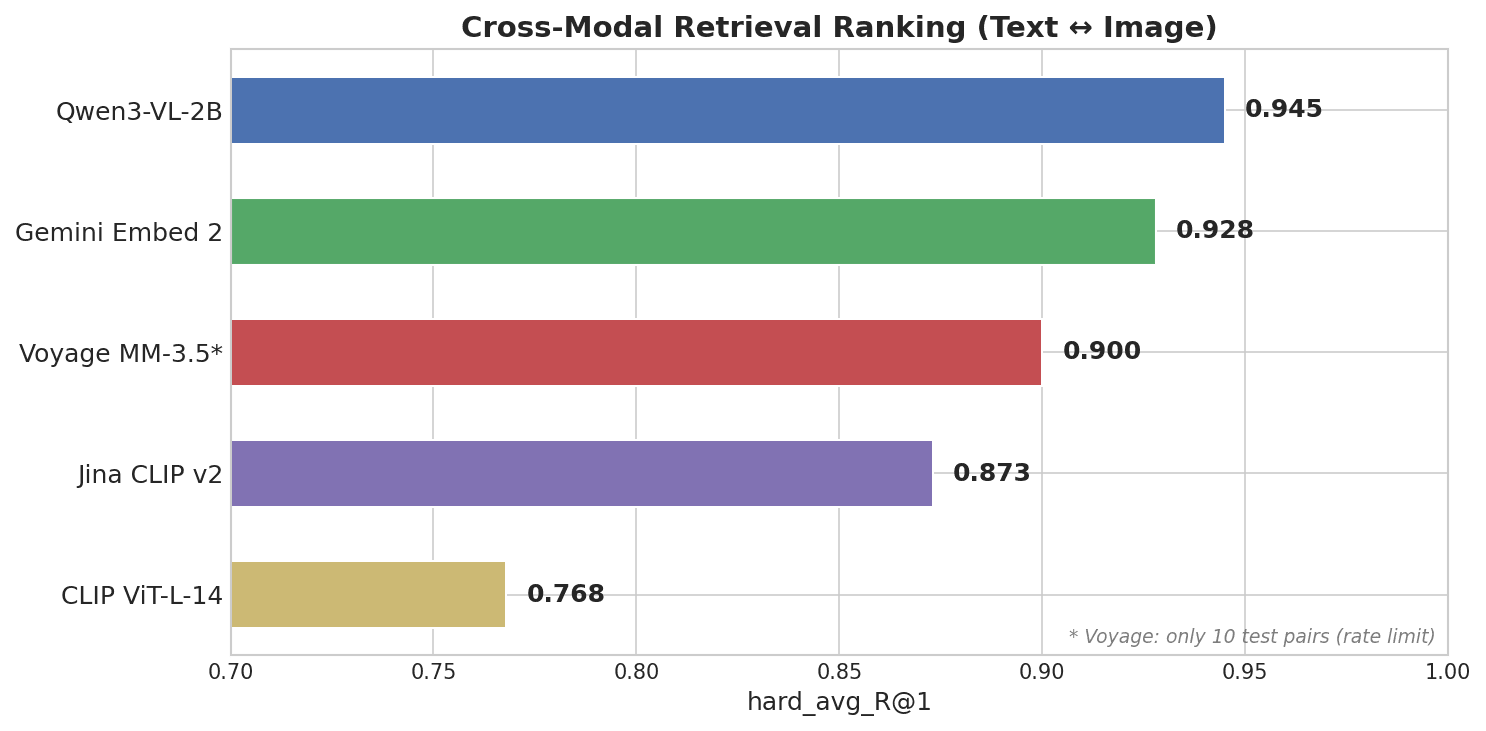 Horizontales Balkendiagramm, das das Cross-Modal-Retrieval-Ranking zeigt: Qwen3-VL-2B führt mit 0.945, gefolgt von Gemini Embed 2 mit 0.928, Voyage MM-3.5 mit 0.900, Jina CLIP v2 mit 0.873 und CLIP ViT-L-14 mit 0.768
Horizontales Balkendiagramm, das das Cross-Modal-Retrieval-Ranking zeigt: Qwen3-VL-2B führt mit 0.945, gefolgt von Gemini Embed 2 mit 0.928, Voyage MM-3.5 mit 0.900, Jina CLIP v2 mit 0.873 und CLIP ViT-L-14 mit 0.768
Qwen3-VL-2B, ein Open-Source-Modell mit 2B Parametern vom Qwen-Team von Alibaba, landete auf dem ersten Platz — vor jeder Closed-Source-API.
Modalitätslücke erklärt den größten Teil des Unterschieds. Embedding-Modelle bilden Text und Bilder in denselben Vektorraum ab, aber in der Praxis neigen die beiden Modalitäten dazu, sich in unterschiedlichen Regionen zu clustern. Die Modalitätslücke misst die L2-Distanz zwischen diesen beiden Clustern. Kleinere Lücke = einfacheres Cross-Modal Retrieval.
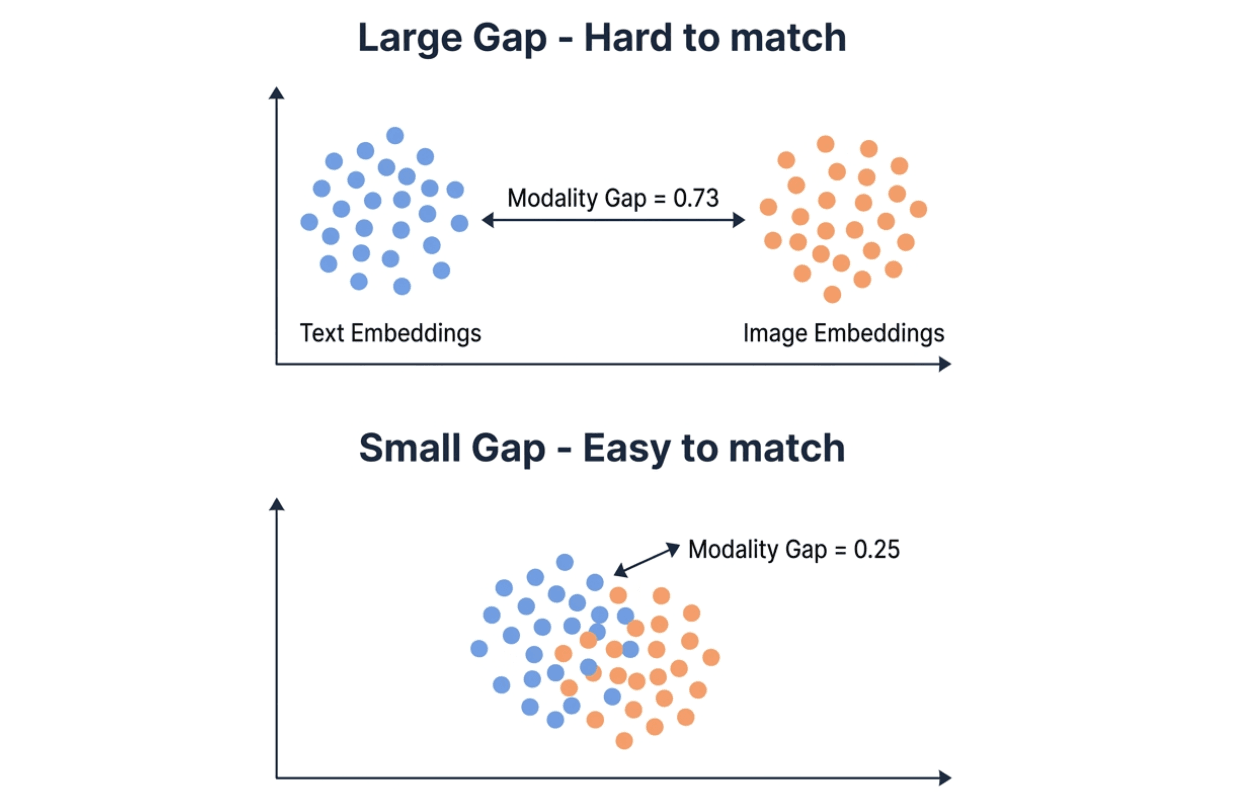 Visualisierung des Vergleichs zwischen großer Modalitätslücke (0,73, Text- und Bild-Embedding-Cluster weit voneinander entfernt) und kleiner Modalitätslücke (0,25, Cluster überlappen) — eine kleinere Lücke erleichtert das Cross-Modal Matching
Visualisierung des Vergleichs zwischen großer Modalitätslücke (0,73, Text- und Bild-Embedding-Cluster weit voneinander entfernt) und kleiner Modalitätslücke (0,25, Cluster überlappen) — eine kleinere Lücke erleichtert das Cross-Modal Matching
| Modell | Score (R@1) | Modalitätslücke | Parameter |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Unbekannt (geschlossen) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Unbekannt (geschlossen) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Qwens Modalitätslücke beträgt 0,25 — ungefähr ein Drittel von Geminis 0,73. In einer Vektordatenbank wie Milvus bedeutet eine kleine Modalitätslücke, dass Sie Text- und Bild-Embeddings in derselben Collection speichern und beide direkt übergreifend durchsuchen können. Eine große Lücke kann die cross-modale Ähnlichkeitssuche weniger zuverlässig machen, und Sie benötigen möglicherweise einen Re-Ranking-Schritt, um dies auszugleichen.
Cross-Lingual Retrieval: Welche Modelle richten Bedeutung sprachübergreifend aus?
Mehrsprachige Wissensdatenbanken sind in der Produktion üblich. Ein Nutzer stellt eine Frage auf Chinesisch, aber die Antwort befindet sich in einem englischen Dokument — oder umgekehrt. Das Embedding-Modell muss Bedeutung über Sprachen hinweg ausrichten, nicht nur innerhalb einer Sprache.
Methode
Wir haben 166 parallele Satzpaare auf Chinesisch und Englisch über drei Schwierigkeitsstufen hinweg erstellt:
 Cross-linguale Schwierigkeitsstufen: Die einfache Stufe ordnet wörtliche Übersetzungen wie 我爱你 I love you zu; die mittlere Stufe ordnet paraphrasierte Sätze wie 这道菜太咸了 This dish is too salty mit schwierigen Negativbeispielen zu; die schwierige Stufe ordnet chinesische Redewendungen wie 画蛇添足 gilding the lily mit semantisch unterschiedlichen schwierigen Negativbeispielen zu
Cross-linguale Schwierigkeitsstufen: Die einfache Stufe ordnet wörtliche Übersetzungen wie 我爱你 I love you zu; die mittlere Stufe ordnet paraphrasierte Sätze wie 这道菜太咸了 This dish is too salty mit schwierigen Negativbeispielen zu; die schwierige Stufe ordnet chinesische Redewendungen wie 画蛇添足 gilding the lily mit semantisch unterschiedlichen schwierigen Negativbeispielen zu
Jede Sprache erhält außerdem 152 schwierige negative Ablenker.
Bewertung:
- Embeddings für alle chinesischen Texte (166 korrekte + 152 Ablenker) und alle englischen Texte (166 korrekte + 152 Ablenker) generieren.
- Chinesisch → Englisch: Jeder chinesische Satz durchsucht 318 englische Texte nach seiner korrekten Übersetzung.
- Englisch → Chinesisch: Dasselbe in umgekehrter Richtung.
- Endergebnis: hard_avg_R@1 = (zh→en-Genauigkeit + en→zh-Genauigkeit) / 2
Ergebnisse
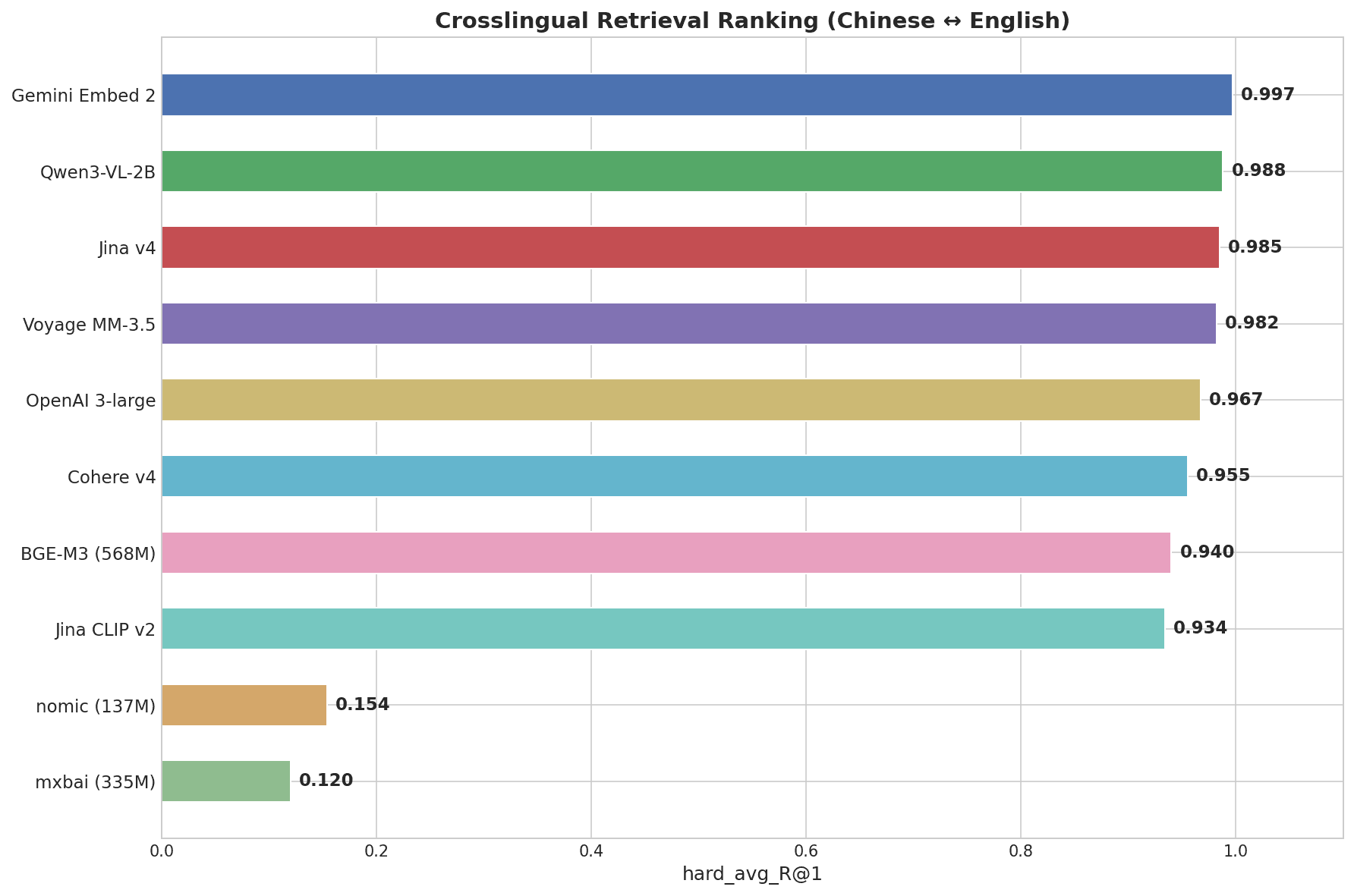 Horizontales Balkendiagramm mit Cross-Lingual Retrieval Ranking: Gemini Embed 2 führt mit 0,997, gefolgt von Qwen3-VL-2B mit 0,988, Jina v4 mit 0,985, Voyage MM-3.5 mit 0,982, bis hinunter zu mxbai mit 0,120
Horizontales Balkendiagramm mit Cross-Lingual Retrieval Ranking: Gemini Embed 2 führt mit 0,997, gefolgt von Qwen3-VL-2B mit 0,988, Jina v4 mit 0,985, Voyage MM-3.5 mit 0,982, bis hinunter zu mxbai mit 0,120
Gemini Embedding 2 erzielte 0,997 — den höchsten Wert aller getesteten Modelle. Es war das einzige Modell, das auf der Hard-Stufe eine perfekte 1,000 erreichte, bei der Paare wie „画蛇添足“ → „gilding the lily“ echtes semantisches Verständnis über Sprachen hinweg erfordern, nicht Musterabgleich.
| Modell | Score (R@1) | Leicht | Mittel | Schwer (Redewendungen) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
Die Top-7-Modelle überschreiten beim Gesamtscore alle 0,93 — die eigentliche Differenzierung zeigt sich auf der Hard-Stufe (chinesische Redewendungen). nomic-embed-text und mxbai-embed-large, beides englischfokussierte leichtgewichtige Modelle, erzielen bei cross-lingualen Aufgaben nahezu null Punkte.
Key Information Retrieval: Können Modelle die Nadel in einem 32K-Token-Dokument finden?
RAG-Systeme verarbeiten häufig lange Dokumente — juristische Verträge, Forschungsarbeiten, interne Berichte mit unstrukturierten Daten. Die Frage ist, ob ein Embedding-Modell dennoch eine bestimmte Tatsache finden kann, die in Tausenden von Zeichen umgebenden Texts verborgen ist.
Methode
Wir nahmen Wikipedia-Artikel unterschiedlicher Länge (4K bis 32K Zeichen) als Heuhaufen und fügten eine einzelne erfundene Tatsache — die Nadel — an verschiedenen Positionen ein: Anfang, 25%, 50%, 75% und Ende. Das Modell muss anhand eines Query-Embeddings bestimmen, welche Version des Dokuments die Nadel enthält.
Beispiel:
- Nadel: "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- Abfrage: "What was Meridian Corporation's quarterly revenue?"
- Heuhaufen: Ein Wikipedia-Artikel mit 32.000 Zeichen über Photosynthese, in dem die Nadel irgendwo verborgen ist.
Bewertung:
- Embeddings für die Abfrage, das Dokument mit der Nadel und das Dokument ohne Nadel generieren.
- Wenn die Abfrage dem Dokument mit der Nadel ähnlicher ist, wird dies als Treffer gezählt.
- Durchschnittliche Genauigkeit über alle Dokumentlängen und Nadelpositionen hinweg.
- Endmetriken: overall_accuracy und degradation_rate (wie stark die Genauigkeit vom kürzesten zum längsten Dokument abnimmt).
Ergebnisse
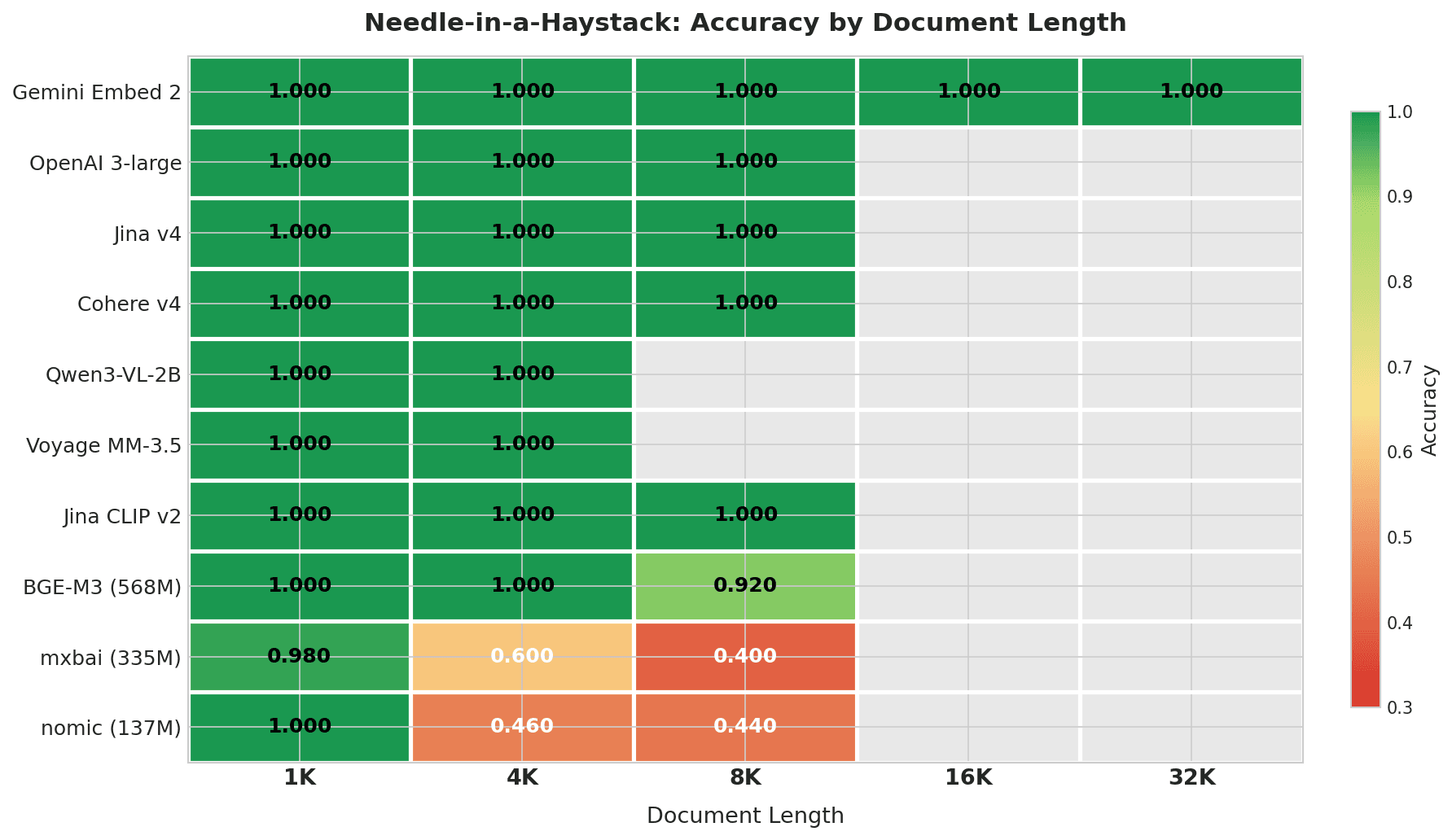 Heatmap, die die Needle-in-a-Haystack-Genauigkeit nach Dokumentlänge zeigt: Gemini Embed 2 erzielt 1.000 über alle Längen bis 32K; die Top-7-Modelle erzielen innerhalb ihrer Kontextfenster perfekte Werte; mxbai und nomic verschlechtern sich stark ab 4K+
Heatmap, die die Needle-in-a-Haystack-Genauigkeit nach Dokumentlänge zeigt: Gemini Embed 2 erzielt 1.000 über alle Längen bis 32K; die Top-7-Modelle erzielen innerhalb ihrer Kontextfenster perfekte Werte; mxbai und nomic verschlechtern sich stark ab 4K+
Gemini Embedding 2 ist das einzige Modell, das über den gesamten Bereich von 4K–32K getestet wurde, und es erzielte bei jeder Länge perfekte Werte. Kein anderes Modell in diesem Test hat ein Kontextfenster, das 32K erreicht.
| Modell | 1K | 4K | 8K | 16K | 32K | Gesamt | Verschlechterung |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" bedeutet, dass die Dokumentlänge das Kontextfenster des Modells überschreitet.
Die Top-7-Modelle erzielen innerhalb ihrer Kontextfenster perfekte Werte. BGE-M3 beginnt bei 8K nachzulassen (0.920). Die leichtgewichtigen Modelle (mxbai und nomic) fallen bereits bei 4K Zeichen — ungefähr 1.000 Tokens — auf 0.4–0.6 ab. Bei mxbai spiegelt dieser Rückgang teilweise wider, dass sein Kontextfenster von 512 Tokens den Großteil des Dokuments abschneidet.
MRL-Dimensionskompression: Wie viel Qualität verliert man bei 256 Dimensionen?
Matryoshka Representation Learning (MRL) ist eine Trainingstechnik, die die ersten N Dimensionen eines Vektors für sich genommen aussagekräftig macht. Nimmt man einen 3072-dimensionalen Vektor, kürzt ihn auf 256, behält er dennoch den Großteil seiner semantischen Qualität. Weniger Dimensionen bedeuten geringere Speicher- und Arbeitsspeicherkosten in Ihrer Vektordatenbank — der Wechsel von 3072 auf 256 Dimensionen entspricht einer 12-fachen Speicherreduktion.
 Illustration, die MRL-Dimensionstrunkierung zeigt: 3072 Dimensionen bei voller Qualität, 1024 bei 95%, 512 bei 90%, 256 bei 85% — mit 12-fachen Speichereinsparungen bei 256 Dimensionen
Illustration, die MRL-Dimensionstrunkierung zeigt: 3072 Dimensionen bei voller Qualität, 1024 bei 95%, 512 bei 90%, 256 bei 85% — mit 12-fachen Speichereinsparungen bei 256 Dimensionen
Methode
Wir verwendeten 150 Satzpaare aus dem STS-B-Benchmark, jeweils mit einer von Menschen annotierten Ähnlichkeitsbewertung (0–5). Für jedes Modell erzeugten wir Embeddings mit voller Dimensionszahl und kürzten sie anschließend auf 1024, 512 und 256.
 STS-B-Datenbeispiele mit Satzpaaren und menschlichen Ähnlichkeitswerten: Ein Mädchen stylt ihr Haar vs. Ein Mädchen bürstet ihr Haar erhält 2,5; Eine Gruppe von Männern spielt Fußball am Strand vs. Eine Gruppe von Jungen spielt Fußball am Strand erhält 3,6
STS-B-Datenbeispiele mit Satzpaaren und menschlichen Ähnlichkeitswerten: Ein Mädchen stylt ihr Haar vs. Ein Mädchen bürstet ihr Haar erhält 2,5; Eine Gruppe von Männern spielt Fußball am Strand vs. Eine Gruppe von Jungen spielt Fußball am Strand erhält 3,6
Bewertung:
- Berechne auf jeder Dimensionsebene die Kosinus-Ähnlichkeit zwischen den Embeddings jedes Satzpaars.
- Vergleiche das Ähnlichkeitsranking des Modells mit dem menschlichen Ranking unter Verwendung von Spearman's ρ (Rangkorrelation).
Was ist Spearman's ρ? Es misst, wie gut zwei Rankings übereinstimmen. Wenn Menschen Paar A als am ähnlichsten, B als zweites und C als am wenigsten ähnlich einstufen — und die Kosinus-Ähnlichkeiten des Modells dieselbe Reihenfolge A > B > C ergeben — dann nähert sich ρ dem Wert 1,0. Ein ρ von 1,0 bedeutet perfekte Übereinstimmung. Ein ρ von 0 bedeutet keine Korrelation.
Endmetriken: spearman_rho (höher ist besser) und min_viable_dim (die kleinste Dimension, bei der die Qualität innerhalb von 5 % der Leistung mit voller Dimension bleibt).
Ergebnisse
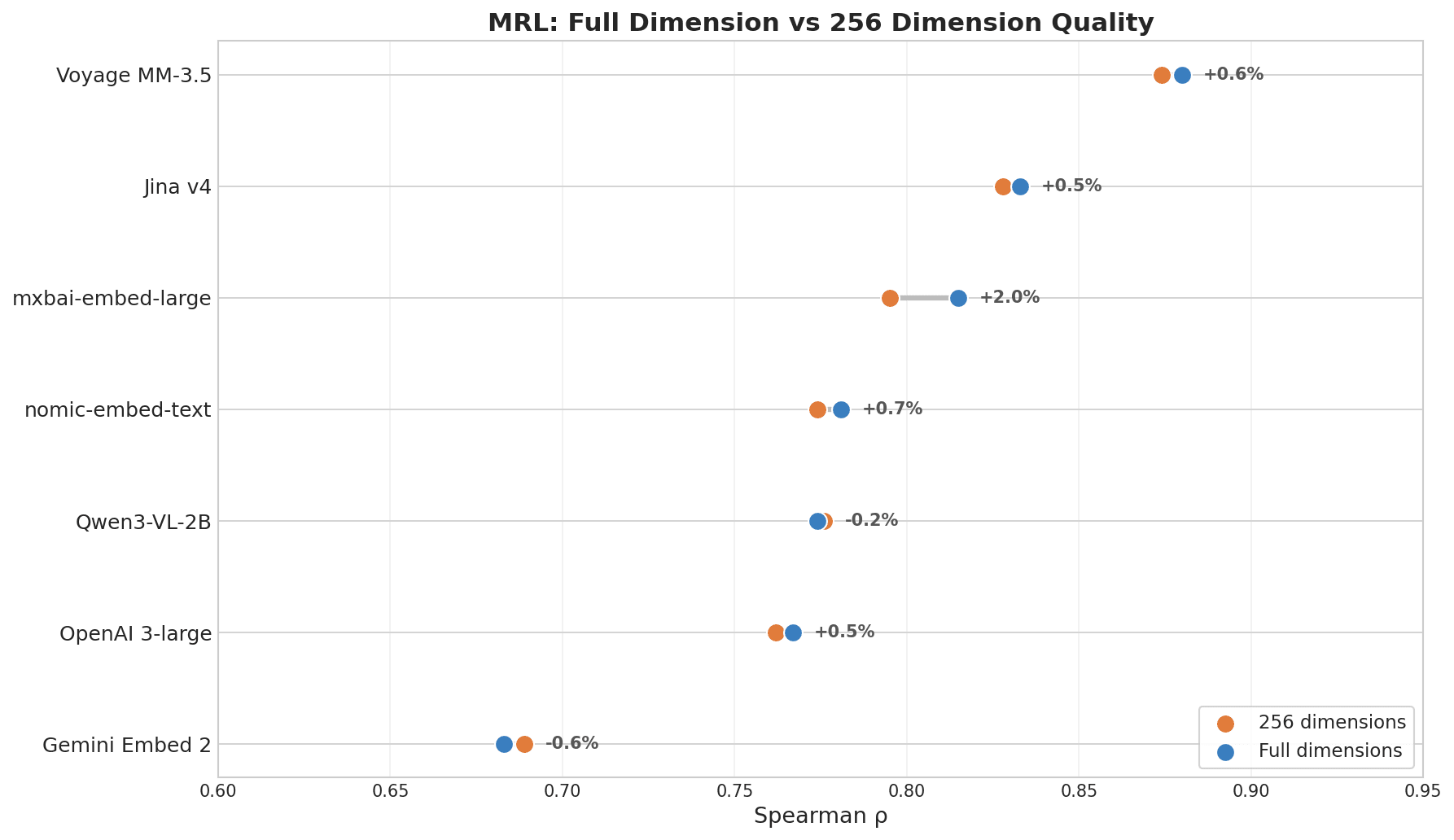 Punktdiagramm, das MRL-Qualität bei voller Dimension vs. 256 Dimensionen zeigt: Voyage MM-3.5 führt mit +0,6 % Veränderung, Jina v4 +0,5 %, während Gemini Embed 2 mit -0,6 % unten liegt
Punktdiagramm, das MRL-Qualität bei voller Dimension vs. 256 Dimensionen zeigt: Voyage MM-3.5 führt mit +0,6 % Veränderung, Jina v4 +0,5 %, während Gemini Embed 2 mit -0,6 % unten liegt
Wenn du planst, Speicherkosten in Milvus oder einer anderen Vektordatenbank durch das Abschneiden von Dimensionen zu senken, ist dieses Ergebnis wichtig.
| Modell | ρ (volle Dim.) | ρ (256 Dim.) | Abnahme |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage und Jina v4 führen, weil beide explizit mit MRL als Ziel trainiert wurden. Dimensionskompression hat wenig mit der Modellgröße zu tun — entscheidend ist, ob das Modell dafür trainiert wurde.
Ein Hinweis zu Geminis Wert: Das MRL-Ranking zeigt, wie gut ein Modell die Qualität nach dem Abschneiden beibehält, nicht wie gut sein Retrieval bei voller Dimension ist. Geminis Retrieval bei voller Dimension ist stark — die Ergebnisse zu Cross-Lingualität und Schlüsselinformationen haben das bereits bewiesen. Es wurde nur nicht für das Verkleinern optimiert. Wenn du keine Dimensionskompression brauchst, trifft diese Metrik nicht auf dich zu.
Welches Embedding-Modell solltest du verwenden?
Kein einzelnes Modell gewinnt in allem. Hier ist die vollständige Scorecard:
| Modell | Parameter | Cross-Modal | Cross-Lingual | Schlüsselinformationen | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Nicht offengelegt | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Nicht offengelegt | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Nicht offengelegt | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Nicht offengelegt | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" bedeutet, dass das Modell diese Modalität oder Fähigkeit nicht unterstützt. CLIP ist eine 2021-Baseline als Referenz.
Folgendes fällt auf:
- Modalitätsübergreifend: Qwen3-VL-2B (0.945) liegt vorn, Gemini (0.928) auf Platz zwei, Voyage (0.900) auf Platz drei. Ein Open-Source-2B-Modell schlug jede Closed-Source-API. Der entscheidende Faktor war die Modalitätslücke, nicht die Parameteranzahl.
- Sprachübergreifend: Gemini (0.997) führt — das einzige Modell, das bei der Ausrichtung auf Idiom-Ebene perfekt abschneidet. Die Top-8-Modelle überschreiten alle 0.93. Leichtgewichtige Modelle nur für Englisch liegen nahe null.
- Schlüsselinformationen: API- und große Open-Source-Modelle erzielen bis 8K perfekte Ergebnisse. Modelle unter 335M beginnen bei 4K nachzulassen. Gemini ist das einzige Modell, das 32K mit perfektem Score bewältigt.
- MRL-Dimensionskompression: Voyage (0.880) und Jina v4 (0.833) liegen vorn und verlieren bei 256 Dimensionen weniger als 1 %. Gemini (0.668) landet auf dem letzten Platz — stark bei voller Dimension, nicht für Kürzung optimiert.
Auswahlhilfe: Ein Entscheidungs-Flowchart
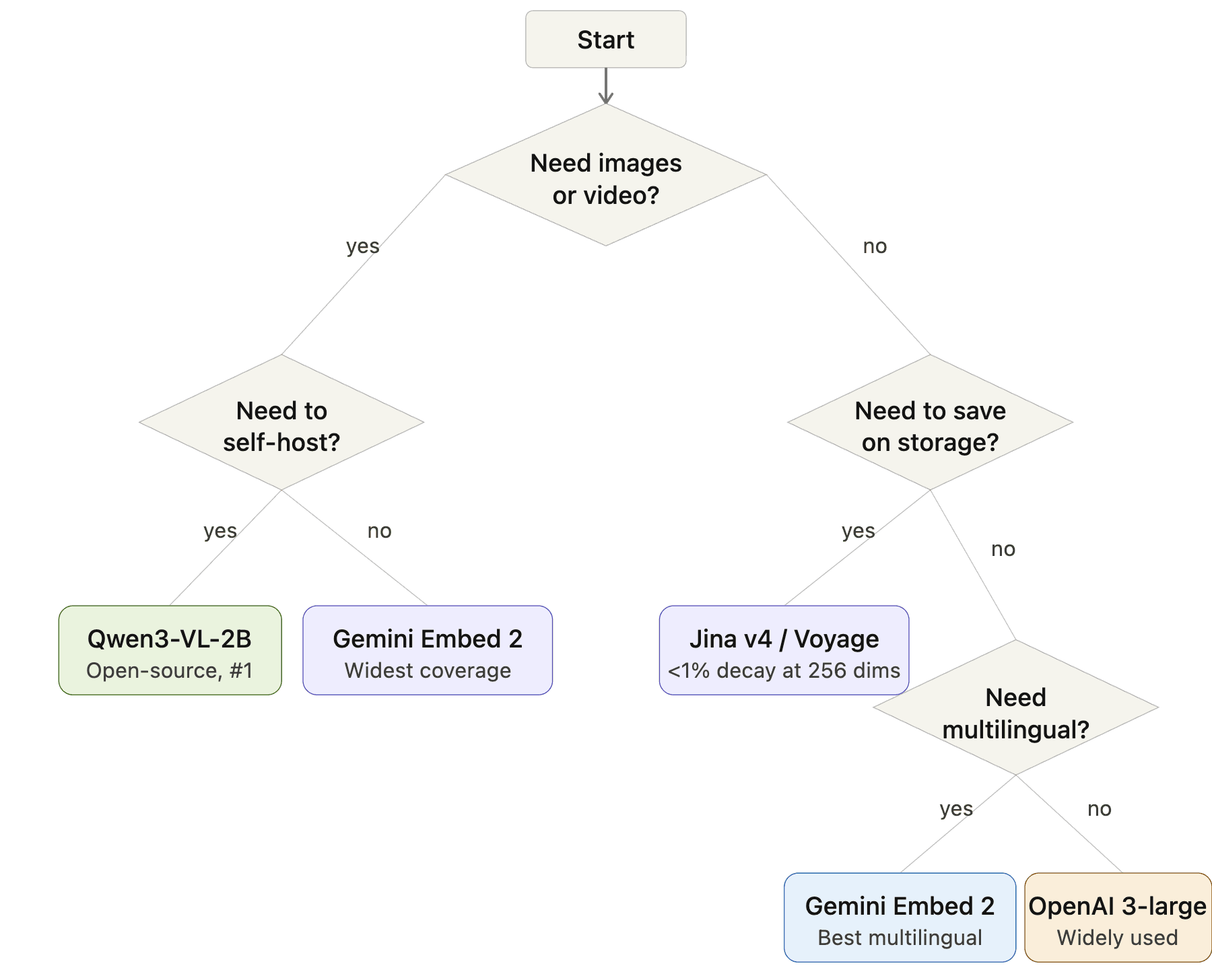 Flowchart zur Auswahl von Embedding-Modellen: Start → Brauchen Sie Bilder oder Video? → Ja: Müssen Sie selbst hosten? → Ja: Qwen3-VL-2B, Nein: Gemini Embedding 2. Keine Bilder → Müssen Sie Speicher sparen? → Ja: Jina v4 oder Voyage, Nein: Brauchen Sie Mehrsprachigkeit? → Ja: Gemini Embedding 2, Nein: OpenAI 3-large
Flowchart zur Auswahl von Embedding-Modellen: Start → Brauchen Sie Bilder oder Video? → Ja: Müssen Sie selbst hosten? → Ja: Qwen3-VL-2B, Nein: Gemini Embedding 2. Keine Bilder → Müssen Sie Speicher sparen? → Ja: Jina v4 oder Voyage, Nein: Brauchen Sie Mehrsprachigkeit? → Ja: Gemini Embedding 2, Nein: OpenAI 3-large
Der beste Allrounder: Gemini Embedding 2
Alles in allem ist Gemini Embedding 2 das stärkste Gesamtmodell in diesem Benchmark.
Stärken: Platz eins bei sprachübergreifender (0.997) und Schlüsselinformationssuche (1.000 über alle Längen bis 32K). Platz zwei bei modalitätsübergreifender Suche (0.928). Breiteste Modalitätsabdeckung — fünf Modalitäten (Text, Bild, Video, Audio, PDF), während die meisten Modelle bei drei enden.
Schwächen: Letzter Platz bei MRL-Kompression (ρ = 0.668). Wird bei modalitätsübergreifender Suche vom Open-Source-Modell Qwen3-VL-2B geschlagen.
Wenn Sie keine Dimensionskompression benötigen, hat Gemini bei der Kombination aus sprachübergreifender + Langdokument-Suche keinen echten Konkurrenten. Aber für modalitätsübergreifende Präzision oder Speicheroptimierung schneiden spezialisierte Modelle besser ab.
Einschränkungen
- Wir haben nicht jedes Modell aufgenommen, das eine Betrachtung wert wäre — NVIDIAs NV-Embed-v2 und Jinas v5-text standen auf der Liste, haben es aber in diese Runde nicht geschafft.
- Wir haben uns auf Text- und Bildmodalitäten konzentriert; Video-, Audio- und PDF-Embedding (trotz entsprechender Support-Behauptungen einiger Modelle) wurde nicht abgedeckt.
- Code-Retrieval und andere domänenspezifische Szenarien lagen außerhalb des Umfangs.
- Die Stichprobengrößen waren relativ klein, daher können enge Ranking-Unterschiede zwischen Modellen innerhalb statistischen Rauschens liegen.
Die Ergebnisse dieses Artikels werden innerhalb eines Jahres veraltet sein. Neue Modelle erscheinen ständig, und die Rangliste wird mit jeder Veröffentlichung neu gemischt. Die nachhaltigere Investition besteht darin, Ihre eigene Evaluierungspipeline aufzubauen — definieren Sie Ihre Datentypen, Ihre Abfragemuster, Ihre Dokumentlängen, und lassen Sie neue Modelle bei Erscheinen durch Ihre eigenen Tests laufen. Öffentliche Benchmarks wie MTEB, MMTEB und MMEB lohnen sich zu beobachten, aber die endgültige Entscheidung sollte immer aus Ihren eigenen Daten kommen.
Unser Benchmark-Code ist Open Source auf GitHub — forken Sie ihn und passen Sie ihn an Ihren Anwendungsfall an.
Sobald Sie Ihr Embedding-Modell ausgewählt haben, brauchen Sie einen Ort, an dem Sie diese Vektoren im großen Maßstab speichern und durchsuchen können. Milvus ist die weltweit am weitesten verbreitete Open-Source-Vektordatenbank mit 43K+ GitHub-Sternen, die genau dafür entwickelt wurde — sie unterstützt MRL-gekürzte Dimensionen, gemischte multimodale Collections, hybride Suche, die dichte und spärliche Vektoren kombiniert, und skaliert vom Laptop bis zu Milliarden von Vektoren.
- Beginnen Sie mit dem Milvus Quickstart guide, oder installieren Sie mit
pip install pymilvus. - Treten Sie dem Milvus Slack oder Milvus Discord bei, um Fragen zur Integration von Embedding-Modellen, zu Strategien für die Vektorindizierung oder zur Skalierung in der Produktion zu stellen.
- Buchen Sie eine kostenlose Milvus Office Hours session, um Ihre RAG-Architektur durchzugehen — wir können bei der Modellauswahl, dem Design des Collection-Schemas und der Leistungsoptimierung helfen.
- Wenn Sie die Infrastrukturarbeit lieber überspringen möchten, bietet Zilliz Cloud (verwaltetes Milvus) einen kostenlosen Tarif für den Einstieg.
Einige Fragen, die aufkommen, wenn Ingenieure ein Embedding-Modell für Production-RAG auswählen:
F: Sollte ich ein multimodales Embedding-Modell verwenden, auch wenn ich derzeit nur Textdaten habe?
Das hängt von Ihrer Roadmap ab. Wenn Ihre Pipeline in den nächsten 6–12 Monaten wahrscheinlich Bilder, PDFs oder andere Modalitäten hinzufügen wird, vermeidet der Start mit einem multimodalen Modell wie Gemini Embedding 2 oder Voyage Multimodal 3.5 später eine schmerzhafte Migration — Sie müssen nicht Ihren gesamten Datensatz neu einbetten. Wenn Sie sicher sind, dass es auf absehbare Zeit nur Text sein wird, bietet Ihnen ein textfokussiertes Modell wie OpenAI 3-large oder Cohere Embed v4 ein besseres Preis-Leistungs-Verhältnis.
F: Wie viel Speicher spart MRL-Dimensionskomprimierung in einer Vektordatenbank tatsächlich?
Der Wechsel von 3072 Dimensionen auf 256 Dimensionen bedeutet eine 12-fache Reduzierung des Speichers pro Vektor. Für eine Milvus-Collection mit 100 Millionen Vektoren bei float32 sind das ungefähr 1,14 TB → 95 GB. Entscheidend ist, dass nicht alle Modelle gut mit Trunkierung umgehen — Voyage Multimodal 3.5 und Jina Embeddings v4 verlieren bei 256 Dimensionen weniger als 1 % Qualität, während andere deutlich nachlassen.
F: Ist Qwen3-VL-2B wirklich besser als Gemini Embedding 2 für die Cross-Modal-Suche?
In unserem Benchmark ja — Qwen3-VL-2B erzielte 0,945 gegenüber Geminis 0,928 beim schwierigen Cross-Modal-Retrieval mit nahezu identischen Distraktoren. Der Hauptgrund ist Qwens viel kleinere Modalitätslücke (0,25 vs. 0,73), was bedeutet, dass Text- und Bild-Embeddings im Vektorraum näher beieinander clustern. Allerdings deckt Gemini fünf Modalitäten ab, während Qwen drei abdeckt. Wenn Sie also Audio- oder PDF-Embedding benötigen, ist Gemini die einzige Option.
F: Kann ich diese Embedding-Modelle direkt mit Milvus verwenden?
Ja. Alle diese Modelle geben standardmäßige Float-Vektoren aus, die Sie in Milvus einfügen und mit Kosinusähnlichkeit, L2-Distanz oder innerem Produkt durchsuchen können. PyMilvus funktioniert mit jedem Embedding-Modell — generieren Sie Ihre Vektoren mit dem SDK des Modells und speichern und durchsuchen Sie sie dann in Milvus. Für MRL-trunkierte Vektoren setzen Sie beim Erstellen der Collection einfach die Dimension der Collection auf Ihr Ziel (z. B. 256).

Weiterlesen

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.