




Experimentieren mit verschiedenen Chunking-Strategien via LangChain für LLM-Apps
Chunking gehört zu den anspruchsvollsten Problemen beim Aufbau von Anwendungen für retrieval-gestützte Generierung (RAG). Chunking ist der Prozess der Satzaufteilung in kleinere, handhabbare Teile für die nachgelagerte Verarbeitung. Auch wenn es einfach klingt, steckt der Teufel im Detail. Eine schlecht gewählte Chunking-Strategie kann zu irrelevanten oder unvollständigen Ergebnissen führen, wodurch es für ein KI-System schwieriger wird, präzise Antworten zu liefern. Beispielsweise können zu kleine Chunks Kontext vermissen lassen, während zu große Chunks irrelevante Informationen zurückgeben können.
In diesem Tutorial untersuchen wir, wie sich unterschiedliche Chunking-Strategien auf die Retrieval-Leistung für denselben Datensatz auswirken; insbesondere konzentrieren wir uns auf einen Anwendungsfall mit Langchain-Chunking. Am Ende dieses Leitfadens wirst du verstehen, wie Chunk-Größe und Überlappung die Retrieval-Qualität beeinflussen, und praktische Einblicke gewinnen, wie du die richtigen Parameter für deinen spezifischen Anwendungsfall auswählst. Der Code für diesen Beitrag ist in diesem GitHub-Repo zur LLM-Experimentation zu finden.
LangChain-Überblick und warum Chunking wichtig ist
LangChain ist ein Large-Language-Model-Orchestrierungsframework mit integrierten Tools zum Laden von Dokumenten und zum Aufteilen von Text. Seine Flexibilität macht es zu einer beliebten Wahl für den Aufbau von RAG-Anwendungen, bei denen Chunking eine entscheidende Rolle dabei spielt, die Relevanz und Vollständigkeit der abgerufenen Informationen zu bestimmen.
Chunking umfasst die Auswahl zweier Hauptparameter: eines gegebenen Chunks, Größe und Überlappung.
Chunk-Größen definieren die Anzahl der Zeichen oder Tokens in jedem Chunk. Größere Chunks erfassen mehr Kontext, riskieren jedoch, irrelevante Informationen zurückzugeben, während kleinere Chunks Präzision sicherstellen, aber notwendigen Kontext verlieren können. Die Überlappung bestimmt, wie viel Text zwischen aufeinanderfolgenden Chunks gemeinsam genutzt wird. Sie hilft, Kontinuität zu bewahren, insbesondere bei zusammenhängenden Ideen über Absätze hinweg, aber übermäßige Überlappung erhöht den Verarbeitungsaufwand. Die Optimierung dieser Parameter stellt ein Gleichgewicht zwischen dem Erfassen von Kontext und dem Beibehalten des Fokus sicher, wenn du Text aufteilst – beides ist entscheidend für präzises Retrieval.
Chunking-Strategien haben breite Anwendungen über RAG-Workflows hinaus. Sie sind entscheidend für kontextbewusste Chatbots, die sich auf gechunkten Text stützen, um prägnante und dennoch umfassende Antworten auf Benutzeranfragen zu liefern. Beispielsweise kann ein Support-Bot Chunking verwenden, um Anleitungen zur Fehlerbehebung in umsetzbare Schritte zu unterteilen, ohne den Benutzer zu überfordern. Ebenso extrahiert Chunking beim Aufbau von Knowledge Graphs Entitäten und Beziehungen aus Rohtext und hilft dabei, unstrukturierte Dokumente in strukturierte Daten umzuwandeln. Diese Beispiele zeigen, wie die richtige Chunking-Strategie nachgelagerte KI-Aufgaben verbessern kann.
Die Herausforderungen von schlechtem Chunking verstehen
Eine schlecht optimierte Chunking-Strategie kann erhebliche Probleme beim Retrieval verursachen. Wirklich kleine Chunk-Größen haben oft nicht genügend Kontext und erzeugen fragmentierte oder unvollständige Ergebnisse. Beispielsweise könnte die Abfrage eines Produkthandbuchs isolierte Fragmente wie „Schritt 1: Schalten Sie die Stromversorgung ein“ zurückgeben, ohne begleitende Informationen zu den folgenden Schritten. Umgekehrt kann das Aufteilen von Text in übermäßig große Chunks durch deine Anwendung die Spezifität der abgerufenen Informationen verwässern. Eine semantische Ähnlichkeitsabfrage, die prägnante Anweisungen zur Fehlerbehebung erwartet, könnte einen ganzen Abschnitt zurückgeben, wodurch es für Benutzer schwieriger wird, relevante Details zu finden.
Überlappung fügt eine weitere Komplexitätsebene hinzu. Ohne Überlappung können Systeme die gedankliche Kontinuität zwischen aufeinanderfolgenden Chunks verlieren, was für zusammenhängende Erzählungen oder Prozesse entscheidend ist. Übermäßige Überlappung kann jedoch Redundanz einführen und Speicher- sowie Verarbeitungskosten erhöhen. Das Ausbalancieren dieser Kompromisse ist entscheidend, um sicherzustellen, dass Retrieval-Systeme präzise, umsetzbare Antworten liefern.
LangChain-Code-Imports und Einrichtung
Dieser erste Abschnitt konzentriert sich auf Importe und andere Setup-Tools. Vielleicht fällt Ihnen am folgenden Code als Erstes auf, dass es eine MENGE Importe gibt. Die häufiger verwendeten sind: os und dotenv, daher werde ich sie nicht behandeln. Sie werden einfach für Ihre Umgebungsvariablen verwendet. Gehen wir das Text-Splitting in LangChain mit Python und dem pymilvus-Client durch.
Oben sehen Sie unsere drei Importe, um das Dokument hineinzuladen. Zuerst gibt es NotionDirectoryLoader, das ein Verzeichnis mit Markdown-/Notion-Dokumenten lädt. Dann haben wir die Markdown Header- und Recursive Character-Text-Splitter. Diese teilen den Text innerhalb des Markdown-Dokuments auf Grundlage von Überschriften (der Header-Splitter) oder einer Reihe vorab ausgewählter Zeichenumbrüche (der rekursive Splitter).
Als Nächstes haben wir die Retriever-Importe. Milvus ist unsere Vektordatenbank, OpenAIEmbeddings ist unser Embedding-Modell, und OpenAI ist unser LLM. Der SelfQueryRetriever ist der native LangChain-Retriever, der es einer Vektordatenbank ermöglicht, sich selbst „abzufragen“. Ich habe in diesem Beitrag mehr über die Verwendung von LangChain zum Abfragen einer Vektordatenbank geschrieben.
Unser letzter LangChain-Import ist AttributeInfo, das, wie man vermuten kann, ein Attribut mit Informationen an den Self-Query-Retriever übergibt. Zuletzt möchte ich auf die pymilvus-Importe eingehen. Diese dienen ausschließlich Hilfszwecken; wir benötigen sie nicht, um in LangChain mit einer Vektordatenbank zu arbeiten. Ich verwende diese Importe, um die Datenbank am Ende zu bereinigen.
Das Letzte, was wir tun, bevor wir die Funktion schreiben, ist, unsere Umgebungsvariablen zu laden und einige Konstanten zu deklarieren. Die Variable headers_to_split_on ist essenziell – sie listet alle Überschriften auf, die wir im Markdown erwarten und anhand derer wir splitten möchten. path sagt LangChain lediglich, wo die Notion-Dokumente zu finden sind.
import os
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from pymilvus import connections, utility
from dotenv import load_dotenv
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_CLUSTER_01_URI")
zilliz_token = os.getenv("ZILLIZ_CLUSTER_01_TOKEN")
headers_to_split_on = [
("##", "Section"),
]
path='./notion_docs'
Eine Chunking-Experimentierfunktion erstellen
Das Erstellen der Experimentierfunktion ist der wichtigste Teil des Tutorials. Wie erwähnt, nimmt diese Funktion einige Parameter für die Dokumentenaufnahme und das Experimentieren entgegen. Wir müssen den Pfad zu den Dokumenten, die Überschriften, nach denen gesplittet werden soll (splitters), die Chunk-Größe, die maximale Chunk-Überlappung sowie die Frage angeben, ob wir am Ende durch das Löschen der Collections bereinigen möchten oder nicht. Das Löschen der Collection ist standardmäßig auf true gesetzt
Wenn wir es vermeiden können, möchten wir Collections so sparsam wie möglich erstellen und löschen, da sie Overheads haben, die wir vermeiden können. Möglicherweise sehen Sie, wie sich das Skript ändert, während ich nach guten Workarounds suche.
Diese Funktion ist der oben verlinkten sehr ähnlich, in der es um die Verwendung von Notion mit LangChain geht. Der erste Abschnitt lädt das Dokument über den Pfad mithilfe des Notion Directory Loader. Beachten Sie, dass wir nur den HTML-Inhalt für die erste Webseite abrufen (und nur eine Seite haben).
Als Nächstes nehmen wir unsere Splitter. Zuerst verwenden wir den Markdown-Splitter, um anhand der oben übergebenen Header zu splitten. Dann verwenden wir unsere rekursive Splitter-Methode und splitten basierend auf Chunk-Größe und Überlappung.
Das ist alles an Splitting, was wir benötigen. Wenn das Splitting abgeschlossen ist, vergeben wir einen Collection-Namen und initialisieren eine LangChain Milvus-Instanz mit den standardmäßigen Umgebungsvariablen, OpenAI Embeddings, Splits und dem Collection-Namen. Außerdem erstellen wir über das AttributeInfo-Objekt eine Liste von Metadatenfeldern, um dem Self-Query Retriever mitzuteilen, dass wir „sections“ haben.
Mit all diesem Setup holen wir uns unser LLM und übergeben es dann an einen Python Self-Query Retriever. Von dort aus erledigt der Retriever seine Magie, wenn wir ihm eine Frage zu unseren Docs stellen. Ich habe es außerdem so eingerichtet, dass es uns sagt, welche Chunk-Strategie wir testen. Schließlich können wir die Collection löschen, wenn wir möchten.
def test_langchain_chunking(docs_path, splitters, chunk_size, chunk_overlap, drop_collection=True):
path=docs_path
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# Let's create groups based on the section headers in our page
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=splitters)
md_header_splits = markdown_splitter.split_text(md_file)
# Define our text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
test_collection_name = f"EngineeringNotionDoc_{chunk_size}_{chunk_overlap}"
vectordb = Milvus.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings(),
connection_args={"uri": zilliz_uri,
"token": zilliz_token},
collection_name=test_collection_name)
metadata_fields_info = [
AttributeInfo(
name="Section",
description="Part of the document that the text comes from",
type="string or list[string]"
),
]
document_content_description = "Major sections of the document"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
res = retriever.get_relevant_documents("What makes a distinguished engineer?")
print(f"""Responses from chunking strategy:
{chunk_size}, {chunk_overlap}""")
for doc in res:
print(doc)
# this is just for rough cleanup, we can improve this
# lots of user considerations to understand for real experimentation use cases though
if drop_collection:
connections.connect(uri=zilliz_uri, token=zilliz_token)
utility.drop_collection(test_collection_name)
LangChain-Tests und Ergebnisse
Okay, jetzt kommt der spannende Teil! Schauen wir uns die Tests und Ergebnisse an.
Code zum Testen von LangChain-Chunks
Dieser kurze Codeblock unten zeigt, wie wir unsere Funktion für Experimente ausführen können. Ich habe fünf Experimente hinzugefügt. Dieses Tutorial testet Chunk-Strategien von 32 bis 512 in der Länge in Zweierpotenzen, mit Überlappungen von 4 bis 64 ebenfalls in Zweierpotenzen. Zum Testen iterieren wir durch die Liste der Tupel und rufen die oben geschriebene Funktion auf.
chunking_tests = [(32, 4), (64, 8), (128, 16), (256, 32), (512, 64)]
for test in chunking_tests:
test_langchain_chunking(path, headers_to_split_on, test[0], test[1])
So sieht die gesamte Ausgabe aus. Werfen wir nun einen Blick auf einzelne Ausgaben. Denkt daran, dass unsere gewählte Beispielfrage lautet: "What makes a distinguished engineer?"
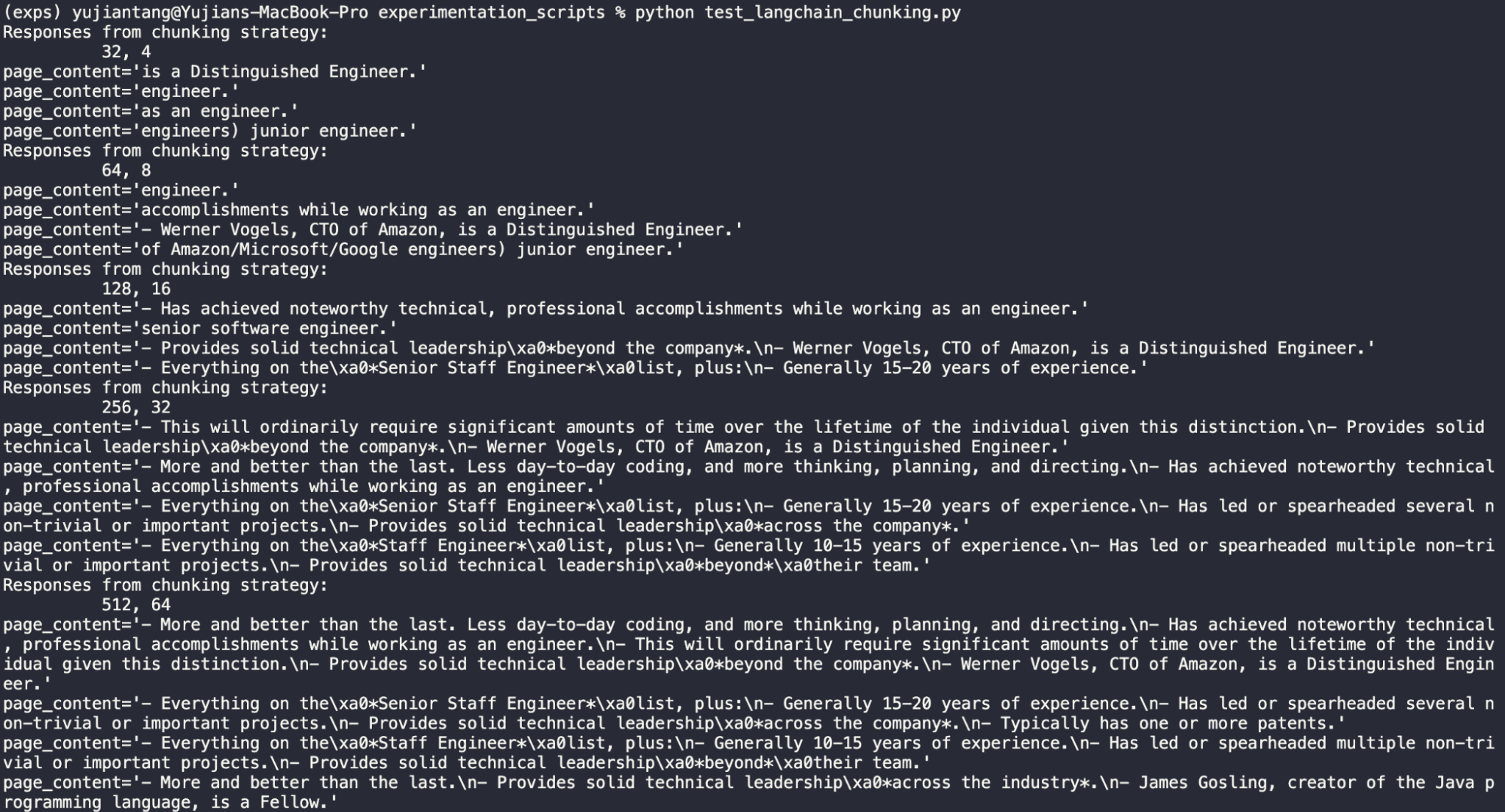
Länge 32, Überlappung 4
Okay, daraus können wir klar erkennen, dass 32 zu kurz ist. Dieser Satz ist völlig nutzlos. „Ist ein Distinguished Engineer“ ist die größtmögliche zirkuläre Argumentation.
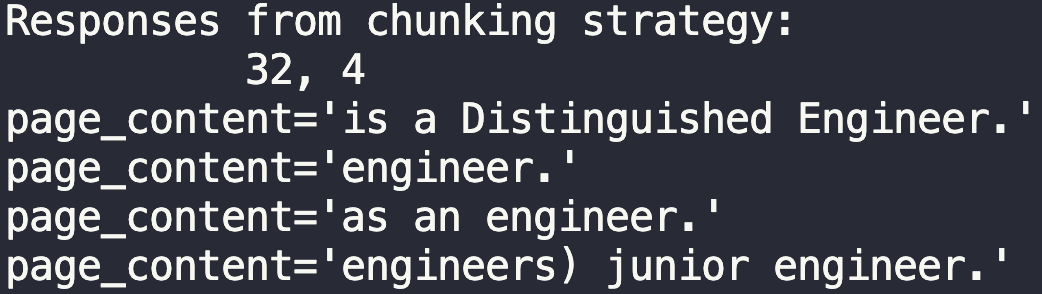
Länge 64, Überlappung 8
64 und 8 ist von Anfang an nicht viel besser. Es liefert uns allerdings ein Beispiel für einen Distinguished Engineer. Werner Vogels, CTO von Amazon.

Länge 128, Überlappung 16
Bei 128 beginnen wir, vollständigere Sätze zu sehen. Weniger Wörter und Antworten wie „engineer.“. Das ist nicht schlecht, es schafft es, den Teil über Werner Vogel und „Hat während seiner Arbeit als Ingenieur bemerkenswerte technische, berufliche Leistungen erzielt.“ zu extrahieren. Der letzte Eintrag stammt tatsächlich aus dem Abschnitt über Principal Engineers.
Ein Nachteil hier ist, dass wir bereits Beispiele für diese Sonderzeichen wie \xa0 und \n auftauchen sehen. Das sagt uns, dass wir beim Chunking vielleicht mit der Länge zu weit gehen.

Länge 256, Überlappung 32
Ich denke, diese Chunking-Länge ist definitiv zu lang. Sie zieht die erforderlichen Einträge heran, aber auch Einträge aus „Fellow“, „Principal Engineer“ und „Senior Staff Engineer“. Der erste Eintrag stammt jedoch aus Distinguished Engineer und deckt drei Punkte dazu ab.

Chunk-Länge 512, Überlappung 64
Wir haben bereits festgestellt, dass 256 wahrscheinlich zu lang ist. Allerdings ist der erste Treffer bei 512 tatsächlich der gesamte Abschnitt für Distinguished Engineers. Jetzt haben wir ein Dilemma – wollen wir einzelne „Zeilen“ oder „Notizen“ oder einen ganzen Abschnitt abrufen? Das hängt von deinem Anwendungsfall ab.

Zusammenfassung des Experimentierens mit unterschiedlichen Chunking-Strategien
Cool, also haben wir in diesem Tutorial mit langchain chunking python fünf verschiedene Text-Splitter-Strategien mit einem parametrisierten Ansatz gesehen, der Chunk-Größe und Chunk-Überlappungsstrategien hervorhebt. Eines der Dilemmas, das wir schon bei diesen einfachen 5 Chunk-Strategien gesehen haben, ist die Entscheidung zwischen dem Abrufen einzelner Häppchen und eines ganzen Abschnitts, abhängig von der Chunk-Größe. Wir haben gesehen, dass 128 ziemlich gut dafür war, einzelne „Zeilen“ oder „Notizen“ über Distinguished Engineers zu erhalten, während 512 unseren gesamten Abschnitt zurückliefern konnte.
Allerdings war 256 nicht so gut.
Diese drei Datenpunkte sagen uns etwas über den Text-Splitter. Es ist nicht nur so, dass es schwierig ist, eine ideale Chunk-Größe zu finden. Es ist auch ein Zeichen dafür, dass du dir beim Festlegen deiner Chunk-Größen ebenfalls überlegen musst, was du von deinen Antworten erwartest.
Beachte, dass wir noch nicht einmal dazu gekommen sind, verschiedene Überlappungen zu testen. Nachdem man gelernt und eine gute Chunk-Strategie entwickelt hat, ist das Überprüfen von Überlappungen der logische nächste Schritt. Vielleicht behandeln wir es in einem zukünftigen Tutorial, vielleicht mit einer anderen Bibliothek. Bleib dran!
Erkenntnisse aus dem Experimentieren
Diese Experimente verdeutlichen die nuancierte Beziehung zwischen Chunk-Größe und Überlappung. Kleinere Chunks sind bei Aufgaben, die punktgenaue Genauigkeit erfordern, besonders stark, während größere Chunks besser für Fragen geeignet sind, die umfangreichen Kontext verlangen. Überlappung hingegen spielt eine zentrale Rolle beim Ausbalancieren dieser Ziele.
Es ist wichtig zu betonen, dass die hier beobachteten Kompromisse keine Einheitslösung sind. Die idealen Chunking-Parameter hängen stark von deinem spezifischen Anwendungsfall ab. Anwendungen wie Konversationsagenten oder Tools für schnelle Nachschlagen können von kleineren Chunks für präzise Antworten profitieren. Andererseits erfordern forschungsintensive Workflows, wie das Zusammenfassen komplexer juristischer Dokumente, größere Chunks, um umfassenden Kontext sicherzustellen.
In realen Szenarien kann ein hybrider Ansatz oft die besten Ergebnisse liefern. Durch die dynamische Anpassung der Chunk-Größen basierend auf der Anfrage und Absicht des Benutzers können Entwickler ein Gleichgewicht zwischen Effizienz und Abrufqualität finden. Solche Ansätze können das Hinzufügen von Ebenen für intelligentes Query-Routing oder adaptive Chunking-Pipelines umfassen, die auf Benutzerbedürfnisse zugeschnitten sind.
Zukünftige Überlegungen
Die in diesem Tutorial durchgeführten Experimente sind erst der Anfang. Zukünftige Untersuchungen könnten hierarchische Chunking-Strategien betrachten, die unterschiedliche Chunk-Größen für eine mehrstufige Segmentierung kombinieren. Darüber hinaus eröffnet die Ausweitung auf multimodalen Datenabruf, etwa die Kombination von Text- und Bild-Embeddings, Möglichkeiten für komplexere Anwendungsfälle.
Es besteht außerdem Potenzial darin, systematisch mit Überlappungen zu experimentieren, um besser zu verstehen, wie sie den Abruf über vielfältige Datensätze hinweg beeinflussen. Die Integration anderer Frameworks neben LangChain könnte Chunking-Ansätze weiter verfeinern und neue Optimierungstechniken aufdecken. Beispielsweise bieten Frameworks wie Haystack zusätzliche Abruffunktionen, die den Workflow von LangChain ergänzen können.
Schließlich könnte die Einbeziehung von Benutzerfeedback in den Abrufprozess zu adaptiven Systemen führen, die Chunking-Strategien im Laufe der Zeit lernen und optimieren. Mit stärker feinabgestimmten Experimenten ist es möglich, robuste, benutzerzentrierte RAG-Pipelines zu etablieren.
Fazit
Chunking ist eine unverzichtbare Komponente von Abruf-Workflows in RAG-Anwendungen. Dieses Tutorial hat gezeigt, wie wichtig es ist, Chunk-Größe und Überlappung sorgfältig abzustimmen, und veranschaulicht, wie unterschiedliche Strategien die Abrufresultate beeinflussen.
Durch das Ausbalancieren von Zielkonflikten zwischen Kontext und Präzision können Entwickler ihre Systeme für eine Vielzahl von Anwendungsfällen optimieren. Während dieses Tutorial grundlegende Experimente behandelte, sind die Möglichkeiten für weitere Erkundungen enorm. Bleiben Sie dran für fortgeschrittenere Tutorials und Einblicke in die Optimierung KI-gestützter Abrufsysteme.
Chunking-Referenzen
Chunking- oder Text-Splitter-Strategien entwickeln sich ständig weiter, daher haben wir begonnen, eine Sammlung dieser verschiedenen Strategien aufzubauen, um sie zu betrachten und potenziell in Ihrer Anwendung zu implementieren. Viel Spaß!
Ein Leitfaden zu Chunking-Strategien für Retrieval Augmented Generation (RAG). In diesem Leitfaden haben wir verschiedene Facetten von Chunking-Strategien innerhalb von Retrieval-Augmented-Generation-(RAG)-Systemen untersucht.
Ein Leitfaden für Einsteiger zu Website-Chunking und Embedding für Ihre RAG-Anwendungen. In diesem Beitrag erklären wir, wie man Inhalte von einer Website extrahiert und sie als Kontext für LLMs in einer RAG-Anwendung verwendet. Zuvor müssen wir jedoch die Grundlagen von Websites verstehen.
Drei Schlüsselstrategien zum Aufbau effizienter Retrieval Augmented Generation (RAG) erkunden. Retrieval Augmented Generation (RAG) ist eine nützliche Technik, um Ihre eigenen Daten in einem KI-gestützten Chatbot zu verwenden. Dieser Blogbeitrag führt Sie durch drei Schlüsselstrategien, um das Beste aus RAG herauszuholen.
Pandas DataFrame: Chunking und Vektorisierung mit Milvus. Wenn wir alle Daten, einschließlich des Chunk-Texts und des Embeddings, innerhalb eines Pandas DataFrame speichern, können wir sie einfach in die Milvus-Vektordatenbank integrieren und importieren.

Weiterlesen

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.