




Der AWS-Ausfall war ein Weckruf für regionsübergreifende Disaster Recovery bei Vektordatenbanken
Cloud-Regionen fallen aus. Es ist keine Frage, ob — sondern wann und wie schlimm.
Letzte Woche gingen zwei AWS-Regionen im Nahen Osten aufgrund physischer Schäden an der Rechenzentrumsinfrastruktur offline. Zwei von drei Availability Zones in der UAE-Region von AWS (ME-CENTRAL-1) fielen aus, und eine Einrichtung in Bahrain (ME-SOUTH-1) wurde beschädigt. Über 60 AWS-Services waren betroffen, darunter Lambda, EKS, VPC, S3 und CloudWatch. Careem, die größte Ride-Hailing-Plattform der Region, verlor den Dienst. Alaan, ein führender Zahlungsanbieter, war nicht mehr erreichbar. AWS riet Kunden, Workloads in andere Regionen zu verlagern — aber dies war kein Neustart-und-Wiederherstellen-Vorfall. Bei Hardwareaustausch und Reparatur der Einrichtung kann die Wiederherstellung Wochen dauern.
Und physische Schäden sind nur eine Ausfallart. In den vergangenen 12 Monaten legte eine fehlerhafte Konfigurationsänderung die Azure-Region Central US für 14,5 Stunden lahm. Ein Fehler in Google Cloud schaltete Cloud Run, GKE und Firebase gleichzeitig für 8 Stunden aus. Ein fehlerhaftes CrowdStrike-Softwareupdate — nicht einmal ein Problem eines Cloud-Anbieters — breitete sich kaskadenartig durch Azure-gehostete Infrastruktur aus und kostete Fortune-500-Unternehmen schätzungsweise 5,4 Milliarden US-Dollar.
Der Bericht 2025 des Uptime Institute beziffert die Median-Kosten eines schwerwiegenden Ausfalls auf 2 Millionen US-Dollar pro Stunde, ungefähr das Doppelte des Werts von vor drei Jahren. Dennoch stellte der Veeam Data Protection Trends Report 2024 fest, dass nur 13 % der Organisationen die Wiederherstellung während einer echten Katastrophe tatsächlich orchestrieren können.
Diese Zahlen waren bereits alarmierend. Dann erhöhte KI den Einsatz.
Wenn KI ausfällt, verlangsamen Teams sich nicht — sie stehen still
Vor fünf Jahren traf ein regionaler Cloud-Ausfall hauptsächlich kundenorientierte Apps. Schmerzhaft, aber die meisten Teams konnten intern weiterhin funktionieren. Heute hat KI Arbeit übernommen, die ganze Abteilungen umfasst — Code-Review, Dokumentation, Support-Triage und sogar Routineanalysen. Da fast 60 % der Mitarbeitenden KI in täglichen Arbeitsabläufen nutzen, verursachen Ausfälle keine allmähliche Verlangsamung. Die Produktivität stürzt ab.
Wir haben das bereits erlebt — ChatGPT und Claude erlitten beide Anfang 2026 erhebliche Ausfälle und ließen Millionen von Nutzern und Enterprise-Teams ohne die KI-Tools zurück, um die herum sie ihre Arbeitsabläufe aufgebaut hatten.
Aber Folgendes übersehen die meisten Teams. Modellausfälle sind störend, doch Modelle sind weitgehend zustandslos: Anbieter können Inferenz-Traffic oft relativ schnell in gesunde Regionen umleiten. Das schwierigere Problem ist die darunterliegende Datenschicht — die Datenbanken, Object Stores und Vektorindizes, die Gedächtnis und Kontext liefern. Diese Schicht ist zustandsbehaftet, regionsgebunden und weit schwieriger wiederherzustellen. Wenn sie ausfällt, generiert dein LLM möglicherweise weiterhin Text — aber ohne den richtigen Kontext wechselt es standardmäßig zu generischer, halluzinationsanfälliger Ausgabe. KI geht nicht einfach offline. Sie wird unzuverlässig.
Die Vektordatenbank ist das Langzeitgedächtnis deiner KI — und sie ist wahrscheinlich Single-Region
Vektordatenbanken sind zum Rückgrat von Enterprise-KI geworden. RAG-Pipelines und KI-Agenten rufen Kontext aus ihnen ab. Empfehlungsmaschinen fragen sie ab. Semantische Suche läuft gegen sie. Wenn diese Schicht nicht verfügbar ist, bricht jede darauf aufgebaute Anwendung zusammen — nicht teilweise, sondern vollständig.
Und anders als bei zustandslosen Services ist die Wiederherstellung nicht einfach:
- Index-Neuaufbauten sind langsam. Vektorsuche hängt von Indexstrukturen wie HNSW-Graphen ab, bei denen die Wiederaufbauzeit nichtlinear mit der Datensatzgröße skaliert. Der Neuaufbau eines Index über 100M+ Vektoren kann auf Standard-Compute 18+ Stunden dauern.
- Connection Strings sind überall. Jede Anwendung, die mit dem alten Cluster verbunden war, muss ihren Endpunkt aktualisiert bekommen — über Konfigurationen, Umgebungsvariablen, CI/CD-Pipelines hinweg, oft von verschiedenen Teams verwaltet.
- Embedding-Model-Drift. Wenn du die genaue Version des Embedding-Modells, das deine aktuellen Vektoren erzeugt hat, nicht finden kannst, musst du möglicherweise deinen gesamten Datensatz neu einbetten.
Bei einem Softwareausfall warten Sie auf einen Neustart. Wenn ein Rechenzentrum jedoch physisch beschädigt ist, dauert die Wiederherstellung Wochen. Die einzig tragfähige Strategie besteht darin, bereits eine live, indexierte, abfragebereite Replik zu haben, die aus einer anderen Region bereitgestellt wird — mit Traffic-Umleitung, die keine Codeänderungen erfordert.
Zilliz Cloud: Die weltweit erste Vektordatenbank mit nativer regionsübergreifender Notfallwiederherstellung
Zilliz Cloud ist die weltweit erste Vektordatenbank, die native regionsübergreifende Notfallwiederherstellung bietet — mit automatisiertem Failover, Echtzeit-Replikation und einem globalen Endpunkt, der während Regionswechseln keine Anwendungsänderungen erfordert.
Wir bieten zwei sich ergänzende Funktionen: Global Cluster für Echtzeit-Failover und Cross-Region Backup für kosteneffiziente Notfallwiederherstellung.
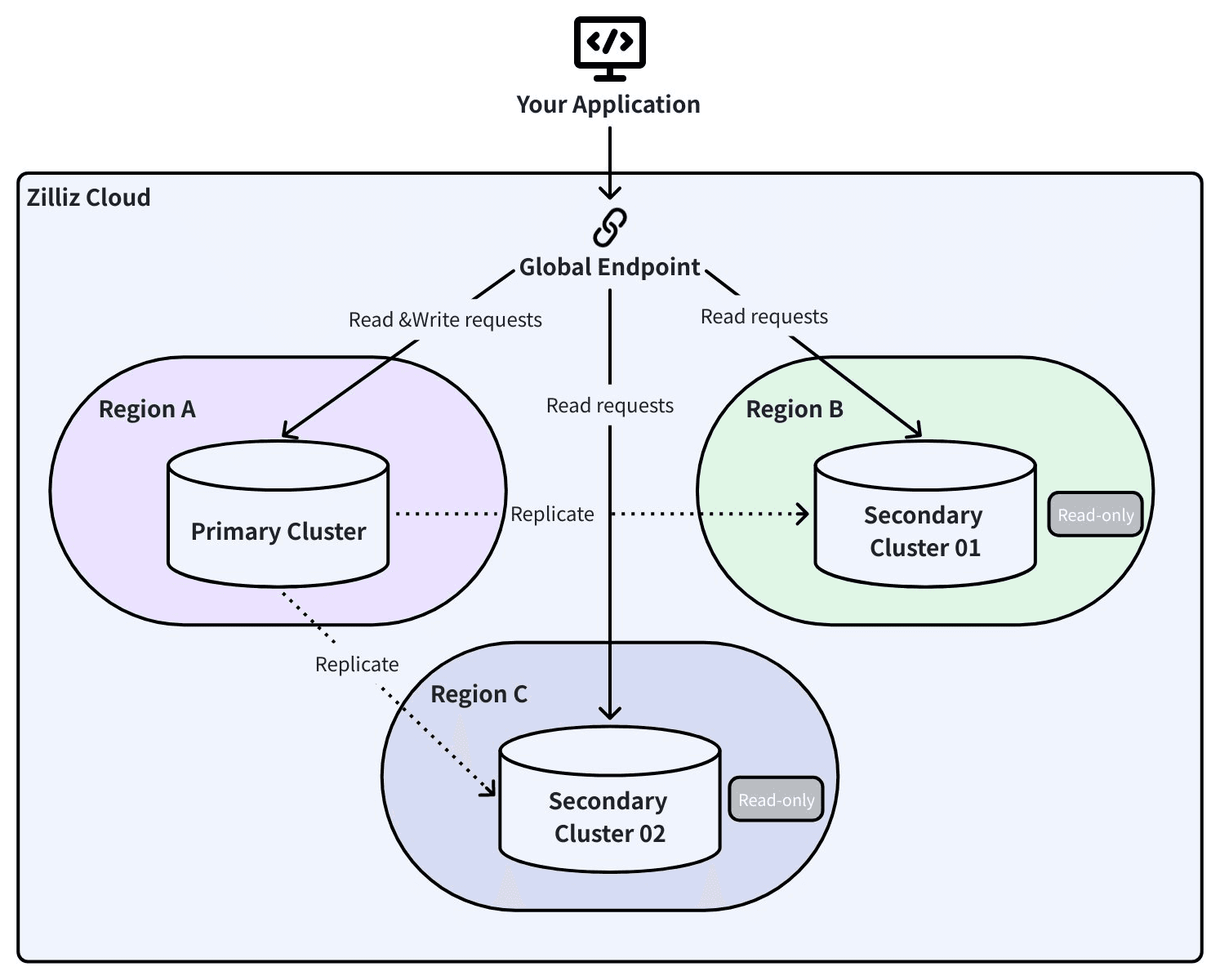
Global Cluster: Live-Replikation mit automatischem Failover
Global Cluster verwendet Change Data Capture (CDC), um Daten kontinuierlich zwischen einem primären Cluster und einem sekundären Cluster in einer anderen Region zu replizieren. Keine periodischen Snapshots — jeder Insert, jedes Update und jedes Delete wird in Echtzeit weitergegeben.
- Geplanter Switchover (Wartung, Migration, Compliance): Das System leert laufende CDC-Nachrichten, bestätigt die vollständige Synchronisierung und tauscht dann die Rollen. RPO ist null. RTO liegt unter 30 Sekunden.
- Automatischer Failover (unerwarteter Regionsausfall): Der sekundäre Cluster stuft sich automatisch selbst hoch. RPO entspricht dem CDC-Lag zum Zeitpunkt des Ausfalls — typischerweise wenige Sekunden. RTO liegt unter 60 Sekunden.
Eine einzigartige Fähigkeit: Nach einem Failover verschwindet der alte primäre Cluster nicht einfach. Er landet in einem Papierkorb mit 7-tägiger Aufbewahrung, und eine Streaming-API namens DumpMessages ermöglicht es Ihnen, alle Schreibvorgänge abzurufen, die auf dem alten primären Cluster gelandet, aber noch nicht repliziert worden waren. Anstatt Datenverlust hinzunehmen, erhalten Sie ein Zeitfenster, um sie wiederherzustellen.
Global Endpoint: Eine Verbindung, jede Region
Hier zahlt sich die Architektur in einem physischen Katastrophenszenario aus.
Ihre Anwendung verbindet sich mit einem einzigen globalen Endpunkt. Dahinter verfolgen SRV-DNS-Einträge, welcher Cluster primär und welcher sekundär ist. Wenn ein Failover stattfindet, erkennt das SDK die Topologieänderung und leitet den Traffic automatisch um. Keine Aktualisierungen von Verbindungszeichenfolgen. Keine Anwendungsneustarts. Keine Codeänderungen.
Denken Sie darüber nach, was das während eines länger andauernden regionalen Ausfalls bedeutet. Ohne einen globalen Endpunkt erfordert die Wiederherstellung, dass jemand ein Runbook findet, Clients manuell neu konfiguriert, Verbindungszeichenfolgen aktualisiert und teamübergreifend koordiniert — um 3 Uhr morgens, unter Druck. Ihre RTO wird nicht in Sekunden gemessen; sie wird daran gemessen, wie lange es dauert, den richtigen Engineer zu erreichen.
Mit Global Endpoint fragt Ihre RAG-Pipeline die Replik in einer anderen Region innerhalb von 60 Sekunden ab, ohne eine einzige Codezeile zu ändern.
Cross-Region Backup: Resilienz ohne die Kosten einer Live-Replik
Nicht jeder Workload rechtfertigt den Betrieb eines sekundären Clusters. Cross-Region Backup repliziert Backup-Daten in eine oder mehrere Zielregionen, jeweils mit eigener Aufbewahrungsrichtlinie. Wenn ein Ausfall auf Regionsebene eintritt, starten Sie einen neuen Cluster von einem beliebigen Backup-Punkt in der Zielregion — während der Krise ist keine regionsübergreifende Datenübertragung erforderlich, weil die Daten bereits dort sind.
Der Trade-off:
- Global Cluster → RPO in Sekunden, RTO unter 60 Sekunden. Für Workloads, die keine Ausfallzeit tolerieren können.
- Cross-Region Backup → RPO und RTO in Stunden. Für Workloads, bei denen das Überleben der Daten wichtiger ist als sofortige Wiederherstellung.
Viele Teams beginnen mit Cross-Region Backup für die entscheidende Garantie — Ihre Daten überstehen einen Regionsausfall — und upgraden auf Global Cluster, sobald ihre KI-Workloads geschäftskritisch werden.
Wie andere Vektordatenbanken mit regionsübergreifender DR umgehen
Die meisten Vektordatenbanken bieten Hochverfügbarkeit innerhalb einer einzelnen Region durch Replica Sets und Knotenredundanz. Das deckt Knotenausfälle ab — nicht Regionsausfälle. Zilliz Cloud ist die einzige Vektordatenbank, die natives automatisiertes regionsübergreifendes Failover mit einem globalen Cluster und einem globalen Endpunkt bietet — Regionswechsel ohne Ausfallzeiten und ohne Codeänderungen.
| Fähigkeit | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Regionsübergreifende Replikation | ✅ CDC-basiert, in Echtzeit | ❌ | ❌ | ❌ | ❌ |
| Ungeplantes Failover | ✅ RPO ≈ Sekunden, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Geplanter Switchover | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Datenrettung nach Failover | ✅ Automatische Rettung von Daten, die nicht synchronisiert wurden. | ❌ | ❌ | ❌ | ❌ |
| Globaler Endpunkt | ✅ Ein globaler Endpunkt, automatische Umleitung ohne Codeänderungen | ❌ | ❌ | ❌ | ❌ |
| Regionsausfall RPO/RTO | ✅ RPO ≈ Sekunden, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Automatisches regionsübergreifendes Backup | ✅ JEDE Region mit Aufbewahrung pro Region | ❌ | ❌ | ❌ | ❌ |
Mehr als Disaster Recovery
Teams verwenden Global Cluster auch für operative Szenarien, die nichts mit Ausfällen zu tun haben:
- Latenzoptimierung: Fügen Sie eine sekundäre Region näher an Ihren Nutzern hinzu, um Abfrageantwortzeiten unter 100 ms zu erzielen.
- Regionsmigration: Verschieben Sie Workloads zwischen Regionen ohne Ausfallzeiten während der Infrastrukturkonsolidierung.
- Compliance für Datenresidenz: Halten Sie Daten innerhalb bestimmter geografischer Grenzen, um regulatorische Anforderungen zu erfüllen.
Dieselbe CDC-Pipeline, die vor Ausfällen schützt, bietet Ihnen auch eine lesefähige Replik näher an Ihren Nutzern — DR-Fähigkeit als Nebeneffekt der Leistungsoptimierung.
Erste Schritte
Global Cluster und Cross-Region Backup sind auf Zilliz Cloud für dedizierte Cluster verfügbar.
- Wenn Sie bereits ein Zilliz Cloud-Konto haben, melden Sie sich an und nutzen Sie die neuen Funktionen sofort — keine Upgrades oder Migrationen erforderlich.
- Neu bei Zilliz Cloud? Kostenlos registrieren und \$100 Guthaben erhalten, um die weltweit führende verwaltete Vektordatenbank zu erleben.
- Haben Sie Fragen zu den Updates? Lesen Sie die neueste Dokumentation oder wenden Sie sich an den Zilliz Support—wir sind hier, um zu helfen.
Ohne Grenzen entwickeln: Ein genauerer Blick auf die Enterprise-fähigen Funktionen von Zilliz Cloud
Global Cluster ist ein Bestandteil einer breiteren Plattform, die für KI im Produktionsmaßstab entwickelt wurde. Zilliz Cloud bietet außerdem:
- Elastische Skalierung & Kosteneffizienz – One-Click-Bereitstellung, serverloses Autoscaling und nutzungsbasierte Preise.
- Fortschrittliche KI-Suche – Vektor-, Volltext- und hybride (sparse + dense) Suche mit Metadatenfilterung, dynamischem Schema und Multi-Tenancy.
- Enterprise-Grade-Sicherheit – 99,95 % SLA, SOC 2 Type II- und ISO 27001-Zertifizierungen, DSGVO-Konformität, HIPAA-Readiness, RBAC, BYOC und Audit-Logs. Weitere Informationen finden Sie in unserem Trust Center.
- Globale Verfügbarkeit – Bereitstellungen über AWS, GCP und Azure mit Latenzzeiten unter 100 ms weltweit.
- Nahtlose Migration – Integrierte Tools für den Wechsel von Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate oder lokalem Milvus.
- Abfragen in natürlicher Sprache – MCP-Server-Unterstützung für intuitive Abfragen ohne komplexe APIs.
- Und mehr!

Weiterlesen

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.