




Zilliz x Galileo: The Power of Vector Embeddings
Unstructured data is everywhere. The IDC has estimated we’ll have over 175 zettabytes (21 zeroes) of data by 2025. 80% of that is unstructured data. Unstructured data is data that doesn’t fit any predetermined format — it doesn’t follow a preset data model or schema. It commonly takes the form of text, images, audio, and videos but can handle various other conditions.
What is a vector embedding?
At the most basic level, vector embeddings are a numerical data representation. A vector embedding typically consists of hundreds or thousands of floats. The high dimensionality allows vector embeddings to store complex data such as images, audio, and text. You can extract vector embeddings from trained machine-learning models. Most neural networks used in production have many layers, each with hundreds of neurons. When a data point is run through the feed-forward function of the neural network, each layer produces an output. Typically, these networks do some classification created by the final layer of the network. The vector embedding representing the data is the output of the final hidden layer, which usually refers to the second to last layer.
How can you work with vector embeddings?
Vector embeddings are the de facto way to work with unstructured data. If you have data that you want to compare, we recommend you do so using vector embeddings. Vector embeddings are generated from neural networks by taking the output from the second to last layer of a neural network and using that as the vector embedding of the input. When generating embedding vectors, there are several factors to consider. Your primary considerations are the size of the embeddings, the data for model training, and the data quality. You have to ensure that your vectors are a size that makes sense.
Using vector embeddings to debug your training data
Find data errors
The initial stage of model development is primarily concerned with addressing "data curation" challenges. The main objective during this phase is to construct an optimal dataset for model training and evaluation. Galileo, an algorithmic LLM Ops platform for the enterprise, employs embeddings for detecting data error through clustering.
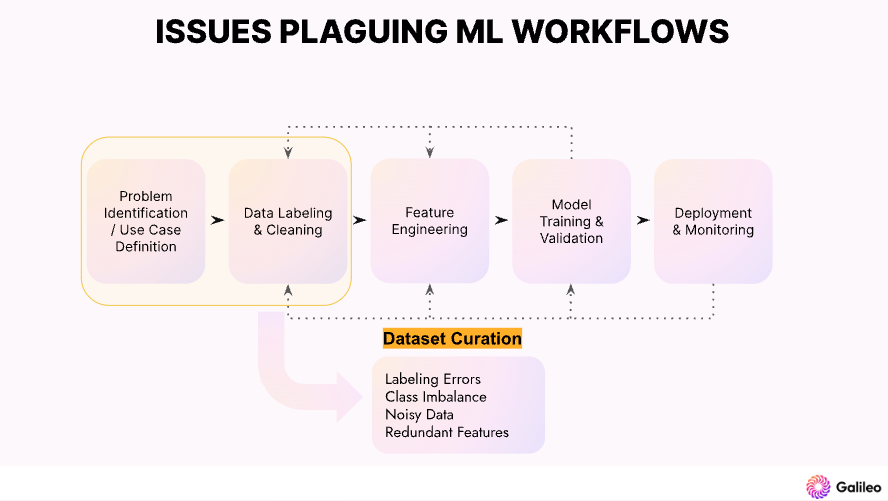
Galileo has a unique ability to show errors with a score called Data Error Potential (DEP). DEP provides a tool to quickly sort and bubble up data that is most difficult and worthwhile to explore when digging into your model’s errors.
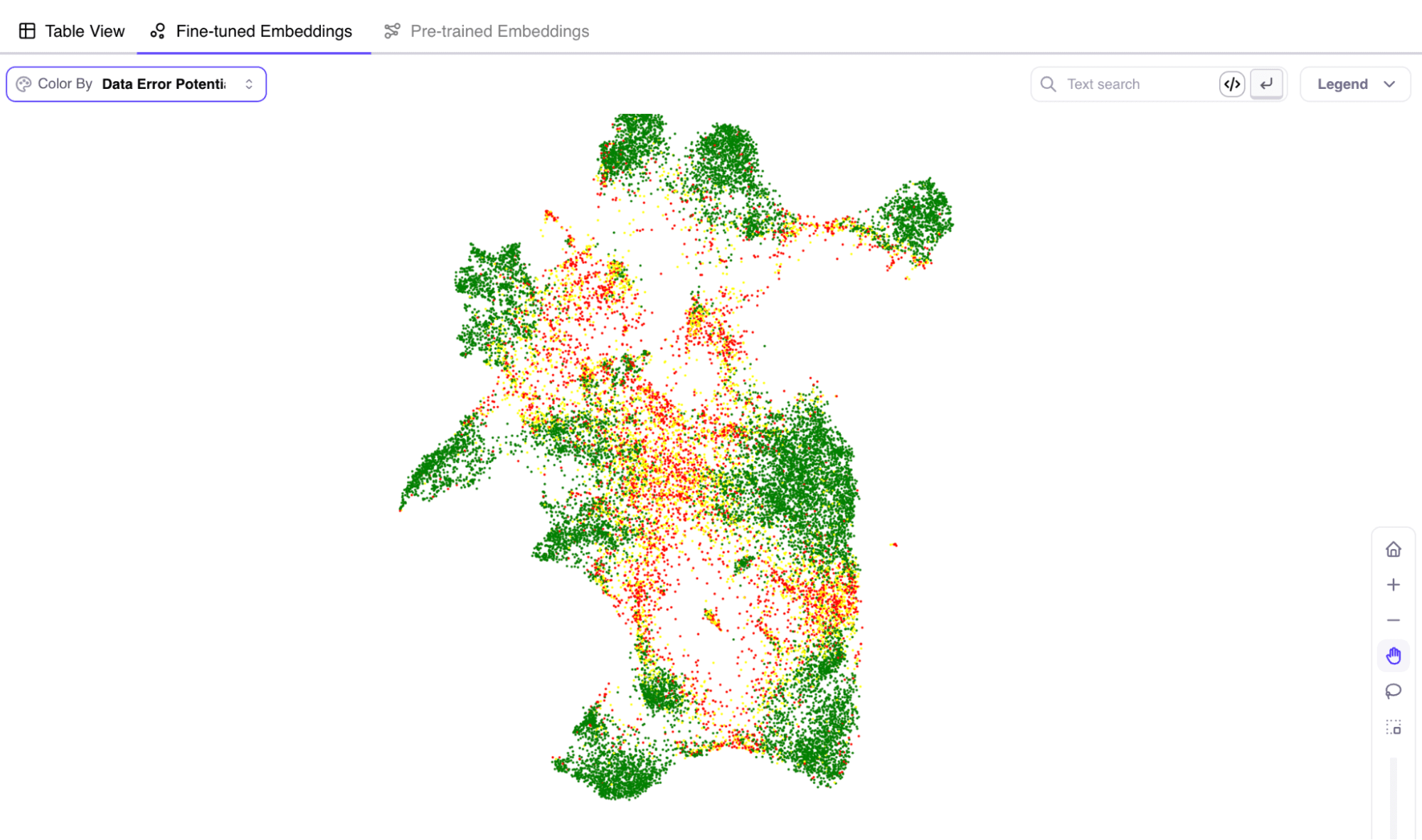
When it comes to debugging your data errors, there are two types of solutions.
Find samples not present in your training data
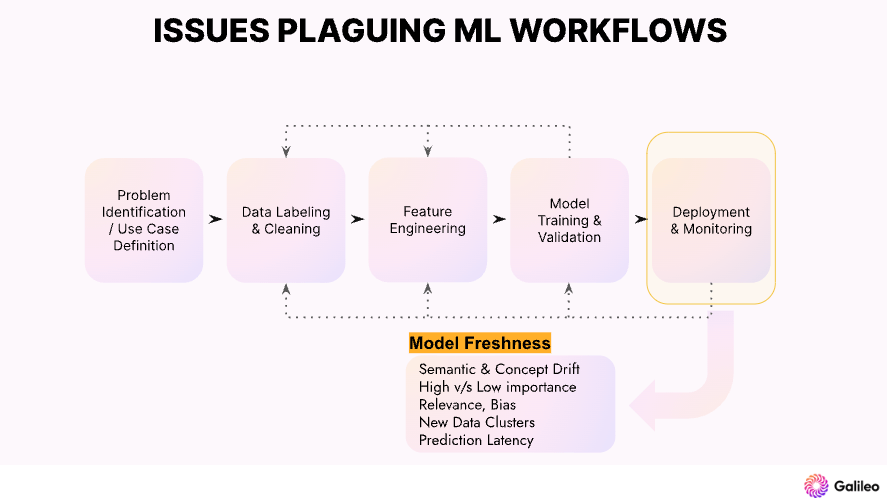
Once the model is deployed and interacts with real-world data, there is a shift in traffic patterns. Galileo can detect model drift by leveraging embeddings to monitor ML models' performance continuously. The drifted samples can be annotated and added to the training data for more robust performance.
Find hallucinations in data
AI hallucination refers to situations where the AI generates information that may sound plausible but is incorrect or unrelated to the context. This problem typically occurs due to AI design biases, inadequate understanding of the real world, or incomplete training data.
To address this issue, Galileo is actively involved in embedding-based techniques to identify instances of AI hallucination. This approach helps uncover errors in the data and contributes to training more accurate and reliable AI models.
Find errors in retrieval augmented generation
(RAG)Retrieval Augmented Generation (RAG) is a popular technique for developing question-answering systems and chatbots. However, a common problem with this approach is the occurrence of poor retrieval, which results in providing incorrect answers. Galileo is building a context relevance score for detecting the wrong context using embedding-based techniques to tackle this issue. Sometimes, even when relevance is correct, the generation might contain hallucinations. Galileo will provide a groundedness score, measuring whether the model’s response was based on the information given to the model in the context window.
 The powerful algorithms in Galileo can show token-level errors, which can help applications stop making hallucinations.
The powerful algorithms in Galileo can show token-level errors, which can help applications stop making hallucinations.

Index, store, and query vector embeddings
While it is excellent to have embeddings, you must be able to use them. It would be best to have something to index, store, and query your vectors for. That’s the whole point of vector databases. Vector databases are purpose-built for indexing, storing, and querying vector data. Being able to index, store, and query makes vector databases a strong candidate for use in LLM applications. They are perfect for storing the semantic meaning of documents and queries and as a cache for FAQs. A perfect example of how to use vector embeddings with LLM apps is OSSChat, an application that allows you to “chat” with open-source software documentation.

One of the most important aspects of having a practical Q/A application is using suitable vector embeddings. To query the documents, we need the latent vector space of the queries. We use an LLM like ChatGPT to generate questions given a set of documents. Then, we index and store those embeddings to query them when the user asks questions.
Summary of the power of vector embeddings
Unstructured data is the most common type of data in the world. Traditionally, it’s been hard to work with unstructured data because it doesn’t conform to a predetermined structure. Deep learning has become more powerful and widespread, so it produced a solution to working with unstructured data by turning it into vectors.
Vector embeddings allow you to do math on things that don’t start as numbers. In this post, we introduced vector embeddings, how to work with them, and four concrete ways to use vectors in the current machine-learning paradigm. You can use vector embeddings to find data errors, find samples not present in your training data, find hallucinations, and fix errors in retrieval augmented generation.
The power of vector embeddings can be seen from this wide range of use cases. The most effective way to work with them is to use a vector database like Milvus or Zilliz Cloud to store, index, and query the vectors.
Join our upcoming webinar hosting Galileo
Join Vikram Chatterji of Galileo and Yujian Tang of Zilliz on October 12 for a deep dive into RAG and LLM management. This webinar will equip you with actionable insights and methods to enhance your LLM pipelines and output quality. It promises to be an informative session for any data scientists and machine learning engineers looking for frameworks and tools to optimize RAG and LLM performance.

Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.