




OpenAI o1: What Developers Need to Know
In September 2024, OpenAI introduced the latest series of their proprietary Large Language Models (LLMs), called the o1 series. The primary feature that differentiates the o1 series from OpenAI’s previous most powerful model, GPT-4o, is their ability to think through problems before generating a final answer for the user. This means that the o1 models are trained to break down problems into smaller components and solve them in a step-by-step manner, a process commonly referred to as chain-of-thought reasoning.
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases. Before that, let’s briefly examine what the o1 models are, how they perform compared to GPT-4o, and the new features OpenAI introduced with this series.
Brief Introduction to o1 Models
OpenAI has introduced three variants in the o1 series: o1-preview, o1, and o1-mini, with o1-preview being the first to launch. All three variants share a unique feature compared to other OpenAI models like GPT-4: advanced reasoning capabilities.
The o1 models are designed to spend more time analyzing a problem before generating an answer. This approach mimics how humans dissect and solve complex issues. For any given problem, these models attempt to break down the question, articulate their thought process step-by-step, and explore alternative solutions if their initial reasoning is inadequate.
Since these models are entirely closed-source, explicit details about their training process remain unavailable. However, there are two likely approaches used during the training of o1 models: chain-of-thought (CoT) prompting and reinforcement learning (RL).
The concept behind CoT prompting is straightforward. Instead of giving the model the direct answers for given problems, CoT prompts include detailed contextual steps for solving the problems, as you can see below:
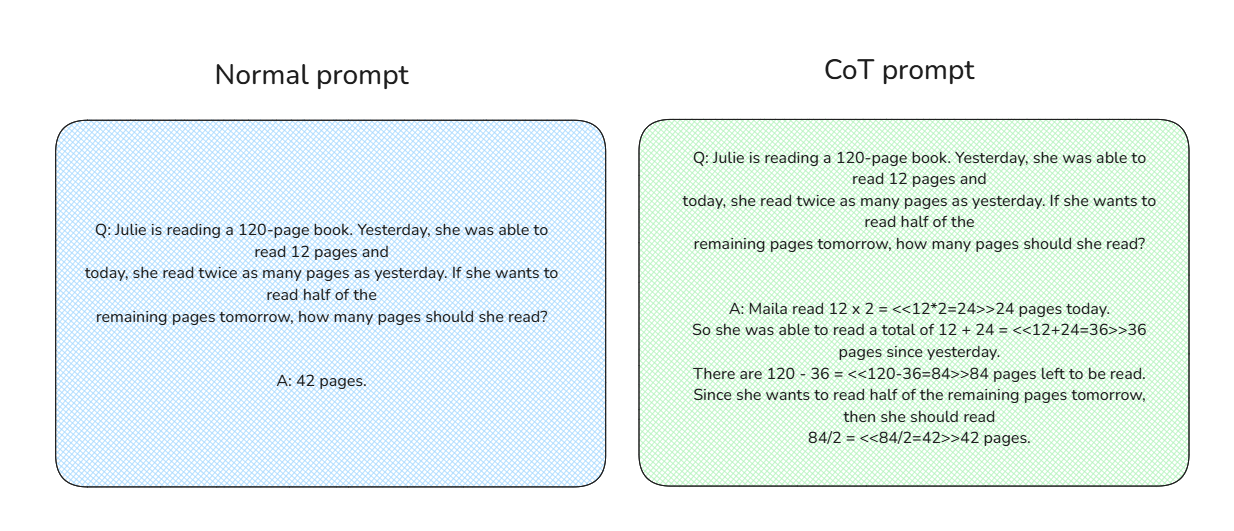
Comparison between normal prompt and CoT prompt.
By combining a massive amount of CoT prompting data with RL during fine-tuning, the model iteratively refines its reasoning process. It learns to identify flaws in its logic and adopt more sensible approaches to problem-solving. The model is then rewarded for generating accurate reasoning steps and correct answers. As a result, the o1 series models can think critically and reason effectively before providing answers.
To implement this reasoning capability, OpenAI introduced additional tokens called "reasoning tokens" in the o1 models. Unlike other LLMs that use only input and output tokens, o1 models utilize reasoning tokens to facilitate their thought process.
These reasoning tokens allow the model to analyze prompts and consider multiple approaches before generating output tokens. Once an answer is finalized, the reasoning tokens are discarded from context. Below is a visualization of the dynamics of input, output, and reasoning tokens during multiple rounds of user-model interactions:
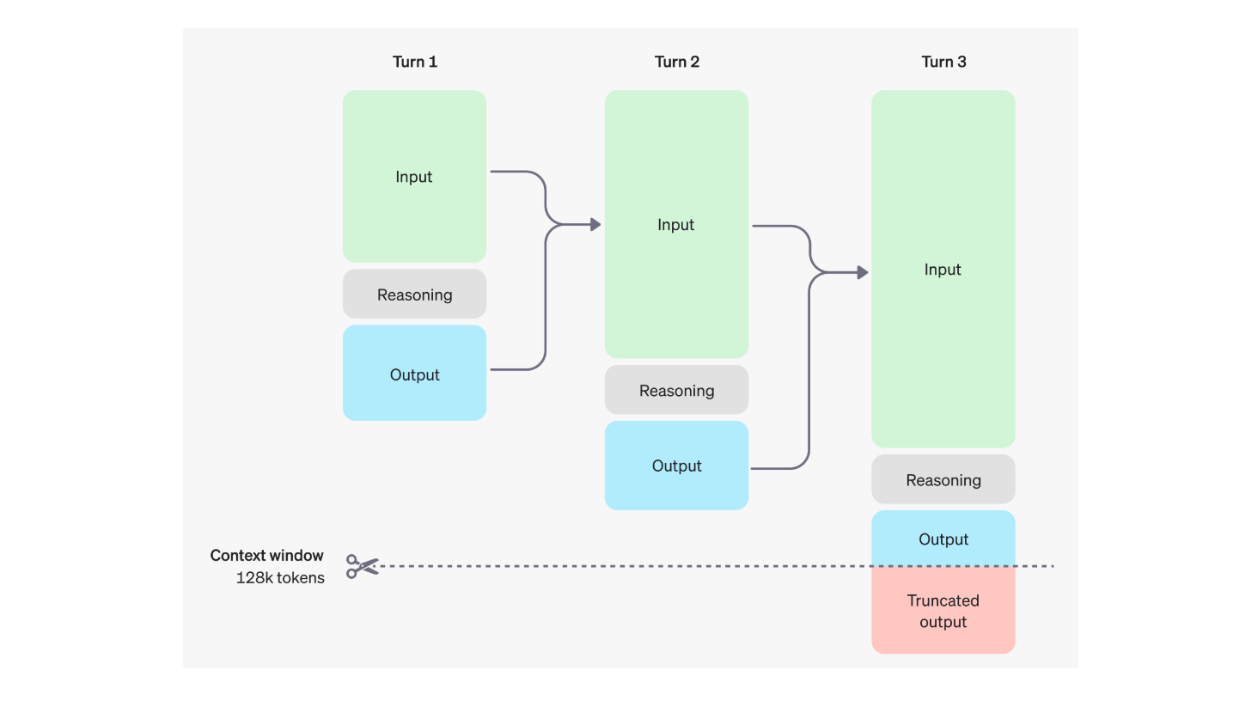
The dynamics of input, output, and reasoning tokens during multiple rounds of user-model interaction. Source.
What Makes o1 Unique (and Why It Matters to Developers)
In essence, the o1 models build upon everything that makes GPT-4o great, but push the boundaries further by combining chain-of-thought (CoT) and reinforcement learning (RL) approaches. As a result, the o1 models outperform GPT-4o in various domains requiring complex reasoning, such as coding, mathematics, and general science.
As illustrated in the visualization below, both the o1-preview and o1 models surpass GPT-4o across benchmarks that demand advanced reasoning. Specifically, they perform significantly better on three key scientific reasoning benchmarks: AIME 2024, Codeforces, and GPQA Diamond.
AIME 2024: A benchmark based on math exams designed to test the brightest high school math students in the U.S.
GPQA Diamond: Measures expertise in science subjects like chemistry, biology, and physics.
Codeforces: Includes challenges from competitive programming contests.
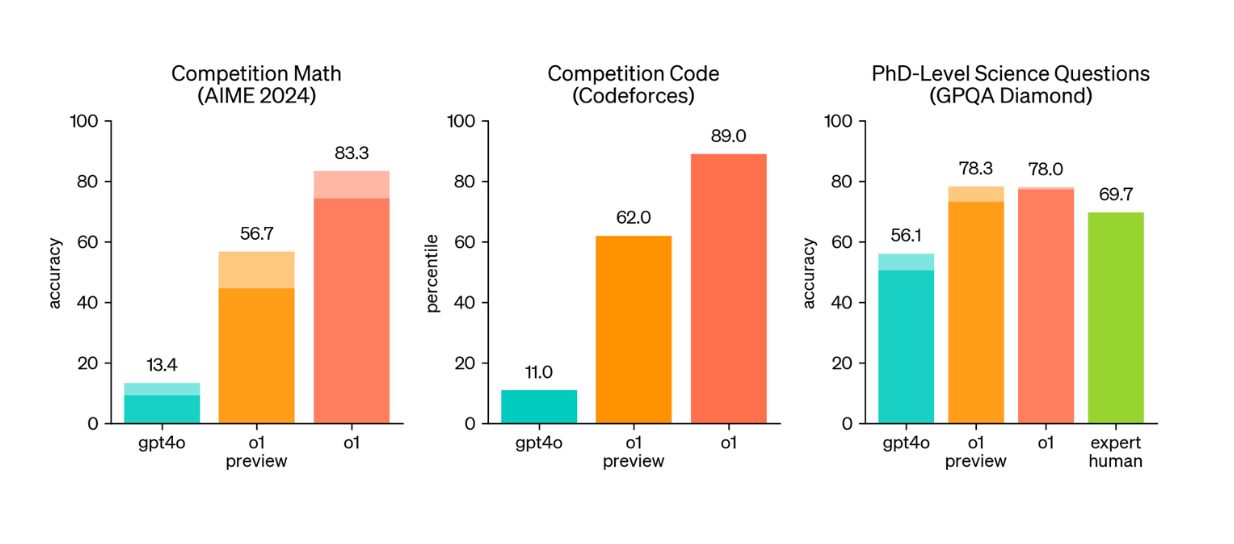
Comparison between GPT-4o, o1-preview, and o1 model on several reasoning benchmarks. Source.
While the o1-preview model demonstrates superior performance in complex reasoning tasks compared to GPT-4o, it has notable drawbacks:
High Reasoning Token Usage: The o1-preview generates a large number of reasoning tokens, which consume a significant portion of the model's 128,000-token context window. For tasks requiring extensive input-output tokens, responses may be truncated. This also increases usage costs compared to GPT-4o.
Latency Issues: The high number of tokens contributes to slower response times. On average, the latency of o1-preview is approximately 10 times slower than GPT-4o, making it less ideal for production use.
To address these limitations, OpenAI introduced two additional models in the o1 series: o1-mini and the latest o1 model.
The o1-mini is a smaller model compared to o1-preview and is specifically optimized for STEM-related data. This optimization allows it to outperform o1-preview on scientific benchmarks such as AIME 2024 (achieving 70% accuracy compared to o1-preview's 44.6%) and Codeforces.
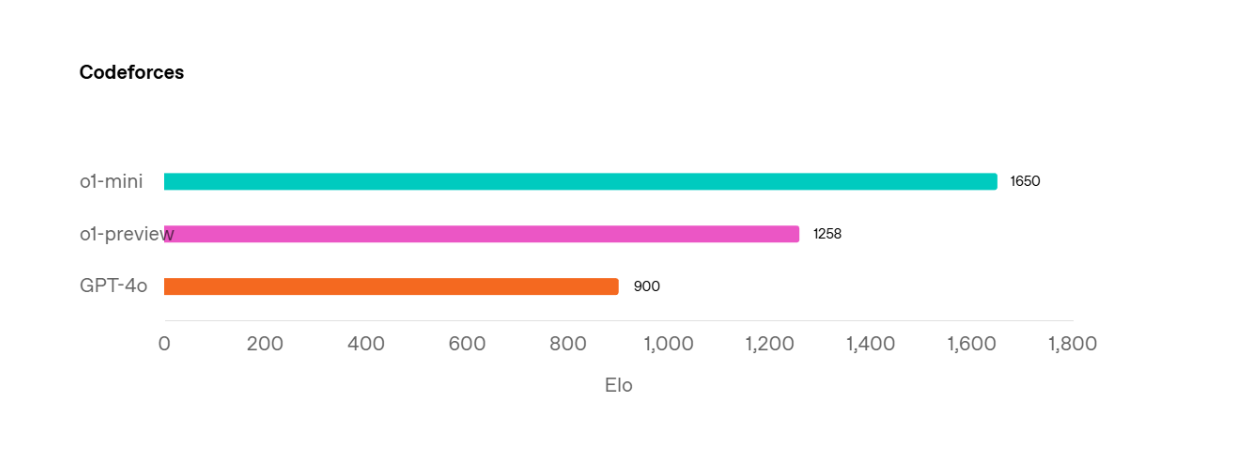
Comparison between GPT-4o, o1-preview, and o1-mini model on Codeforces benchmarks. Source.
Additionally, being smaller than o1-preview results in faster latency for o1-mini. The inference time for this model is approximately 3–5 times faster than that of o1-preview. However it’s important to note that the performance of o1-mini is still worse than o1-preview on non-STEM benchmarks.
To further enhance performance and capabilities, OpenAI introduced the latest version of the o1 model. As shown in the visualization above, this model surpasses o1-preview across all scientific benchmarks.
Beyond stronger performance on complex reasoning tasks, the latest o1 model also offers several key improvements:
Larger Context Window: Supports up to 200,000 tokens for input and a maximum of 100,000 output tokens.
Efficient Reasoning Token Usage: Uses on average around 60% fewer reasoning tokens than o1-preview for any given request. This makes the latency of the latest o1 models better than o1 preview.
Vision Capabilities: Accepts images as inputs, enabling reasoning over visual data. Note that this feature is not available in either o1-preview or o1-mini models.
Enhanced Integration with OpenAI Tools: Includes functionality for structured outputs, function calling, and developer-defined styles or tones. Additionally, users can adjust reasoning effort (low, medium, or high) using the
reasoning_effortparameter to balance speed, cost, and quality.
Real-World Use Cases of o1 Models
There are many real-world use cases that we can solve by using the o1 series. In this section, we’ll walk you through several examples, such as complex problem reasoning, information extraction and deduction from texts, Retrieval Augmented Generation (RAG), image understanding, and function calling.
However, at the time of writing this article, the availability of the latest o1 model is still limited, as it's only available for certain user tiers. Therefore, we’ll demonstrate the code snippets for the use cases using the o1-mini model whenever possible, since this model is accessible to the most of user tiers (Tier 1 through 5).
Before we proceed into the examples, we need to set our OpenAI API key first. You can learn more about how to set up your own API key here. Next, put the API key as part of the environment as follows:
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
And now we’re ready to use the models from OpenAI.
Complex Problem Reasoning
The most straightforward application of the o1 model is to solve complex problems in mathematics and coding that require in-depth thinking before we can arrive at an answer. Let's say we want it to teach us how to solve a math problem; we can do so by calling the OpenAI API as follows:
from openai import OpenAI
client = OpenAI()
prompt = """
Julie is reading a 120-page book. Yesterday, she was able to read 12 pages and
today, she read twice as many pages as yesterday. If she wants to read half of the
remaining pages tomorrow, how many pages should she read?
"""
response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
)
print(response.choices[0].message.content)
"""
Output:
To determine how many pages Julie should read tomorrow, let's break down the problem step by step:
1. **Total Pages in the Book:**
The book has **120 pages**.
2. **Pages Read Yesterday:**
Julie read **12 pages** yesterday.
3. **Pages Read Today:**
Today, she read **twice** as many pages as yesterday.
( 2 times 12 = 24 ) pages.
4. **Total Pages Read in Two Days:**
( 12 text{ (yesterday)} + 24 text{ (today)} = 36 ) pages.
5. **Remaining Pages:**
( 120 text{ (total)} - 36 text{ (read)} = 84 ) pages left.
6. **Pages to Read Tomorrow:**
She wants to read **half** of the remaining pages:
( frac{84}{2} = 42 ) pages.
**Answer:**
Julie should read **42 pages** tomorrow.
"""
As you can see, instead of just providing the final answer, the model generates its step-by-step thought process, which enhances our understanding of how to approach similar problems in the future.
Creative Automations
As with other LLMs from OpenAI, the o1 model can be used for creative automation, such as summarizing the content of a PDF, generating a YouTube script from an article, and extracting and deducing particular information from documents.
In the following example, we’ll use the o1-mini model to extract particular information from a text with a specific output schema. Not only will we extract information contained in the text, but we'll also ask the model to deduce information by performing simple mathematical operations.
import requests
def fetch_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
url = "<https://en.wikipedia.org/wiki/List_of_NBA_career_scoring_leaders>"
html_content = fetch_html(url)
json_format = """
{
companies: [
{
"player_name": "Tim Duncan",,
"total_points": "1750",
"total_points_without_free_throw": "1050",
}
]
}
"""
o1_response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": f"""
Extract information from the text.
- Read the following html and return players with the most points without free throw in the NBA's history: {html_content}.
- Return the result in order from the highest to lowest, and show me the top 5. Return only as a JSON with the following format: {json_format}"
"""
}
]
)
print(o1_response.choices[0].message.content)
"""
Output:
```json
{
"players": [
{
"player_name": "LeBron James",
"total_points": "41599",
"total_points_without_free_throw": "33048"
},
{
"player_name": "Kareem Abdul-Jabbar",
"total_points": "38387",
"total_points_without_free_throw": "31675"
},
{
"player_name": "Karl Malone",
"total_points": "36928",
"total_points_without_free_throw": "27141"
},
{
"player_name": "Wilt Chamberlain",
"total_points": "31419",
"total_points_without_free_throw": "25362"
},
{
"player_name": "Kobe Bryant",
"total_points": "33643",
"total_points_without_free_throw": "25265"
}
]
}
"""
As you can see, the o1 model not only extracts the information according to the output schema that we defined, but it’s also able to perform mathematical operations and include the appropriate result in the output schema along with other extracted information.
AI-Powered Search Engines
We can also use the o1 model in a Retrieval Augmented Generation (RAG) setting, where we use it to generate a response to a query based on provided context obtained via similarity search.
The usual workflow of a RAG application is as follows: given a user query, the query is transformed into an embedding using an embedding model of our choice, such as text-embedding-3-large from OpenAI. Next, the query embedding is compared with a collection of context embeddings stored inside a vector database via similarity search. The top-k most relevant contexts are then fetched and added to the prompt, providing our LLM with helpful context to answer the query.
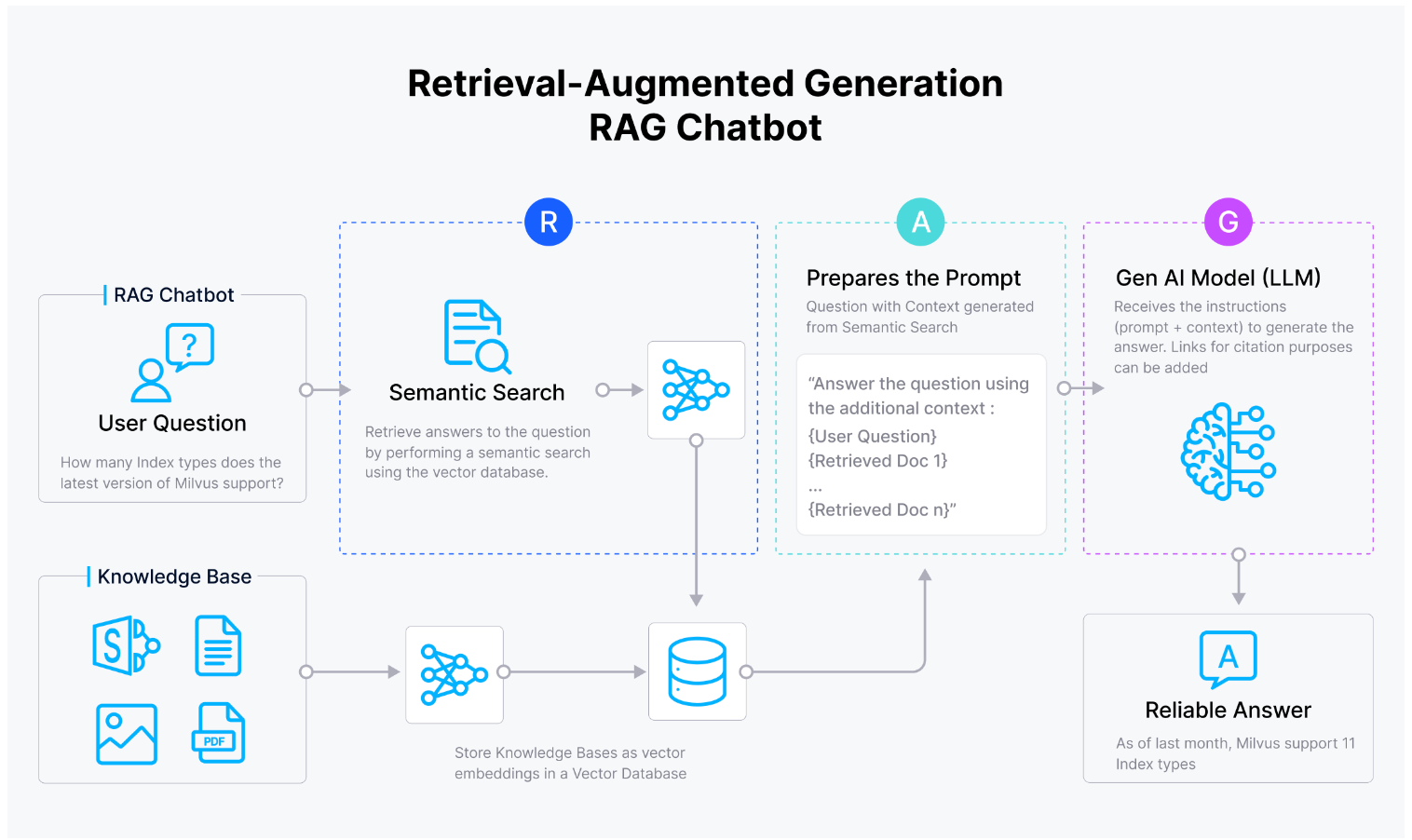
RAG workflow.
As you can see, to use the o1 model in a RAG use case, we typically combine it with vector databases, such as Milvus, to store massive amounts of context and perform efficient and fast similarity searches.
In the example below, we’ll create a simple RAG application using the combination of the o1-mini model and Milvus.
First, we load the text source from HTML, which we’ll use as possible contexts in our RAG application. Next, we split the original text into chunks, each consisting of approximately 2000 characters. After the chunking process, we can store all of the chunks inside the Milvus vector database. We’ll set the indexing type to "FLAT" since we want to conduct an exhaustive search to find the best possible contexts for any given query.
!pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
# Create a WebBaseLoader instance to load documents from web sources
loader = WebBaseLoader(
web_paths=(
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# Load documents from web sources using the loader
documents = loader.load()
# Initialize a RecursiveCharacterTextSplitter for splitting text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
# Split the documents into chunks using the text_splitter
docs = text_splitter.split_documents(documents)
# Define the default embedding model from OpenAI
embeddings = OpenAIEmbeddings()
# Store the chunked data into Milvus
vectorstore = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={
"uri": "./milvus_demo.db",
},
index_params={"index_type": "FLAT", "metric_type": "L2"},
drop_old=True, # Drop the old Milvus collection if it exists
)
Now we can define the model and the prompt, which contains instructions like "Use the provided context to answer the query," as well as the query itself. We’ll fetch the top-1 most relevant context as a result.
from langchain_openai import ChatOpenAI
from langchain import hub
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(model_name="o1-mini", temperature=1)
# Define the prompt template for generating AI responses
prompt = hub.pull("rlm/rag-prompt")
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
query = "What is self-reflection of an AI Agent?"
vectorstore.similarity_search(query, k=1)
Finally, we can easily orchestrate the RAG workflow with LangChain and then obtain the response from our o1-mini model to any given query using the most relevant context fetched from our Milvus database.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Define a function to format the retrieved documents
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# rag_chain.get_graph().print_ascii()
# Invoke the RAG chain with a specific question and retrieve the response
res = rag_chain.invoke(query)
print(res)
"""
Output:
Self-reflection in an AI agent refers to its ability to evaluate and refine its own actions and decisions based on past experiences. This process allows the agent to identify and correct mistakes, thereby improving its performance over time. It is essential for handling complex, real-world tasks where iterative improvement through trial and error is necessary.
"""
Image Understanding
One of the main advantages of the latest o1 model compared to o1-preview and o1-mini is its multimodal capability—it accepts not only text as input but also images. This makes the o1 model ideal for image reasoning use cases, such as describing the content of an image, summarizing text in an image, and extracting structured information from an image.
There are two ways we can provide the model with an image input: by passing the link to the image or by passing the Base64 encoded image. Below is the example code to do so:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url",
"image_url": {
"url": "<https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg>",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
Function Calling
Another exciting use case we can explore with the o1 model is function calling. In essence, function calling enables the LLM to interact with our code or external services, such as a search engine or an API. With its ability to think through a problem, it can accurately use the appropriate external services to help it solve the task at hand.
As an example, let’s say we want to know the current weather in Los Angeles. Without external services, it would be impossible for the LLM to give us the correct answer, and it’s likely to start hallucinating. If we have access to the weather API, we can use this "tool" as an additional resource to help our o1 model answer our query.
You can learn more about the code implementation of function calling to create an agentic model in the documentations provided by OpenAI or LangChain.
Comparison Between o1 Model and its Alternatives
In this section, we’ll compare the pros and cons of the o1 model with its alternatives, such as GPT 4o, o3-mini, Claude 3.5 Sonnet, and DeepSeek R1.
Comparison with GPT 4o
Although the performance of the o1 model is far superior to the GPT-4o model on complex reasoning benchmarks, that doesn't mean we should always choose the o1 model over GPT-4o.
Overall, the o1 model excels at tasks that require complex and detailed thinking processes, such as ideation tasks. For example, we can use the o1 model as a partner to help us plan strategies and outline best and worst-case scenarios for a business we're about to start. In the educational field, we can use the o1 model to generate detailed explanations for each component of a scientific course we're developing. We can also utilize the o1 model as our partner during code reviews or for code optimization.
However, when we want to deploy an AI assistant in production, GPT-4o is currently still preferred over the o1 model. This is because GPT-4o is much more mature in terms of OpenAI's API implementation compared to the o1 model. For example, while both GPT-4o and the o1 model accept images as inputs, the o1 model doesn't have access to several tools and features, such as custom instructions, file uploads (except images), voice capabilities, and web browsing. Therefore, if our use case requires these features, we need to use GPT-4o.
Moreover, the availability of the o1 model is limited as of now. Only certain users have access to the model, as we should at least be a Tier 3 user or subscribe to ChatGPT Plus or Pro plan to be able to access this model. Also, if inference latency is very critical in our use case, GPT-4o still offers a better alternative than the o1 model.
Comparison with o3-mini
The o3-mini model is the latest model in OpenAI’s reasoning LLMs. Same as the o1-mini, the o3-mini has been highly optimized in the STEM domains, but with performance that is superior than o1-mini and comparable to the o1 model, as you can see in the performance graph across different STEM benchmarks as shown below:

Performance comparison between o3-mini and o1 model across different STEM benchmarks. Source.
The o3-mini keeps everything that makes the o1-mini great (low cost and latency) and improves further upon it. Therefore, if your use case is within the STEM domain and the latency or cost is critical, then the o3-model would be more preferable than the o1 model. However, the o1 model still offers broader knowledge than the o3-mini, which makes it more suitable to use if your use case is more general and not in the STEM domain.
Both o3-mini and o1 model support advanced API features like function calling, structured output, developer messages, as well as adjustable reasoning effort. However, the o3-mini currently supports text-only input, meaning that if the input of our use case is an image, then we need to use the o1 model.
Regarding availability through API, as of now, both o3-mini and o1 models are available only for users in Tier 3-5. You can use both models if you’re subscribed to ChatGPT Plus, Pro, and Team.
Comparison with DeepSeek R1 and Claude 3.5 Sonnet
Other alternatives to the o1 model include Claude 3.5 Sonnet and DeepSeek R1. Out of these two, DeepSeek R1 is a closer competitor to o1 due to its reasoning optimization during training, while Claude 3.5 Sonnet was not really optimized for reasoning. As you can see on several reasoning benchmarks below, both o1 and R1 outperform 3.5 Sonnet by considerable margin. Meanwhile, the performance of o1 and R1 are comparable to each other.

Comparison between o1 model and other representative models. Source.
Therefore, it’s recommended to use either o1 or R1 when your use case needs reasoning capability from the LLM. If not, Claude 3.5 Sonnet would be preferable since it would yield to both lower cost and better latency than the o1 model.
Now let’s say that our use case requires the reasoning capability from our LLMs, which means that we can use either o1 or R1 models. The main advantage of the R1 model is its open-source nature, meaning that we can host it in our own infrastructure. This is very beneficial if data privacy is a concern in our use case.
In terms of latency, R1 might be better than o1 due to its Mixture-of-Expert (MoE) architecture. Thanks to MoE, only a small fraction of R1’s parameters will be activated in any given request, which speeds up the inference process. Also, R1 adopts a multi token prediction approach during training, which can be repurposed to speculative decoding during inference. This further speeds up the inference process.
However, it’s important to note that DeepSeek R1 contains in total 671B parameters, which means you need roughly 1.5 TB of GPU memory (e.g., NVIDIA A100 80GB x16) to host it. Therefore, it’s very expensive to host the model on our own, and using the o1 model would be more preferable to save us from the complicated steps of hosting R1.With o1, we only need to pay when we make the API request. This ends up being cheaper in most cases compared to the per hour GPU cost that we need to pay when hosting the R1 model on popular cloud providers like AWS or GCP.
Conclusion
The o1 model represents an advancement in AI reasoning capabilities, as it improves upon GPT-4o by integrating chain-of-thought prompting and reinforcement learning. With its ability to break down complex problems and explore alternative solutions, the o1 model excels in tasks requiring deep analytical thought, such as STEM-related or coding tasks. Also, the latest o1 model enhances efficiency with a larger context window, multimodal capabilities, and optimized reasoning token usage.
However, despite its strengths, adopting the o1 model over its alternatives still totally depends on specific use case requirements. The o1 model outperforms GPT-4o in complex reasoning tasks but in terms of cost, latency, and API maturity, GPT-4o is more preferable. Compared to o3-mini, o1 offers broader general knowledge, while o3-mini is more efficient for STEM applications with lower cost and latency. Against DeepSeek R1 and Claude 3.5 Sonnet, o1 and R1 excel in reasoning, but R1's open-source nature and Mixture-of-Expert architecture improve latency, though it requires costly infrastructure.
Tutorials using OpenAI GPT-o1
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and OpenAI text-embedding-3-small
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and NVIDIA embed-qa-4
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and Cohere embed-multilingual-v3.0
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and Ollama mxbai-embed-large
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and HuggingFace all-MiniLM-L12-v1
Keep Reading

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.