




Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
Not too long ago, AWS dropped something new: S3 Vectors. It’s their first attempt at a vector storage solution, letting you store and query vector embeddings for semantic search right inside Amazon S3.
At a glance, it looks like a lightweight vector database running on top of low-cost object storage—at a price point that is clearly attractive compared to many dedicated vector database solutions.
 amazon s3 vectors.png
amazon s3 vectors.png
Naturally, this sparked a lot of hot takes. I’ve seen folks on social media and in engineering circles say this could be the end of purpose-built vector databases—Milvus, Pinecone, Qdrant, and others included. Bold claim, right?
As the engineering architect of Milvus and someone who’s spent way too many late nights thinking about vector search, I have to admit that: S3 Vectors does bring something interesting to the table, especially around cost and integration within the AWS ecosystem. But instead of “killing” vector databases, I see it fitting into the ecosystem as a complementary piece. In fact, its real future probably lies in working with professional vector databases, not replacing them.
In this post, I’ll walk you through why I think that—looking at it from three angles: the tech itself, what it can and can’t do, and what it means for the market.
A Surprising Fact: Vector Storage Can Cost More Than LLM Calls
Vector search is powerful, but it comes with a serious catch: it’s expensive. The computational demands are often one to two orders of magnitude higher than what you’d see in a typical NoSQL database. That gap isn’t just theoretical—it shows up in real bills.
I recently spoke with the CTO of a popular AI note-taking app who told me something surprising: they spend twice as much on vector search as they do on OpenAI API calls. Think about that for a second. Running the retrieval layer costs them more than paying for the LLM itself. That flips the usual assumption on its head.
The 2022 ChatGPT boom only made this more obvious. Suddenly, embeddings were everywhere, and vector data became the fastest-growing data type on the public cloud. Retrieval-Augmented Generation (RAG) was the driver—and with it came three challenges that reshaped what a vector database like Milvus had to do:
Massive data explosion: Workloads jumped from tens of millions to tens of billions of vectors almost overnight. That’s not linear growth—it’s a quantum leap, and it broke the old ways of handling data.
Latency tolerance shifted: Since LLMs take time to generate responses anyway, users became more forgiving of slightly slower retrieval. The “sub-10ms recall at all costs” mindset suddenly mattered less.
Cost sensitivity skyrocketed: Doubling or tripling data volume wasn’t just a storage problem; it became a financial crisis if you tried to scale using traditional compute-heavy designs.
In short: vector databases had to evolve fast, not because the technology didn’t work, but because the economics of retrieval were suddenly front and center.
The Evolution of Vector Storage: From Memory to Disk, and Now to Object Storage
The pressure around cost and scale forced one conclusion: vector databases couldn’t stay memory-only forever. They had to evolve—first to disk, and now to object storage like S3. This wasn’t a choice; it was an industry inevitability. And if you’ve been following the space, you’ve probably noticed the same trend I have over the last few years.
I’ve seen vector databases go through three distinct stages:
Phase I (2018–2022): The Pure Memory Era: In the early Milvus days, we leaned on memory indexes like HNSW and IVF. The performance and recall were fantastic—but the costs were brutal. Memory doesn’t scale cheaply, and everyone paying those cloud bills knew it.
Phase II (2022–2024): The Disk Index Revolution: To break the memory bottleneck, we pioneered a disk-based approach using DiskANN along with our proprietary Cardinal index (exclusive to Zilliz Cloud, the managed Milvus). With tricks like asynchronous I/O (AIO) and io_uring, we managed to squeeze real performance out of disks. The result? A 3–5x cost reduction. Our capacity-optimized compute units (CUs) quickly became bestsellers in Zilliz Cloud.
Phase III (2024– ): The Tiered Storage Era: The next step was obvious: push vector indexes onto cheap object storage. New players like TurboPuffer went all-in on S3, dropping storage costs to ~$0.33/GB/month—a 10x reduction. But the trade-off was just as clear: cold query latency in the 500ms–1s range, and weaker recall precision.
At Zilliz, we’ve been working on tiered storage for a while, but we held back release until we could tame cold query performance. Next month, we’ll be rolling out our upgraded extended-capacity CUs with true hot/cold separation in Zilliz Cloud. That means stable cold query latency under 500ms, paired with ultra-high QPS for hot queries. In other words, the best of both worlds.
Amazon S3 Vectors Arrives Right on Cue
With tiered storage already proving itself, it’s no surprise that AWS jumped in with S3 Vectors. In fact, the release feels like a natural extension of what was already happening across the industry. Amazon had been expanding S3’s role with features like S3 Tables, evolving it from “just object storage” into a multi-modal cold storage backbone. Vectors are simply the next modality in that evolution—and it probably won’t stop there. Graphs, key-value, and time series data could all follow the same path.
And Amazon brings three undeniable advantages to the table:
Lower cost: among the lowest storage pricing in the industry.
Massive scale: AWS’s machine pools can absorb almost any query load.
Microservice-native architecture: perfectly aligned with vector indexing’s write–build–query workflow.
Put together, these give S3 Vectors the makings of an ultra-low-cost, highly scalable cold storage solution for vectors.
S3 Vectors is A True Price Killer, But With Clear Limits
As soon as S3 Vectors was announced, our team put it through comprehensive tests. The results were eye-opening—not just in terms of how cheap it is, but also where the cracks start to show.
S3 Vectors is A True Price Killer
There’s no denying it: S3 Vectors is incredibly cost-effective.
Storage runs at just $0.06/GB, roughly 5 times cheaper than most serverless vector solutions. For a representative workload—say 400 million vectors plus 10 million queries per month—the bill comes out to about $1,217/month. That’s more than a 10x reduction compared to traditional vector databases. For low-QPS, latency-tolerant workloads, it’s almost unbeatable.
But Performance Has Real Constraints
Collection size limits: Each S3 table maxes out at 50M vectors, and you can only create up to 10,000 tables.
Cold queries: Latency comes in at ~500ms for 1M vectors and ~700ms for 10M vectors.
Hot queries: Latency stays under 200ms at 200 QPS, but pushing beyond that 200 QPS ceiling is tough.
Write performance: Capped at under 2MB/s. That’s orders of magnitude lower than Milvus (which handles GB/s), though to its credit, writes don’t degrade query performance. Translation: it’s not designed for scenarios with large, frequently changing datasets.
Precision and Functionality Trade-Offs
The precision story is where things get tricky. Recall hovers at 85–90%, and you don’t get knobs to tune it higher. Layer on filters, and recall can drop below 50%. In one test where we deleted 50% of data, TopK queries asked for 20 results but could only return 15.
Functionality is also pared down. TopK queries max out at 30. Metadata per record has strict size limits. And you won’t find features like hybrid search, multi-tenancy, or advanced filtering—all of which are must-haves for many production applications.
Dissecting S3 Vectors: The Likely Architecture
After running tests and mapping them against familiar AWS design patterns, we’ve formed a pretty good hypothesis of how S3 Vectors works under the hood. While Amazon hasn’t published full details, the performance characteristics point to five core technologies:
SPFresh Dynamic Indexing: Instead of rebuilding entire indexes after each write, S3 Vectors seems to update only the affected portions. This design keeps write costs low and availability high, but it comes at a price: recall rates slip by a few percentage points after updates.
Deep Quantization (4-bit PQ): To cut down on S3’s I/O overhead, embeddings are likely compressed using 4-bit product quantization.
The upside: storage is cheap, and queries stay fast.
The downside: recall flatlines around ~85%, and there are no knobs for developers to tune it higher.
Post-Filter Mechanism: Filtering looks to be applied after coarse retrieval. That keeps the index unified and simple, but it struggles with complex conditions. In our tests, when we deleted 50% of data, TopK queries requesting 20 results returned only 15—classic signs of a post-filter pipeline. This also suggests Amazon leaned heavily on existing open-source index designs rather than building a custom one from scratch.
Multi-Tier Caching: Hot queries behave much faster, likely thanks to an SSD/NVMe cache sitting in front of S3. But when a query misses the cache, latency jumps significantly. That pattern fits a multi-tier cache hierarchy built to mask object storage’s inherent slowness.
Large-Scale Distributed Scheduling: AWS has no shortage of machine pools. S3 Vectors appears to spread the workload across microservices, pipelining the read → decompress → search flow. The result is what we observed in tests: a remarkably stable latency distribution, even under heavy load.
Where S3 Vectors Fits: The Right Tool for Specific Jobs
After putting S3 Vectors through its paces, it’s clear that it shines in some scenarios and falls short in others. Like most infrastructure tools, it’s not a one-size-fits-all solution—it’s the right tool for the right job.
Where It Works Well
Cold data archiving: Perfect for storing history datasets that are rarely accessed. If you can live with 500ms+ query times, the cost savings are unbeatable.
Low-QPS RAG queries: Think of small internal tools or chatbots that run only dozens of queries per day, staying under 100 QPS. For these use cases, latency isn’t a dealbreaker.
Low-cost prototyping: Great for proof-of-concept projects where the goal is to test an idea without spending heavily on infrastructure.
Where It Struggles
High-performance search and recommendation: If your application needs sub-50ms latency, S3 Vectors simply isn’t built for it.
High-volume writes or frequent updates: Performance degrades quickly, and recall precision drops noticeably under heavy churn.
Complex query workloads: There’s no support for hybrid search, aggregations, or other advanced querying features.
Multi-tenant production apps: With a hard cap of 10,000 buckets, it’s not designed for large-scale multi-tenant deployments.
In other words, S3 Vectors is excellent for cold, cheap, low-QPS scenarios—but it’s not the engine you want to power a recommendation system, a real-time search app, or any high-scale production system.
The Future is Tiered Vector Storage
S3 Vectors doesn’t spell the end of vector databases—it confirms something many of us have been seeing for a while: the future is tiered storage. Instead of keeping every vector in expensive memory or fast disk, workloads will naturally spread across hot, warm, and cold tiers based on how often it’s accessed and what kind of latency the application can tolerate.
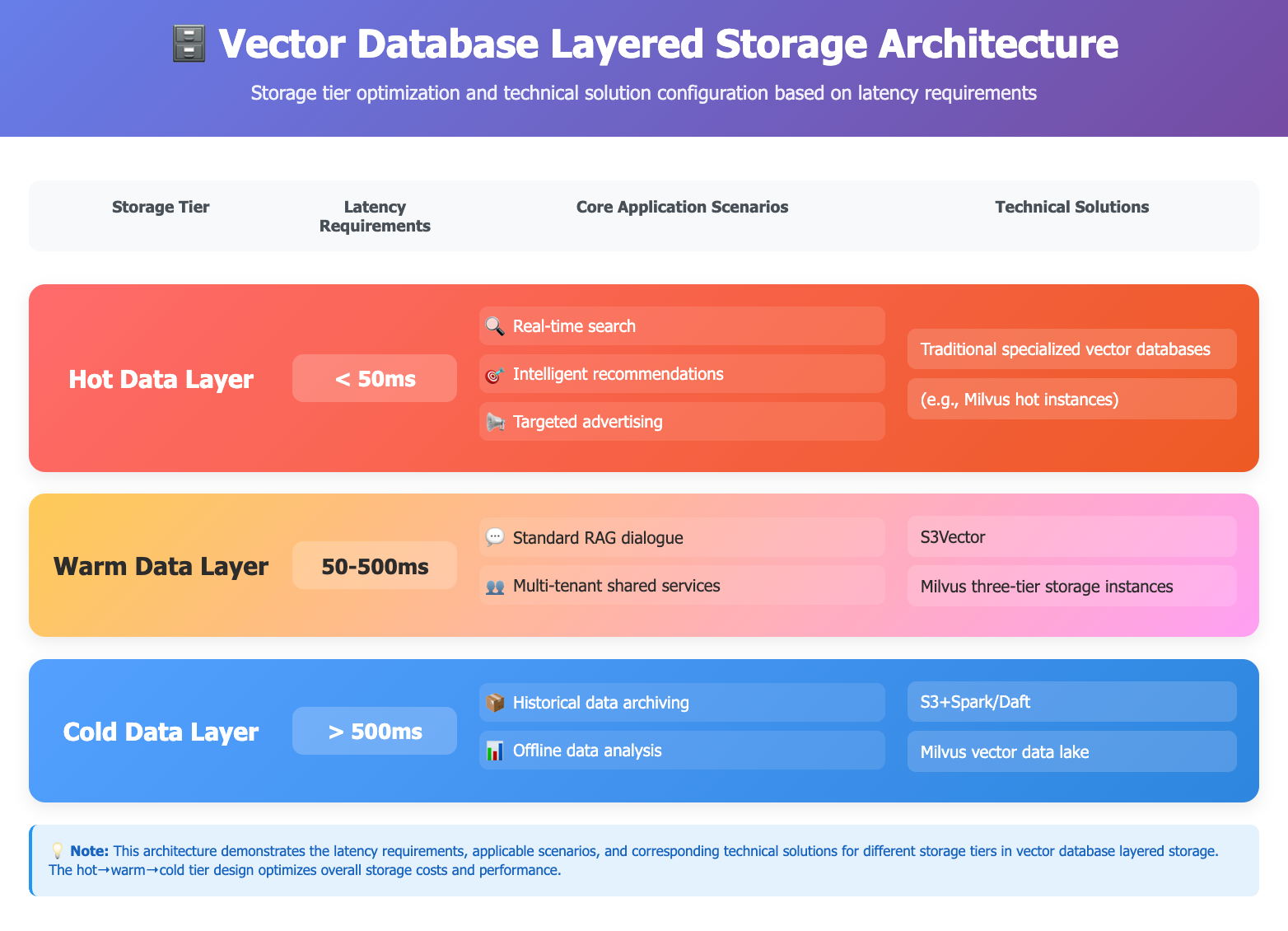
Here’s what that looks like in practice:
Hot Data Layer (<50ms) – This is where real-time search, recommendations, and targeted ads live. Latency needs to be under 50ms, which means specialized vector databases are still the best option. They’re optimized for both blazing speed and high query throughput.
Warm Data Layer (50–500ms) – Many RAG-based applications and multi-tenant shared services fall here. These workloads don’t need ultra-low latency, but they do need predictable performance at lower cost. S3 Vectors and Milvus’s tiered storage instances fit this middle ground.
Cold Data Layer (>500ms) – Historical archives and offline analysis don’t require real-time responses, so latency in the hundreds of milliseconds is acceptable. What matters here is cost efficiency at massive scale. This is where solutions like S3 + Spark/Daft or the Milvus vector data lake shine.
The hot–warm–cold split balances latency, cost, and scale in a way that no single storage tier can cover on its own. It’s a pattern we’ve seen before in relational databases, data warehouses, and even CDNs—and vector storage is now following the same trajectory. This three-tier architecture also lines up closely with the roadmap we’ve been building for Milvus and Zilliz Cloud.
1. A Unified Online + Offline Processing Architecture
AI applications don’t live neatly in separate “online” and “offline” worlds. In reality, data moves constantly between the two. That’s why with the upcoming Milvus 3.0, we will introduce a vector data lake, designed to support both real-time retrieval and offline processing from the same dataset.
In practice, this means one dataset can power your live RAG and search queries, while also feeding into Spark-based offline analysis—for example, curating training data for LLMs. No duplication, no juggling two different pipelines.
We will also roll out the StorageV2 format for the vector data lake, which takes the economics to another level:
Up to 100x cheaper for cold data storage.
Up to 100x faster than brute-force Spark queries on hot data.
The result is a unified system that minimizes redundancy, keeps costs under control, and makes working with vector data a lot less painful.
2. Building Features AI Developers Actually Need
Over the past two years, AI applications have been moving fast—and so have the requirements for the infrastructure behind them. At Zilliz, we’ve pushed Milvus forward in step with those needs, shipping capabilities like BM25 + vector hybrid search, multi-tenant isolation, hot–cold tiered storage, and MinHash deduplication, along with a long list of developer-focused improvements.
Our philosophy has been simple: when you combine deep understanding of business use cases with the latest technology, you unlock entirely new infrastructure possibilities. That’s the mindset shaping Milvus 3.0, which will bring a new wave of AI-native features designed directly for real-world applications. Among them:
Keyword weighting in search – So a query like “red phone” can prioritize red appropriately.
Geolocation support – Store and query location-aware vectors to handle prompts like “find nearby coffee shops.”
Multi-vector support for RAG – Attach multiple embeddings to each text, improving recall and accuracy in complex retrieval tasks.
Flexible UDF processing – User-defined functions for richer, customizable data processing.
Visual analytics tools – Deeper offline mining and data exploration at scale.
And that’s just the start. The bigger point is that Milvus is evolving into a system that’s not only efficient and scalable, but AI-native at its core—purpose-built for how modern applications actually work.
3. Engineering for Scale Without the Price Tag
At Zilliz, we believe that: a 10x cost reduction opens the door to 100x more application use cases. That principle has guided every big milestone in Milvus. Since 2022, we’ve introduced disk-based indexes, GPU acceleration, and RabitQ quantization—all of which have pushed query performance up by orders of magnitude while driving costs down.
Looking ahead, our focus is on squeezing even more efficiency out of the stack:
Deeper hardware optimization – Tuning for raw compute power and IOPS performance.
Smarter compression and quantization – Making vectors lighter without giving up accuracy.
Early termination for index queries – Cutting off wasted computation as soon as we have confident results.
Refined tiered indexing – Better cache utilization for faster access to cold data.
The end goal hasn’t changed: build infrastructure that just works out of the box, scales on demand, and stays both fast and affordable.
Why the Advent of S3 Vectors Is Good News for Everyone
A lot of people worry that S3 Vectors will make traditional vector databases obsolete. My take is the opposite: its release is good news for the entire industry. In fact, I see three big benefits.
It validates demand. No one can claim vectors are just a fad anymore. If AWS is building a product around it, that’s proof positive that vector storage is a real necessity—not just “indexes wrapped in a database.”
It educates the market. With AWS’s reach, more enterprises are now aware of vector databases, which expands the boundaries of what applications can be built.
It drives innovation. Competition pushes all of us—Milvus included—to optimize harder, cut costs further, and find differentiated strengths.
From a positioning standpoint, S3 Vectors looks less like a complete vector database and more like the cold tier of vector storage. Its low cost makes it especially attractive for scenarios that were previously priced out: small teams building RAG apps, individual developers experimenting, or organizations indexing massive datasets with only basic retrieval needs. That’s a real unlock for the ecosystem.
Personally, I also want to acknowledge the AWS engineering team. They’ve been steadily improving their platform—from Lambda debugging to cold start performance—and S3 Vectors is another example of thoughtful product innovation. I’m genuinely curious to see what developers will build now that the economics are this favorable.
So no, the vector database market isn’t being disrupted—it’s maturing into a tiered ecosystem where different solutions serve different performance and cost needs. That’s good for enterprises, good for developers, and good for the overall AI infrastructure stack.
The golden age of vector databases isn’t over—it’s just beginning.

Keep Reading

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.