




Catch a Cute Ghost this Halloween with Milvus
A version of this article is posted on DZone.
I just gave a talk at All Things Open and it is hard to believe that Retrieval Augmented Generation (RAG) now seems like it has been a technique that we have been doing for years.
There is a good reason for that, as over the last two years it has exploded in depth and breadth as the utility of RAG is boundless. The ability to improve the results of generated results from large language models is constantly improving as variations, improvements and new paradigms are pushing things forward.
Today we will look at:
Practical Applications for Multimodal RAG
- Image Search with Filters
- Finding the best Halloween Ghosts
Using Ollama, LLava 7B and LLM Reranking
Running Advanced Multimodal RAG Locally

I will use a couple of these new advancements in the state of RAG to solve a couple of Halloween problems. Let’s look at the problems; finding if something is a ghost and what is the cutest cat ghost?
Practical Applications for Multimodal RAG
Is something a ghost? Image Search with Filters and clip-vit-base-patch32
We want to build a tool for all the ghost detectors out there by helping determine if something is a “ghost”. To do this we will use our hosted “ghosts” collection that has a number of fields we can filter on as well as search our multimodal encoded vector. We allow someone to pass in a ghost photo via Google form, Streamlit app, S3 upload and Jupyter notebook. We encode that query which can be a combination of text and/or image by utilizing the CLIP model from OpenAI with Hugging Face’s Sentence Transformer. This lets us encode our suspected ghost image and use it to search our collection to see its similarity. If the similarity is high enough then we can consider it a "ghost".
Collection Design
Before you build any application you should make sure you have it well defined with all the fields you may need and the types and sizes that match your needs.
For our collection of “ghosts”, at a minimum we will need:
An id field that is of type INT64, set as the primary key and set to have Automatic ID generation
Next field in our schema is ghostclass which is a VARCHAR scalar string of length 20 that holds the traditional classifications of ghosts such as Class I, Class II, Fake and Class IV.
After that is category which is a larger VARCHAR scalar string of length 256 that holds our short descriptions that are classifications such as Fake, Ghost, Deity, Unstable and Legend.
We add a field for s3path which is defined as a large VARCHAR scalar string of length 1,024 that holds an S3 Path to the image of the object.
Finally and most importantly, vector, which holds our floating point vector of dimension 512.
Now that we have our data schema, we can build it and use it for ghastly analytics against our data.
Step 1: Connect to Milvus Standalone
Step 2: Load the CLIP model
Step 3: Define our collection with its schema of vectors and scalars.
Step 4: Encode our image to use for a query.
Step 5: Run the query against the ghosts collection in our Milvus standalone database and look only for those filtered by category of not Fake. We limit it to one result.
Step 6: Check the distance, if it is 0.8 or higher we will consider this a ghost. We do this by comparing the suspected entity to our large database of actual ghost photos, if something is the current class of ghost it should be similar to our existing ones.

Step 7: The result is displayed with the prospective ghost and its nearest match.

As you can see in our example we matched close enough to a similar "ghost" that was not in the Fake category.
In a separate Halloween application, we will look at a different collection and a different encoding model for a separate use case also involving Halloween ghosts.
Finding the Cutest Cat Ghost with Visualized BGE model
We want to find the cutest cat ghosts and perhaps others for winning prizes, putting on social media posts or other important endeavors.
Collection Design
Before you build any application you should make sure you have determined what fields you may need. For this simple use case we are going to have a dynamic schema with automatic id generation. This way we don’t have to define the fields and ones will be created with fields of id and vector.
For our collection of “ghostslocal”, these will automatically be created for us:
An id field that is of type INT64, set as the primary key and set to have Automatic ID generation
We have set this collection to enable dynamic fields, we will add one important one during data insertion.
Finally and most importantly, vector, which holds our floating point vector of dimension 768.
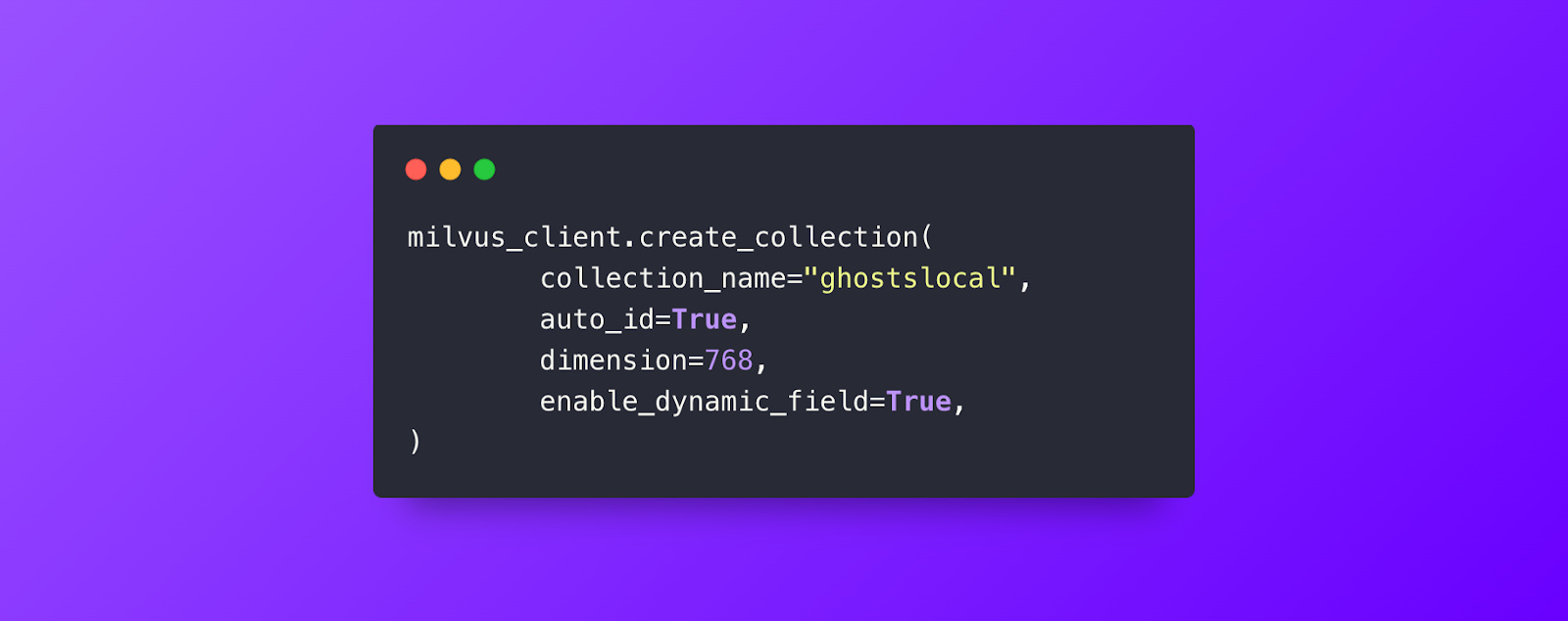
Now that we have our data schema, now we can find the cutest ghost.
Step 1: Connect to Milvus Standalone
Step 2: Load the BAAI/bge-base-en-v1.5 model
Step 3: Define our collection with its schema of vectors and scalars.
Step 4: Iterate through our list of images, encode them and add them to a dict for later insertion.
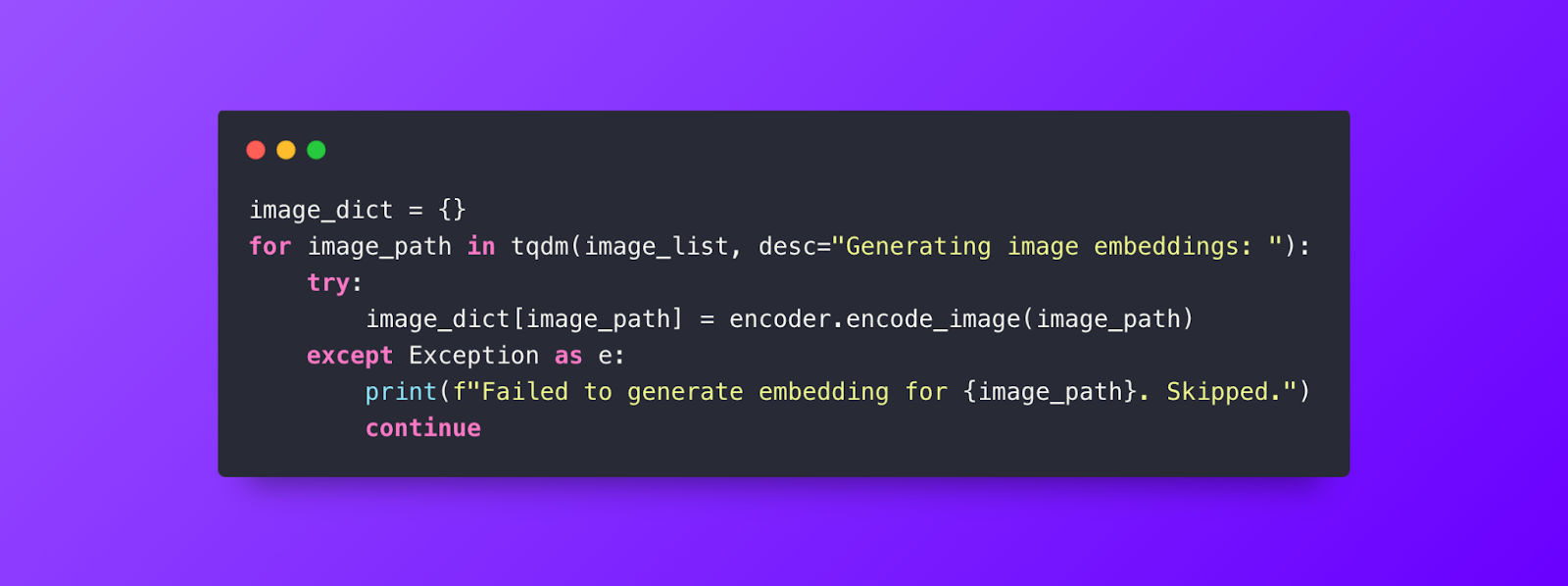
Step 5: Insert ****our images, image_path is created as a dynamic field in our schema for this collection.

Step 6: Vector encode the text query, “Show me the cutest cat ghost” to use for a query.
Step 5: Run our similarity search
Step 6: Iterate the results and show the image that matches the cutest cat.
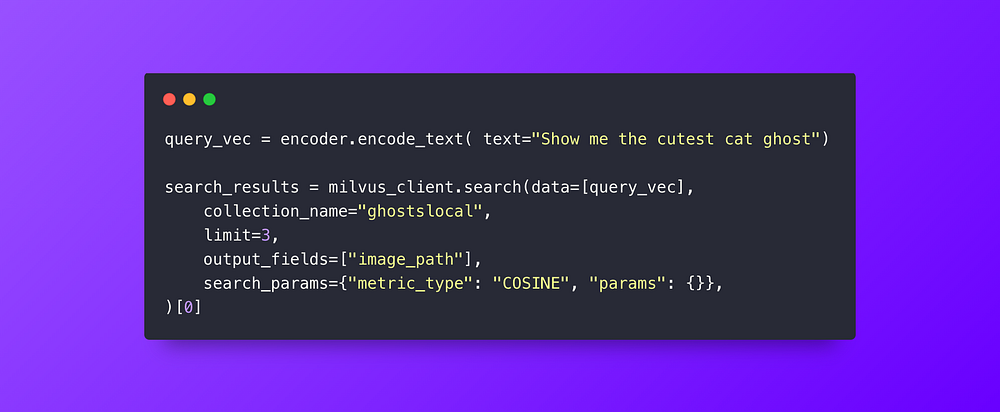
Our vector search is pretty simple, we just encode our text looking for the cutest cat ghost (in their little Halloween costume). Milvus will query the 768 dimension floating point vector and find us the nearest match. With all the spooky ghouls and ghosts in our database, it’s hard to argue with these results.

Using Ollama, LLava 7B and LLM Reranking
Running Advanced RAG Locally
Okay this is a little trick AND treat, we can do both topics at the same time. We are able to run this entire advanced RAG technique locally utilizing Milvus Lite, Ollama, LLava 7B and a Jupyter Notebook. We are going to do a Multimodal Search with a Generative Reranker. This uses an LLM to rank the images and explain the best results. Previously we have done this with the super charged GPT-4o model. I am getting good results with LLava 7B hosted locally with Ollama. Let’s show running this open, local and free!
We will reuse the existing example code to build the panoramic photo from the images returned by our hybrid search of an office photo with ghosts with the text “computer monitor with ghost”. We then send that photo to the Ollama hosted LLaVA7B model with instructions on how to rank the results. We get back a ranking, an explanation and an image.

Our search image and nine results

LLM returned results for ranked list order.

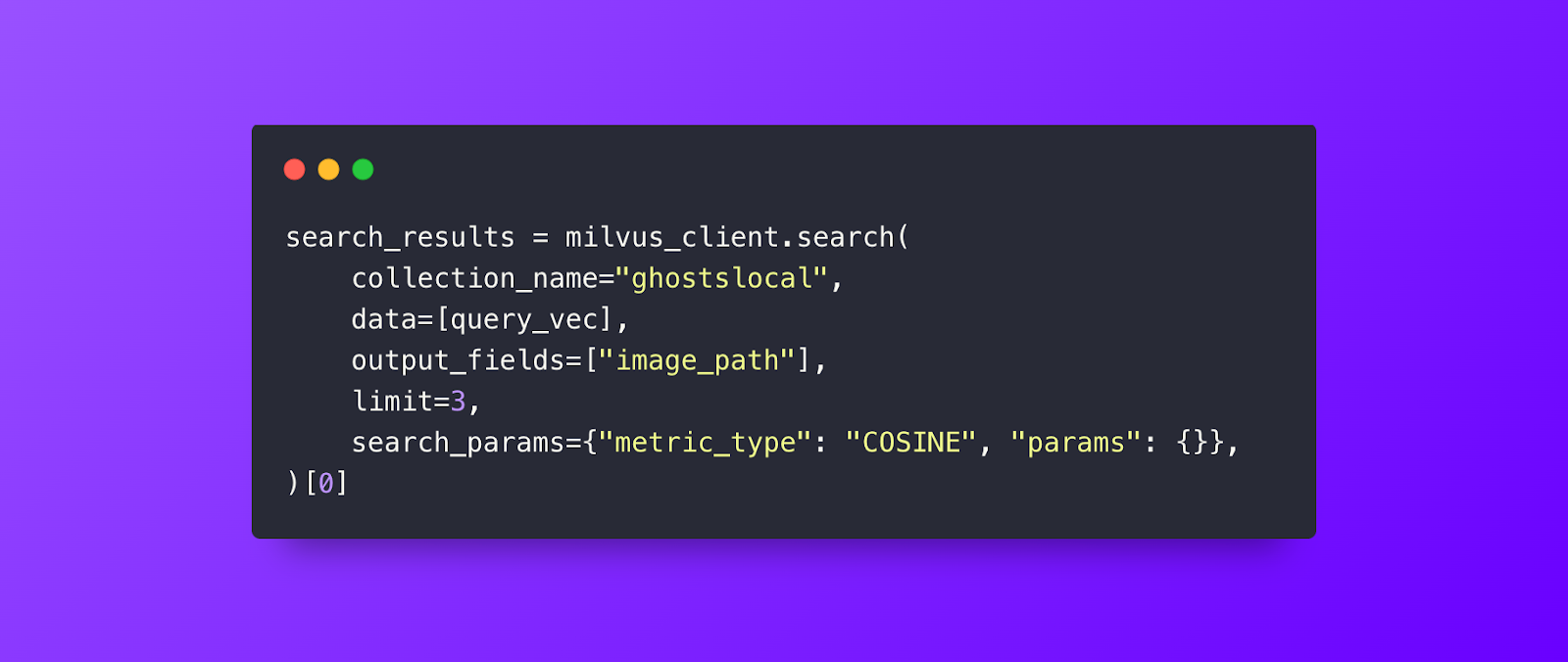
Our simple and fast Milvus query to get results to feed the LLM.
You can find the complete code in our example github and you can use any images of your choosing as the example shows. There are also some references and documented code including a StreamLit application to experiment with on your own.
Conclusion
As you can see not only is multimodal RAG not scary, it is fun and useful for many applications.
If you are interested in building more advanced AI applications then using Milvus and Multimodal RAG is a great combination for building applications. You can now move beyond only text and add images and more. Multimodal RAG opens up many new avenues for LLM generation, search and AI applications in general.
We’d love to hear what you think!
If you like this article we’d really appreciate it if you could give us a star on GitHub! You’re also welcome to join our Milvus community on Discord to share your experiences. Please join one or all of our meetups for local in-person community and code while also getting access to our Youtube library of recorded meetup talks, demos and deep dives.
If you’re interested in learning more, check out our Bootcamp repository on GitHub for examples of how to build Multimodal RAG apps with Milvus.
Further Resources

Keep Reading

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.