




How To Evaluate a Vector Database?
This article was originally published in InfoWorld and is reposted here with permission.
In today's data-driven world, the exponential growth of unstructured data is a phenomenon that demands our attention. The rise of AI and Large Language Models (LLMs) has once again ignited this data explosion, directing our focus toward a groundbreaking technology: vector databases. As a vital infrastructure in the age of AI, vector databases are powerful tools for storing, indexing, and searching unstructured data.
With the world's attention firmly fixed on vector databases, a pressing question arises: How do you select the right one for your business needs? What are the key factors to consider when comparing and evaluating vector databases? This post will delve into these questions and provide insights from scalability, functionality, and performance perspectives, helping you make informed decisions in this dynamic landscape.
What is a vector database?
Conventional relational database systems manage data in structured tables with predefined formats and excel in executing precise search operations. In contrast, vector databases specialize in storing and retrieving unstructured data, such as images, audio, videos, and text, through high-dimensional numerical representations known as vector embeddings.
Vector databases are famous for similarity searches, employing techniques like the Approximate Nearest Neighbor (ANN) algorithm. This algorithm arranges data according to spatial relationships and quickly identifies the nearest data point to a given query within extensive datasets.
Developers use Vector databases in building recommender systems, chatbots, and applications for searching similar images, videos, and audio. With the rise of ChatGPT, vector databases have become beneficial in addressing the hallucination issues of large language models.
Vector databases vs. other vector search technologies
Various technologies are available for vector searching beyond vector databases. In 2017, Meta open-sourced FAISS, significantly reducing the costs and barriers associated with vector searching. In 2019, Zilliz introduced Milvus, a purpose-built open-source vector database leading the way in the industry. Since then, many other vector database companies have emerged. The trend of vector databases took off in 2022 with the entry of many traditional search products such as Elasticsearch and Redis and the widespread use of LLMs like ChatGPT.

What are their differences now that there are so many vector search products? I roughly categorize them into the following types:
Vector search libraries. They are collections of algorithms without basic database functionalities like insert, delete, update, query, data persistence, and scalability. FAISS is a primary example.
Lightweight vector databases. They are built on vector search libraries, making them lightweight in deployment but with poor scalability and performance. Chroma is one such example.
Vector search plugins. These are vector search add-ons that rely on traditional databases. However, their architecture is for conventional workloads, which can negatively impact their performance and scalability. Elasticsearch and Pgvector are primary examples.
Purpose-built vector databases. These databases are purpose-built for vector searching and offer significant advantages over other vector-searching technologies. For example, dedicated vector databases provide more user-friendly features such as distributed computing and storage, disaster recovery, and data persistence. Milvus is a primary example.
How to evaluate a vector database?
When assessing a vector database, scalability, functionality, and performance are the top three most crucial metrics.
Scalability
Scalability is essential for determining whether a vector database can handle exponentially growing data effectively. When evaluating scalability, we must consider horizontal/vertical scalability, load balancing, and multiple replications.
Horizontal/Vertical Scalability
Different vector databases employ diverse scaling techniques to accommodate business growth demands. For instance, Pinecone and Qdrant opt for vertical scaling, while Milvus adopts horizontal scaling. Horizontal scalability offers greater flexibility and performance than vertical scaling, with fewer upper limits.
Load Balancing
Scheduling is crucial for a distributed system. Its speed, granularity, and precision directly influence load management and system performance, reducing scalability if not correctly optimized.
Multiple Replica Support
Multiple replicas enable differential responses to various queries, enhancing the system's query per second (QPS) and overall scalability.
Different vector databases cater to different types of users, so their scalability strategies differ. Milvus, for example, concentrates on scenarios with rapidly increasing data volumes and uses a horizontally scalable architecture with storage-compute separation. Pinecone and Qdrant, on the other hand, are designed for users with moderate data volume and scaling demands. Meanwhile, LanceDB and Chroma prioritize lightweight deployments over scalability.
Functionality
I classify the functionality of vector databases into two main categories: database-oriented and vector-oriented features.
Vector-Oriented Features
Vector databases benefit many use cases, such as retrieval augmented generation (RAG), recommender systems, and semantic similarity search using various indexes. Therefore, the ability to support multiple index types is a critical factor in evaluating a vector database.
Currently, most vector databases support HNSW (Hierarchical Navigable Small World) indexes, with some also accommodating IVF (Inverted File) indexes. These indexes are suitable for in-memory operations and are best suited for environments with abundant resources. However, some vector databases choose mmap-based solutions for situations with limited hardware resources. While easier to implement, the mmap-based solutions come at the cost of performance.
Milvus, one of the longest-standing vector databases, supports 11 index types, including disk-based and GPU-based indexes. This approach ensures adaptability to a wide range of application scenarios.
Database-Oriented Features
Many features beneficial for traditional databases also apply to vector databases, such as Change Data Capture (CDC), multi-tenancy support, resource groups, and role-based access control (RBAC). Milvus and a few traditional databases equipped with vector plugins effectively support these database-oriented features.
Performance
Performance is the most critical metric for assessing a vector database. Unlike conventional databases, vector databases conduct approximate searches, meaning the top k results retrieved cannot guarantee 100% accuracy. Therefore, in addition to traditional metrics such as Query Per Second (QPS) and Latency, "recall rate" is another essential performance metric for vector databases that quantifies retrieval accuracy.
I recommend two well-recognized open-source benchmarking tools to evaluate different metrics: ANN-Benchmark and VectorDBBench.
ANN-Benchmark
Vector indexing is a critical and resource-intensive aspect of a vector database. Its performance directly affects the overall database performance. ANN-Benchmark is a leading benchmarking tool for evaluating the performance of diverse vector index algorithms across a range of real datasets.
The graph below demonstrates the results of testing recall/queries per second of various algorithms based on the GIST1M dataset (1M vectors with 960 dimensions). It plots the recall rate on the x-axis against QPS on the y-axis, illustrating each algorithm's performance at different levels of retrieval accuracy.
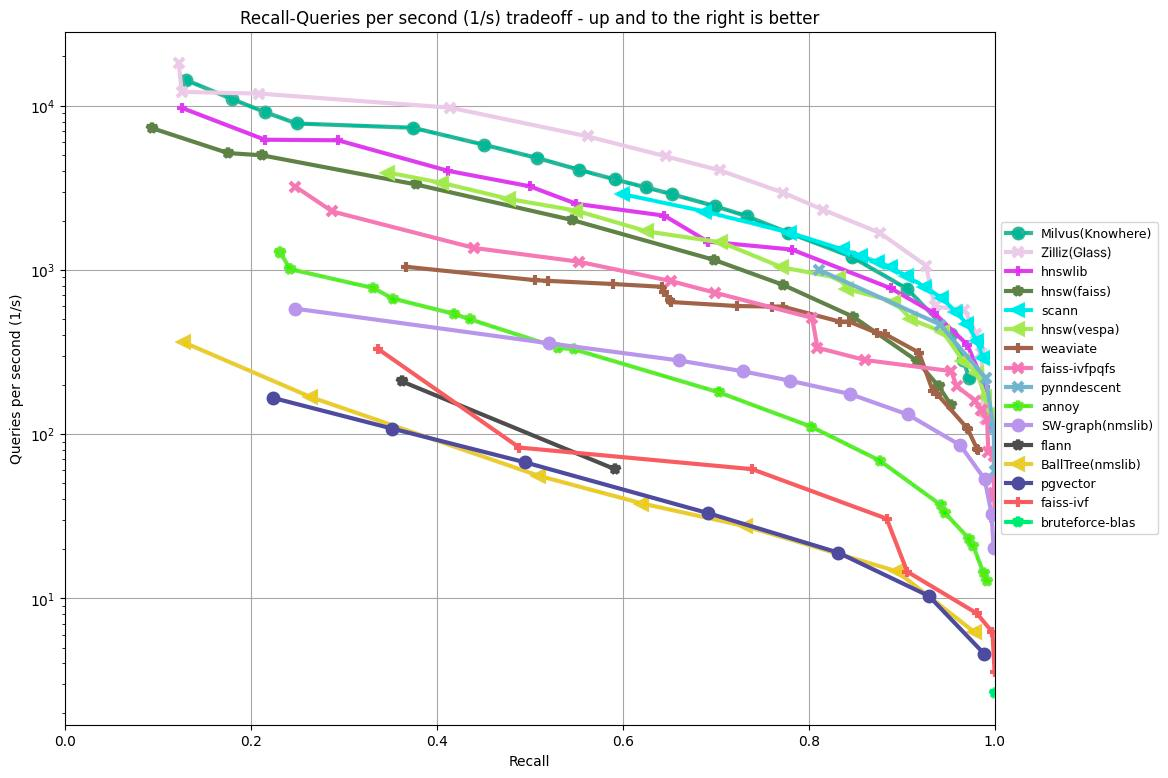
According to the results shown in the graph above, Milvus, Zilliz, and HNSW libraries achieved the top three best results when processing 1,000,000 vectors with 960 dimensions. For more benchmarking results, see ANN-Benchmark’s website.
VectorDBBench
Although the ANN-Benchmark is incredibly useful for selecting and comparing different vector searching algorithms, it does not provide a comprehensive overview of vector databases. We must also consider factors like resource consumption, data loading capacity, and system stability. Moreover, ANN-Benchmark misses many common scenarios, such as filtered vector searching.
VectorDBBench is an open-source benchmarking tool that can address the above-mentioned limitations and is designed for open-source vector databases like Milvus and Weaviate and fully-managed services like Zilliz Cloud and Pinecone. Because many fully managed vector search services do not expose their parameters for user tuning, VectorDBBench displays QPS and recall rates separately.
The charts below demonstrate the testing results for QPS and the recall rate of various mainstream vector databases when processing 500,000 vectors with 1,536 dimensions and 1,000,000 vectors with 768 dimensions, respectively.
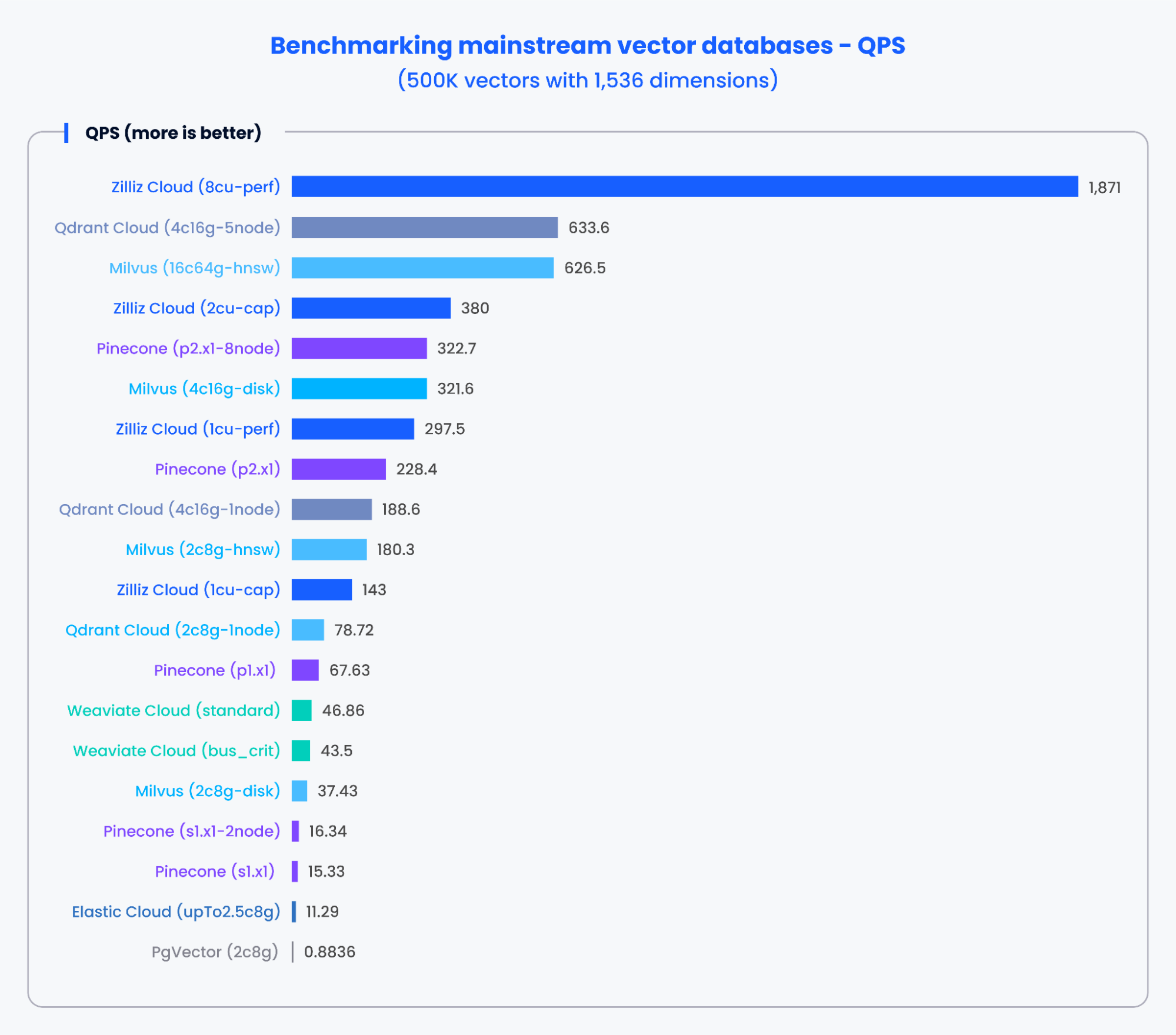
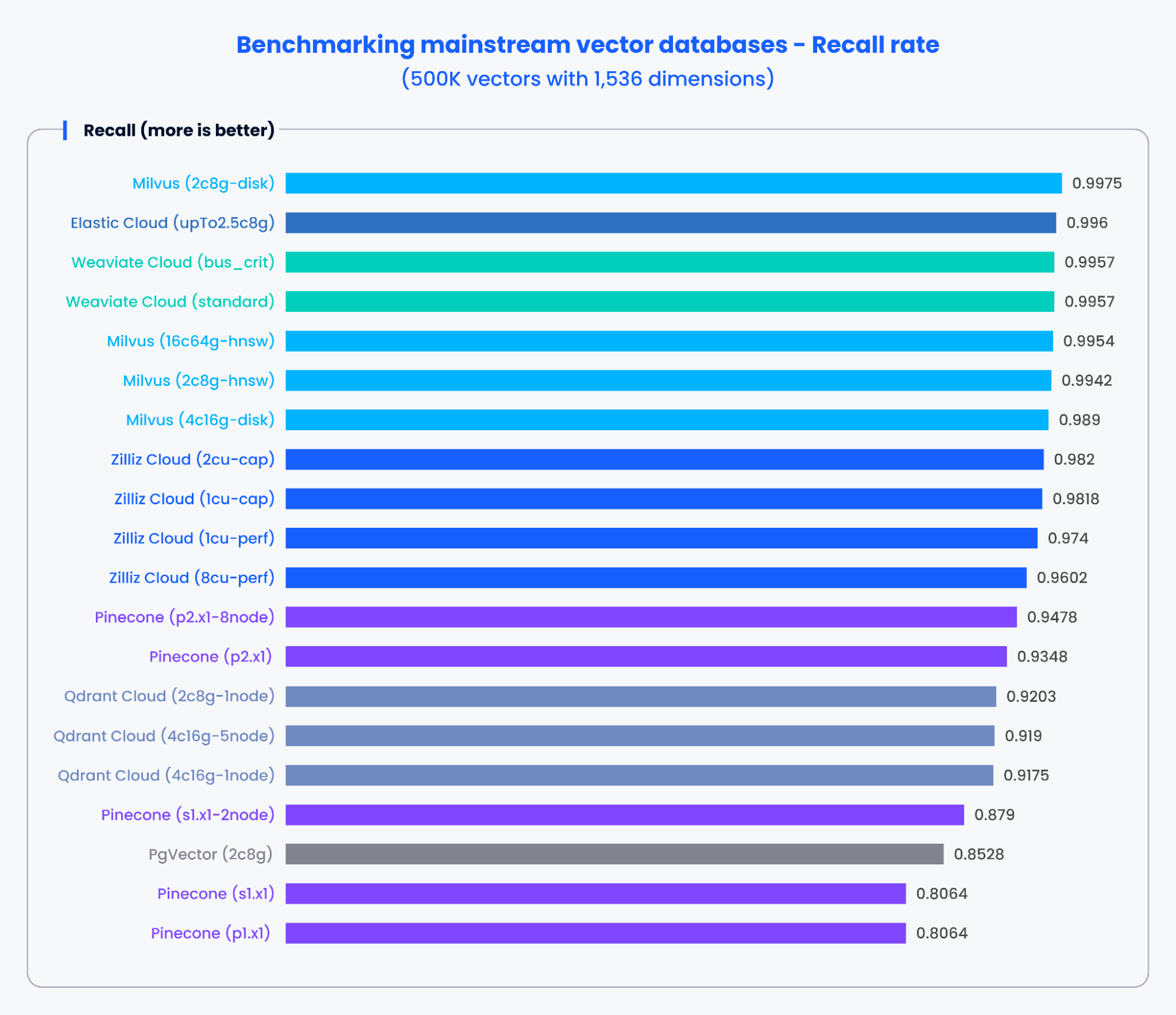
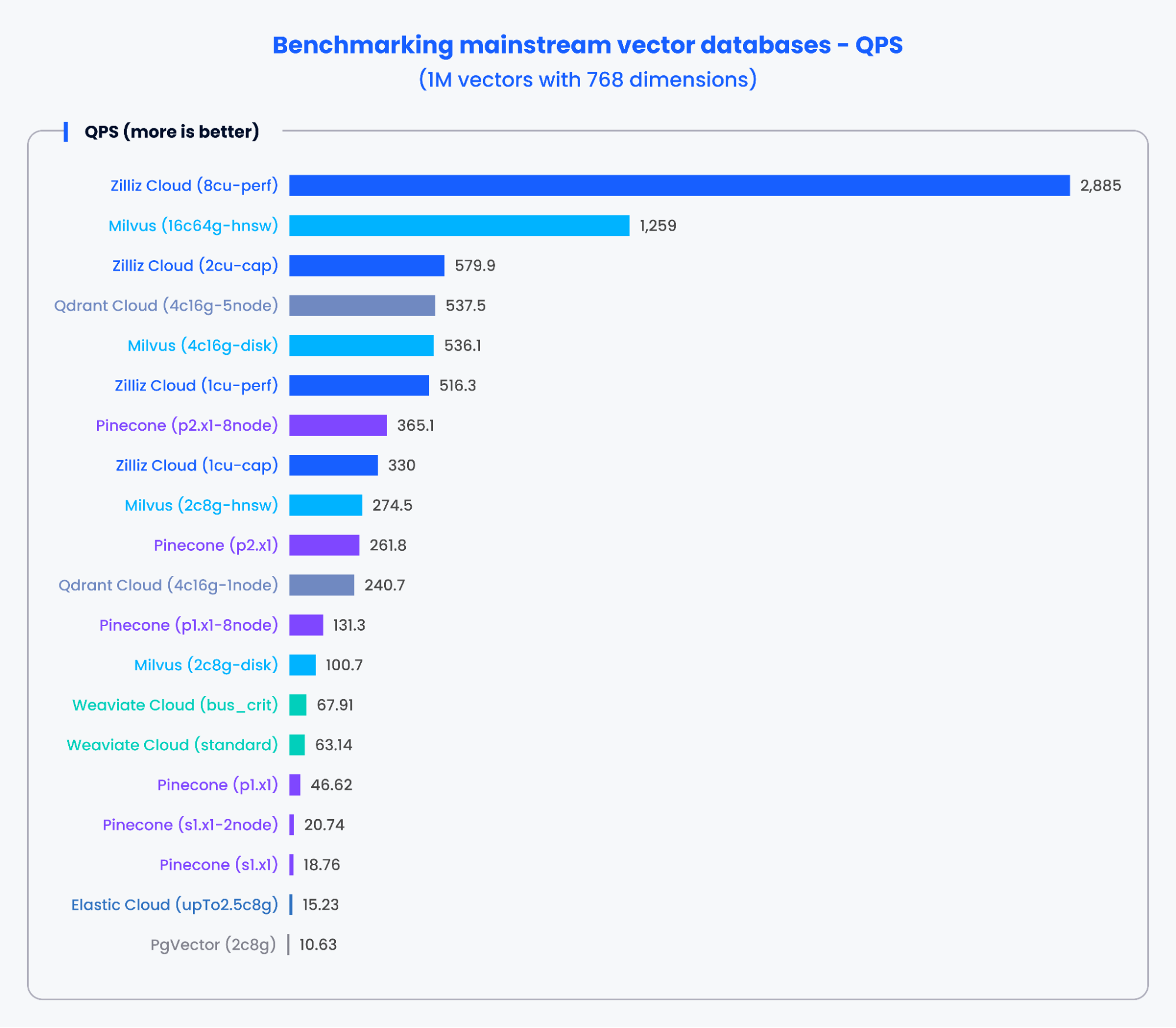
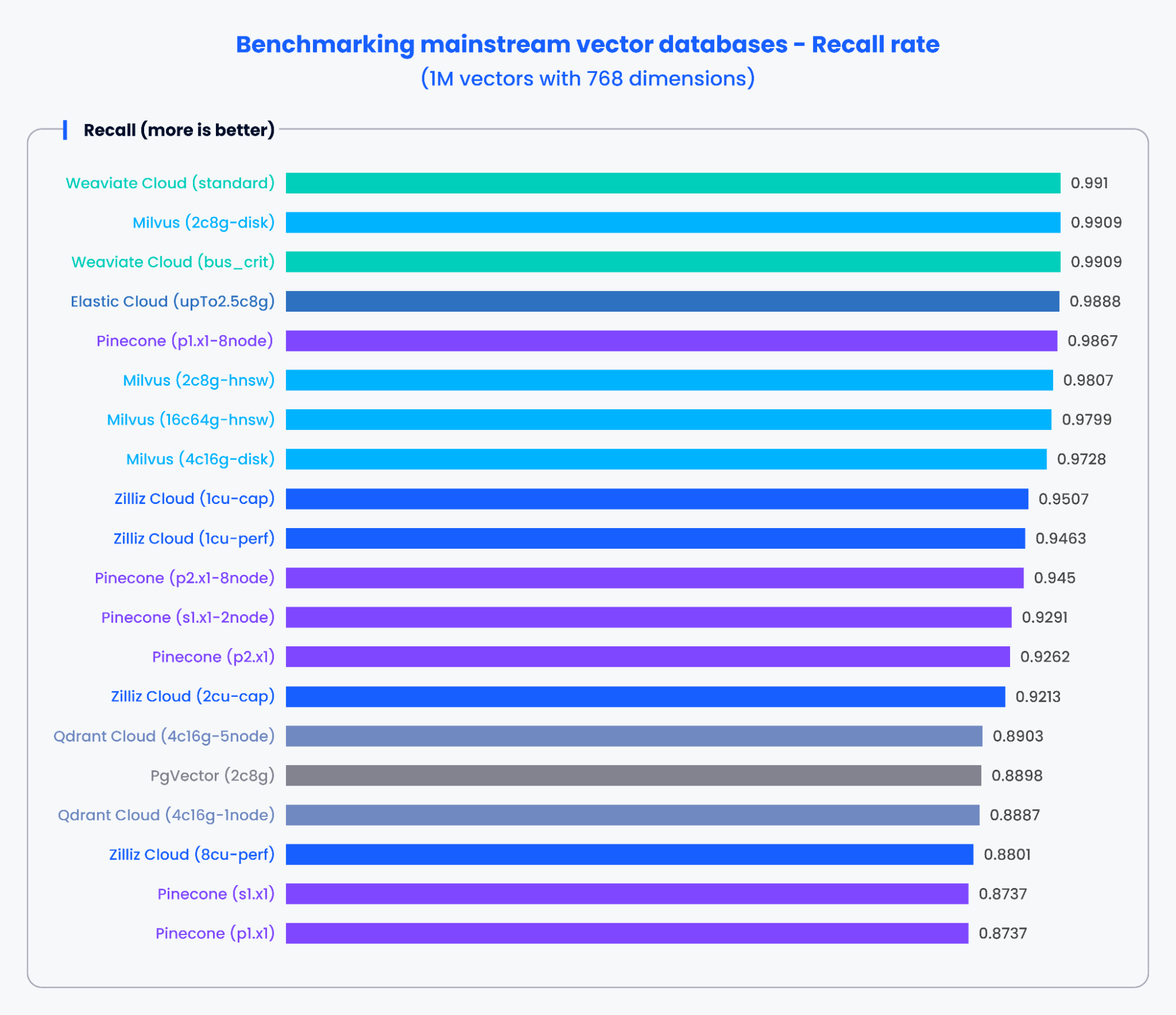
Based on the results in the charts above, purpose-built vector databases like Milvus and Zilliz demonstrated outstanding performance in both QPS and recall rates. These results indicate that purpose-built vector databases can quickly process vast amounts of data and retrieve more precise results. In contrast, vector search add-ons based on traditional databases showed poorer performance.
For more benchmarking results, see the VectorDBBench website.
Conclusion
In the dynamic realm of vector databases, numerous products exhibit unique emphases and strengths. There is no universal "best" vector database; the choice depends on your needs. Therefore, evaluating a vector database's scalability, functionality, performance, and compatibility with your particular use cases is vital.

Keep Reading

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.