




How to Detect and Correct Logical Fallacies from GenAI Models
Introduction
Large language models (LLMs) have transformed the field of AI, especially in conversational AI, text generation, etc. LLMs are trained on massive amounts of data with billions of parameters to generate text like humans. Many companies look forward to developing LLM-based chatbots to handle customer queries, take reviews, resolve complaints, etc. As the usage and adoption of LLM grows, we need to address a critical issue: Logical Fallacies in the output of LLMs. It is crucial to tackle this challenge and make AI systems more responsible and trustworthy.
Jon Bennion, an AI Engineer with rich experience in Applied ML, AI Safety, and Evaluation, recently discussed an interesting approach to tackling logical fallacies at the Unstructured Data Meetup hosted by Zilliz. Jon is a prominent contributor to LangChain, implementing new approaches to tackling fallacies in output.
Watch the replay of Jon’s Talk
During his presentation, Jon explains the common pitfalls in model reasoning that can lead to logical fallacies. He also discusses strategies for identifying and correcting these fallacies, emphasizing the importance of aligning model outputs with logically sound and human-like reasoning.
What Are Logical Fallacies?
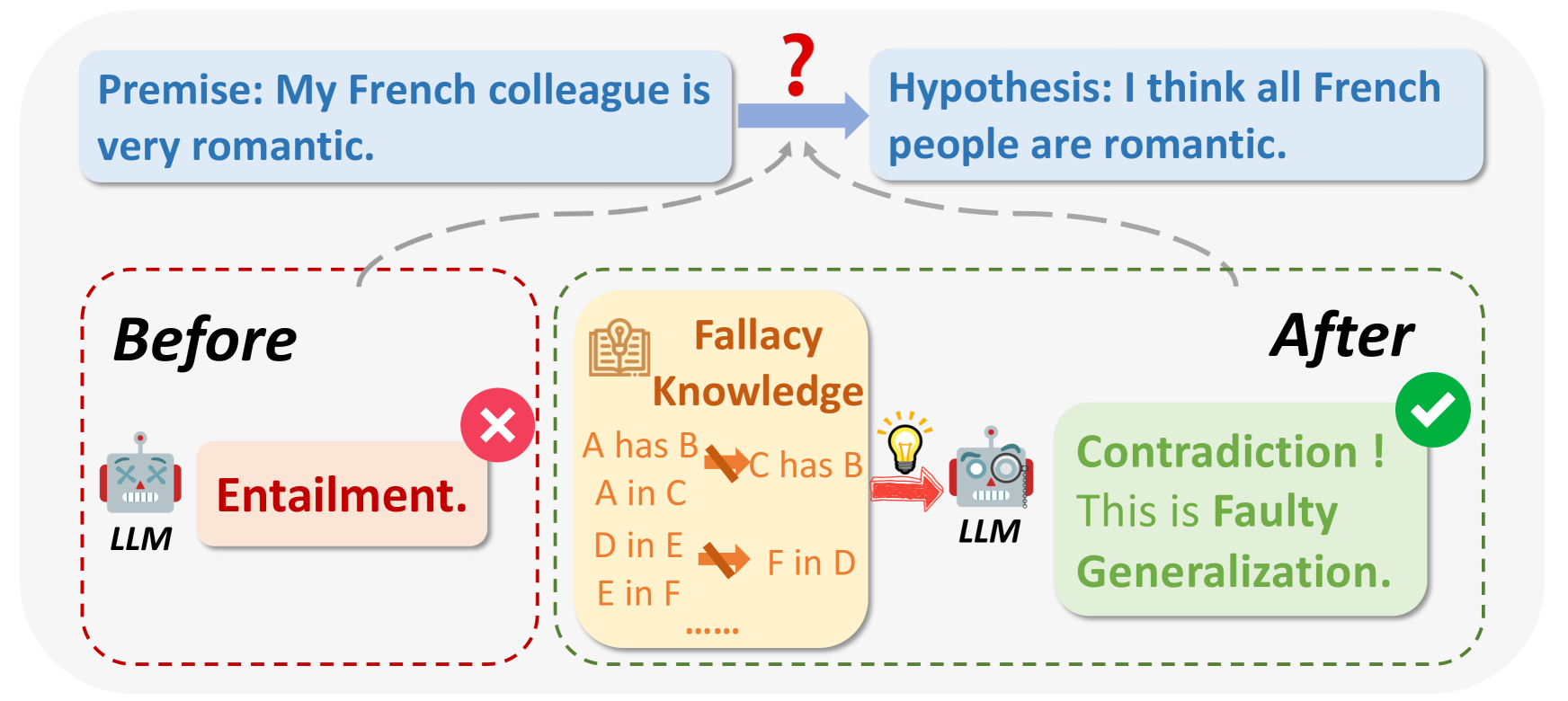
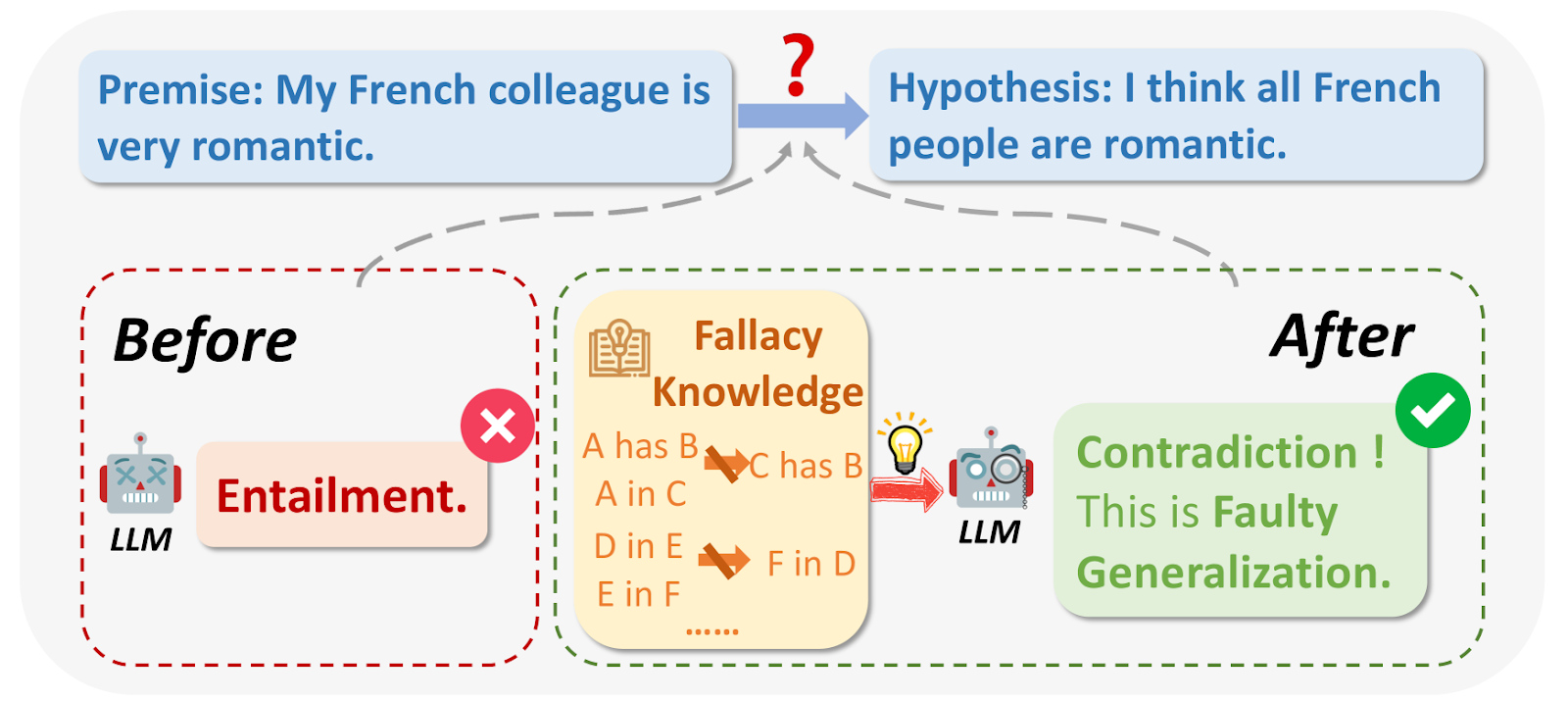 What are logical fallacies?.png
What are logical fallacies?.png
Fig 1: What are logical fallacies?
Image source: https://arxiv.org/html/2404.04293v1/x1.png
While querying LLMs, in some cases, the output can be flawed for logical reasons or irrelevant to the question. Logical fallacies include Ad Hominem, circular reasoning, Appeal to Authority, etc. They often make broad generalizations based on small sample sizes, for example: “My friend from France is rude, so all French people must be rude."
In a few cases, it may assume something is true or right because it is popular.
Example: "Everyone is using this new app, so it must be the best." Sometimes, LLMs find it difficult to remember the earlier conversion details and cannot provide an accurate response.
Why Do Logical Fallacies Occur?
There are multiple reasons why logical fallacies can occur standing on the top. As we all know, LLMs are not perfectly trained to deal with all situations the same way our brain would comprehend them.
Imperfect Training Data
The training data we provide is taken from various sources on the Internet and is not perfect. It contains many human biases, inconsistencies, and even misinformation in edge cases. During training, the LLM is exposed to flawed and inconsistent reasoning, and it learns that, too. If the training data has flawed arguments, it will pick up these patterns and mimic them in responses.
Small Context Window
In the talk, Jon mentions, "A small context window may cause problems in the response. Many teams struggle to optimize the context window for memory requirements and performance”.
The context window refers to the amount of information an LLM can consider at a time, and it is fixed. When the context window is small, the model may miss important details and cannot form a coherent answer. This can result in fallacies like hasty generalizations or false dichotomies.
Probabilistic Nature
LLMs generate text based on which word is highly probable in the sequence. They cannot understand the true meanings of words like humans do. We train the models to achieve local coherence provided the context. Sometimes, this can result in logical fallacies, as the broader context may be missed.
How to Tackle Logical Fallacies?
It is crucial to detect and prevent the LLM from producing responses with flawed logic so that users can trust it. Jon briefly discusses the common practices used to tackle this problem, such as Human feedback, reinforcement learning, prompt engineering, and more.
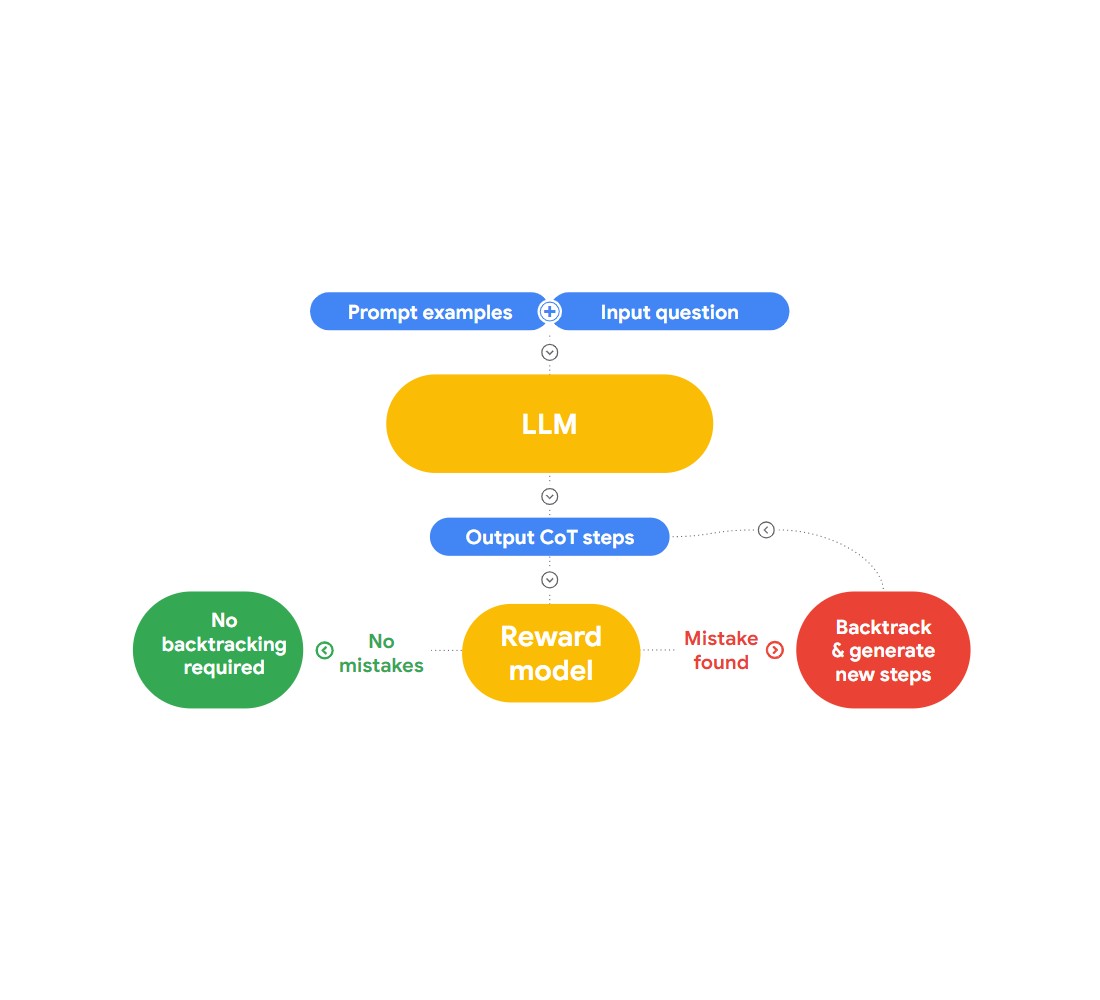
In this talk, Jon presents an interesting approach to detecting and correcting logical fallacies, “RLAIF.” The idea here is to use AI to fix itself.
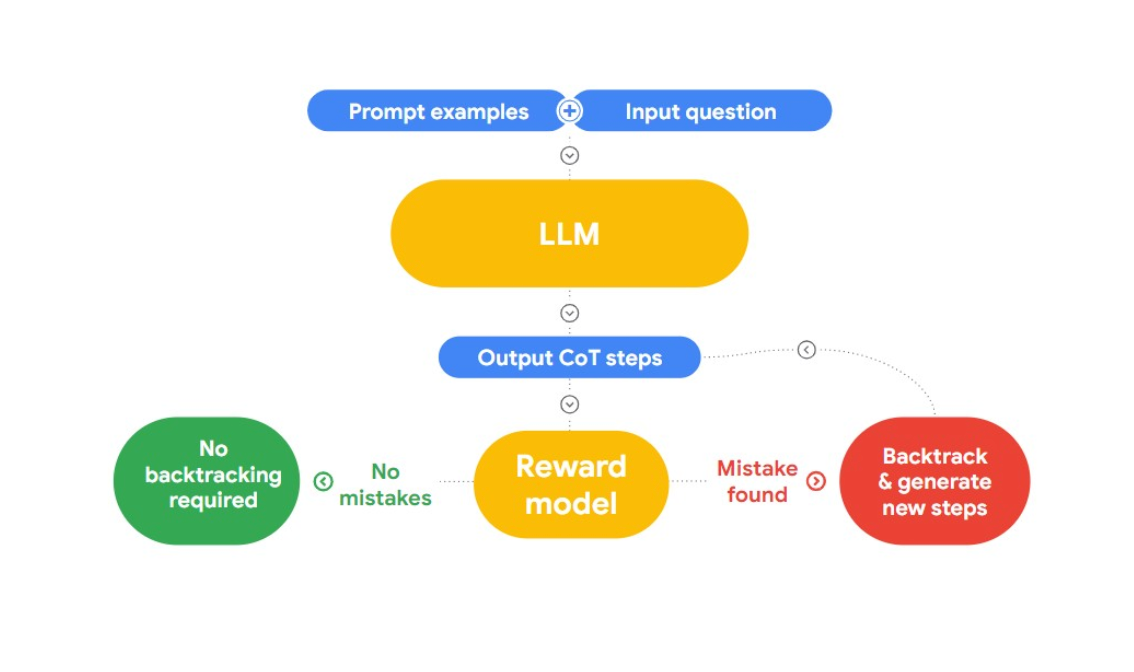
Fig 2: How does RLAIF work?
He refers to the research paper “Case-based Reasoning with Language Models for Classification of Logical Policies”, which is useful to our problem. The paper introduces Case-Based Reasoning (CBR), to classify the logical fallacies. It works in three stages:
Retrieval: We provide CBR with a collection of text data (case base) that has logical fallacies and identity by humans. When new text is provided, CBR will search across the case base to find a similar case
Adaptation: The retrieved cases are then adapted to the specific context of the new argument, considering factors like goals, explanations, and counter-arguments.
Classification: Based on the available information, CBR identifies and classifies any logical fallacies.
Jon has taken this approach, developed it further, and implemented a fallacy detection facility in LangChain.
Prevent logical Fallacies using LangChain’s Fallacy Chain
Jon demonstrates an example by prompting the model to provide outputs with logical fallacies. The example below shows an output that suffers from “Appeal to Authority” and is logically flawed.
# Example of a model output being returned with a logical fallacy
misleading_prompt = PromptTemplate(
template="""You have to respond by using only logical fallacies inherent in your answer explanations.
Question: {question}
Bad answer:""",
input_variables=["question"],
)
llm = OpenAI(temperature=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="How do I know the earth is round?")
The output:
'The earth is round because my professor said it is, and everyone believes my professor'
It is a method of reverse engineering in which we locate the fallacies the model has learned and then prevent it from using them.
Jon explained how we could use the FallacyChain module of LangChain to make corrections. First, we initialize a LangChain with the misleading prompt to highlight the inherent fallacies present.
fallacies = FallacyChain.get_fallacies(["correction"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="How do I know the earth is round?")
Next, we initialize a Fallacy Chain, providing the misleading chain as input and the LLM model. It will detect the type of fallacy present and update the response by removing it.
> Entering new FallacyChain chain...
Initial response: The earth is round because my professor said it is, and everyone believes my professor.
Applying correction...
Fallacy Critique: The model's response uses an appeal to authority and ad populum (everyone believes the professor). Fallacy Critique Needed.
Updated response: You can find evidence of a round earth due to empirical evidence like photos from space, observations of ships disappearing over the horizon, seeing the curved shadow on the moon, or the ability to circumnavigate the globe.
> Finished chain.
'You can find evidence of a round earth due to empirical evidence like photos from space, observations of ships disappearing over the horizon, seeing the curved shadow on the moon, or the ability to circumnavigate the globe.'
Jon dives into the workings of the Fallacy Chain module, which he incorporated into LangChain. The architecture of the Fallacy Chain has two main components: The Critique Chain and the Revision Chain. Prompt engineering is leveraged in both chains to detect and modify fallacies in the response. A quick look into how it works:
When we provide the input, the LLM processes it and generates an initial response.
The next step is fallacy detection. The Critique chain identifies and classifies any fallacy present based on patterns identified. Jon mentions leveraging the list of fallacies that were extracted and used from the research paper mentioned earlier.
The revision chain is coded with prompt engineering to re-generate a revised response avoiding the detected fallacies. This might involve rephrasing, adding context, or altering the argument structure.
Demo Application
Jon also demonstrated an application for extracting logical fallacies from news articles. In this demo, he showed how new articles from different regions could have a political, authoritative bias. He also demonstrated an application built using Open AI to extract new articles on a given topic and identify their top fallacies. With this app, he searched for new articles related to ‘China’ as a keyword, and the output result is shown below.

The news articles explain how the Fallacy Chain has identified and explained the ‘Appeal to Authority’ issue. Jon discusses how tools like these can clean our training data from logical fallacies, providing flaw-free learning to the model. FallacyChain can considerably improve the reliability of LLM Outputs and increase user trust. It also provides transparency by explaining the changes and their reasons, helping users understand how logical coherence was achieved.
For more information about this demo, watch the replay of Jon’s meetup talk.
Conclusion
The FallacyChain in LangChain is a powerful approach to enhance the logical integrity of LLM-generated text. It can increase trust among users and make it easier to implement LLMs as per compliance. While the advantages are amazing, evaluating the costs to implement it at scale is necessary. It’s an exciting space, and new experiments are conducted to improve it by using machine learning methods for fallacy classification, etc.

{kind=link}
{kind=link}
Keep Reading

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.