




How to Build a LangChain RAG Agent with Reporting
One of the most important parts of moving AI Agents into production with your retrieval augmented generation applications is monitoring what they do underneath the surface. Many monitoring tools, such as Arize, TruEra, and Portkey, are available on the market. In this example, we create an AI Agent with LangChain, Milvus, and OpenAI. Then, we use Portkey to monitor our token usage, token count, and request latency. Find the code for AI Agents Cookbooks in this GitHub repo.
Introduction to the Tech Stack
Before we get into the code, let’s briefly cover the pieces of this tech stack. In this tutorial, we use four primary pieces of technology: LangChain to orchestrate your retrieval augmented generation app, Milvus as our vector database to store and send relevant information to one of your favorite Large Language Models (LLM), Portkey for monitoring systems, and OpenAI for our LLM.
LangChain
LangChain is the most popular open-source LLM Orchestration framework as of May 2024. It is one of many frameworks on the market for retrieval augmented generation. LangChain’s specialty is chaining. It is particularly suited for assembling inputs(or relevant data) and outputs of large language models (LLMs) and other related functions. You can read more about the difference between the three popular frameworks in this article about LangChain vs. LlamaIndex vs. Haystack.
Milvus
Milvus is the most popular open-source and only distributed vector database that is often used to store your multiple data sources when building retrieval augmented generation applications. Milvus performs vector similarity search particularly well in terms of scalability, flexibility, and enterprise-ready features compared to other vector databases. For this tutorial, we’ll run Milvus via Docker Compose.
Portkey
Portkey featured the most popular open-source LLM Gateway in May 2024. It is one of many monitoring solutions for LLM applications. Portkey provides monitoring by routing calls through its gateway. It monitors the cost, token count, and latency of your calls. Portkey also allows you to configure auxiliary tools like a semantic cache, similar to GPTCache.
OpenAI
OpenAI brought LLMs to the general public's attention via ChatGPT. Since then, they’ve released several different versions of GPT and encouraged many competitors, such as Mistral, Meta AI, and others, to enter the market.
Building the LangChain RAG Agent
Now that we know the main technologies we’re working with, let’s build our LangChain Retrieval Augmented Generation (RAG) Agent. You can run the lines below in a Python notebook cell, or you can run them directly in the terminal without the ! at the front. We need five required libraries and an optional sixth one.
The five required libraries are:
pymilvusfor Milvus actionslangchainfor LangChainlangchain-communityfor the community integrations, including the Milvus + LangChain integrationlangchain-openaifor the OpenAI + LangChain libraryunstructuredfor helping load the data
The sixth optional library is langchainhub. We use this library to access the agent prompts from LangChain hub, so we don’t have to write them ourselves. The second command, `docker compose up—d', runs the Docker compose file to run Milvus.
! pip install --upgrade --quiet pymilvus langchain langchain-community langchainhub langchain-openai unstructured
! docker-compose up -d
Setup
The first part of building our RAG Agent is simple. All we do here is load our environment variables and do a bunch of imports. The two environment variables we’ll need are a Portkey API key and an OpenAI API key. We can do away with the Portkey key if we host it locally.
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
PORTKEY_API_KEY = os.environ["PORTKEY_API_KEY"]
I’ll split the imports into two sections: LangChain-related and Portkey-related. We need nine imports from LangChain. We need:
- DirectoryLoader to load data from a specified directory
- RecursiveCharacterTextSplitter to split the text in our documents
- Milvus, to connect to Milvus
- OpenAIEmbeddings to create embedding vectors
hubis the LangChain hub we pull the prompts fromcreate_retriever_toolfor creating a tool that can retrieve data- ChatOpenAI to use GPT as a chat endpoint
- AgentExecutor to execute an agent
And
create_openai_tools_agentto create an agent from tools and the OpenAI endpoint
We need three imports to manage Portkey: the Portkey Gateway URL, a function to create headers, and the UUID library to track each run.
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Milvus
from langchain_openai import OpenAIEmbeddings
from langchain import hub
from langchain.tools.retriever import create_retriever_tool
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
import uuid
Getting Documents into Milvus
The first step in creating an RAG agent is sending your data sources, in this case, documents to Milvus. First, we define our text splitter. For this example, we define a chunk size and chunk overlap. These two concepts are what we use to split a huge document into reasonably sized chunks. The overlap helps account for contextual information retrieval and continuity.
Once we have a text splitter ready, we load the directory and split it into LangChain documents using the text splitter. Next, we define our embedding function, in this case using the OpenAIEmbeddings language model. Now, with the doc and embeddings function ready, we connect to Milvus and load the chunks with the OpenAI embeddings function.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
loader = DirectoryLoader("../city_data")
docs = loader.load_and_split(text_splitter=text_splitter)
embeddings = OpenAIEmbeddings()
db = Milvus.from_documents(
docs,
embeddings,
connection_args={"host": "127.0.0.1", "port": "19530"})
Creating a Retriever Tool for RAG
Step one in building RAG is getting your documents into a vector database like Milvus. When using a framework like LangChain, the next step is the information retrieval component which is to turn the data sources the vector database into a “retriever.” This object automatically takes a string, vectorizes it, and searches the vector database for relevant responses.
Since we’re building an AI Agent, we must turn our retriever into a tool. Creating a retriever tool in LangChain requires three parameters: the retriever model itself, the tool's name, and a description of its function.
Now, we create a list of tools and add this retriever tool. This step becomes important later.
retriever = db.as_retriever()
tool = create_retriever_tool(
retriever,
"search_cities",
"Searches and returns excerpts from Wikipedia entries of many cities.",
)
tools = [tool]
Setting Up the RAG Agent
We start setting up the RAG agent by getting the prompt. We can create a prompt or pull it directly from the LangChain hub, where Harrison Chase has a prompt ready for an agent built on OpenAI. The last thing we must create before getting the LLM is our Portkey headers.
We use Portkey here to monitor our usage and check internal details of our LLM calls, such as latency, number of tokens used, and cost. For our Portkey headers, we need four things: the Portkey API Key, a UUID, the name of the LLM provider (OpenAI), and a Portkey config. The config file can be any configuration; you can create a default configuration for the user dashboard.
Next, we instantiate our LLM via ChatOpenAI. We need four parameters: the OpenAI API key, the Portkey gateway URL, the Portkey headers, and the LLM's temperature. With all these ready, we can create the agent using create_openai_tools_agent. We only need three parameters to make the agent: the LLM, the tools list, and the prompt.
prompt = hub.pull("hwchase17/openai-tools-agent")
portkey_headers = createHeaders(
api_key=PORTKEY_API_KEY,
trace_id=uuid.uuid4(),
provider="openai",
config="pc-basic-b390c9"
)
llm = ChatOpenAI(api_key=OPENAI_API_KEY, base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, temperature=0)
agent = create_openai_tools_agent(llm, tools, prompt)
Trying Out the RAG Agent
The last step is to create a function to execute tasks for our agent, and then our agent is finally ready for the field. It’s a strange name if you think about it. Anyway, the function that can execute our agentic workflow takes two parameters: the tool agent and the tools themselves.
agent_executor = AgentExecutor(agent=agent, tools=tools)
With our agent ready to execute, we can invoke it with an input. For this example, we ask it to get us the size of San Francisco.
result = agent_executor.invoke(
{
"input": "What is the size of San Francisco?"
}
)
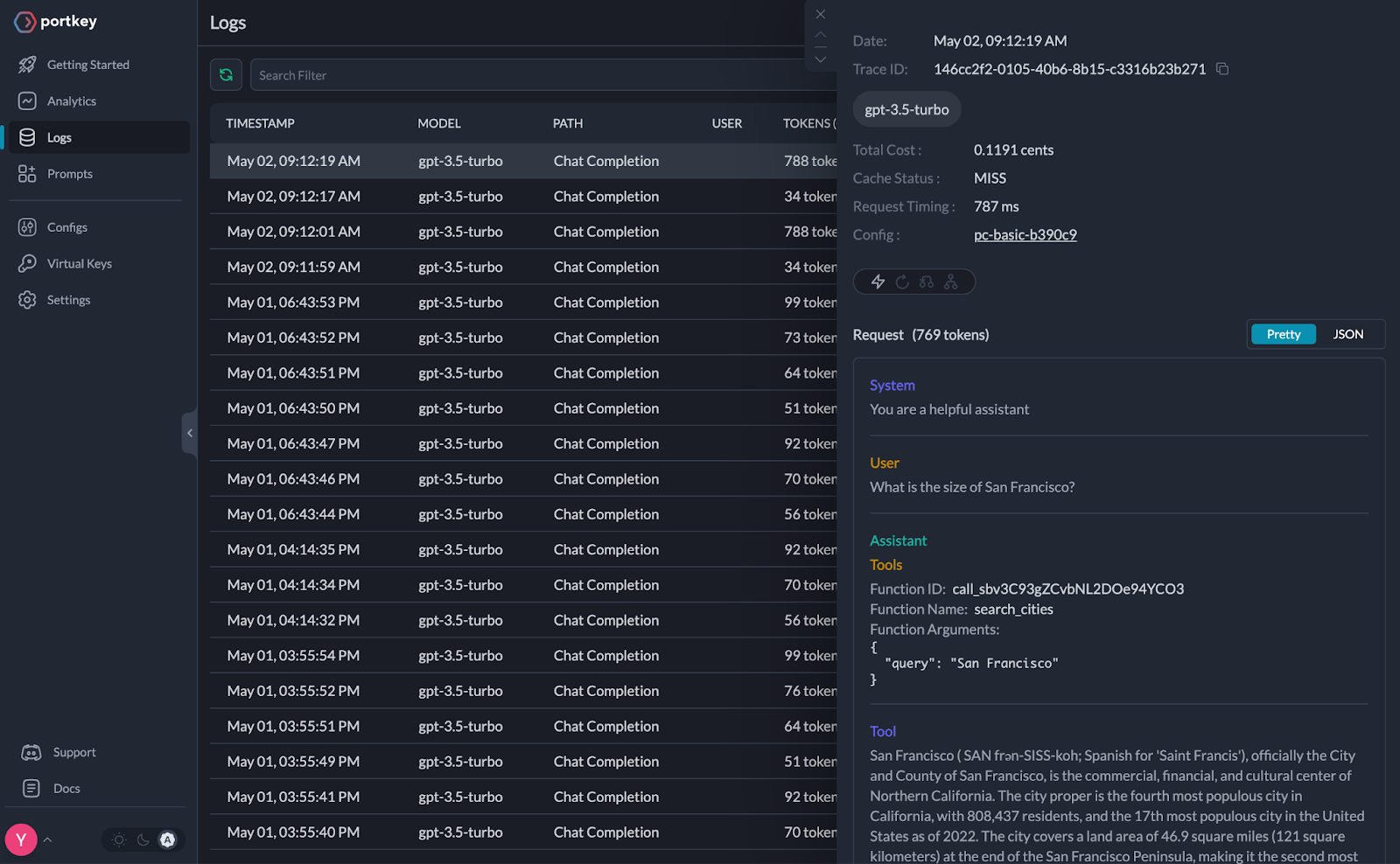
The agent can retrieve information from the documents created on San Francisco’s Wikipedia page. It tells us that the size of San Francisco is 46.9 square miles of 121 square kilometers.

To check our monitoring and see how our LangChain RAG Agent is doing, we can just check the dashboard for Portkey. We can see that this particular RAG agent question cost us 0.1191 cents, took 787ms, and used 769 tokens.
Summary of Building a LangChain RAG Agent
This tutorial taught us how to build an AI Agent that does RAG using LangChain. In addition to the AI Agent, we can monitor our agent’s cost, latency, and token usage using a gateway. The gateway we chose for this particular tutorial is Portkey.
There were five steps in building, using, and monitoring this LangChain RAG Agent. First, we had to go through the most boring step—setup. After we had our basic setup, we imported our external knowledge (documents) into Milvus to perform semantic search for efficient retrieval. Then, we turned our LangChain Milvus object into a retriever and that retriever into a retriever tool.
If we had stopped at the retrieval phase, we would have had the basis for standard RAG. Creating the tool allows us to build an agent on top of it. Once the tool was ready, we defined an LLM routed through a gateway (Portkey) and gave it access to the tools. Next, we asked our RAG Agent a question and got an answer. That run gave us insight into how the agent ran the LLM and the details of responses, the cost, latency, and token usage.
More Langchain resources

Keep Reading

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.