




Revolutionizing Autonomous AI: Harnessing Vector Databases to Empower Auto-GPT
ChatGPT, or Chat Generative Pre-trained Transformer, has been a game-changer in AI technology, with groundbreaking advancements. However, even with large language models (LLMs) such as GPT and specialized AI applications like Midjourney, human input is still necessary for prompts. This reliance on humans prompts the question: Can AI function independently and achieve goals without human intervention? Auto-GPT has emerged as a popular solution to this need.
What is Auto-GPT?
Auto-GPT is an experimental open-source project on GitHub. It combines a GPT language model with other tools to create an AI system that can work continuously and independently with minimal or even without human input.
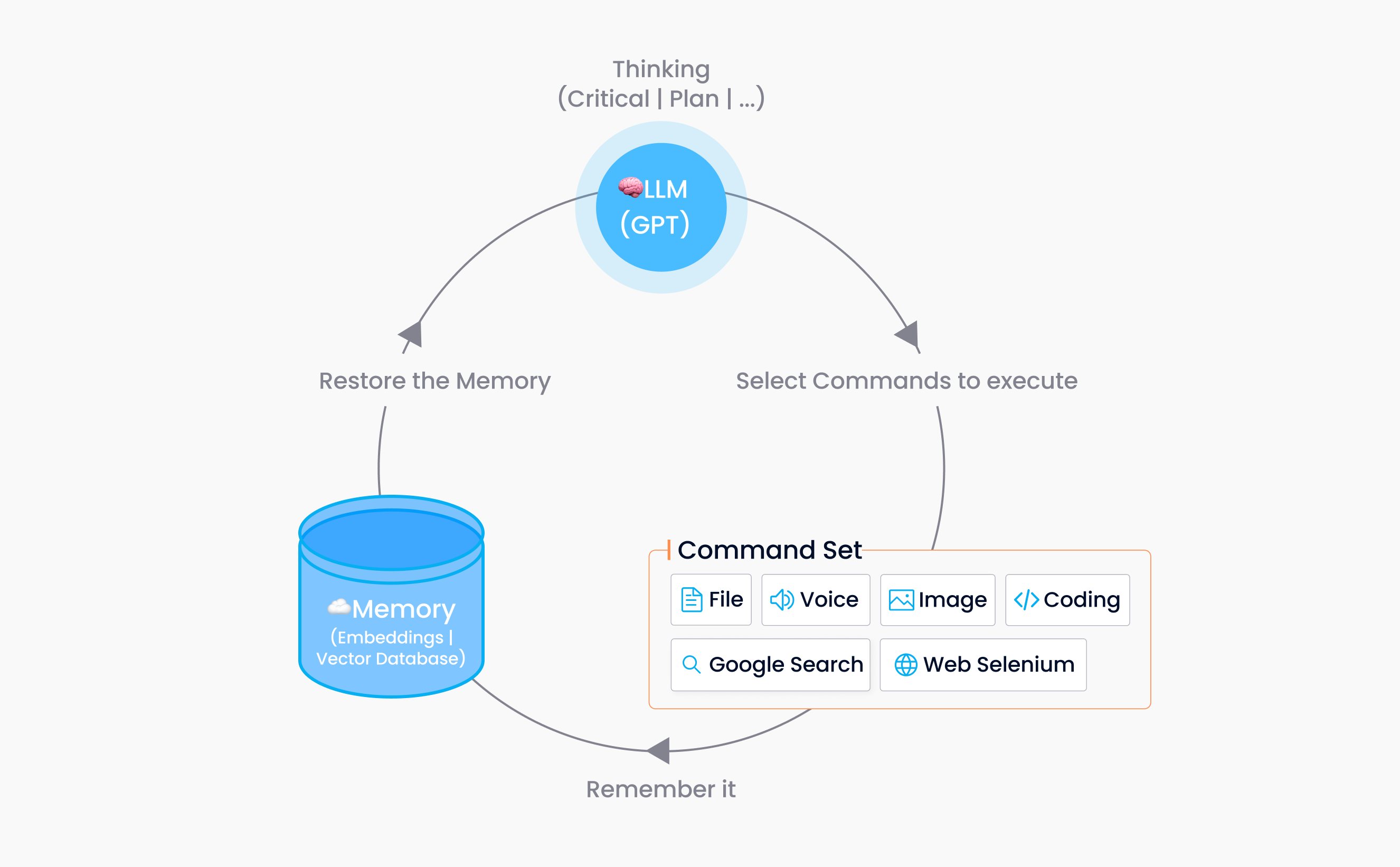
Auto-GPT has two core parts: an LLM and a command set. The LLM, such as GPT, serves as the "brain" of Auto-GPT and handles cognitive processing. So Auto-GPT prompts are developed by the LLM rather than traditional human input. Meanwhile, the command set performs various tasks autonomously, such as managing files, conducting web searches, and accessing social networks. These abilities are equivalent to Auto-GPT's "hands" and "senses."
To explain the process further, Auto-GPT uses the GPT language model and human feedback to analyze and break down large tasks into smaller ones. It then assigns specific commands to these smaller tasks, executes them, and receives input for the next round of cognitive processing. These procedures repeat until Auto-GPT completes the task.
Auto-GPT’s restrictions
Now that you know Auto-GPT, it’s important to understand its abilities and restrictions. While Auto-GPT can perform tasks automatically, it has limitations in understanding and retaining extensive contextual information because the GPT model it leverages has a token limit. For example, OpenAI's GPT-3 can only process a maximum of 4,096 tokens for context, which means that when conversations exceed the token limit, GPT-3 may forget previous discussions.
In addition, to complete a complex task, Auto-GPT has to take multiple steps. However, you can't send each step separately to the GPT model because it might result in the loss of context. Such a loss would make it challenging to determine if the actions are correct and approach the goal effectively. But if you send all previous messages to the GPT model at each step, they will exceed GPT's token limit more quickly.
One way to address this contextual issue is to access a window of historical messages, such as the last ten messages or a fixed number of tokens, without exceeding the token limit of a single conversation. However, this method restricts Auto-GPT from accessing earlier contextual information, which might lead to the failure of Auto-GPT to accomplish its goal.
Enhancing Auto-GPT’s contextual ability with a vector database
Integrating Auto-GPT with a vector database is a more effective and efficient solution to enhance Auto-GPT’s memory and contextual understanding. Here's how the integration works:
The integration converts Auto-GPT commands and execution results for each step into embeddings and stores them in a vector database.
When generating the next task, it retrieves messages from the history window and stores them as input for a vector database search.
It then retrieves the
top-khistorical messages to improve context with a larger chronological span.
 image
image
Additionally, thanks to the similarity retrieval capability of the vector database, the system can determine if the last action is similar to the current one and if it helps complete the task, providing more precise information for the following command.
How to set up Auto-GPT with Milvus
Milvus is one of the most popular open-source vector databases capable of handling vast datasets containing millions, billions, or even trillions of vectors. You can follow the guide below to integrate Milvus with your Auto-GPT easily.
- Pull the Docker image of Milvus and install it using Docker Compose:
https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml
docker compose up -d
- Install the
pymilvusclient in your python environment:
pip install pymilvus==2.2.8
- Update your
.envfile:
MEMORY_BACKEND=milvus
If you find deploying and maintaining Milvus difficult, consider using Zilliz Cloud. It is a fully-managed cloud-native service for Milvus and can help you manage Auto-GPT's memory easily. Zilliz Cloud has a broad user base worldwide and was recommended by Nvidia CEO Jensen Huang at GTC 2023. In addition, Zilliz Cloud is OpenAI's designated ChatGPT Retrieval plugin provider.
Here's a guide on how to use Zilliz Cloud as Auto-GPT's memory backend:
Sign in to Zilliz Cloud or sign up for an account if you don't have one.
Create a database and get the public cloud endpoint.
Install
pymilvusby runningpip install pymilvus==2.2.8, and update your.envfile with the following commands:
MEMORY_BACKEND=milvus
MILVUS_ADDR=your-public-cloud-endpoint
MILVUS_USERNAME=your-db-username
MILVUS_PASSWORD=your-db-password
By utilizing Milvus or Zilliz Cloud as the memory backend for Auto-GPT, you can significantly improve its abilities and bring it one step closer to achieving real autonomy.
Limitations to integrating Auto-GPT with a vector database
Incorporating a vector database with Auto-GPT is highly beneficial and necessary for automating tasks and generating commands aligned with the user's objectives. Despite this, there are still some limitations.
When retrieving messages from the vector database, the top-k results are not filtered. As a result, information with low similarity may exist, which could mislead the GPT model and ultimately slow its progress toward achieving the desired outcome.
You can only add and query the context data but cannot delete any data that is no longer relevant or necessary.
Currently, it is not possible to customize the embedding model. The only option available is to utilize the embedding interface provided by OpenAI.
Auto-GPT Explained
Auto-GPT is a new development in AI technology that aims to achieve complete autonomy with minimal or no human input. Although still experimental, Auto-GPT has immense potential, especially when combined with vector databases like Milvus.
As the provider of infrastructure software for AI technologies, we are thrilled to see vector databases play a crucial role in developing and empowering new AI-generated content (AIGC) systems like Auto-GPT. We have many informative articles available if you'd like to learn more about open source vector databases and Milvus, as well as related topics such as Hierarchical Navigable Small Worlds (HNSW). So, let us work together to continue pushing the boundaries of AI and creating a brighter future for AIGC.

Keep Reading

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.