




Getting Started with the Zilliz REST API
Zilliz Cloud is a comprehensive vector database service that enables and accelerates artificial intelligence (AI) and analytics applications at scale. It's built on Milvus, the robust and scalable open-source vector database that can easily handle billions of vector embeddings.
Milvus simplifies handling unstructured data, allowing businesses to analyze and derive insights from massive amounts of data efficiently. By providing you with a scalable, cloud-ready vector database, Zilliz Cloud serves as a one-stop solution.
The use cases for Milvus and Zilliz Cloud are broad and varied. They can power recommendation systems to offer customized shopping experiences by analyzing a customer's browsing and buying patterns. In healthcare, they can aid in building AI models that recognize patterns in large medical datasets, leading to more accurate diagnoses and personalized treatment plans.
One feature Zilliz Cloud adds to Milvus is a REST API for managing your vector databases, with simple methods for manipulating collections, uploading and deleting data, and submitting queries. This post will show you how to use these APIs. Let's get started!
Before we get started
You'll need a few things to follow this tutorial:
First, you'll need a Zilliz Cloud account. If you already have one, you can skip ahead to retrieving your cluster's URL and API key.
Everything covered in this post works with a free account, so you only need to go here and click on Get Started Free. Then, log in to your Zilliz dashboard, and follow the prompts to create a cluster.
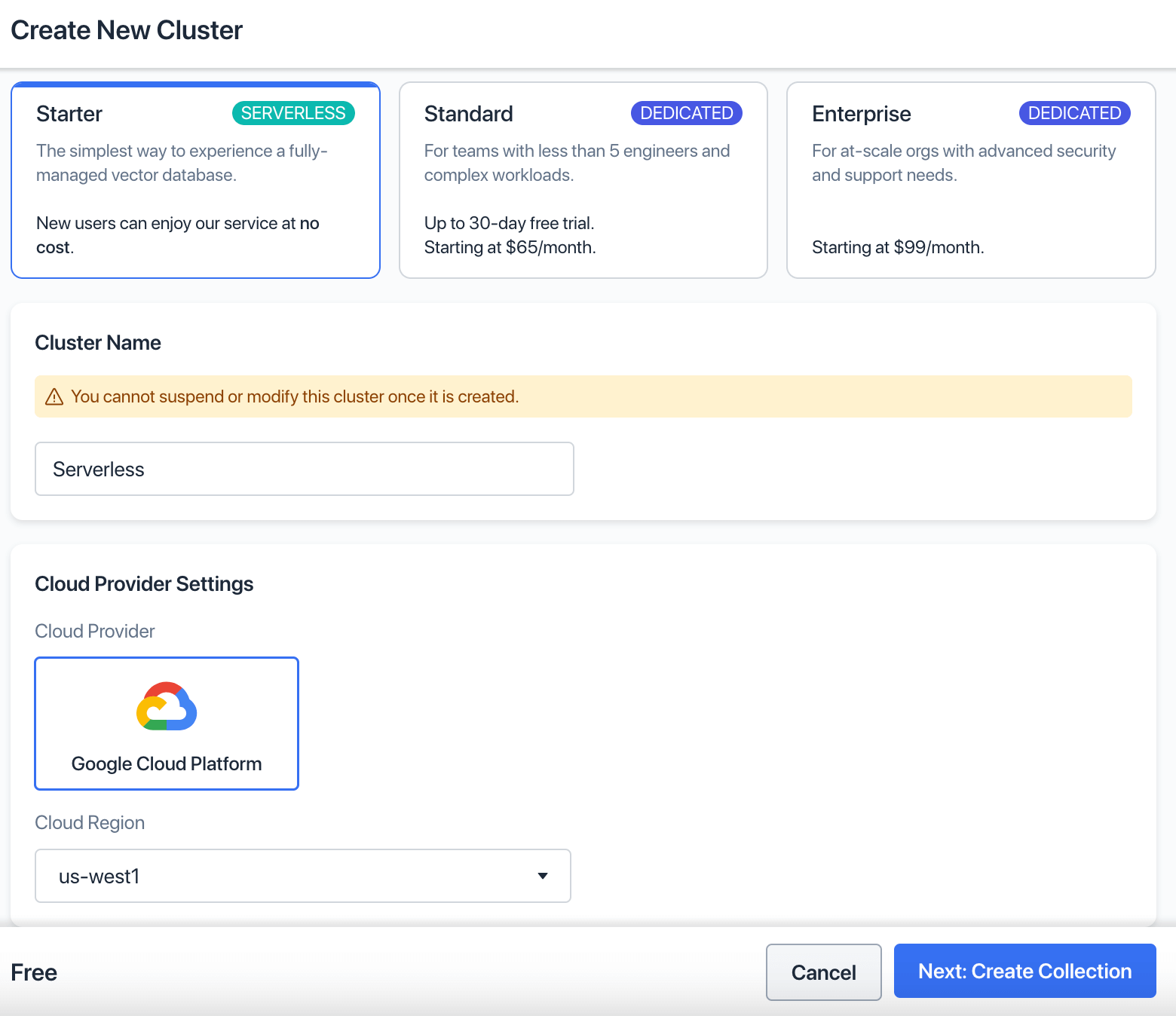 Create new cluster
Create new cluster
Give it a name. The default options are sufficient for this tutorial. Click Next: Create Collection.
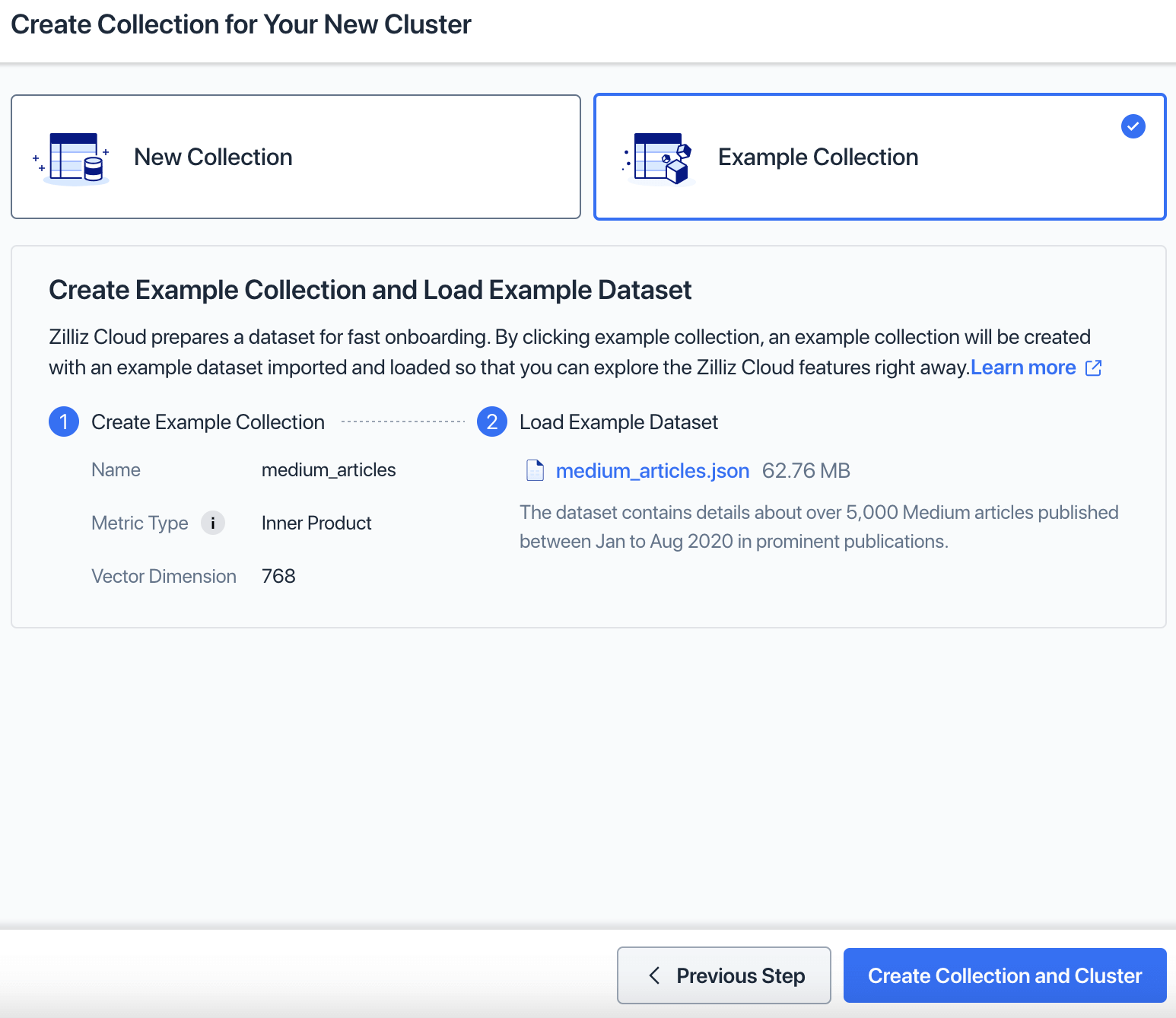 Create collection for your new cluster
Create collection for your new cluster
Select Example Collection and then Create Collection and Cluster.
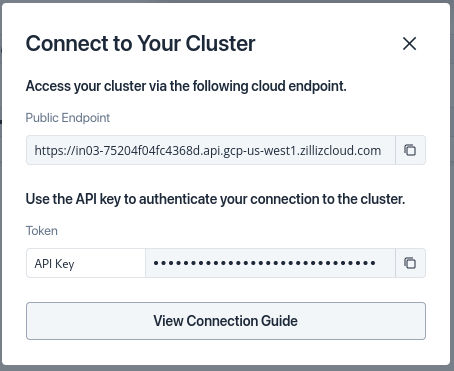 Connect to your cluster
Connect to your cluster
This dialog has your cluster URL and API key. Copy them for later use. You can also retrieve them from your dashboard by selecting the cluster.
The examples in this tutorial will contain code from the Visual Studio Code and the vscode-restclient plugin.
You can find the queries here, in a gist. You can follow along with any HTTP client or use the Playground in your Zilliz dashboard.
Zilliz REST API overview
The Zilliz REST API has methods for managing clusters, collections, and vector data. We will focus on the last two categories: creating collections to store data and managing the data inside the collection.
Collection operations include:
List
Create
Describe
Drop
Vector operations include:
Query
Get
Insert
Delete
Search
API call components
The first part of all your API endpoints is your cluster's public endpoint, which you copied above, followed by the API version and /vector/, which is the top-level directory for API methods.
For example, my cluster's URL started with this:
https://in03-75204f04fc4368d.api.gcp-us-west1.zillizcloud.com/v1/vector
The example calls will use $PUBLIC_ENDPOINT as a placeholder for your cluster's hostname.
Each API call requires two headers:
content_type - this is always application/json. This tells the web server that any data you send is JSON.
Authorization - all requests require this header with your API key.
The example calls will use $YOUR_API_KEY as a placeholder for your cluster's hostname.
Let's start with collections.
Getting started with the Zilliz API
Create, describe, drop, and list collections
First, let's list the collections on your cluster.
The endpoint for collection operations is /collections. A GET call to it elicits a list.
Here's the call in the VS Code Rest Client:
GET https://$PUBLIC_ENDPOINT/v1/vector/collections HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
And here is the response, with all the headers. I'll omit them going forward.
HTTP/1.1 200 OK
content-type: application/json; charset=utf-8
Content-Length: 40
x-ratelimit-remaining-second: 999
x-ratelimit-limit-second: 1000
ratelimit-limit: 1000
ratelimit-remaining: 999
ratelimit-reset: 1 x-sso-plugin-version: v0.0.1
date: Mon, 10 Jul 2023 17:53:12 GMT
vary: Origin access-control-allow-origin: *
requestid: 8c5a2031-afbe-4fa2-9a28-8195e1f20357
strict-transport-security: max-age=31536000; includeSubDomains
x-content-type-options: nosniff via: 1.1 google Alt-Svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000
Connection: close
{
"code": 200,
"data": [
"medium_articles"
]
}
The server returns a success code of 200, and a data field with a vector of collection names.
Let's add a new collection, then retrieve the new list.
For this, POST a document describing the collection to /collections/create.
POST https://$PUBLIC_ENDPOINT/v1/vector/collections/create HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "large_articles",
"dimension": 256,
"metricType": "L2",
"primaryField": "id",
"vectorField": "vector"
}
You can specify five fields to describe your collection:
collectionName - the name is required.
dimension - the number of dimensions for the vector field is also required.
metricType - the type of similarity metrics used to measure similarity among vectors. In this example, the default metric type is L2, representing the Euclidean distance.
primaryField - the default primary field is id.
vectorField - the default vector field is vector.
On success, Zilliz responds with 200 and an empty document.
HTTP/1.1 200 OK
{
"code": 200,
"data": {}
}
List your collections again, and you'll see two names.
HTTP/1.1 200 OK
{
"code": 200,
"data": [
"medium_articles",
"large_articles"
]
}
You can retrieve a description for an existing collection. For this, send a GET with collectionName as a request parameter.
GET https://$PUBLIC_ENDPOINT/v1/vector/collections/describe?collectionName=medium_articles HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
This response is a detailed description of your collection's current state.
HTTP/1.1 200 OK
{
"code": 200,
"data": {
"collectionName": "medium_articles",
"shardsNum": 2,
"description": "demo collection",
"load": "loaded",
"enableDynamicField": true,
"fields": [
{
"name": "id",
"type": "int64",
"primaryKey": true,
"autoId": true,
"description": ""
},
{
"name": "title_vector",
"type": "floatVector(256)",
"primaryKey": false,
"autoId": false,
"description": ""
}
],
"indexes": [
{
"indexName": "vector_idx",
"fieldName": "vector",
"metricType": "L2"
}
]
}
}
Finally, let's wrap up by deleting the collection you just created. This is a POST request to /collections/drop, so instead of passing the name as a parameter, use a JSON document.
POST https://$PUBLIC_ENDPOINT/v1/vector/collections/drop HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "large_articles"
}
The response is similar to what Zilliz sends for creating a collection.
HTTP/1.1 200 OK
{
"code": 200,
"data": {}
}
Request another list of collections, and you'll see that you're back to one. Now, let's work with some data.
Insert data
To insert data, send a POST to /insert a document describing the data.
Looking at the description you retrieved above, the sample collection has two fields:
id - an integer value
title_vector - a vector with 768 floats
So, you need a document with a value that contains these two fields in the data field of the insert request. Data is a list so that you can insert more than one value.
Here's a request with one value:
POST https://$PUBLIC_ENDPOINT/v1/vector/insert HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName":"medium_articles",
"data": [
{
"id": 1,
"title_vector": [
0.2109777665089908,
0.6424190129752343,
(768 values)...
0.9818514815450557
],
},
]
}
Submit this code. Your response is the number of items inserted and their ids.
HTTP/1.1 200 OK
{
"code": 200,
"data": {
"insertCount": 1,
"insertIds": [
"1"
]
}
}
Query, search, and get data
Zilliz REST API has three methods for retrieving data: querying, searching, and getting.
A vector query uses criteria to match entries in the database. Let's start with a query based on the id field.
For this query, you POST a search document to /query. It uses the in operator to match entries with ids of 1 or 2.
POST https://$PUBLIC_ENDPOINT/v1/vector/query HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"filter": "id in (1, 2)"
}
Milvus responds with the value you just inserted, along with data from the sample collection.
HTTP/1.1 200 OK
{
"code": 200,
"data": [
{
"id": 1,
"title_vector": [
0.21097776,
0.5381259,
0.48835102,
0.15038285,
0.94545513,
(768 values)...
]
},
{
"claps": 500,
"id": 2,
"link": "https://medium.com/swlh/how-can-we-best-switch-in-python-458fb33f7835",
"publication": "The Startup",
"reading_time": 6,
"responses": 7,
"title": "How Can We Best Switch in Python?",
"title_vector": [
0.031961977,
0.00047043373,
-0.018263113,
0.027324716,
-0.0054595284,
-0.014779159,
(768 values)...
]
}
}
You can use outputFields to filter the results.
Let's query for a few more documents while cutting back on the size of the results.
POST https://$PUBLIC_ENDPOINT/v1/vector/query HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"filter": "id in (1, 2, 4, 99)",
"outputFields": ["id", "publication"]
}
This result is much easier to read:
HTTP/1.1 200 OK
{
"code": 200,
"data": [
{
"id": 1,
"publication": null
},
{
"id": 2,
"publication": "The Startup"
},
{
"id": 4,
"publication": "The Startup"
},
{
"id": 99,
"publication": "Towards Data Science"
}
]
}
A vector search finds data using a similarity search on vector fields.
Let's submit a search using the same values you used to insert the new value.
Search supports the same filter and outputFields fields as a query, along with a vector field for the search criteria, a limit for search results, and an offset. Omit the offset; you get at least one match.
POST https://$PUBLIC_ENDPOINT/v1/vector/search HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"filter": "id in (1,2,3,4,5,6,7,8,9,99)",
"limit": 5,
"outputFields": ["id", "publication"],
"vector": [
0.2109777665089908,
0.0375565730811388,
0.6424190129752343,
0.9818514815450557,
0.10598735548499805,
...
]
}
}
Since we limited the search to five values, here is the result. Yours will differ based on the values you used to add the new entry.
HTTP/1.1 200 OK
{
"code": 200,
"data": [
{
"distance": 0,
"id": 1,
"publication": null
},
{
"distance": 211.61267,
"id": 2,
"publication": "The Startup"
},
{
"distance": 211.71194,
"id": 5,
"publication": "The Startup"
},
{
"distance": 211.719,
"id": 6,
"publication": "The Startup"
},
{
"distance": 211.9408,
"id": 7,
"publication": "The Startup"
}
]
}
Finally, you can get vectors by posting a list of ids to /get. This get request yields the same results as the query above.
POST https://$PUBLIC_ENDPOINT/v1/vector/get HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"id": [1, 2, 4, 99],
"outputFields": ["id", "publication"]
}
Delete data
Our last operation is deleting vectors. Like get, delete uses the id field. Post a list of ids to /delete to remove their entries from the database.
POST https://$PUBLIC_ENDPOINT/v1/vector/delete HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"id": [1]
}
The result is an empty document.
HTTP/1.1 200 OK
{
"code": 200,
"data": {}
}
Try to retrieve the id to verify it’s gone:
POST https://$PUBLIC_ENDPOINT/v1/vector/get HTTP/1.1
content-type: application/json
Authorization: Bearer $YOUR_API_KEY
{
"collectionName": "medium_articles",
"id": [1],
"outputFields": ["id", "publication"]
}
Milvus will return an empty result set.
Conclusion
In this post, we covered creating a Milvus cluster using Zilliz Cloud and then querying it using the Zilliz REST API. We saw how to create, list, and remove a collection and then how to manipulate data with the Zilliz cloud and the REST endpoints it creates for your Milvus cluster.
Now that you've seen how easy Zilliz Cloud is to deploy and use Milvus, sign up for your free account and get started today!

Keep Reading

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.