




Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
If your business serves customers across multiple continents, you’ve likely felt the pressure of keeping AI systems fast and reliable everywhere. A single cloud-region outage can instantly become a customer-experience outage. Maybe shoppers in Europe will suddenly stop receiving personalized recommendations; riders in Southeast Asia can’t get real-time matching; and employees in Brazil watch their GenAI assistant time out. Even though the outage is regional, the business consequences are real — lost revenue, frustrated users, and a dip in trust that’s hard to win back.
That’s why we’re introducing the Global Cluster in Zilliz Cloud — a built-in global clustering capability that provides true region-level disaster recovery for vector search workloads. Zilliz Cloud is also the industry’s first vector database to offer native global clustering and cross-region fault tolerance. With a Global Cluster, a region outage no longer becomes a business outage: traffic automatically shifts to the nearest healthy region with zero code changes, zero connection-string updates, and no manual failover runbooks. Your AI applications would continue to operate where your users are, even when the infrastructure doesn’t.
Regional Failures Are Rare — But Never Rare Enough
Running a stateful system across continents has always been one of the hardest challenges in distributed infrastructure. As your global footprint expands, you’re constantly managing trade-offs: keeping data safe, keeping latency low for users in every region, and keeping operations manageable for your engineering team. With vector workloads, the difficulty only increases — embeddings are large, updates are continuous, and search queries are extremely sensitive to latency.
Cloud providers engineer their regions for durability, but no region is immune to real-world failures. A fiber cut, a cooling system malfunction, or a cascading network issue can take an entire region offline without warning. And without a true cross-region strategy, that outage becomes your outage immediately. Your service in that region goes dark, and restoring from snapshots or cold backups takes hours — far too slow for AI applications powering real-time user experiences.
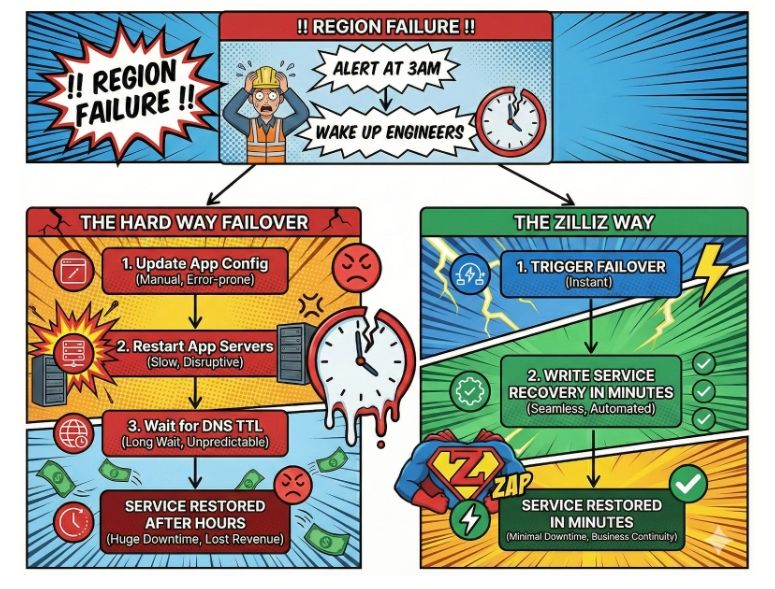
Some teams try to build their own multi-region architecture. While it’s possible, it often creates two major problems: ongoing operational burden and high coordination cost during failures.
Maintenance and operational burden: In day-to-day operation, custom replication scripts, homegrown sync pipelines, and dual-write logic require constant tuning and careful monitoring. Engineers end up fixing replication lag or index drift instead of building product — the work they were hired to do.
Coordination friction during failures: When a region fails, all the hidden complexity surfaces at once. Manual failover isn’t just stressful — it’s chaotic. Teams must restart services, update DNS, verify data freshness, resolve configuration drift, and respond to leadership at the same time, while dashboards are flashing red and customers are already impacted. These are exactly the moments teams hope to avoid.
Zilliz Cloud Global Clusters: Manage Globally, Operate Simply
Running AI systems across continents often means juggling regional clusters, mismatched endpoints, custom routing rules, and failover playbooks that don’t actually hold up during a real incident. Zilliz Cloud Global Clusters remove all of that overhead. It lets you operate a deployment that spans North America, Europe, and APAC as if it were a single, unified system.
From your team’s perspective, there’s no cluster sprawl and no region-by-region babysitting. You interact with one deployment and one global topology. Zilliz takes care of the heavy lifting—replication, routing, failover, and recovery—so your engineers don’t have to.
A Cohesive Multi-Region Architecture
At the core of a Global Cluster is a simple, predictable structure that your team doesn’t need to engineer themselves.
Your Primary cluster acts as the authoritative source of truth, handling all writes and serving the most latency-sensitive operations.
Secondary clusters sit in the regions where you operate — synchronized, warm, and ready. They provide fast local read access for nearby users and stand by to take over instantly if the Primary cluster becomes unavailable.
This lets you support a global user base without forcing your engineers to become experts in distributed systems. The architecture works out of the box, and it scales as your business expands.
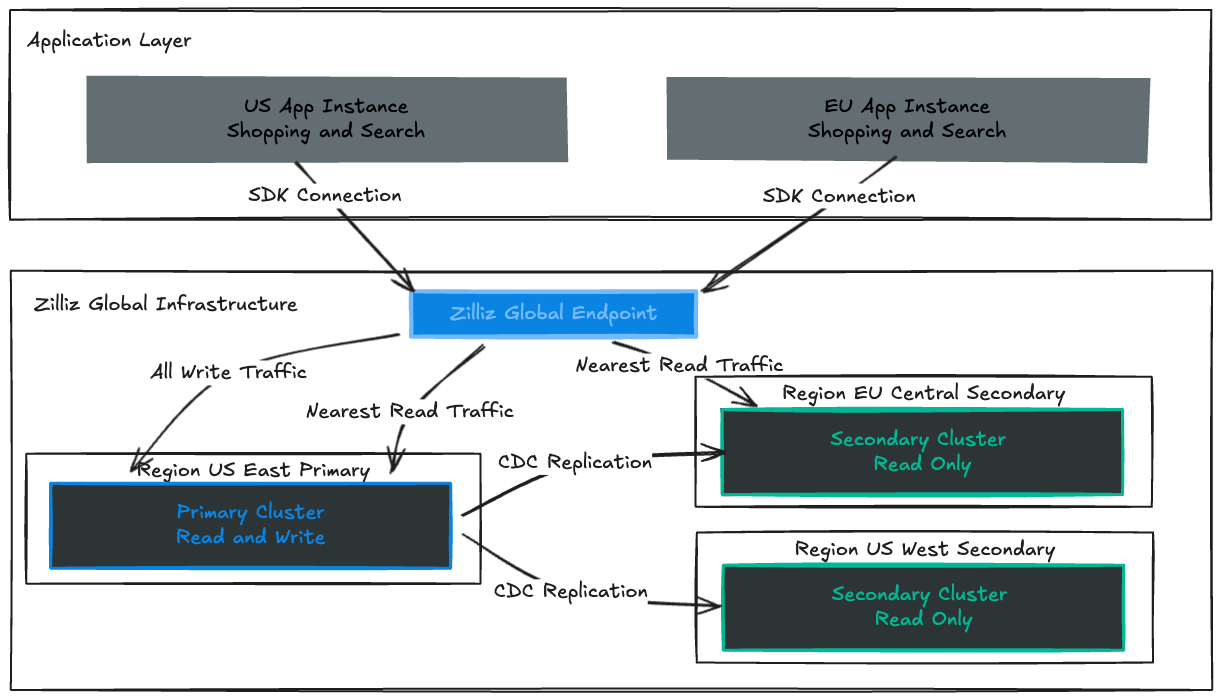
Global Endpoint: Failover Without the Fire Drill
The key to making multi-region operations feel effortless is the Global Endpoint — a topology-aware routing layer that presents your entire deployment as a single, stable entry point.
One Unified URL
Your application connects to one URL. That URL never changes, even as your infrastructure evolves.
Intelligent, topology-aware routing
The Global Endpoint automatically routes traffic to the right destination: writes go to the active Primary, reads go to the nearest healthy Secondary. Whether users are in Singapore, Frankfurt, or São Paulo, they experience consistent performance without needing region-specific configuration.
Zero-code transitions during failover
When an emergency failover or planned maintenance switchover occurs, the transition is instant and invisible. Routing updates immediately, your application keeps running without modification, and your team doesn’t have to scramble to change configurations or redeploy anything. No fire drills. No 3 a.m. emergency patches. Just smooth continuity.
How a Global Cluster Works
When teams think about cross-region replication, the first concern is usually performance: “If I replicate to Frankfurt, won’t that slow down users in Virginia?”
With Zilliz Cloud Global Cluster, the answer is no — writes stay local, fast, and unaffected by network distance.
Asynchronous CDC: The Engine Behind Global Replication
Zilliz Cloud uses an asynchronous Change Data Capture (CDC) pipeline that streams inserts, updates, deletes, and schema changes from the Primary cluster’s Write-Ahead Log to every Secondary region. This design delivers:
Performance Isolation: Replication runs independently from write operations, so write latency on the Primary cluster is driven by local system conditions rather than inter-region network delays.
Eventual Consistency: Data in Secondary regions is kept sufficiently up to date for production workloads, usually lagging by only a few seconds, while maintaining predictable write performance.
Efficient resource usage: Instead of serving solely as standby replicas, Secondary clusters actively handle local read traffic, allowing the same infrastructure to support both high availability and low-latency regional access.
Operational Workflows: Switchover and Failover
Global systems need to handle two very different operational moments: planned data transitions and unexpected disasters. Zilliz provides clear, reliable workflows for both, so your team isn’t forced to improvise during critical events.
Switchover for planned migration
Switchover is used for scheduled maintenance, compliance requirements, or shifting workloads between regions. It lets you move the Primary to a different region with zero data loss.
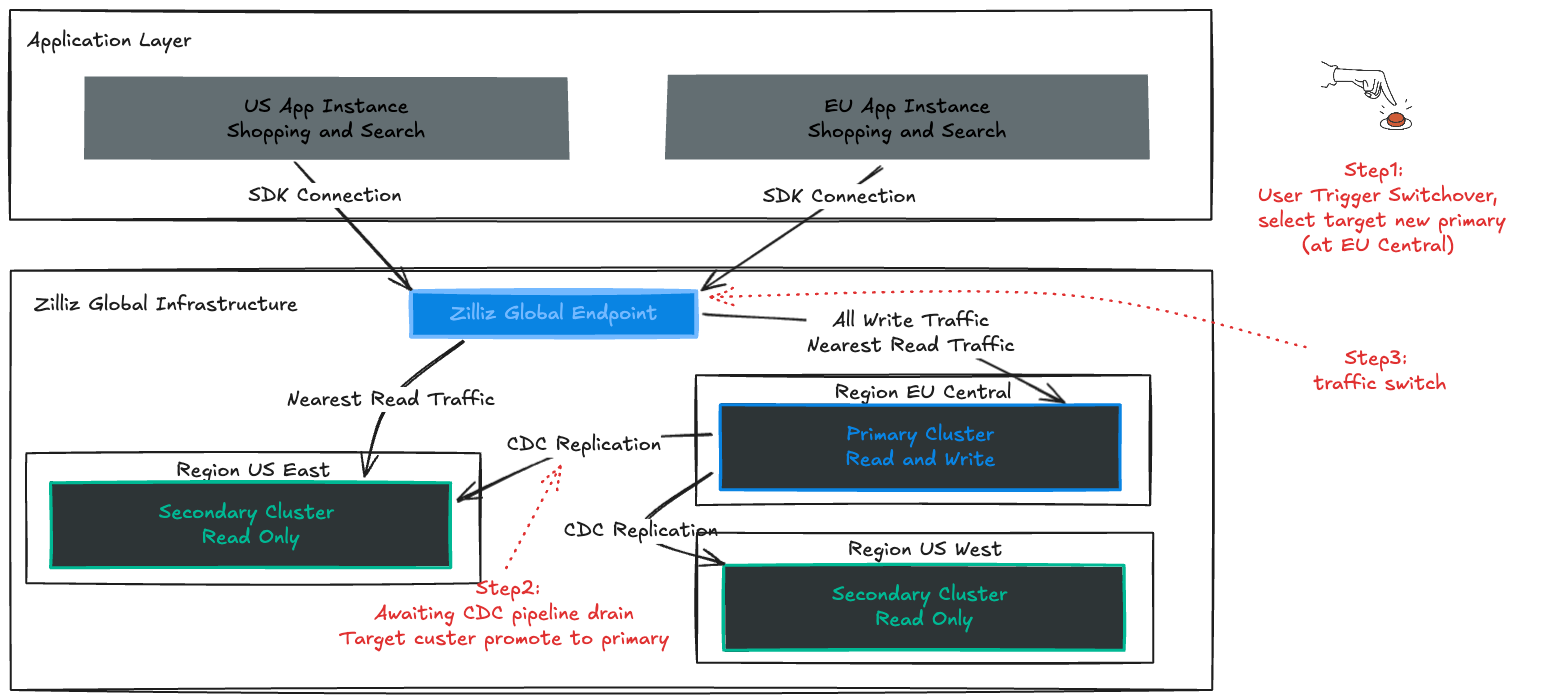
Here is how it works:
Trigger: You initiate a switchover to a target region in the console.
Zero Data Loss: The system briefly pauses writes and waits for replication lag to reach zero, ensuring a perfect handoff (RPO = 0).
Seamless Swap: The Secondary becomes the new Primary. The Global Endpoint updates routing instantly, and applications continue operating without interruption.
Failover for Recovery From a Regional Outage
Failover is designed for the moments no one wants — a region goes dark, a fiber cut isolates a zone, or a cloud provider suffers a major incident.
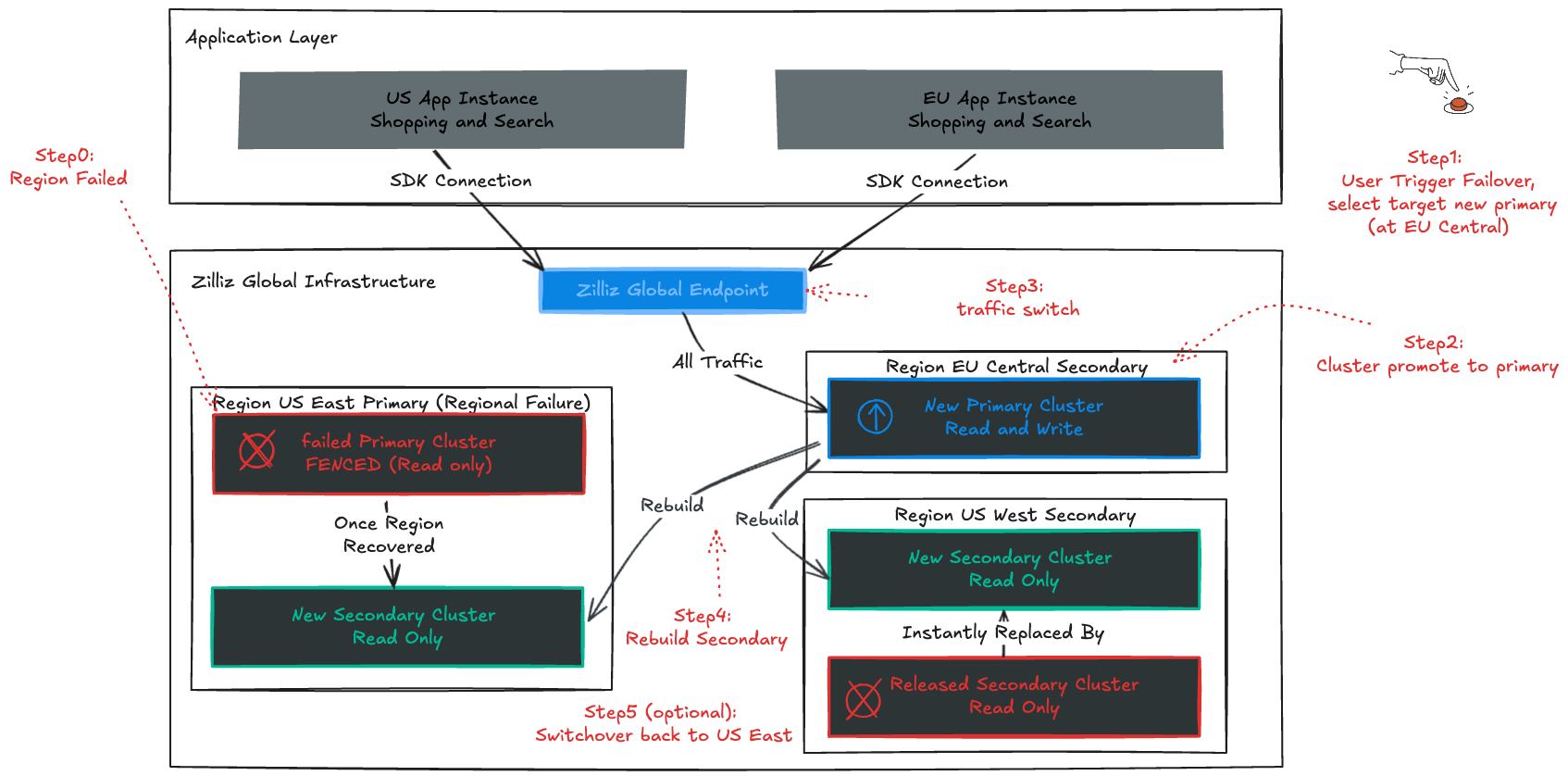
Below is how this workflow works:
Assess: You review the Global Topology Dashboard to check real-time replication status.
Execute: You issue the Force Failover command.
Safety Interlock (I/O Fencing): The system cryptographically "Fences" the unreachable old Primary. This prevents a "Split-Brain" scenario (where the old Primary wakes up and accepts conflicting writes), ensuring data integrity.
Restore: The Secondary becomes Primary. Traffic is redirected. RTO is measured in minutes.
Self-Healing Architecture: Automatic Rebuild
Resilience doesn’t end with failover — true global continuity requires restoring redundancy as soon as the failed region comes back online. Zilliz Cloud Global Cluster automatically closes that loop. When the fenced Primary eventually recovers, the system detects that its data is no longer authoritative. Rather than risking divergence, Zilliz Cloud safely resets the stale state, reprovisions the region, and rebuilds it as a fresh Secondary.
There’s no manual cleanup, no scripts to run, and no complex reindexing. The cluster heals itself in the background, ensuring your global topology returns to full strength without operational effort. Your team manages the response; Zilliz handles the recovery.
Be Ready for Day 2 Now
Global Cluster is built for the realities of “Day 2” — the moments when your system encounters real-world failures, unexpected traffic surges, or a cloud region outage you had no control over. You can’t stop fiber cuts, weather incidents, or provider disruptions from happening. But you can design an architecture that keeps those problems from ever reaching your customers.
With asynchronous CDC replication keeping your data fresh, a Global Endpoint simplifying traffic routing, and rigorous fencing protocols protecting consistency, Zilliz Cloud gives your vector database the resilience modern AI applications demand. This isn’t just a feature — it’s the backbone of business continuity for teams running mission-critical AI at a global scale.
If you’re building AI-powered products for a global audience, it’s time to make your vector infrastructure as resilient as your ambitions.
Contact us to learn more and become an early adopter of Global Cluster.
Build Without Limits: A Closer Look at Zilliz Cloud’s Enterprise-Ready Capabilities
With the introduction of Global Cluster, Zilliz Cloud extends its lead as the most performant, secure, and resilient vector database service for production-scale AI. But resilience is only one part of the story. Zilliz Cloud brings together a comprehensive suite of capabilities designed to help enterprises build intelligent applications with confidence — from security and compliance to search performance and operational simplicity.
Elastic scaling & cost efficiency – One-click deployment, serverless autoscaling, and pay-as-you-go pricing.
Advanced AI search – Vector, full-text, and hybrid (sparse + dense) search with metadata filtering, dynamic schema, and multi-tenancy.
Enterprise-grade reliability & security – 99.95% SLA, SOC 2 Type II and ISO 27001 certifications, GDPR compliance, HIPAA readiness, RBAC, BYOC, audit logs, business critical plan, and now global clusters. See our trust center for more information.
Global availability – Deployments across AWS, GCP, and Azure with sub-100ms latency worldwide.
Seamless migration – Built-in tools to move from Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, AWS S3 vectors, Weaviate, or on-prem Milvus.
Natural language querying – MCP server support for intuitive queries without complex APIs.
Taken together, these capabilities make Zilliz Cloud more than a vector database — a fully managed, production-ready platform for building and scaling AI applications without limitations.

Keep Reading

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.