




Building Production Ready Search Pipelines with Spark and Milvus
Building a scalable vector search pipeline in production is not as easy as building its prototype. When working on a prototype, we often deal with only a small amount of unstructured data. However, when moving the prototype into production, we typically need to handle millions or billions of unstructured data and high query volumes. Therefore, a robust solution is needed for the efficient execution of common vector search pipeline operations such as data ingestion and information retrieval.
In a recent talk, Jiang Chen, Head of Ecosystem & AI Platform at Zilliz, presented a step-by-step process to build an efficient and production-ready vector search pipeline. This article will discuss the main points of the talk, which consist of three topics:
Workflow of information search in traditional and Retrieval Augmented Generation (RAG) settings.
Building a scalable vector search pipeline in a RAG system with Milvus and Spark.
Advice to improve the quality of your RAG system.
Without further ado, let’s talk about the first main topic and we start with the workflow of information search in a traditional setting.
Workflow of a Traditional Information Search
Before the advancements of deep learning, traditional information retrieval or search systems relied heavily on tags and manual labeling. Consider the case of online shops: they relied on product tags to give customers the most suitable products according to their needs. Therefore, online shops need a scalable and efficient search pipeline that enables them to serve a large number of customer queries every day.
To accommodate this demand, the traditional search system's architecture is normally divided into two components: one for offline data ingestion and one for online query serving.
Offline Data Ingestion
The main goal of offline data ingestion is to load all the data into a database. As a first step of this process, the data is gathered from one or multiple sources, such as internal documents or the Internet. Once we can fetch the data, we can continue with data tagging. Finally, the tagged data can be indexed and loaded into the database.
Let's use the online shop example to illustrate the workflow. We can obtain product descriptions from the Internet by crawling the web. Next, once we have the descriptions, we create tags that represent those product descriptions, such as 'clothes', 'dress', 'formal dress', 'party dress', etc. Then, we build the index of the tags, product descriptions, prices, and other metadata before loading them into an unstructured database. Finally, we push this database to the serving environment.
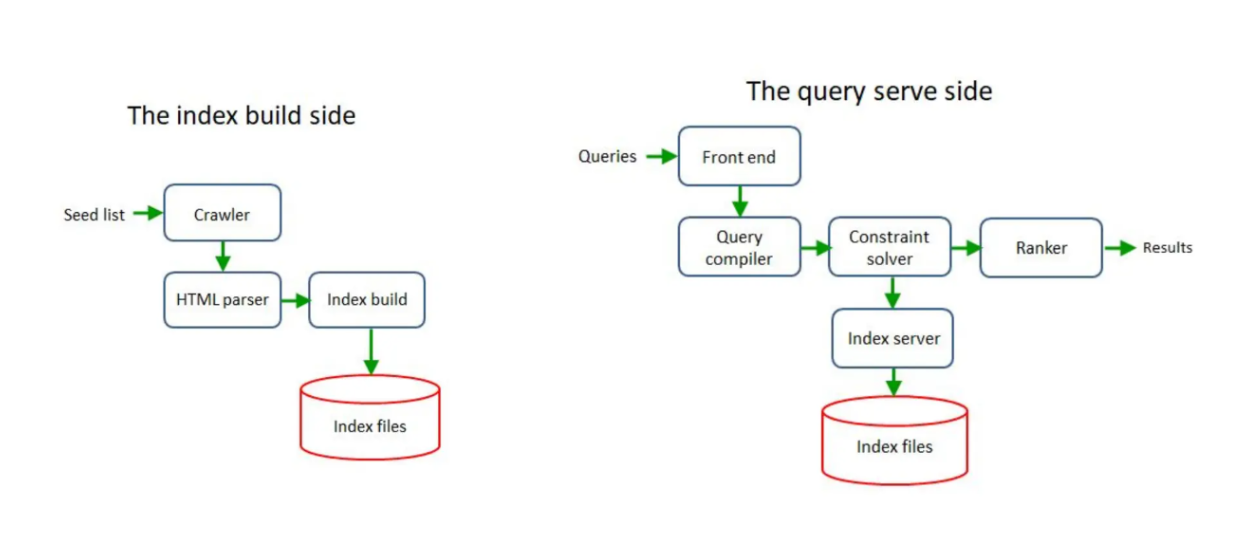 Two components of a traditional information search architecture
Two components of a traditional information search architecture
Online Query Serving
The main goal of the second component is to serve the queries from customers and perform information retrieval from the database we have created in the previous workflow.
The process starts from the front-end and query compiler to synthesize the user's query into a set of tags. Next, the system will use the generated tags as inputs for similarity search. The top k entries in the database with the most similar keywords or tags will then be fetched and ranked using an algorithm that varies based on use cases. The ranked result will finally be returned to the user.
The main drawback of traditional information retrieval and search systems is the lack of semantic understanding. Tags or manually created labels couldn't capture the semantic meaning and the intent of the user's query, which might lead to inaccurate search results. Also, manually tagging each entry would be cumbersome if we have a massive amount of data.
The Workflow of RAG as the New Information Search
The rapid advancements of deep learning have significantly changed the landscape of information retrieval processes. With the help of embedding models and large language models (LLMs) like GPT, Claude, LLAMA, and Mistral, the semantic meaning of a user's query can be effectively captured, eliminating the need for manually creating labels or tags for each data entry.
With embedding models, unstructured data can be transformed into vector embeddings, which consist of n-dimensional vectors. The dimensionality of the embedding depends on the model used. These embeddings carry semantic meaning of the data they represent and therefore, the similarity between any two embeddings can be easily calculated using metrics like cosine distance. The intuition is that embeddings that carry similar meanings will be placed closer to each other in the vector space.
 Example of vector embeddings that carry similar semantic meaning in a 2D vector space
Example of vector embeddings that carry similar semantic meaning in a 2D vector space
Once we have the embeddings, they can be directly ingested into a vector database like Milvus, completing the data ingestion part. Afterwards, the information retrieval process can be conducted.
When a user query is received, it’ll be transformed into an embedding using the same embedding model during data ingestion part. Next, the pipeline performs a vector search operation and fetches the top k most similar embeddings from the database. In Retrieval Augmented Generation (RAG) context, these similar embeddings are then used as contexts for the LLM to answer the user's query.
 RAG workflow
RAG workflow
Vector Search Pipeline with Spark and Milvus
RAG is a novel approach to improve the answers accuracy generated by an LLM by providing it with relevant contexts fetched from a vector search. However, building a production-ready RAG application is challenging due to scalability issues.
When deploying a RAG application in production, you'll most likely be dealing with millions or even billions of unstructured data. Additionally, your RAG system will receive thousands or even more queries from customers. Therefore, an efficient and scalable solution is needed to handle these problems effectively, and this is where Apache Spark can be useful.
In this section, we'll build a search pipeline using Milvus and Spark. Milvus is an open-source vector database that enables us to perform vector search on massive amounts of data in seconds. Meanwhile, Spark is a powerful open-source distributed computing framework particularly useful for processing and analyzing large datasets in a fast and efficient way.
Let's start by installing Milvus. There are several ways to install Milvus, but if you want to use Milvus in a production environment, it’s best if you install and run Milvus in Docker with the following commands:
# Download the installation script
$ curl -sfL <https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh> -o standalone_embed.sh
# Start the Docker container
$ bash standalone_embed.sh start
As an open-source vector database, Milvus offers seamless integrations with many tools and AI frameworks, making it easy to build production-ready AI-powered applications like RAG. Apache Spark is one of the frameworks that can be used together with Milvus to efficiently scale data ingestion and query retrieval processes.
 Example of a vector search pipeline workflow with Milvus and Spark
Example of a vector search pipeline workflow with Milvus and Spark
Since Spark is a distributed processing system, it is able to distribute data processing tasks across multiple computers in a batch. This feature speeds up data processing when dealing with massive amounts of data, such as when deploying a RAG application in production. Thanks to this integration, we can also move data between Milvus and other database services like MySQL.
To install Apache Spark, please refer to their latest installation documentation. Once you have installed Spark, you will also need to install the spark-milvus jar file.
wget <https://github.com/zilliztech/spark-milvus/raw/1.0.0-SNAPSHOT/output/spark-milvus-1.0.0-SNAPSHOT.jar>
Once you have downloaded the spark-milvus jar file, you can add it as a dependency by following these steps:
# For pyspark
./bin/pyspark --jars spark-milvus-1.0.0-SNAPSHOT.jar
# For spark-shell
./bin/spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar
And now we’re ready to integrate Milvus with Spark. In the following example, we’ll show you how you can ingest data from Spark dataframe directly to Milvus.
import org.apache.spark.sql.{SaveMode, SparkSession}
import io.milvus.client.{MilvusClient, MilvusServiceClient}
import io.milvus.grpc.{DataType, FlushResponse, ImportResponse}
import io.milvus.param.bulkinsert.{BulkInsertParam, GetBulkInsertStateParam}
import io.milvus.param.collection.{CreateCollectionParam, DescribeCollectionParam, FieldType, FlushParam, LoadCollectionParam}
import io.milvus.param.dml.SearchParam
import io.milvus.param.index.CreateIndexParam
import io.milvus.param.{ConnectParam, IndexType, MetricType, R, RpcStatus}
import zilliztech.spark.milvus.{MilvusOptions, MilvusUtils}
import zilliztech.spark.milvus.MilvusOptions._
import org.apache.spark.SparkConf
import org.apache.spark.sql.types._
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.util.CaseInsensitiveStringMap
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.log4j.Logger
import org.slf4j.LoggerFactory
import java.util
import scala.collection.JavaConverters._
object Hello extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("HelloSparkMilvus")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "a", Seq(1.0,2.0,3.0,4.0,5.0)),
(2, "b", Seq(1.0,2.0,3.0,4.0,5.0)),
(3, "c", Seq(1.0,2.0,3.0,4.0,5.0)),
(4, "d", Seq(1.0,2.0,3.0,4.0,5.0))
).toDF("id", "text", "vec")
// set milvus options
val milvusOptions = Map(
"milvus.host" -> "localhost" -> uri,
"milvus.port" -> "19530",
"milvus.collection.name" -> "hello_spark_milvus",
"milvus.collection.vectorField" -> "vec",
"milvus.collection.vectorDim" -> "5",
"milvus.collection.primaryKeyField", "id"
)
sampleDF.write.format("milvus")
.options(milvusOptions)
.mode(SaveMode.Append)
.save()
}
In the code snippet provided above, we ingested a Spark DataFrame with three fields: an ID, a text, and a vector embedding into a collection called "hello_spark_milvus". The embeddings consist of 5-dimensional vectors, and we used the ID as the primary key of our collection.
We also need to provide several pieces of configuration about our Milvus database inside milvusOptions map:
milvus.hostandmilvus.port: Milvus server and port. If you run Milvus in Docker, the default port is 19530.milvus.collection.name: the collection name inside the Milvus database where the data will be ingested.milvus.collection.vectorField: the column name of our data which contains the vector embedding.milvus.collection.vectorDim: the dimensionality of our vector embedding.milvus.collection.primaryKeyField: the column name of our data which contains the primary key.
If you'd like to know more about the different kinds of Milvus options that you can adjust, check out the Milvus documentation page.
Now that we have ingested data into the Milvus database, we need to specify the indexing method for our collection. Milvus supports various indexing methods, such as the regular Flat index, Inverted Flat Index (IVF), Hierarchical Navigable Small World (HNSW), and many more.
In the following example, we'll use AUTOINDEX, which is a customized version of HNSW. As the metric during vector search, we'll use L2 distance.
val username = <YOUR_MILVUS_USER>
val password = <YOUR_MILVUS_PASSWORD>
val connectParam: ConnectParam = ConnectParam.newBuilder
.withHost("localhost")
.withPort("19530")
.withAuthorization(username, password)
.build
val client: MilvusClient = new MilvusServiceClient(connectParam)
val createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName("hello_spark_milvus")
.withIndexName("index_name")
.withFieldName("vec")
.withMetricType(MetricType.L2)
.withIndexType(IndexType.AUTOINDEX)
.build()
val createIndexR = client.createIndex(createIndexParam)
println(createIndexR)
Next, we need to load our “hello_spark_milvus” collection before we’re able to do vector search on it.
import io.milvus.param.collection.{CreateCollectionParam, DescribeCollectionParam, FieldType, FlushParam, LoadCollectionParam}
// Load collection, only loaded collection can be searched
val loadCollectionParam = LoadCollectionParam.newBuilder().withCollectionName("hello_spark_milvus").build()
val loadCollectionR = client.loadCollection(loadCollectionParam)
println(loadCollectionR)
Now that we have ingested the data into Milvus and created an index, finally we are ready to perform a vector search operation. We will use the first row of the Spark DataFrame we created earlier as the input vector.
// Search, use the first row of input dataframe as search vector
val fieldList: util.List[String] = new util.ArrayList[String]()
fieldList.add("vec")
val searchVectors = util.Arrays.asList(sampleDF.first().getList(2))
val searchParam = SearchParam.newBuilder()
.withCollectionName("hello_spark_milvus")
.withMetricType(MetricType.L2)
.withOutFields("text")
.withVectors(searchVectors)
.withVectorFieldName("vec")
.withTopK(2)
.build()
val searchParamR = client.search(searchParam)
println(searchParamR)
As you can see, we need to provide several method calls inside SearchParam.newBuilder() method to perform a vector search operation, such as:
.withCollectionName(): the collection name where the vector search is performed..withMetricType(): the metric used to perform vector search..withOutFields(): the output fields in a collection to return the result..withVectors(): the input or query vector..withVectorFieldName(): the field in a collection that contains vector embeddings..withTopK(): return the top k entries that have the most similar embeddings to the query vector.
In a RAG application, the top k most similar entries will be used as contexts to be passed alongside the query into the LLM. This way, the LLM can use the contexts to generate an accurate answer to the query.
There are many more advanced use cases where you can leverage Milvus integration with Spark. For example, you can read data from your regular database like MySQL, transform them into vector embeddings, and ingest those embeddings into Milvus. You can explore these use cases in this GitHub repository or in this Milvus notebook demo.
Good RAG Comes from Good Data
Milvus's integration with many AI toolkits and frameworks simplifies the development of production-ready RAG (Retrieval Augmented Generation) applications. However, after deploying a RAG system in production, it's important to continuously monitor the quality of the responses generated by the system.
If the response quality needs to be improved, it's crucial to first examine the fundamentals before diving into more complex algorithms. The key focus should be on the quality of the data source used by the RAG system.
When evaluating the data source, consider the following questions:
Do we have the required data to answer the user's queries in our database?
Have we collected all the necessary data into our database?
Have we performed the correct data preprocessing steps before ingesting the data into our database (e.g., data parsing, data cleaning, chunking, using appropriate embedding models)?
Once you have verified the quality of the data source, you can then consider improving the quality of the RAG system from an algorithmic perspective. There are several ways to enhance the performance of a RAG system, such as:
Using more powerful embedding models: Experiment with different pre-trained or custom-trained embedding models to find the one that best captures the semantic relationships in your data.
Implementing query routing and third-party tool integration: If the embedding model is not the issue, you can improve the RAG system by applying an agent for query routing and integrating with additional tools or data sources.
By focusing on the fundamentals and continuously iterating on the data source and algorithmic components, you can ensure that your production-ready RAG application delivers high-quality responses to your users.
Conclusion
The seamless integration of Milvus with various frameworks like Spark makes it easy for us to build and deploy a scalable LLM-powered application. Spark's ability to distribute data processing tasks across multiple computers in batches really speeds up data processing operations. This feature is particularly helpful when we want to ingest massive amounts of data into our vector database or when our application is dealing with a large number of user queries at the same time.
Once we ingest data into our Milvus vector database and receive a user's query, we can then perform a vector search. This process is crucial to fetch the most relevant contexts among the data inside our database to be passed into an LLM to generate highly contextualized answers.
Keep Reading

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.