




How VIPSHOP Elevated Its E-commerce Recommender 10x Faster with Milvus
Recommender systems have become indispensable for e-commerce success, acting as a strategic catalyst to enhance user experience, stimulate customer engagement, and boost business revenue. VIPSHOP, the pioneering online retailer in China, faced a critical juncture. With a rapidly growing customer base surpassing 52 million and an annual surge of 270 million orders, its legacy Elasticsearch-based recommender system proved sluggish and inadequate. The call for a faster, personalized solution at VIPSHOP grew more urgent. In this post, we’ll delve into the challenges VIPSHOP confronted and how the adoption of Milvus improved its recommendation system.
The quest for an efficient vector search engine
The bedrock of an agile recommender system lies in its vector search capability, which is crucial for delivering semantically similar results promptly. VIPSHOP initially relied on Elasticsearch for vector search but soon faced challenges as its product range expanded. The legacy system encountered two major stumbling blocks—prolonged response times and soaring maintenance costs.
The slowdown was attributed to Elasticsearch's high latency in retrieving Top-K results, averaging 300 ms. The final response time was seconds long, negatively impacting the user experience when coupled with subsequent processing stages. Additionally, the shared indexes turned into a complex labyrinth, escalating construction and maintenance costs. Despite attempts to revitalize Elasticsearch with a hashing plugin, the results fell short. The quest for a new vector searching stack became the team's encore for a responsive recommender system.
VIPSHOP chose Milvus to upgrade its recommender system
Milvus is an open-source vector database that promises speed and a symphony of features capable of handling billions of vector embeddings. It also offered the allure of distributed deployment, multi-language SDKs, and read/write separation—a composition that outshone Elasticsearch and other vector search technologies. After careful consideration and evaluation, VIPSHOP chose Milvus to rebuild its recommender system.
How Milvus functions in VIPSHOP’s recommender system
The diagram provides a glimpse into the architecture of VIPSHOP's recommendation system powered by Milvus.
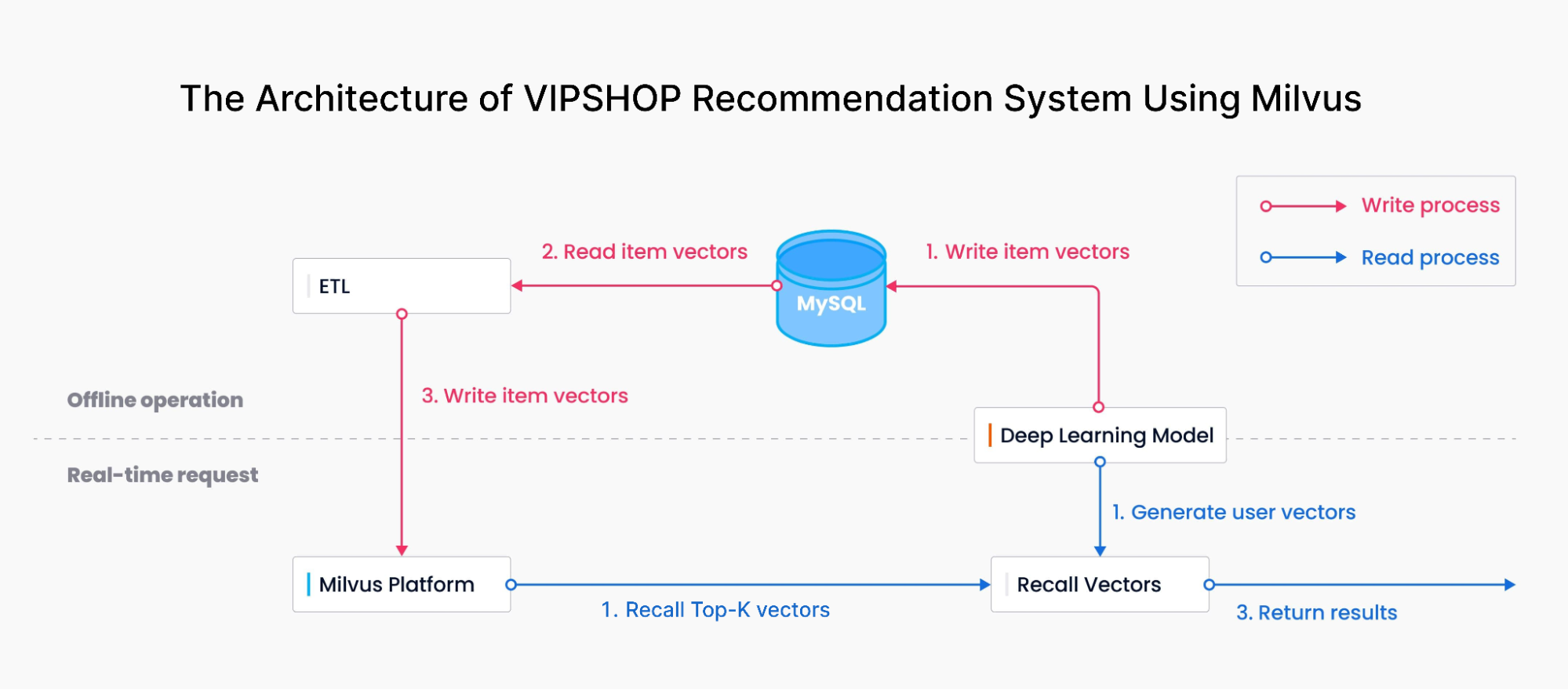
A deep learning model converts product features into vector embeddings. These embeddings are then ingested into Milvus for storage and retrieval using MySQL and an ETL tool.
Simultaneously, consumers' queries and purchase preferences undergo a similar transformation into vector embeddings, initiating a similarity search within Milvus. Here, Milvus performs an Approximate Nearest Neighbors (ANN) search by assessing spatial distances between consumer and product vectors, delivering the Top-K most relevant results. Finally, this outcome is presented to consumers.
Milvus showcased remarkable efficiency in both data update and recall processes.
Data update and recall are pivotal for swift vector search and personalized recommendations within this intricate orchestration. The data update procedure ensures seamless synchronization, involving tasks such as writing vector data, detecting data volumes, index construction, index pre-loading, and alias management. On the other hand, the recall process, integral to product recommendations, entails retrieving vectors related to consumer queries and purchase behaviors, calculating their distances, and merging results.
Milvus showcased remarkable efficiency and agility in both data update and recall processes, achieving an average latency of just 10ms. The table below illustrates the performance metrics of three primary Milvus services related to data update and recall.
| Service | Role | Input Parameters | Output parameters | Response latency |
|---|---|---|---|---|
| User vectors acquisition | Obtain user vector | user info + query | user vector | 10 ms |
| Milvus Search | Calculate the vector similarity and return Top-K results | user vector | item vector | 10 ms |
| Scheduling Logic | Concurrent result recalling and merging | Multi-channel recalled item vectors and the similarity score | Top-K items | 10 ms |
Elevating user experiences with 10x faster recommendations and vast cost reduction
Integrating Milvus into VIPSHOP's recommender system has reshaped the landscape, ushering in a new era of user experiences.
10x Faster Overall Responses: Milvus slashed overall vector query times below 30ms. This extraordinary speed is a tenfold acceleration from the previous Elasticsearch solution, ensuring users receive lightning-fast recommendations.
Enhanced Capability to Handle Business Data Surge: Milvus's distributed deployment and horizontal scaling capabilities empowered VIPSHOP's recommender system to manage escalating data volumes and user queries effortlessly. The independence to scale computing and storage aligns seamlessly with VIPSHOP's evolving needs, providing unparalleled flexibility.
Reduced Maintenance Costs: Milvus, with its streamlined query mechanisms, helped VIPSHOP reduce the maintenance costs for the recommender system. This reduction enhances operational efficiency and contributes to the overall cost-effectiveness of the platform.
Challenges with Milvus and lessons learned
In their journey with Milvus, VIPSHOP's team also encountered some challenges, which they solved with the help of Zilliz’s technical support team. In this section, they shared the lessons they learned and the insights they gained for optimizing system performance. * Adopting a read-write separation deployment strategy can enhance the overall system performance when read operations take precedence.
The Milvus Java client lacks an inherent reconnection mechanism because it resides in memory within the recall service. The VIPSHOP team crafted a dedicated connection pool to ensure consistent connectivity, implementing a heartbeat test between the Java client and the server.
Occasional slow queries in Milvus are attributed to the insufficient warm-up of new collections. To tackle this challenge, the VIPSHOP team implemented a strategy of simulating queries on the newly created collection.
Achieving the right balance between retrieval performance and accuracy is crucial. The VIPSHOP team recommends conducting meticulous pressure testing experiments tailored to the specific business scenario. Setting a reasonable threshold value is vital to optimize these parameters effectively.
In scenarios involving static data, an efficient approach involves initially importing all data into the collection and deferring the index-building process to a later stage.

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.