




Webinar Recap: Boost Your LLM with Private Data Using LlamaIndex
The popularity of ChatGPT has demonstrated the capabilities of large language models (LLMs) in generating knowledge and reasoning. However, ChatGPT is pre-trained on publicly available data, which may not provide specific answers and results relevant to your business. So how can we best augment our LLMs with private data? LlamaIndex is one of the most popular solutions. It is a simple, flexible, centralized interface connecting your external data and LLMs.
In our recent webinar, Jerry Liu, Co-founder and CEO of LlamaIndex, explained how LlamaIndex could boost your LLMs with private data. In addition, Frank Liu, Machine Learning Architect and Director of Operations at Zilliz, also shared his insights on LLMs. Join me in exploring the key takeaways from this webinar and addressing some of the unanswered questions from the audience.
Fine-tuning and in-context learning
"How to enhance LLMs with private data" is a question many LLM developers would ask. In the webinar, Jerry discussed two methods: fine-tuning and in-context learning. Fine-tuning requires retraining the network with private data, but it can be costly and lack transparency. Additionally, it may only be effective in some cases. On the other hand, in-context learning involves pairing a pre-trained model with external knowledge and a retrieval model to add context to the input prompt. However, challenges arise in combining retrieval and generation, retrieving appropriate context, and managing extensive source data. LlamaIndex is a toolkit designed to address the challenges of in-context learning.
What is LlamaIndex?
LlamaIndex is an open-source tool that provides the central data management and query interface for your LLM applications. Its toolkit contains three main components:
- Data connectors for ingesting data from various sources.
- Data indices for structuring data for different use cases.
- A query interface for inputting prompts and receiving the knowledge-augmented output.
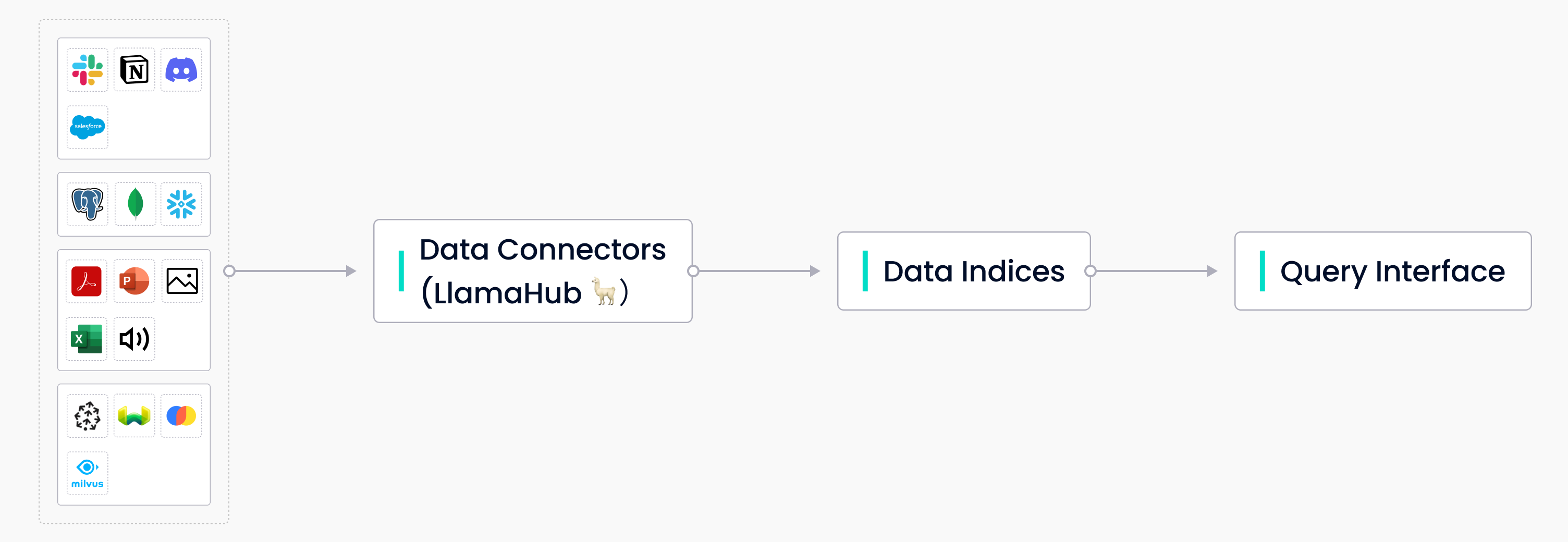 Three main components of LlamaIndex
Three main components of LlamaIndex
LlamaIndex is also a valuable tool for developing LLM applications. It operates like a black box, taking in detailed query descriptions and providing rich responses that include references and actions. LlamaIndex also manages interactions between the language model and private data to provide accurate and desired results.
 LlamaIndex in context
LlamaIndex in context
How LlamaIndex’s vector store index works
LlamaIndex has various indices, including the list index, the vector store index, the tree index, and the keyword index. Jerry used the vector store index in the webinar to show you how LlamaIndex indices work.
The vector store index is a popular mode of retrieval and synthesis that pairs a vector store with a language model. A set of source documents are ingested, split into text nodes, and stored in the vector store with an embedding attached to each node. When you make a query, a query embedding searches the vector store for the top-k most similar nodes, these nodes are then used in the response synthesis module to generate a response.
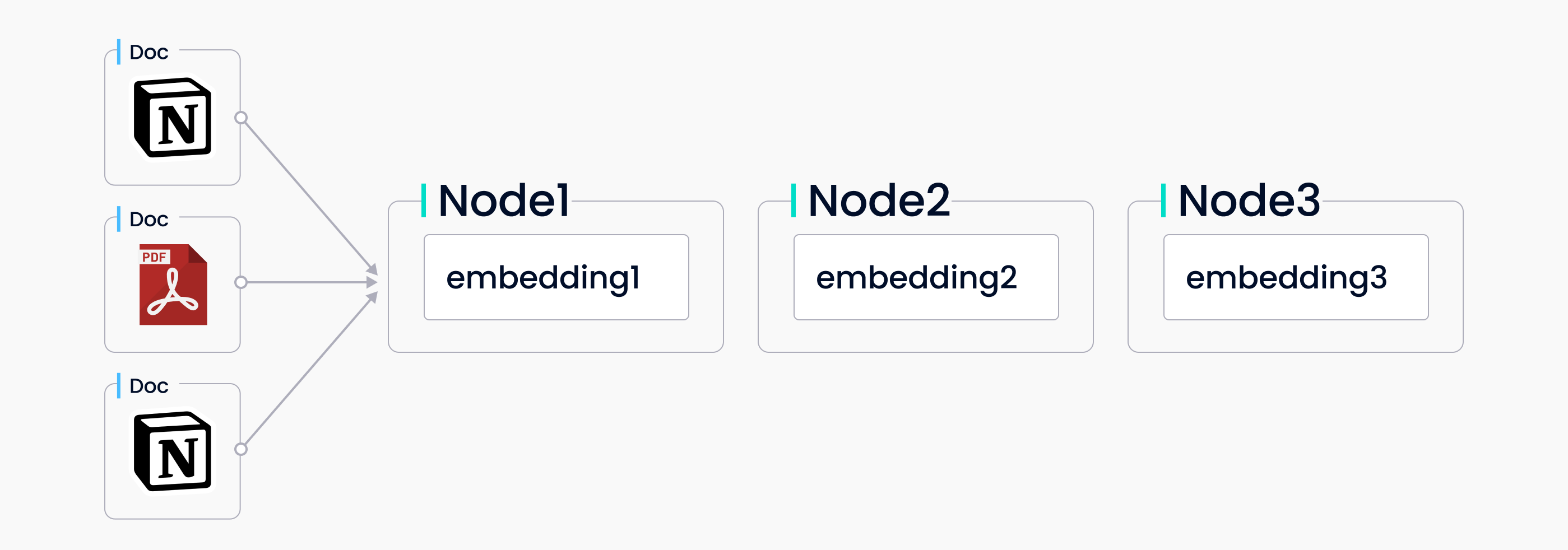 Data ingestion to LlamaIndex
Data ingestion to LlamaIndex
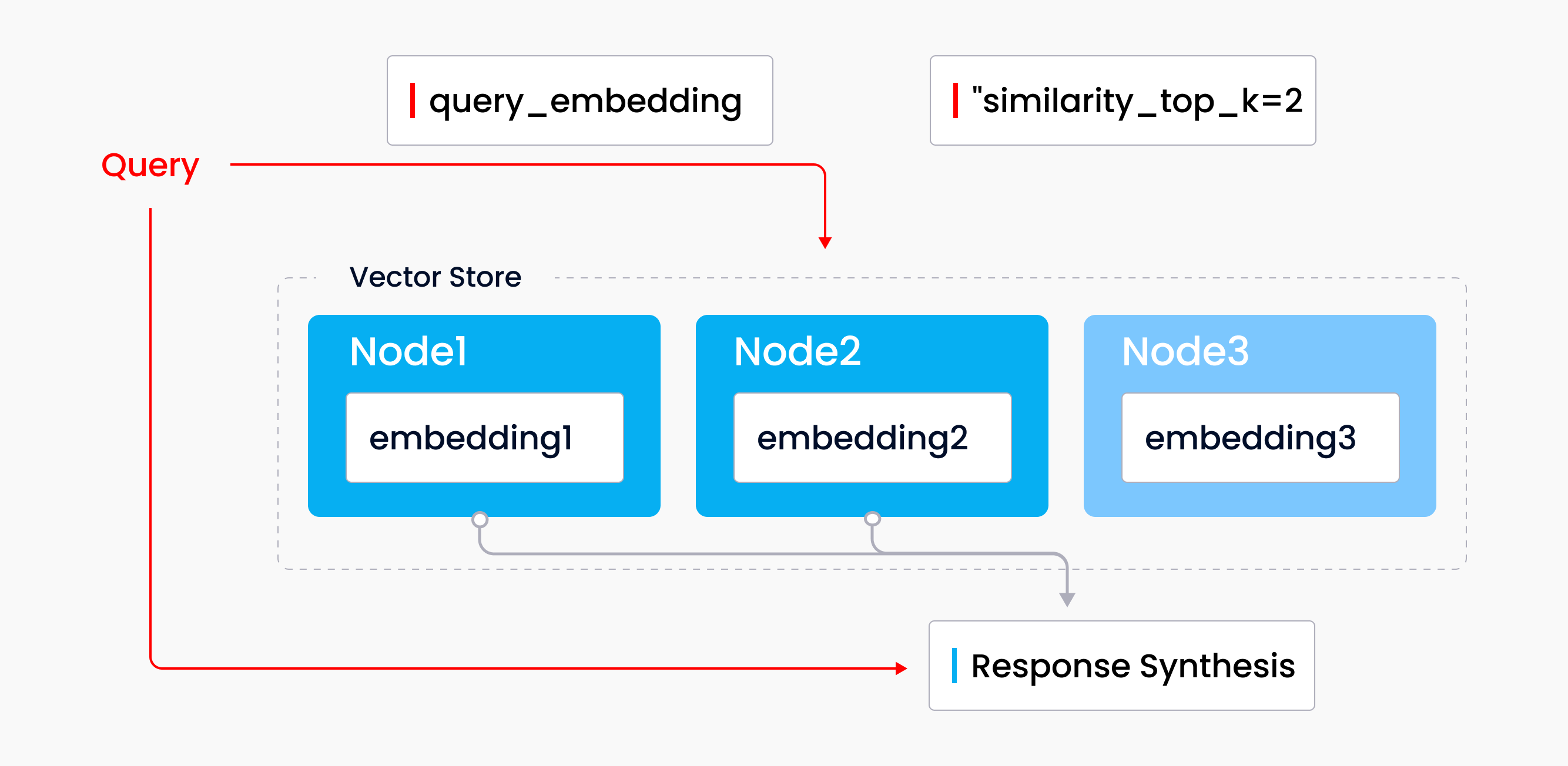 Querying through the vector store index
Querying through the vector store index
Using a vector store index is the best approach to introduce similarity into your LLM application. This index type is ideal for workflows that compare texts for semantic similarity. For instance, a vector store index would be suitable for asking questions about a particular open-source software.
The integration of Milvus and LlamaIndex
LlamaIndex provides numerous integrations that are both powerful and lightweight. In the webinar, Jerry highlighted the integration of Milvus and LlamaIndex.
Milvus is a vector database that is open-source and capable of handling vast datasets that contain millions, billions, or even trillions of vectors. With the integration, Milvus acts as the backend vector store for embeddings and text. Setting up the integration is simple: inputting several parameters, wrapping them in some storage context, and then putting them into the vector store index. Querying the index is done through the query engine, and you’ll get the answers you need.
Zilliz Cloud is a fully-managed and cloud-native service for Milvus, and the integration of LlamaIndex and Zilliz Cloud is also available.
LlamaIndex use cases
In the webinar, Jerry also shared many popular use cases of LlamaIndex, including:
- Semantic search
- Summarization
- Text to SQL (structured data)
- Synthesis over heterogeneous data
- Compare/contrast queries
- Multi-step queries
- Exploiting temporal relationships
- Recency filtering / outdated nodes
For detailed descriptions and information, watch the complete webinar recording.
Q&A
We received many questions from our audience during the webinar and appreciated their engagement. Jerry answered some of the questions during the Q&A session, but due to time constraints, some were left unanswered. Below, we have compiled a list of the most asked questions, and the unanswered questions, along with Jerry's answers.
Q: What do you think about OpenAI’s plugins, and how would LlamaIndex work with them?
This is a good question. We see ourselves on both sides of the plugin landscape. On the one hand, we see ourselves as a really good plugin that can be called by any outer agent abstraction (whether it's ChatGPT, LangChain, or more). A client agent would pass an input request to us, and we would figure out how to best execute that request under the hood. For instance, we're a plugin in the chatgpt-retrieval-plugin repo. On the client side, we support integrating with any services that implement the chatgpt-retrieval-plugin - a "vector store" abstraction.
Q: You mentioned trade-offs in performance and latency. What are some bottlenecks and challenges in that area that you encounter?
Greater amounts of context + bigger chunk size = higher latency. There’s debate on whether bigger chunk sizes always lead to better results (GPT-4 empirically is better at handling more extended amounts of context than GPT-3). Still, in general, there’s a positive correlation here. Another tradeoff is that any “advanced” LLM system, e.g., involving agents, requires chained LLM calls. Chained LLM calls inherently take longer to execute.
Q: I understand that we are using an external model to execute the queries. How secure is the private data that is transmitted?
It depends on the API service. For example, OpenAI doesn’t use API data to train/improve its models, but there will still be enterprise concerns about sending sensitive data to a 3rd party. We’ve recently added some PII modules to help alleviate this. Another alternative is to use local models.
Q: What are the pros and cons of the two approaches: (a) leveraging a vector database like Milvus for advanced similarity search and graph optimizations BEFORE loading onto and indexing on LlamaIndex and interfacing with an LLM; (b) using LlamaIndex native integrations to vector stores?
You can do either. We plan to consolidate these two a bit more, so stay tuned. At a very high level, using Milvus as a data loader first allows you to use existing data with LlamaIndex. In contrast, if you use our vector index backed by Milvus, we will define additional structures on top of this data. The pro of the former is you can use existing data, and the pro of the latter is we have more control in defining metadata.
Q: I need to analyze roughly 6,000 pdfs and PowerPoints locally. What would you recommend for me to have the best results without using OpenAI, LlamaIndex, with llama65b?
You can try using Llama if you’re okay with the license. Take a look at the open-source models on GitHub.
Watch the complete webinar recording!
Watch the webinar recording for more information about LlamaIndex and discussions between Jerry Liu and Frank Liu.

Keep Reading

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.