




Yet another cache, but for ChatGPT
ChatGPT is an impressive technology that enables developers to create game-changing applications. However, the performance and cost of language model models (LLMs) are significant issues that hinder their widespread application in various fields. For example, as we developed a chatbot https://osschat.io/ for the open-source community, ChatGPT was a major bottleneck preventing our application from responding as quickly as expected. The cost is also another obstacle preventing us from serving more open-source communities.
At a team lunch, an idea came to mind: Why not add another cache layer for the LLM-generated responses? This caching layer would be similar to how Redis and Memcache were built in the past to accelerate and reduce the cost of accessing databases. With this cache, we can decrease expenses for generating content and provide faster real-time responses. Additionally, the cache can be used to mock responses, which helps us verify our application's features without incurring extra expenses on our tests.
Traditional caches only retrieve data when the key is identical. This limitation presents a significant issue for AIGC applications that often work with natural language and need more specific syntax restrictions or additional data cleansing mechanisms. To address this issue, we created Yet Another Cache for AIGC-native applications, which we named GPTCache (https://github.com/zilliztech/GPTCache) since it is built natively to accelerate ChatGPT and optimized for semantic search.
With GPTCache, you can cache your LLM responses with just a few lines of code changes, boosting your LLM applications 100 times faster. In this blog post, we will describe how we built the semantic cache and some of the design choices we made.
Why would a cache help on our use cases?
Our chatbot allows users to ask general questions about open-source projects on GitHub and detailed questions about specific GitHub repositories and their associated documentation pages. As our service gains popularity, the expenses associated with calling OpenAI APIs increase. We have observed that certain types of content, such as popular or trending topics and hot GitHub repositories, are accessed more frequently. "What is" questions are the most commonly accessed, along with the recommended question list on the service's front page.
Like traditional applications, user access for AIGC applications has temporal and spatial locality. We can take advantage of this by implementing a cache system that reduces the number of ChatGPT calls. Given the slow response time and high cost of OpenAI APIs, this cache system is essential, which typically charges several dollars per 1M tokens and takes a few seconds to respond. By performing a vector search among millions of cached vectors and retrieving the cached result from a database, we can significantly reduce our service's average end-to-end response time and lower the OpenAI service cost.
Why won't Redis work in AIGC scenarios?
I'm a big fan of Redis because of its flexibility and performance, making it suitable for various use cases. However, it is not my first choice for building a cache for ChatGPT. Redis uses a key-value data model and cannot query approximate keys.
For example, suppose a user asks questions like "What are the advantages and disadvantages of all deep learning frameworks?" or "Tell me about PyTorch vs. TensorFlow vs. JAX?". In that case, they are asking the same thing. However, Redis fails to hit the query, whether you cache the entire question or only cache the keywords generated from a tokenizer. This failure is because different words can have the same meaning in natural language, and deep learning models are better at revealing these semantics than rules. Therefore, we should incorporate vector similarity search as part of a semantic cache.
Another reason why Redis may not be a perfect fit for AIGC caching is its high cost. The keys and values are large due to the long context, so storing everything in Redis can quickly become expensive. Caching with a disk-based database may be a better alternative because chatGPT responses are slow, so it doesn't matter if the cache can respond in sub-milliseconds or tens of milliseconds.
Build GPTCache from Scratch
We are excited about this idea and discussed it overnight. As a result, we came up with a useful architecture diagram shown below:
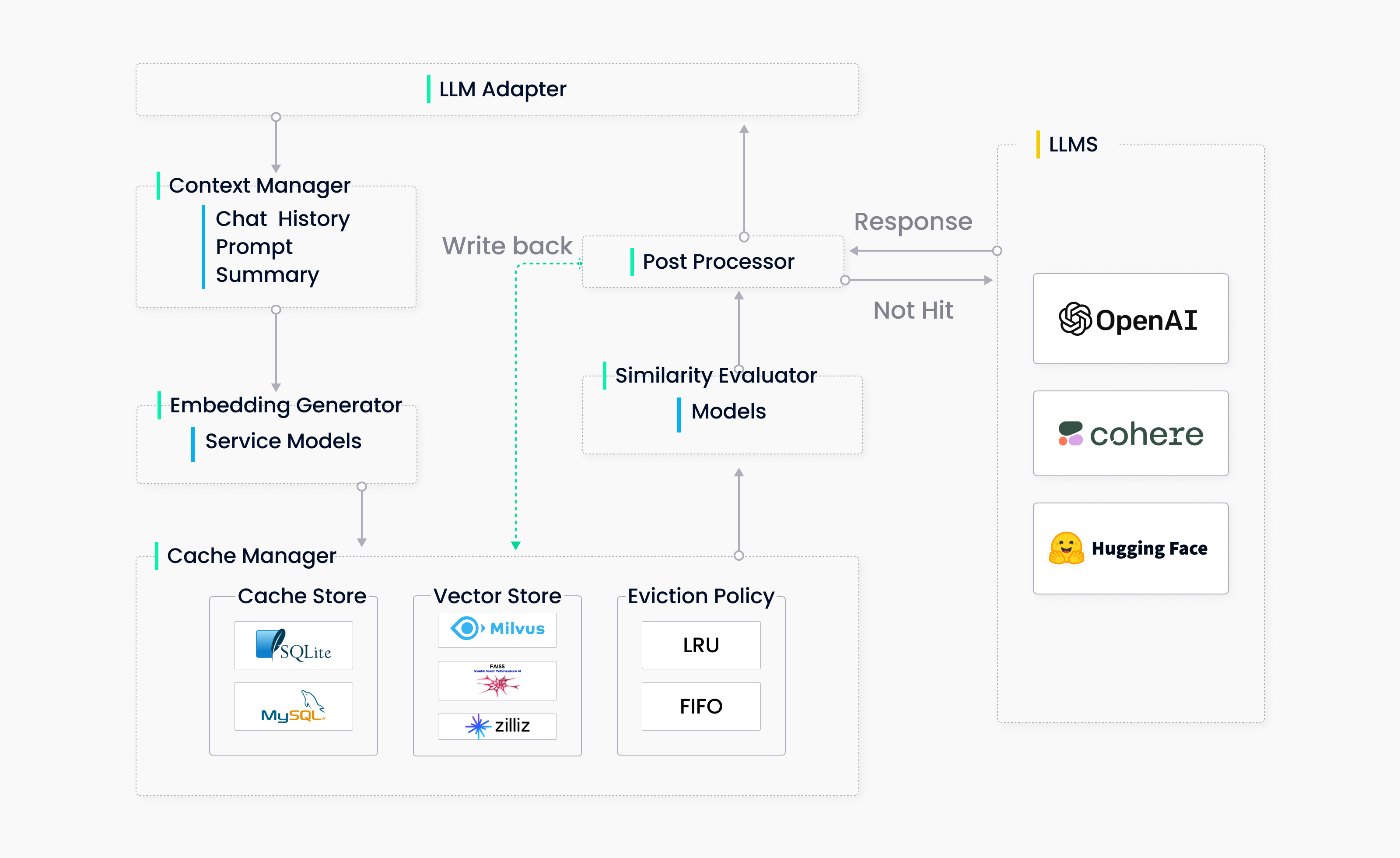 GPTCache High Level Architecture | Zilliz
GPTCache High Level Architecture | Zilliz
Later, we decided to simplify the implementation by skipping the context manager. Despite these changes, the system still consists of five major components. We listed the significant functionalities for each of the components below:
- LLM Adapter: Adapters convert LLM requests into cache protocol and the cached results into LLM responses. We aim to make this cache transparent, requiring no extra effort to integrate it into our system or any other system that depends on ChatGPT. The adapter should facilitate easy integration of all LLMs and be extendable for future multimodal models. Initially, we implemented OpenAI and langchain adapters because our system heavily depends on them. Multiple implementations also ensured that our interface made sense for all LLM APIs so that we could extend the adapter further.
- Embedding Generator: The embedding generator encodes queries into embeddings, enabling similarity searches. To cater to the needs of different users, we support two ways of generating embeddings. The first is through cloud services like OpenAI, Hugging Face, and Cohere. The second is through a local model serving on ONNX. In addition, we plan to support PyTorch embedding generators and encode images, audio files, and other types of unstructured data.
- Cache Manager: The cache manager is the core component of GPTCache, serving three functions: cache storage, which stores user requests and their LLM responses; vector storage, which stores vector embeddings and searches for similar results; and eviction management, which controls cache capacity and evicts expired data when the cache is full, using either the LRU or FIFO policy. The Cache Manager uses a pluggable design. Initially, we implemented it with SQLite and FAISS as the backend. Later, we expanded it to include other implementations such as MySQL, PostgreSQL, Milvus, and other vector databases, making it even more scalable. The Eviction Manager frees up memory by removing old, unused data from GPTCache. It removes entries from both the cache and vector storage when necessary. However, frequent deletions in most vector storage systems can cause a drop in performance. GPTCache triggers asynchronous operations such as index building or compaction once the delete threshold is reached to mitigate this issue.
- Similarity Evaluator: The GPTCache retrieves the top k similar answers from its cache and uses a similarity evaluation function to determine whether a cached answer matches the input query. GPTCache supports three evaluation functions: exact match evaluation, embedding distance evaluation, and ONNX model evaluation. The similarity evaluation module is crucial for the effectiveness of GPTCache. After investigation, we used a fine-tuned version of the ALBERT model. However, there is always room for improvement by using other fine-tuned language models or other LLMs such as LLaMa-7b. Any contributions or suggestions would be highly welcomed.
- Post Processors: Post Processor assists in preparing the final response to the user. It can return the most similar response or add randomness based on the request temperature. If no similar response can be found in the cache, the request will be delegated to LLMs to generate and cache a new response.
Evaluation
To illustrate our idea, we have discovered a dataset containing three sentence pairs: positive samples with identical semantics, negative samples with related but not identical semantics, and sentences between positive and negative samples with completely unrelated semantics. You can find the dataset in our repo.
Experiment 1
To establish a baseline, we first cache the keys of all 30,000 positive samples. Next, we randomly select 1,000 samples and use their peer values as queries. Here are the results we obtained:
| Cache Hit | Cache Miss | Positive | Negative | Hit Latency |
|---|---|---|---|---|
| 876 | 124 | 837 | 39 | 0.20s |
We have discovered that setting the similarity threshold of GPTCache to 0.7 achieves a good balance between the hit and positive ratios. Therefore, we will use this setting for all subsequent tests.
To determine if the cached result is positive or negative concerning the query, we use the similarity score generated by ChatGPT and set the positive threshold to 0.6. We generate this similarity score using the following prompt:
Please rate the similarity of the following two questions on a scale from 0 to 1, where 0 means not related and 1 means exactly the same meaning.
The questions "What are some good tips for self-study?" and "What are the smart tips for self-studying?" are very similar, with a similarity score of 1.0.
The questions "What are some essential things for wilderness survival?" and "What are the things you need for survival?" are quite similar, with a similarity score of 0.8.
The questions "What advice would you give to 16-year-old you?" and "Where should I promote my business online?" are completely different, so the similarity score is 0.
So, questions "Which app lets you watch live football for free?" and "How can I watch a football live match on my phone?" The similarity score is
Experiment 2
We issued queries consisting of 50% positive samples and 50% negative samples (unrelated queries). As a result, after running 1160 requests, we obtained the following results:
| Cache Hit | Cache Miss | Positive | Negative | Hit Latency |
|---|---|---|---|---|
| 570 | 590 | 549 | 21 | 0.17s |
The hit ratio is almost 50%, and the negative ratio among the hit results is similar to that of experiment 1, meaning GPTCache did an awesome job of distinguishing related and unrelated queries.
Experiment 3
We conducted another experiment, inserting all negative samples into the cache and using their peer values as queries. Although some negative sample pairs had a high similarity score (larger than 0.9, according to ChatGPT), to our surprise, none of the negative examples hit the cache. This is likely because the model used in the similarity evaluator is fine-tuned on this dataset, and almost all of the similarity scores for negative samples have been undervalued.
Future evaluation
We have integrated GPTCache into our OSSChat website and are now working on collecting production statistics. So stay tuned for the release of our next benchmark, which will include real-world use cases.
It’s the end of the blog, but just the start for GPTCache
We are pleased with how quickly we were able to implement and open-source such an amazing piece of work in less than two weeks. Bravo! Hopefully, you now fully understand the idea of GPTCache, how it was implemented, and have a plethora of ideas on how it can be integrated into your system.
Let's quickly recap some of the keynotes about GPTCache:
- ChatGPT is impressive, but it can be expensive and slow at times.
- Like other applications, we can see locality in AIGC use cases.
- To fully utilize this locality, all you need is a semantic cache.
- To build a semantic cache, embed your query context and store it in a vector database. Then, search for similar queries in the cache before sending the request to LLMs.
- Remember to manage the capacity of the cache!
We are currently working on integrating GPTCache with more LLMs and vector databases. Soon, we will release the GPTCache Bootcamp, which will explain how to use GPTCache together with LangChain and Hugging Face, as well as other ideas for making GPTCache multi-modal. We welcome any contributions or suggestions and encourage you to show us how GPTCache helps you in your application!
Learn More about GPTCache

Keep Reading

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.