




Creating Collections in Zilliz Cloud Just Got Way Easier
Building the proper data schema is critical for any database application, and as your projects grow in complexity, you need more powerful configuration options. While Zilliz Cloud has always offered advanced capabilities through our SDK, we heard your feedback about wanting these features available directly in the UI.
Today, we're delivering exactly that. We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.
Full-Text Search and Keyword Matching Now Available in the UI
Full-text search ranks documents by term relevance, essential for RAG (Retrieval-Augmented Generation) and keyword-intensive applications. It works directly on raw text and automatically generates sparse vectors—no manual embedding required. Keyword matching, meanwhile, is perfect for exact phrase filtering and precise lookups.
Previously, both features were only available via the SDK. Configuring them required an understanding of how input text field, function, and output sparse field work together—easy to misconfigure, hard to debug.
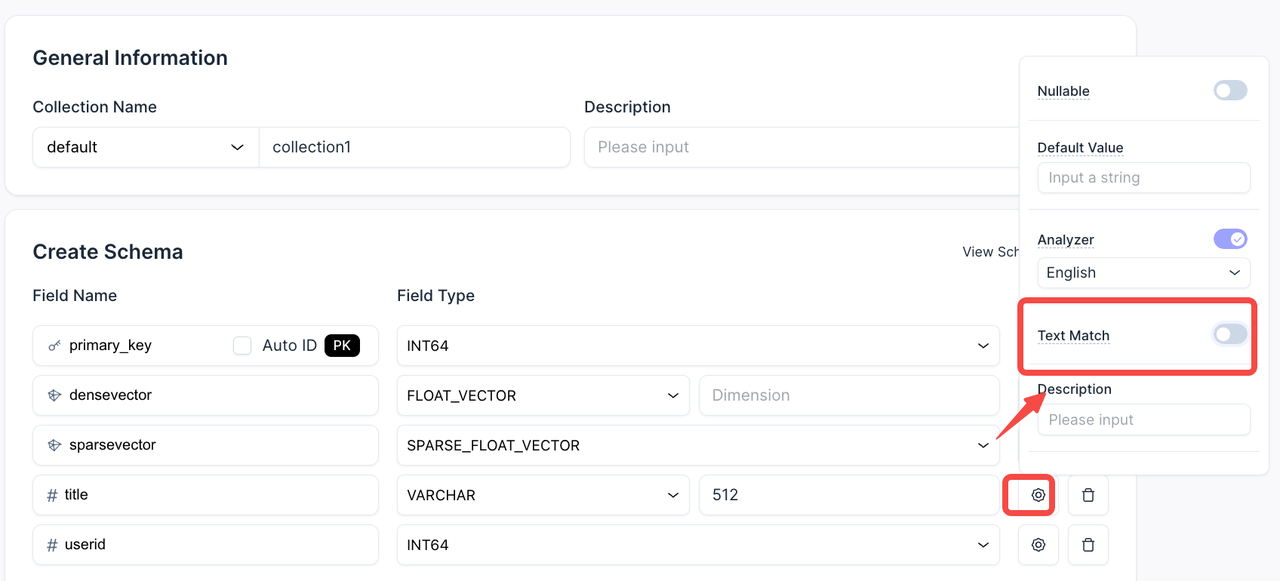
With this update, full-text search is now fully UI-driven. Select a VARCHAR column, choose a function (Standard or Custom Analyzer), and assign a sparse field. We also display SDK code samples inline to help you transition smoothly to code workflows if needed.
Keyword matching is now a one-click toggle. You can directly enable it for specific fields, making the configuration faster and more intuitive.
 Full-Text Search and Keyword Matching Now Available in the UI.png
Full-Text Search and Keyword Matching Now Available in the UI.png
Partitioning Made Simple: Clear Guidance for the Right Choice
Partitioning is essential for performance tuning, especially in multi-tenant or large-scale environments. But the distinction between Partition and Partition Key hasn't always been obvious—and it matters.
In Zilliz Cloud:
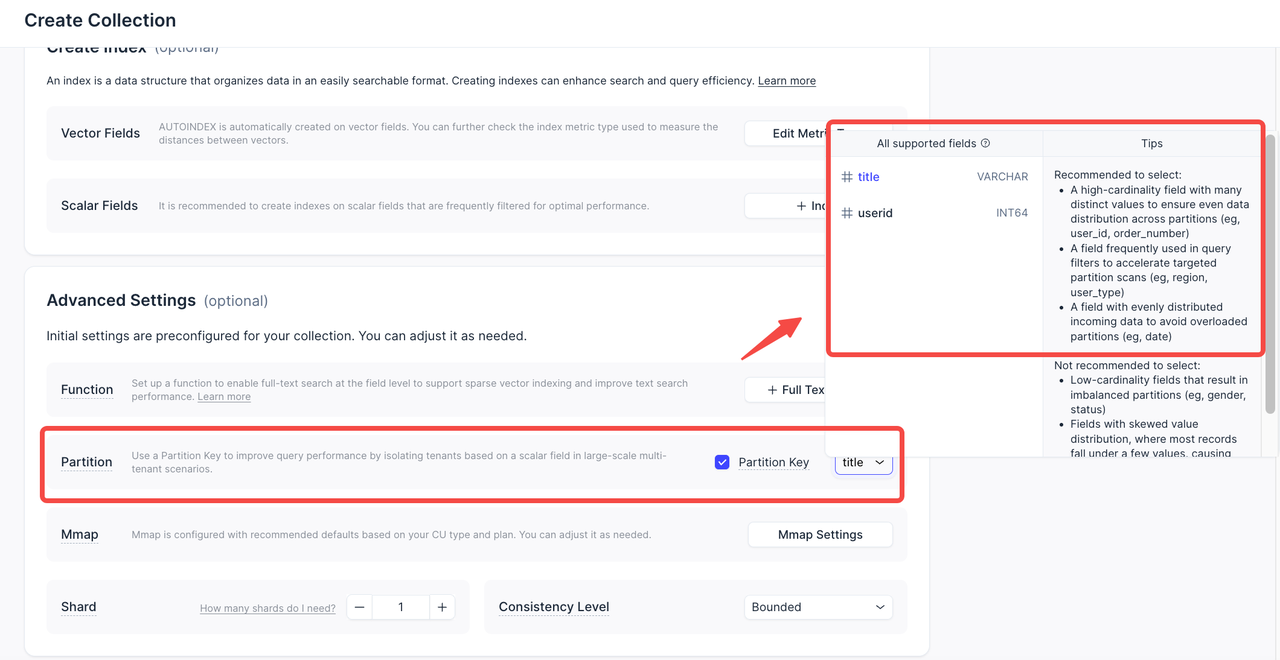
A Partition is a physical subset of a Collection. It shares the same schema but contains only part of the data—ideal for isolating workloads or improving query performance.
A Partition Key lets you split data across tenants using a scalar field, enabling logical isolation at scale.
Previously, partitions had to be created, defined, and managed via the SDK. The similar names and mutually exclusive behaviors often led to confusion, and configuration mistakes could be costly, sometimes requiring a complete data reload.
Now, we've made this simpler and safer. The UI now clearly explains the difference between Partition and Partition Key during collection creation, helping you choose the right setup for your needs. A new partition management page lets you create and preview partition, and import data directly into them.
When Partition Key is enabled, partitions are managed automatically—the UI disables manual partitioning to prevent conflicts.
 Partitioning Made Simple- Clear Guidance for the Right Choice
Partitioning Made Simple- Clear Guidance for the Right Choice
Memory Mapping Controls: Configure Anytime, Not Just at Creation
Mmap (memory mapping) is a powerful feature that reduces memory footprint and improves throughput, especially for large or rarely accessed fields. But managing it used to be tricky.
Previously, Mmap had to be enabled during collection creation and could only be changed via SDK. The interface also didn't explain when you needed to release your collection to make changes, or help you understand the different ways Mmap could be applied to your data.
We've addressed all of that.
Mmap settings are now more granular and explicit. Field-level, collection-level, and cluster-level priorities are clearly defined.
You can now configure Mmap on demand at the collection or column level—and separately for raw data and index data.
Mmap status is visible and editable directly in the schema view. Just release the collection, and you can update settings from the UI.
Nullable and Default Value Support: More Resilient Writes, Cleaner UI
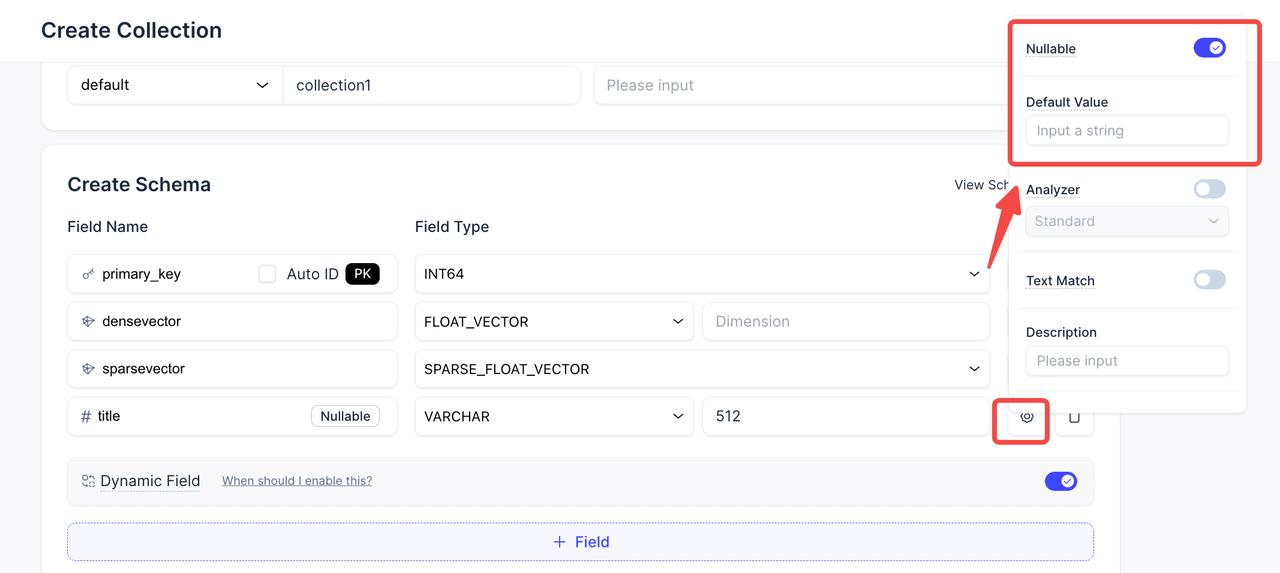
We know not every field needs a default value or nullability setting. But when you do need them—especially for incomplete data or flexible schemas—they're essential.
Previously, these options cluttered the collection creation interface, even when unused. Now, we've streamlined the experience. Nullable and default value settings are tucked away by default. They're still available when needed, but no longer get in the way of frequent operations.
This gives you a cleaner interface while retaining full fault-tolerance controls when you need them.
 Nullable and Default Value Support- More Resilient Writes, Cleaner UI
Nullable and Default Value Support- More Resilient Writes, Cleaner UI
Complete Index Management: Scalar and Vector Indexes in One Place
Indexes are critical for fast search and filtering. Previously, creating a collection would automatically set up vector indexes; but if you wanted to create scalar indexes, you had to configure them separately using the SDK. The UI didn't explain why scalar indexes are important either, so most users simply skipped this step. This became a performance bottleneck—when users filtered their data using scalar fields without proper indexing, queries ran much slower than they should.
We’ve addressed all these issues with this update.
The collection creation flow now includes a complete indexing module, explaining why indexes matter and guiding you to configure the right ones.
A dedicated index management page has been added to support creating, deleting, and previewing all index types, bringing full lifecycle management into the UI.
JSON Path index support is now available, giving you a huge boost in query performance for JSON and dynamic fields.
Shard and Consistency Level Now Visible in the UI
Two of the most powerful Collection-level settings—Shard and Consistency Level—were previously hidden in the UI. That made it hard to validate whether the defaults suited your workload.
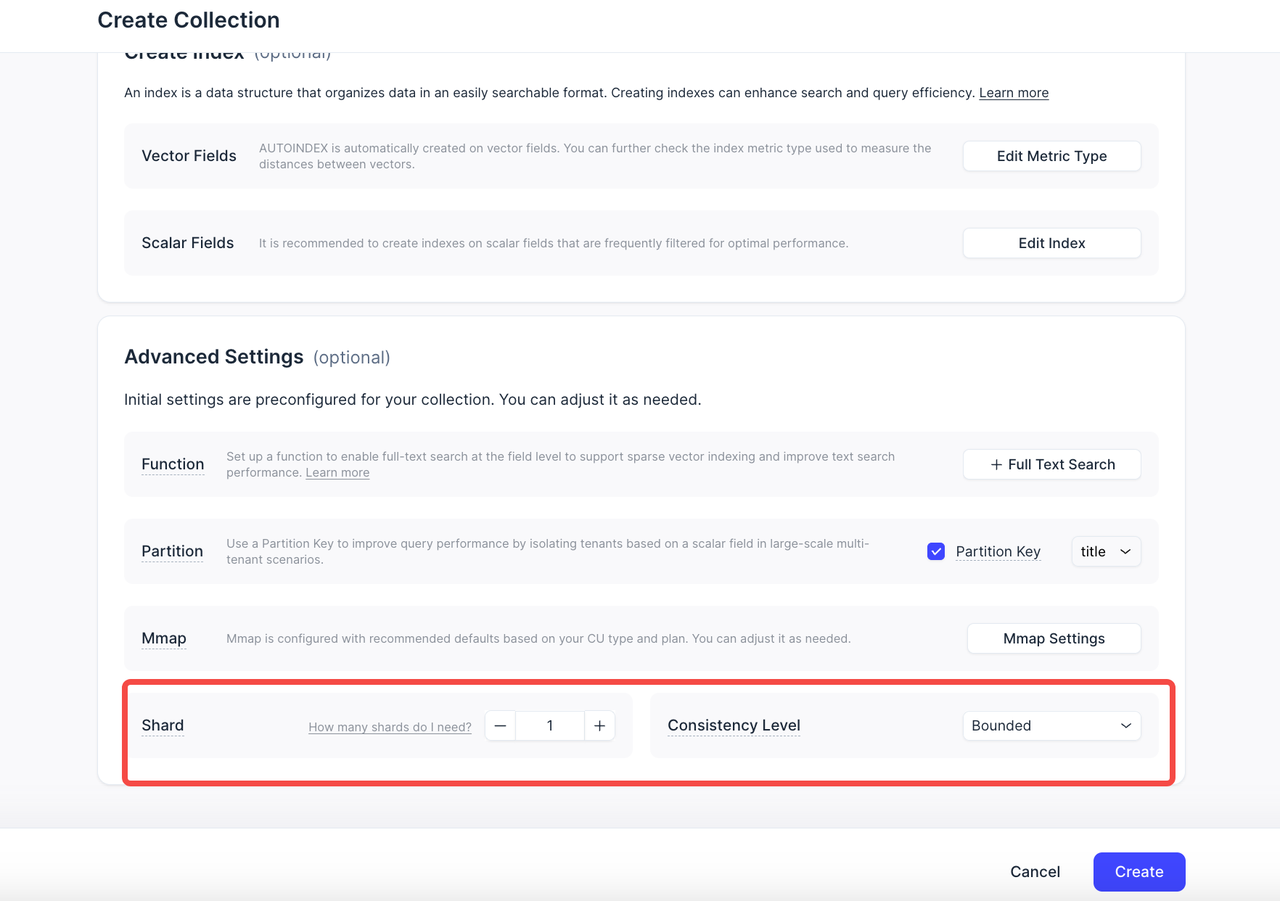
Shards split your Collection horizontally and enable concurrent write channels—greatly improving write throughput.
Consistency Level controls how fresh the data needs to be during search and query operations. By default, we use
Bounded, which balances freshness and performance.
In this update, we show both settings upfront in the collection creation flow. You can customize them immediately based on your application needs—with built-in explanations and usage guidance to support your decisions.
 Shard and Consistency Level Now Visible in the UI
Shard and Consistency Level Now Visible in the UI
Enhanced Schema Design: Better Dynamic Field Integration
Dynamic fields let you insert new fields without modifying the schema—ideal for applications with flexible data structures. However, the Zilliz Cloud UI presented this as just a toggle, making it unclear how dynamic fields related to scalar or vector columns.
Now, dynamic fields are shown alongside scalar and vector fields in schema design. We've added description labels to help you understand how this powerful feature fits into your schema.
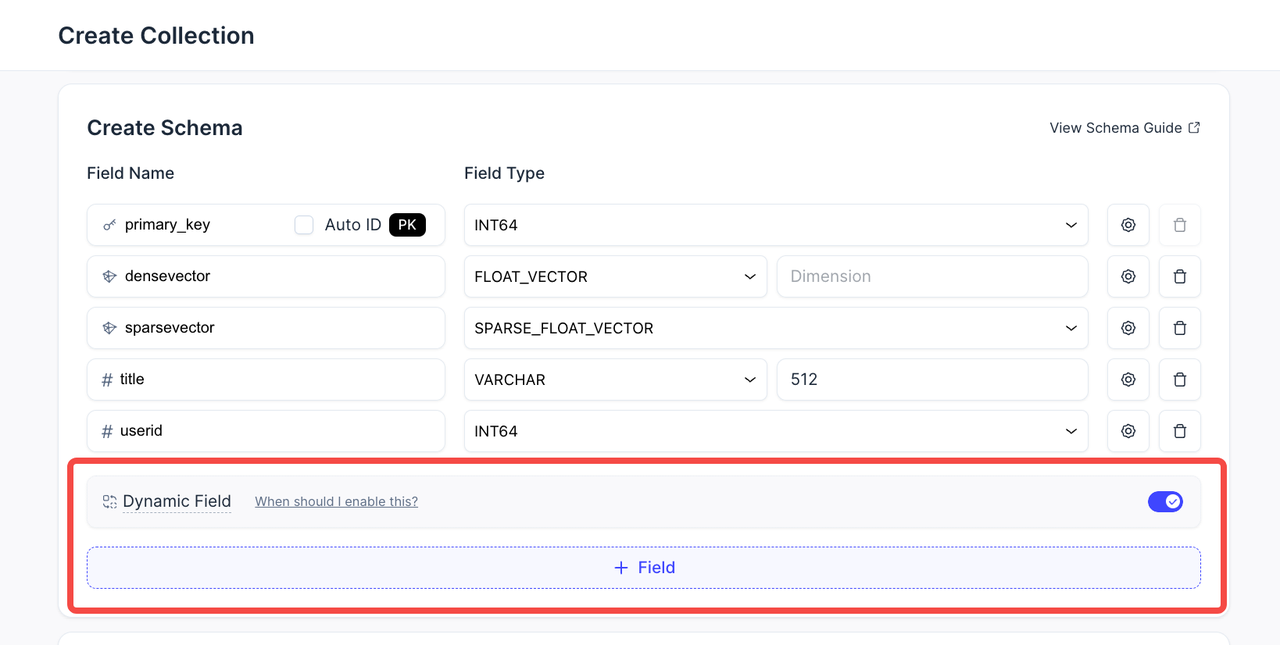 Enhanced Schema Design- Better Dynamic Field Integration
Enhanced Schema Design- Better Dynamic Field Integration
We’ve also merged Data Import into Data Preview, simplifying the workflow and reducing tab-switching.
Conclusion: Build It Right, From the Start
At Zilliz, we believe collection creation shouldn’t be a guessing game. The correct schema is the foundation of everything, from query performance to cost efficiency to how quickly your AI applications can scale.
This upgrade isn’t just about adding more settings. It’s about giving you the clarity and control to design your data model confidently the first time around. Whether configuring partitions, toggling Mmap, defining indexes, or fine-tuning consistency settings, everything is now easier to see, understand, and manage directly in the UI.
With these improvements, you can stop worrying about infrastructure complexity and focus on building faster, smarter, more intelligent applications powered by vector search.
Getting Started with Zilliz Cloud
Ready to experience the enhanced workflow? The new interface is available now to all Zilliz Cloud users.
Existing users: Log into your Zilliz Cloud console and create a new collection to explore the updated features. Your existing collections will continue working unchanged.
New to Zilliz Cloud? Sign up for free and get started with up to $200 in credits. Experience the power of managed vector databases with our simplified schema design tools.
Need help? Check out our documentation or contact our support team for guidance on optimizing your vector database setup.
As always, we'd love your feedback to help us keep making Zilliz Cloud better.

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.