Build RAG Chatbot with Llamaindex, HNSWlib, Cohere Command R+, and voyage-3-lite
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a game-changer for GenAI applications, especially in conversational AI. It combines the power of pre-trained large language models (LLMs) like OpenAI’s GPT with external knowledge sources stored in vector databases such as Milvus and Zilliz Cloud, allowing for more accurate, contextually relevant, and up-to-date response generation. A RAG pipeline usually consists of four basic components: a vector database, an embedding model, an LLM, and a framework.
Key Components We'll Use for This RAG Chatbot
This tutorial shows you how to build a simple RAG chatbot in Python using the following components:
- Llamaindex: a data framework that connects large language models (LLMs) with various data sources, enabling efficient retrieval-augmented generation (RAG). It helps structure, index, and query private or external data, optimizing LLM applications for search, chatbots, and analytics.
- HNSWlib: a high-performance C++ and Python library for approximate nearest neighbor (ANN) search using the Hierarchical Navigable Small World (HNSW) algorithm. It provides fast, scalable, and efficient similarity search in high-dimensional spaces, making it ideal for vector databases and AI applications.
- Cohere Command R+: A state-of-the-art enterprise-focused LLM optimized for high-efficiency Retrieval-Augmented Generation (RAG) and tool use, designed to automate complex workflows. Strengths include multilingual support, scalability, and robust accuracy for enterprise-grade applications. Ideal for automating customer support, data analysis, and knowledge-intensive tasks while ensuring secure, reliable collaboration between AI and human teams.
- Voyage-3-Lite: This model is designed for resource-constrained environments, offering a lightweight and efficient solution for various NLP tasks. It excels in applications such as chatbots, content generation, and real-time text analysis, providing quick responses while maintaining a balance between performance and computational efficiency. Ideal for developers needing high throughput with limited resources.
By the end of this tutorial, you’ll have a functional chatbot capable of answering questions based on a custom knowledge base.
Note: Since we may use proprietary models in our tutorials, make sure you have the required API key beforehand.
Step 1: Install and Set Up Llamaindex
pip install llama-index
Step 2: Install and Set Up Cohere Command R+
%pip install llama-index-llms-cohere
from llama_index.llms.cohere import Cohere
llm = Cohere(model="command-r-plus", api_key=api_key)
Step 3: Install and Set Up voyage-3-lite
%pip install llama-index-embeddings-voyageai
from llama_index.embeddings.voyageai import VoyageEmbedding
embed_model = VoyageEmbedding(
voyage_api_key="",
model_name="voyage-3-lite",
)
Step 4: Install and Set Up HNSWlib
%pip install llama-index-vector-stores-hnswlib
from llama_index.vector_stores.hnswlib import HnswlibVectorStore
from llama_index.core import (
VectorStoreIndex,
StorageContext,
SimpleDirectoryReader,
)
vector_store = HnswlibVectorStore.from_params(
space="ip",
dimension=embed_model._model.get_sentence_embedding_dimension(),
max_elements=1000,
)
Step 5: Build a RAG Chatbot
Now that you’ve set up all components, let’s start to build a simple chatbot. We’ll use the Milvus introduction doc as a private knowledge base. You can replace it with your own dataset to customize your RAG chatbot.
import requests
from llama_index.core import SimpleDirectoryReader
# load documents
url = 'https://raw.githubusercontent.com/milvus-io/milvus-docs/refs/heads/v2.5.x/site/en/about/overview.md'
example_file = 'example_file.md' # You can replace it with your own file paths.
response = requests.get(url)
with open(example_file, 'wb') as f:
f.write(response.content)
documents = SimpleDirectoryReader(
input_files=[example_file]
).load_data()
print("Document ID:", documents[0].doc_id)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, embed_model=embed_model
)
query_engine = index.as_query_engine(llm=llm)
res = query_engine.query("What is Milvus?") # You can replace it with your own question.
print(res)
Example output
Milvus is a high-performance, highly scalable vector database designed to operate efficiently across various environments, from personal laptops to large-scale distributed systems. It is available as both open-source software and a cloud service. Milvus excels in managing unstructured data by converting it into numerical vectors through embeddings, which facilitates fast and scalable searches and analytics. The database supports a wide range of data types and offers robust data modeling capabilities, allowing users to organize their data effectively. Additionally, Milvus provides multiple deployment options, including a lightweight version for quick prototyping and a distributed version for handling massive data scales.
Optimization Tips
As you build your RAG system, optimization is key to ensuring peak performance and efficiency. While setting up the components is an essential first step, fine-tuning each one will help you create a solution that works even better and scales seamlessly. In this section, we’ll share some practical tips for optimizing all these components, giving you the edge to build smarter, faster, and more responsive RAG applications.
LlamaIndex optimization tips
To optimize LlamaIndex for a Retrieval-Augmented Generation (RAG) setup, structure your data efficiently using hierarchical indices like tree-based or keyword-table indices for faster retrieval. Use embeddings that align with your use case to improve search relevance. Fine-tune chunk sizes to balance context length and retrieval precision. Enable caching for frequently accessed queries to enhance performance. Optimize metadata filtering to reduce unnecessary search space and improve speed. If using vector databases, ensure indexing strategies align with your query patterns. Implement async processing to handle large-scale document ingestion efficiently. Regularly monitor query performance and adjust indexing parameters as needed for optimal results.
HNSWlib optimization tips
To optimize HNSWlib for a Retrieval-Augmented Generation (RAG) setup, fine-tune the M parameter (number of connections per node) to balance accuracy and memory usage—higher values improve recall but increase indexing time. Adjust ef_construction (search depth during indexing) to enhance retrieval quality. During queries, set ef_search dynamically based on latency vs. accuracy trade-offs. Use multi-threading for faster indexing and querying. Ensure vectors are properly normalized for consistent similarity comparisons. If working with large datasets, periodically rebuild the index to maintain efficiency. Store the index on disk and load it efficiently for persistence in production environments. Monitor query performance and tweak parameters to achieve optimal speed-recall balance.
Cohere Command R+ optimization tips
To optimize Cohere Command R+ in a RAG setup, preprocess input queries by chunking large texts and filtering irrelevant context to reduce noise. Use retrieval-friendly parameters like temperature=0.3 for focused responses and max_tokens=512 to balance detail and conciseness. Fine-tune document retrieval with semantic reranking and metadata filtering to prioritize high-relevance sources. Enable confidence_score to validate output reliability, and cache frequent queries to reduce latency. Monitor token usage and response quality to iteratively adjust retrieval thresholds and generation settings for cost-performance balance.
voyage-3-lite optimization tips
voyage-3-lite is optimized for speed and efficiency, making it a strong choice for low-latency RAG applications. Improve retrieval by minimizing the number of retrieved documents while maintaining relevance using adaptive filtering techniques. Keep prompts concise and to the point, avoiding redundant context to reduce processing overhead. Set temperature between 0.1 and 0.2 to prioritize factual accuracy and prevent unnecessary response variation. Use caching to reduce repeated API calls for common queries. Implement response streaming to improve user experience in real-time applications. Optimize resource usage by running voyage-3-lite in high-throughput scenarios where speed is prioritized over deep reasoning, reserving larger models for more complex analysis.
By implementing these tips across your components, you'll be able to enhance the performance and functionality of your RAG system, ensuring it’s optimized for both speed and accuracy. Keep testing, iterating, and refining your setup to stay ahead in the ever-evolving world of AI development.
RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
Estimating the cost of a Retrieval-Augmented Generation (RAG) pipeline involves analyzing expenses across vector storage, compute resources, and API usage. Key cost drivers include vector database queries, embedding generation, and LLM inference.
RAG Cost Calculator is a free tool that quickly estimates the cost of building a RAG pipeline, including chunking, embedding, vector storage/search, and LLM generation. It also helps you identify cost-saving opportunities and achieve up to 10x cost reduction on vector databases with the serverless option.
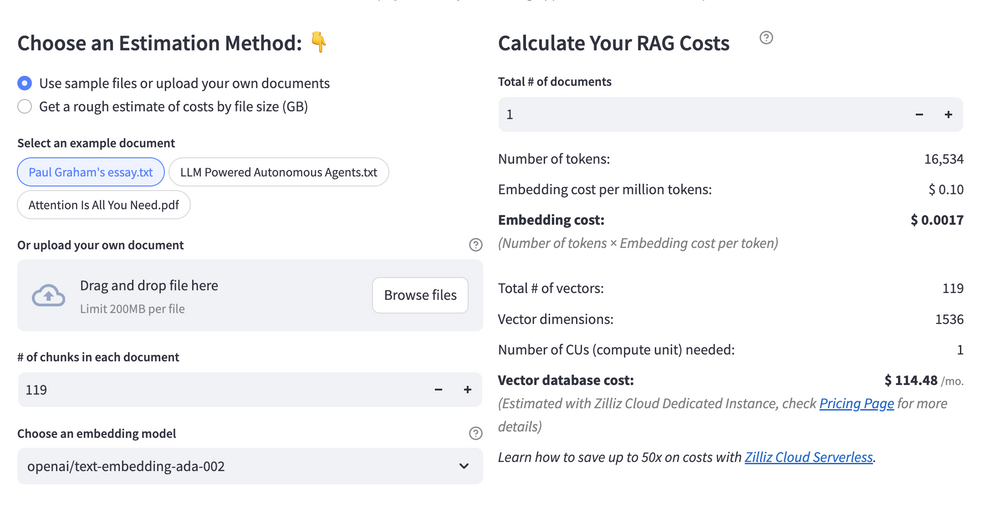 Calculate your RAG cost
Calculate your RAG cost
What Have You Learned?
Wow, what a journey we've taken together in building an efficient RAG (Retrieval-Augmented Generation) system! Through this tutorial, you’ve learned how to seamlessly integrate a variety of powerful components, namely LlamaIndex as your framework, HNSWlib as a high-performance vector database, the Cohere Command R+ for generating human-like responses, and the voyage-3-lite embedding model for excellent semantic understanding. Each piece plays a vital role: LlamaIndex orchestrates the workflow, HNSWlib ensures lightning-fast retrieval of relevant information, while the embedding model and LLM (Language Model) work in perfect harmony to process and generate contextually rich responses. That's a recipe for success you should be proud of!
But we didn’t stop there! I hope you found the optimization tips particularly helpful, as they can make a significant difference in your RAG application’s performance. Oh, and don't forget about the free RAG cost calculator shared in the tutorial—what an amazing resource to help you manage expenses while pushing the boundaries of your projects! So, now it's time to roll up your sleeves and dive into your own RAG innovations. The possibilities are endless, and with your newfound skills, you have the tools to create something truly spectacular. Embrace the challenge, keep experimenting, and who knows—you might be the one to change the game in RAG applications!
Further Resources
🌟 In addition to this RAG tutorial, unleash your full potential with these incredible resources to level up your RAG skills.
- How to Build a Multimodal RAG | Documentation
- How to Enhance the Performance of Your RAG Pipeline
- Graph RAG with Milvus | Documentation
- How to Evaluate RAG Applications - Zilliz Learn
- Generative AI Resource Hub | Zilliz
We'd Love to Hear What You Think!
We’d love to hear your thoughts! 🌟 Leave your questions or comments below or join our vibrant Milvus Discord community to share your experiences, ask questions, or connect with thousands of AI enthusiasts. Your journey matters to us!
If you like this tutorial, show your support by giving our Milvus GitHub repo a star ⭐—it means the world to us and inspires us to keep creating! 💖
- Introduction to RAG
- Key Components We'll Use for This RAG Chatbot
- Step 1: Install and Set Up Llamaindex
- Step 2: Install and Set Up Cohere Command R+
- Step 3: Install and Set Up voyage-3-lite
- Step 4: Install and Set Up HNSWlib
- Step 5: Build a RAG Chatbot
- Optimization Tips
- RAG Cost Calculator: A Free Tool to Calculate Your Cost in Seconds
- What Have You Learned?
- Further Resources
- We'd Love to Hear What You Think!
anchor.title
Vector Database at Scale
Zilliz Cloud is a fully-managed vector database built for scale, perfect for your RAG apps.
Try Zilliz Cloud for Free