




Что такое Vector Lakebase?
TL;DR
- Vector Lakebase — это унифицированная, lake-native архитектура данных для ИИ, которая сочетает обслуживание уровня векторной базы данных с открытым lake-хранилищем, переиспользуемыми индексами уровня lake и общим семантическим слоем.
- Она позволяет одним и тем же неструктурированным данным обеспечивать онлайн-обслуживание (RAG, агенты, семантический поиск) и офлайн-обнаружение (кластеризация, дедупликация, повторное создание эмбеддингов, управление данными) — без копирования данных между системами.
- Zilliz Vector Lakebase — это реализация этой архитектуры: эволюция Zilliz Cloud от управляемой векторной базы данных к унифицированной платформе данных для ИИ.
Что такое Vector Lakebase?
Vector Lakebase — это унифицированная, lake-native архитектура данных для ИИ. Она сочетает обслуживание уровня векторной базы данных, открытое lake-хранилище, переиспользуемые индексы уровня lake и общий семантический слой, чтобы одни и те же неструктурированные данные могли поддерживать онлайн-приложения ИИ, интерактивное обнаружение и офлайн-аналитику — без копирования между системами. Она отвечает на иной вопрос, чем одно лишь извлечение: что происходит, когда производственным командам ИИ нужны одни и те же данные для извлечения, обнаружения, аналитики, управления, обратной связи и непрерывного улучшения?
Лучше всего понимать ее как расширение векторной базы данных, а не как ее замену. Векторный поиск остается низколатентным путем обслуживания; Vector Lakebase помещает этот путь внутрь более широкой основы, которая также может хранить, индексировать, управлять и непрерывно улучшать окружающие его данные.
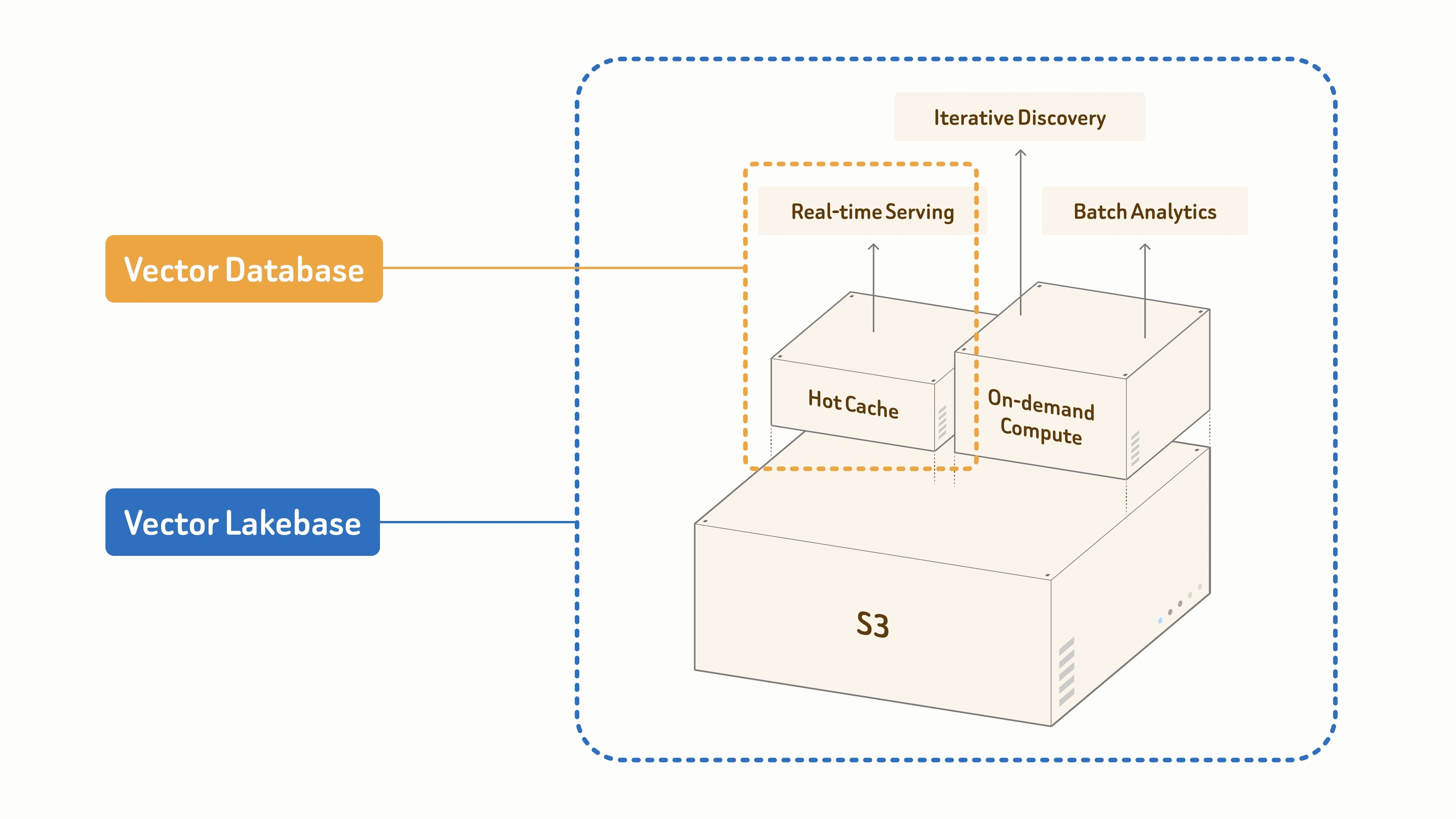
Почему современным AI-нагрузкам нужен Vector Lakebase
Векторные базы данных решили первую проблему данных современного ИИ: быстрый семантический поиск в масштабе, обеспечивающий RAG, агентов и семантический поиск. Эта проблема по-прежнему важна — как никогда, по мере распространения AI-систем.
Но производственным командам ИИ все чаще нужно больше, чем извлечение из тех же данных, — дедупликация и кластеризация для обучающих наборов, обнаружение аномалий и дрейфа, повторное создание эмбеддингов при изменении моделей, управление и происхождение данных, а также обратная связь из поведения в production.
Большинство стеков обрабатывают эти рабочие процессы как отдельные системы: data lake для сырых файлов, векторная база данных для онлайн-извлечения, пакетные конвейеры для предварительной обработки и отдельные задания для эмбеддингов и индексов. Данные копируются между ними, индексы перестраиваются, а онлайн-обслуживание и офлайн-обнаружение расходятся.
Vector Lakebase устраняет эту фрагментацию, предоставляя единую логическую основу данных для обслуживания и обнаружения. Она сохраняет низколатентный путь извлечения, для которого созданы векторные базы данных, но соединяет его с lake-native основой, где данные, векторы, индексы, метаданные и семантический контекст могут храниться, управляться, версионироваться, переиспользоваться и со временем улучшаться. Цель не в том, чтобы заменить векторную базу данных lake-хранилищем; цель — интегрировать векторный поиск, семантический контекст и обработку неструктурированных данных в единую архитектуру. (Контекст отрасли и инженерные аспекты этого сдвига см. в Why We Built Vector Lakebase.)
Ключевые принципы проектирования Vector Lakebase: One Data, One Index, One Semantic Layer
Архитектура Vector Lakebase основана на трех принципах: One Data, One Index и One Semantic Layer. Они описывают, где находится система записи, как управляются индексы и как организуется смысл.

One Data: lake как общая основа данных
One Data означает, что открытое lake-хранилище становится общей основой для неструктурированных AI-данных. Сырые файлы, очищенные данные, векторы, скалярные поля, метаданные, артефакты индексов, семантические метки, происхождение данных и результаты офлайн-обработки — все это находится в рамках единой логической основы данных.
В этой архитектуре векторная база данных не является новым изолированным хранилищем данных. Она становится частью пути обслуживания с низкой задержкой. Авторитетные данные остаются lake-native, тогда как онлайн-системы кэшируют горячие данные и индексы при необходимости. Это сокращает дублирование хранилищ, управление и межсистемную миграцию, а также позволяет одним и тем же данным поддерживать онлайн-приложения, офлайн-обработку, обучение моделей, оценку и управление.
Например, документ, используемый в системе RAG, также может быть частью офлайн-задачи кластеризации, рабочего процесса исследования обучающих данных, проверки соответствия требованиям и будущего процесса повторного создания эмбеддингов. Во фрагментированной архитектуре каждый рабочий процесс создает собственную копию или производное представление. В Vector Lakebase эти рабочие процессы работают на одной и той же логической основе данных.
One Index: индексы становятся активами уровня lake
One Index означает, что индексы не заблокированы внутри одного онлайн-движка обслуживания. Они становятся активами данных, которые можно строить, версионировать, повторно использовать и обслуживать в разных режимах вычислений. Это важно, потому что индексы дороги и операционно значимы — они кодируют то, как система извлекает и организует данные. Если каждому рабочему процессу приходится строить собственный индекс, команды впустую тратят вычислительные ресурсы, создают несогласованное поведение поиска и усложняют управление.
В Vector Lakebase логический индекс может отображаться в разные формы обслуживания в зависимости от шаблона доступа и стоимости. Горячие индексы поддерживают онлайн-поиск на уровне миллисекунд; теплые данные обслуживаются через кэш или многоуровневое хранилище; холодные данные остаются в lake для исследования, управления и офлайн-анализа. Одна и та же родословная индекса может поддерживать обслуживание RAG, семантический поиск, память агентов, исследование данных и пакетную обработку — позволяя командам выбирать подходящий профиль задержки и стоимости, не нарушая модель данных.
One Semantic Layer: смысл становится общим системным слоем
One Semantic Layer означает, что система управляет не только эмбеддингами. Эмбеддинг — это лишь одно представление базового актива. Полезной основе AI-данных также нужны сущности, метки, резюме, темы, фрагменты контекста, исходная информация, версии моделей, политики доступа, родословная и сигналы обратной связи. Этот семантический слой позволяет командам организовывать неструктурированные данные по смыслу, а не только по пути к файлу, таблице, bucket или коллекции.
Система RAG может извлекать доверенный контекст из семантического слоя. AI-агент может понимать предыдущие задачи, воспоминания и результаты вызовов инструментов. Рабочий процесс обучающих данных может обнаруживать пробелы в покрытии, дубликаты, выбросы и смещение. Система управления может проследить ответ, признак или образец обратно к исходным данным и версии модели, которые его произвели.
Семантический слой также является центром маховика данных: онлайн-приложения генерируют запросы, клики, цитирования, исправления и обратную связь; офлайн-обнаружение превращает эти сигналы в более качественные метаданные, более чистые наборы данных, улучшенные индексы и более сильный контекст; и эти улучшения возвращаются обратно в обслуживание. Именно в этом цикле Vector Lakebase становится чем-то большим, чем хранилище плюс поиск.
Как работает Vector Lakebase: маховик CS/CD в четыре этапа
Vector Lakebase работает как непрерывный цикл между обслуживанием и обнаружением — мы называем это CS/CD (Continuous Serving и Continuous Discovery). Обслуживание генерирует обратную связь и новые данные, обнаружение превращает их в более чистые данные и лучшие индексы, а эти улучшения возвращаются обратно в обслуживание.
Операционно тот же цикл проходит через четыре этапа: прием данных, векторизация и обогащение, обслуживание запросов и офлайн-обработка.
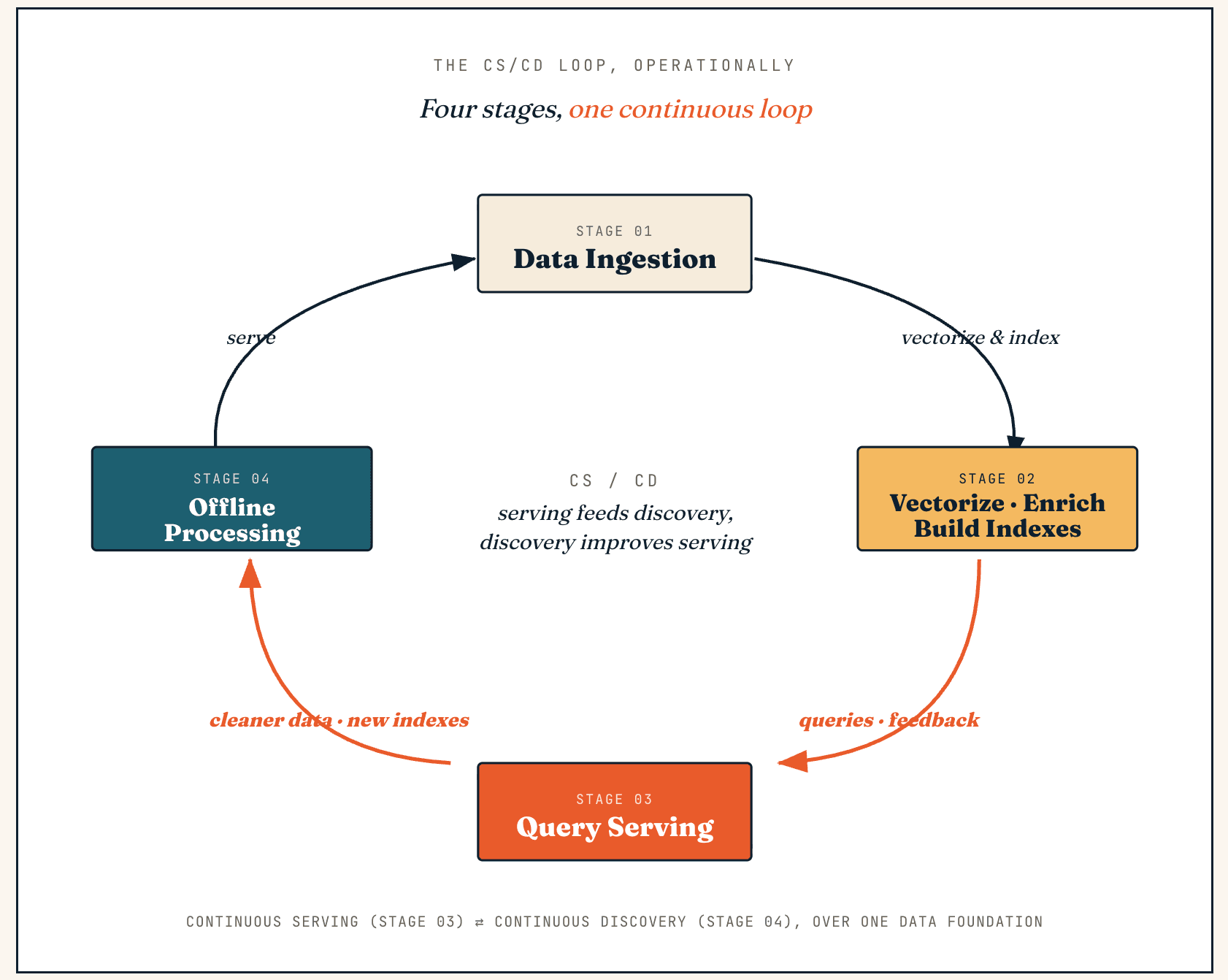
Прием данных
Данные могут поступать в систему через API векторной базы данных, конвейер документов, объектное хранилище или существующий открытый формат lake. Данные могут включать документы, векторы, скалярные поля, бизнес-метаданные, изображения, аудио, видео, код, логи, разговоры, обращения в поддержку или трассировки агентов.
По мере роста объема неструктурированных данных их ingestion также должен поддерживать очистку, нормализацию, контроль доступа, отслеживание источников и lineage. Системе нужно знать не только, что представляют собой данные, но и откуда они поступили, какая модель их обработала, кто может получить к ним доступ и как их можно использовать. Это особенно важно для enterprise AI. Система RAG или агент не может рассматривать каждый фрагмент полученных данных как одинаково надежный. Контекст должен учитывать источник, разрешения, актуальность, а иногда и бизнес-специфичные правила управления данными.
Векторизация, обогащение и построение индексов
После ingestion система генерирует векторные представления с использованием embedding-моделей и заданий обработки данных. Она также обогащает данные метаданными — сущностями, метками, резюме, темами, информацией об источнике, разрешениями, временными метками и версиями моделей. Затем она строит структуры запросов поверх данных lake: векторные индексы, keyword-индексы, full-text-индексы, JSON-индексы, scalar-индексы и другие структуры, необходимые для hybrid retrieval.
С архитектурной точки зрения ключевой момент заключается в следующем: индексы не привязаны к какому-либо одному serving-движку. Их можно версионировать, публиковать, повторно использовать и отслеживать обратно до snapshot данных, на основе которого они были построены, — что делает управление жизненным циклом индексов частью data foundation, а не деталью реализации, скрытой внутри одного приложения.
Обслуживание запросов
Vector Lakebase предоставляет пути retrieval для RAG, agentic search, semantic search, multimodal retrieval, AI memory, рекомендаций и других нагрузок AI-приложений. Путь запроса может использовать векторную базу данных или cache layer для hot data, которым нужна низкая задержка, и обращаться к lake-native данным и индексам для colder или менее частых нагрузок.
Запрос может сочетать vector search, keyword search, full-text search, фильтрацию по метаданным, scalar predicates, разрешения и hybrid ranking — потому что production AI retrieval редко основан только на векторном сходстве. Хороший результат часто зависит от семантической релевантности, актуальности, прав доступа, качества источника, бизнес-метаданных и намерения пользователя.
Офлайн-обработка
Офлайн-обработка включает кластеризацию, дедупликацию, обнаружение аномалий, анализ качества данных, исследование обучающих данных, эволюцию схемы, повторное embedding, оценку и перестроение индексов. Эти рабочие процессы выполняются на больших пакетах данных и не всегда требуют миллисекундной задержки, но им нужен доступ к тем же векторам, метаданным, индексам и семантическому контексту, которые используются online-приложениями.
Их результат записывается обратно в lake, index system и semantic layer — более чистые наборы данных, улучшенные метки, улучшенные фрагменты контекста, новые версии индексов или обновленные сигналы обратной связи — и публикуется как atomic snapshot, чтобы production никогда не читал наполовину построенные индексы. Это основной операционный цикл: serving генерирует обратную связь, discovery улучшает данные, а улучшенные данные возвращаются в serving.
Три формы нагрузок для Vector Lakebases
Нагрузки данных AI не имеют одной формы. Некоторым нужно обслуживание на уровне миллисекунд в течение всего дня. Некоторым нужен интерактивный поиск для короткой аналитической сессии. Некоторым нужны большие offline processing jobs, которые запускаются, публикуют результаты и исчезают. Единая always-on модель online-хранилища не может эффективно покрыть все это.
Традиционная векторная база данных в первую очередь оптимизирована для первой формы нагрузки. Vector Lakebase предназначена для всех трех поверх одного логического набора данных.
В Zilliz Vector Lakebase эти нагрузки соответствуют трем compute modes — long-running (резидентное обслуживание на уровне миллисекунд), on-demand (интерактивный режим, тарифицируемый поминутно, мост между serving и discovery) и offline batch (крупные задания, которые освобождают вычислительные ресурсы после завершения).
| Тип рабочей нагрузки | Типичные примеры | Вычислительный паттерн |
|---|---|---|
| Обслуживание в реальном времени | Production RAG, память агентов, семантический поиск, рекомендации, персонализация, AI-поиск | Долгоживущие обслуживающие кластеры с горячими индексами, прогретыми кешами и предсказуемой задержкой |
| Интерактивное исследование | Анализ обратной связи, инспекция трасс агентов, поиск аномалий, извлечение холодных данных, семантическое исследование | Вычисления по требованию, которые запускаются при необходимости и освобождают ресурсы после завершения сессии |
| Пакетная аналитика | Дедупликация корпуса, кластеризация, полное повторное эмбеддирование, подготовка обучающих данных, перестроение индексов | Пакетные вычисления для крупных задач, которые выполняются, публикуют результаты и исчезают |
Распространенные варианты использования Vector Lakebases
Поскольку Vector Lakebase объединяет обслуживание и исследование на единой основе, его варианты использования делятся на две группы.
 图片12
图片12
Варианты использования для извлечения (общие с векторной базой данных, теперь на управляемой основе):
- RAG — документы, базы знаний, код и логи как доступный для поиска контекст, поддерживаемый в актуальном состоянии, с управлением правами доступа и возможностью переиндексации по мере изменения моделей.
- Память AI-агентов и использование инструментов — хранить и извлекать память агентов, затем анализировать ее офлайн и возвращать полученные выводы обратно.
- Агентный и мультимодальный поиск — векторный, keyword, full-text и метаданные поиск по текстам, изображениям, аудио, видео и сущностям.
- Рекомендательные системы и многое другое.
Варианты использования жизненного цикла данных (за пределами того, что покрывает одна только векторная база данных):
- Инжиниринг признаков и контекста — выводить сущности, резюме, темы, метки и кластеры, хранящиеся рядом с данными, из которых они были получены.
- Исследование обучающих данных — кластеризовать образцы, находить почти дубликаты, инспектировать выбросы и отслеживать примеры обратно к источнику.
- Предобработка неструктурированных данных — дедупликация, обнаружение аномалий, обогащение и фильтрация качества, записываемые обратно в lake.
Как Vector Lakebase соотносится с векторными базами данных и Lakebases
Vector Lakebase связан с двумя архитектурами: векторными базами данных и Lakebase. Он не является заменой ни одной из них. Таблица ниже дает краткий обзор; последующие разделы объясняют каждую взаимосвязь.
| Векторная база данных | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Основные данные | Векторные эмбеддинги + связанные неструктурированные данные | Неструктурированные и мультимодальные данные, а также полный жизненный цикл вокруг них | Структурированные / транзакционные данные приложений |
| Основная задача | Семантическое извлечение с низкой задержкой | Объединить онлайн-обслуживание и офлайн-исследование на одной основе | Привнести возможности баз данных (OLTP) в открытое lake-хранилище |
| Индексы | Создаются и удерживаются внутри обслуживающего движка | Активы уровня lake: создаются, версионируются, повторно используются в разных режимах вычислений | Табличные / SQL-индексы |
| Вычисления | Постоянно включенное обслуживание | Долгоживущие + по требованию + офлайн-пакетные | Транзакционные |
| Система записи | Часто связана с движком | Открытое lake-хранилище | Открытое lake-хранилище |
| Лучшее применение | Быстрый векторный поиск для онлайн-приложения | Обслуживание и непрерывное улучшение неструктурированных данных в масштабе | Транзакционные данные приложений в lake |
| Связь с vector lakebase | Становится обслуживающим движком внутри Vector Lakebase | - | Структурированный аналог той же lake-native идеи |
Vector Lakebase vs. векторные базы данных
Vector Lakebase не заменяет векторные базы данных. Если организации нужен только векторный поиск с низкой задержкой для одного приложения, векторной базы данных может быть достаточно — она остается правильной системой для production-извлечения, когда важны задержка, масштаб, фильтрация и операционная надежность. Milvus, например, создан для такого рода production-векторного поиска.
Расчет меняется, когда организации необходимо повторно использовать одни и те же неструктурированные данные, эмбеддинги, индексы и семантический контекст между множеством команд, моделей, приложений и рабочих процессов обработки.
В таком мире векторная база данных не должна быть единственным местом, где живут данные и индексы; она становится обслуживающим движком внутри более широкой архитектуры неструктурированных данных. Ее роль становится более конкретной и более важной — она предоставляет путь обслуживания, необходимый AI-приложениям, тогда как Vector Lakebase обеспечивает более широкую основу данных вокруг этого пути. Результат — не меньше векторного поиска; это векторный поиск, связанный с полным жизненным циклом неструктурированных данных.
Если мне нужна только векторная база данных, подходит ли мне Vector Lakebase?
Это совершенно хорошая отправная точка — потому что векторная база данных уже является частью Vector Lakebase. Вы можете использовать слой обслуживающего кластера ровно как автономную векторную базу данных (низколатентный ANN-поиск, гибридный поиск, фильтрация по метаданным, полнотекстовый поиск, JSON-фильтрация, управление индексами, производственная надежность) и в первый день вообще не трогать интерактивное исследование или пакетную аналитику. Разница в том, что вы не заперты в архитектуре, ориентированной только на извлечение: если рабочая нагрузка позже расширится до поиска по холодным данным, крупномасштабной дедупликации, повторного эмбеддинга, подготовки обучающих данных или семантического управления, более широкая архитектура уже будет на месте — без перестройки, без дублирования данных.
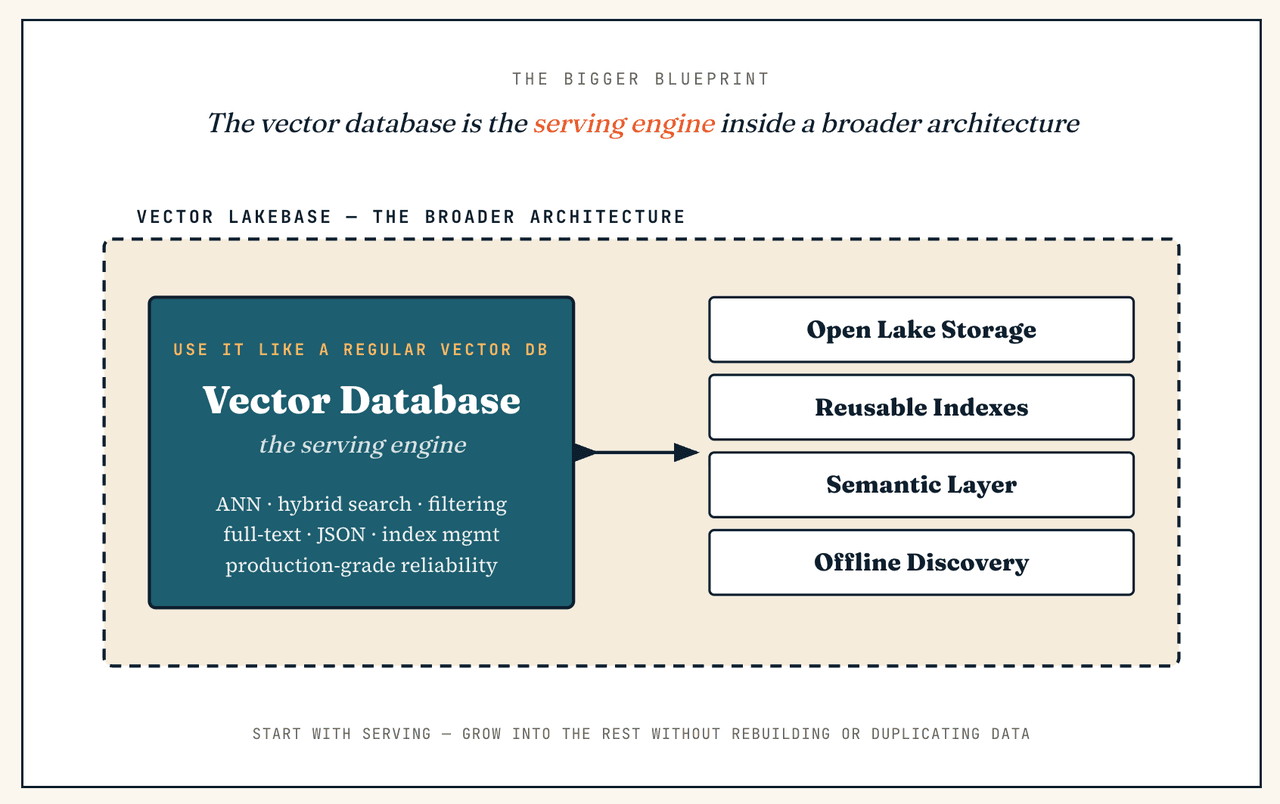
Vector Lakebase против Lakebase
Vector Lakebase связан с Lakebase, но это не просто "Lakebase плюс векторы."

Архитектура в стиле Lakebase привносит возможности, похожие на возможности баз данных, в открытое lake-хранилище для структурированных данных приложений — структурированных записей, транзакций, схем, эластичных вычислений и унифицированного управления, запрашиваемых через известные поля и связи.
Vector Lakebase ориентирован на другой центр тяжести: неструктурированные и мультимодальные данные для AI. Проблема не в том, как хранить состояние приложения в lake; она в том, как управлять семантическими представлениями, векторными индексами, метаданными, контекстом, обратной связью и офлайн-процессами исследования неструктурированных данных — которым нужны семантическая интерпретация, извлечение, уточнение и обратная связь, а не поиск по известным полям. Его лучше описывать не как замену Lakebase, а как идею Lakebase, расширенную на эпоху векторов, индексов и семантического контекста.
| Измерение | Lakebase | Vector Lakebase |
|---|---|---|
| Основные данные | Структурированные данные приложений, транзакционные записи, состояние приложения | Документы, изображения, аудио, видео, логи, код, разговоры, векторы, метаданные и семантический контекст |
| Ключевые абстракции | Таблицы, транзакции, схемы, ветки, клоны | Векторы, индексы, фрагменты, сущности, метки, резюме, разрешения, обратная связь и семантические связи |
| Основные рабочие нагрузки | Чтение и запись приложений, транзакции, аналитика в реальном времени | RAG, память агентов, агентный поиск, мультимодальное извлечение, исследование, инженерия контекста, рабочие процессы обучающих данных |
| Модель запросов | SQL, транзакционные запросы, аналитические запросы | Векторный поиск, гибридный поиск, полнотекстовый поиск, JSON-фильтрация, мультимодальное извлечение, семантическое исследование |
| Семантическая модель | Бизнес-смысл выражен в основном через схему | Смысл выражен через эмбеддинги, метаданные, сущности, резюме, версии моделей, происхождение данных и обратную связь |
| Ценность для AI | Привносит возможности, похожие на возможности баз данных, в открытое lake-хранилище | Привносит AI-контекст, векторное индексирование, семантическое извлечение и офлайн-исследование в lake-native неструктурированные данные |
Чем Vector Lakebase не является
Поскольку Vector Lakebase — это новый архитектурный паттерн, стоит четко обозначить, чем он не является.
- Это не просто озеро данных с эмбеддингами, хранящимися в столбце. Хранение эмбеддингов в таблице озера сохраняет векторы, но не предоставляет ничего из того, что нужно производственным AI-системам: индексации, обслуживания, семантических метаданных, гибридного поиска, цикла обратной связи или пути извлечения с низкой задержкой. Векторы полезны, когда их можно искать, управлять ими, версионировать, фильтровать, связывать с исходными данными и улучшать со временем — а не просто хранить.
- Это не просто векторная база данных, подключенная к object storage. Размещение object storage за векторной базой данных может снизить стоимость хранения, но не решает вопросы повторного использования индексов, офлайн-обнаружения, управления, версионирования или согласованности между обработанными и обслуживаемыми данными. Сложность не в том, где находятся байты; она в том, как данные, индексы, метаданные, семантические сигналы и режимы вычислений работают вместе как единая операционная система.
- Это не офлайн-система аналитики. Офлайн-обнаружение — лишь одна сторона архитектуры. Vector Lakebase также обслуживает производственный трафик, поддерживает горячие пути извлечения, управляет индексами, обеспечивает контроль доступа и возвращает релевантный контекст приложениям и агентам. Смысл не в том, чтобы выбирать между обслуживанием и аналитикой, — а в том, чтобы соединить их.
- Это не отход от векторных баз данных. Возможно, это самый важный момент, который мы неоднократно упоминали. Vector Lakebase не делает векторные базы данных менее актуальными. Он дает им более широкую архитектуру для работы.
Zilliz Vector Lakebase доступен в публичном предварительном просмотре
Мы запустили публичный предварительный просмотр Zilliz Vector Lakebase — важную эволюцию Zilliz Cloud от чисто управляемой векторной базы данных к единой семантической платформе данных, которая сочетает векторное обслуживание с низкой задержкой с открытостью, масштабируемостью и экономикой озера данных.
Ключевые возможности Zilliz Vector Lakebase:
- Многоуровневое обслуживание, оптимизированное под разные компромиссы между производительностью в реальном времени и стоимостью
- Поиск по требованию для крупномасштабных или исследовательских рабочих нагрузок без постоянно включенных вычислений
- Поиск во внешнем озере данных — индексируйте и ищите напрямую по вашим существующим данным в озере
- AI-поиск полного спектра по векторам, тексту, JSON и геопространственным данным с гибридным извлечением и reranking
- Единое lake-native хранилище на базе Vortex, открытый формат с более быстрым и дешевым случайным чтением, чем Lance или Parquet
Если ваш текущий стек разделяет обслуживание и обнаружение на отдельные системы, возможно, стоит взглянуть на Vector Lakebase. Попробуйте его в Zilliz Cloud — новые регистрации с рабочей электронной почтой получают $100 бесплатных кредитов — или свяжитесь с нами, чтобы обсудить ваш сценарий использования.
Узнайте больше о Vector Lakebases
- От Vector Database к Vector Lakebase
- Мы 8 лет делали векторный поиск быстрее. Затем AI изменил модель вычислений
- Почему мы создали Vector Lakebase: переосмысление архитектуры неструктурированных данных для AI
- Vector Lakebase: положить конец разрозненности AI-данных
- Zilliz Cloud On-Demand Compute: платите только за то, что используете
- Векторный поиск Notion превосходен. Их следующая проблема сложнее.
Читать далее

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.