




Сбой AWS стал тревожным сигналом для межрегионального аварийного восстановления векторных баз данных
Облачные регионы выходят из строя. Вопрос не в том, произойдёт ли это — вопрос в том, когда и насколько серьёзно.
На прошлой неделе два региона AWS на Ближнем Востоке ушли в офлайн из-за физического повреждения инфраструктуры дата-центров. Две из трёх зон доступности в регионе AWS UAE (ME-CENTRAL-1) были выведены из строя, а объект в Бахрейне (ME-SOUTH-1) был повреждён. Пострадало более 60 сервисов AWS, включая Lambda, EKS, VPC, S3 и CloudWatch. Careem, крупнейшая в регионе платформа для заказа поездок, потеряла сервис. Alaan, ведущий провайдер платежей, перестал работать. AWS рекомендовала клиентам перенести рабочие нагрузки в другие регионы — но это не был инцидент уровня «перезагрузить и восстановиться». При замене оборудования и ремонте объекта восстановление может занять недели.
И физическое повреждение — лишь один из сценариев отказа. За последние 12 месяцев ошибочное изменение конфигурации вывело из строя регион Azure Central US на 14,5 часа. Ошибка в Google Cloud одновременно отключила Cloud Run, GKE и Firebase на 8 часов. Некорректное обновление ПО CrowdStrike — даже не проблема облачного провайдера — каскадно затронуло инфраструктуру, размещённую в Azure, обойдясь компаниям из Fortune 500, по оценкам, в $5,4 млрд.
В отчёте Uptime Institute за 2025 год медианная стоимость серьёзного сбоя оценивается в $2 млн в час, что примерно вдвое больше показателя трёхлетней давности. При этом отчёт Veeam Data Protection Trends Report за 2024 год показал, что только 13% организаций действительно способны организовать восстановление во время реальной катастрофы.
Эти цифры уже были тревожными. Затем AI поднял ставки.
Когда AI отключается, команды не замедляются — они останавливаются
Пять лет назад отказ облачного региона в основном бил по приложениям для клиентов. Болезненно, но большинство команд всё ещё могли работать внутри компании. Сегодня AI вобрал в себя работу, охватывающую целые отделы, — ревью кода, документацию, сортировку обращений в поддержку и даже рутинный анализ. Поскольку почти 60% сотрудников используют AI в ежедневных рабочих процессах, сбои не вызывают постепенного замедления. Производительность обрывается как с обрыва.
Мы уже видели, как это происходит, — ChatGPT и Claude оба столкнулись с серьёзными сбоями в начале 2026 года, оставив миллионы пользователей и корпоративные команды без AI-инструментов, вокруг которых они выстроили свои рабочие процессы.
Но вот что большинство команд упускает из виду. Сбои моделей нарушают работу, однако модели в значительной степени не имеют состояния: провайдеры часто могут довольно быстро перенаправить инференс-трафик в исправные регионы. Более сложная проблема — нижележащий слой данных — базы данных, объектные хранилища и векторные индексы, которые предоставляют память и контекст. Этот слой имеет состояние, привязан к региону и гораздо сложнее в восстановлении. Когда он выходит из строя, ваш LLM может всё ещё генерировать текст — но без правильного контекста он по умолчанию выдаёт обобщённый, склонный к галлюцинациям результат. AI не просто уходит в офлайн. Он становится ненадёжным.
Векторная база данных — это долговременная память вашего AI, и, вероятно, она находится в одном регионе
Векторные базы данных стали основой корпоративного AI. RAG-пайплайны и AI-агенты извлекают из них контекст. Рекомендательные движки обращаются к ним с запросами. Семантический поиск работает по ним. Когда этот слой недоступен, ломается каждое приложение, построенное поверх него, — не частично, а полностью.
И, в отличие от сервисов без состояния, восстановление здесь не простое:
- Перестроение индексов занимает много времени. Векторный поиск зависит от индексных структур вроде графов HNSW, где время перестроения растёт нелинейно с размером набора данных. Перестроение индекса по более чем 100 млн векторов может занять 18+ часов на стандартных вычислительных ресурсах.
- Строки подключения повсюду. Каждому приложению, подключавшемуся к старому кластеру, нужно обновить endpoint — в конфигах, переменных окружения, CI/CD-пайплайнах, часто управляемых разными командами.
- Дрифт embedding-модели. Если вы не можете найти точную версию embedding-модели, которая сгенерировала ваши текущие векторы, вам может понадобиться заново embedding-овать весь набор данных.
При программном сбое вы ждете перезапуска. Но когда центр обработки данных физически поврежден, восстановление занимает недели. Единственная жизнеспособная стратегия — уже иметь работающую, индексированную, готовую к запросам реплику, обслуживаемую из другого региона — с перенаправлением трафика, не требующим изменений в коде.
Zilliz Cloud: первая в мире векторная база данных с нативным аварийным восстановлением между регионами
Zilliz Cloud — первая в мире векторная база данных, предлагающая нативное аварийное восстановление между регионами — с автоматическим переключением при отказе, репликацией в реальном времени и глобальной конечной точкой, которая не требует изменений в приложении при переходах между регионами.
Мы предоставляем две взаимодополняющие возможности: Global Cluster для переключения при отказе в реальном времени и Cross-Region Backup для экономически эффективного аварийного восстановления.
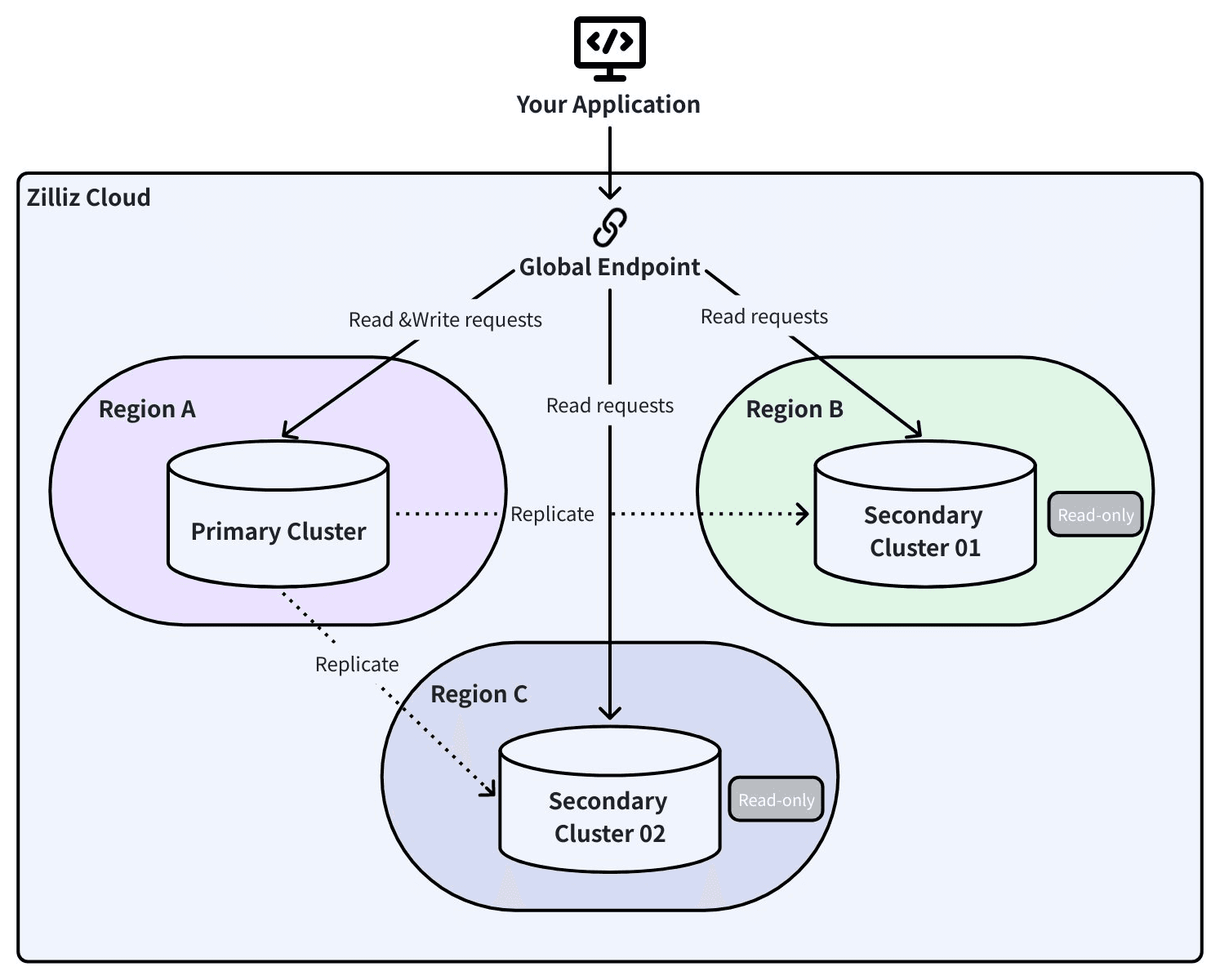
Global Cluster: оперативная репликация с автоматическим переключением при отказе
Global Cluster использует Change Data Capture (CDC) для непрерывной репликации данных между основным кластером и вторичным кластером в другом регионе. Не периодические снимки — каждая вставка, обновление и удаление передаются в реальном времени.
- Плановое переключение (обслуживание, миграция, соответствие требованиям): система завершает обработку текущих CDC-сообщений, подтверждает полную синхронизацию, затем меняет роли. RPO равен нулю. RTO составляет менее 30 секунд.
- Автоматическое переключение при отказе (неожиданный сбой региона): вторичный кластер автоматически повышает свой статус. RPO равен задержке CDC в момент сбоя — обычно несколько секунд. RTO составляет менее 60 секунд.
Одна уникальная возможность: после переключения при отказе старый основной кластер не просто исчезает. Он попадает в корзину с хранением в течение 7 дней, а потоковый API под названием DumpMessages позволяет извлечь любые записи, которые попали на старый основной кластер, но еще не были реплицированы. Вместо того чтобы смириться с потерей данных, вы получаете окно для их восстановления.
Global Endpoint: одно подключение, каждый регион
Именно здесь архитектура окупается в сценарии физической катастрофы.
Ваше приложение подключается к единой глобальной конечной точке. За ней SRV DNS-записи отслеживают, какой кластер является основным, а какой — вторичным. Когда происходит переключение при отказе, SDK обнаруживает изменение топологии и автоматически перенаправляет трафик. Никаких обновлений строки подключения. Никаких перезапусков приложения. Никаких изменений в коде.
Подумайте, что это означает во время продолжительного регионального сбоя. Без глобальной конечной точки восстановление требует, чтобы кто-то нашел регламент, вручную перенастроил клиенты, обновил строки подключения и скоординировал действия между командами — в 3 часа ночи, под давлением. Ваш RTO измеряется не секундами, а тем, сколько времени потребуется, чтобы вызвать нужного инженера.
С Global Endpoint ваш RAG-пайплайн отправляет запросы к реплике в другом регионе в течение 60 секунд, без изменения единой строки кода.
Cross-Region Backup: устойчивость без стоимости работающей реплики
Не каждая рабочая нагрузка оправдывает запуск вторичного кластера. Cross-Region Backup реплицирует резервные данные в один или несколько целевых регионов, каждый со своей политикой хранения. Когда происходит сбой на уровне региона, вы разворачиваете новый кластер из любой точки резервного копирования в целевом регионе — без необходимости передачи данных между регионами во время кризиса, потому что данные уже там.
Компромисс:
- Global Cluster → RPO в секундах, RTO менее 60 секунд. Для рабочих нагрузок, которые не могут терпеть простоя.
- Cross-Region Backup → RPO и RTO в часах. Для рабочих нагрузок, где сохранность данных важнее мгновенного восстановления.
Многие команды начинают с Cross-Region Backup ради критически важной гарантии — ваши данные переживут региональный сбой — и переходят на Global Cluster по мере того, как их AI-нагрузки становятся критически важными.
Как другие векторные базы данных справляются с аварийным восстановлением между регионами
Большинство векторных баз данных обеспечивают высокую доступность в пределах одного региона с помощью наборов реплик и избыточности узлов. Это помогает при сбоях узлов — но не при сбоях региона. Zilliz Cloud — единственная векторная база данных, предлагающая встроенное автоматизированное межрегиональное переключение при сбое с глобальным кластером и глобальным endpoint — переходы между регионами без простоя и без изменений в коде.
| Возможность | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Межрегиональная репликация | ✅ На основе CDC, в реальном времени | ❌ | ❌ | ❌ | ❌ |
| Незапланированное переключение при сбое | ✅ RPO ≈ секунды, RTO<= 30 с | ❌ | ❌ | ❌ | ❌ |
| Плановое переключение | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Восстановление данных после переключения при сбое | ✅ Автоматическое восстановление несинхронизированных данных. | ❌ | ❌ | ❌ | ❌ |
| Global Endpoint | ✅ Один Global endpoint, автоматическая перемаршрутизация без изменений в коде | ❌ | ❌ | ❌ | ❌ |
| RPO/RTO при региональном сбое | ✅ RPO ≈ секунды, RTO < 30 с | ❌ | ❌ | ❌ | ❌ |
| Автоматическое межрегиональное резервное копирование | ✅ ЛЮБОЙ регион с хранением по регионам | ❌ | ❌ | ❌ | ❌ |
За пределами аварийного восстановления
Команды также используют Global Cluster для операционных сценариев, не связанных со сбоями:
- Оптимизация задержки: Добавьте вторичный регион ближе к вашим пользователям, чтобы время ответа на запросы было менее 100 мс.
- Миграция региона: Переносите рабочие нагрузки между регионами без простоя во время консолидации инфраструктуры.
- Соответствие требованиям резидентности данных: Храните данные в определённых географических границах для соблюдения нормативных требований.
Тот же конвейер CDC, который защищает от сбоев, также предоставляет вам реплику с возможностью чтения ближе к вашим пользователям — возможность DR как побочный эффект оптимизации производительности.
Начало работы
Global Cluster и Cross-Region Backup доступны в Zilliz Cloud для выделенных кластеров.
- Если у вас уже есть аккаунт Zilliz Cloud, просто войдите и сразу начните пользоваться новыми возможностями — без обновлений или миграций.
- Новичок в Zilliz Cloud? Зарегистрируйтесь бесплатно и получите \$100 кредитов, чтобы познакомиться с ведущей в мире управляемой векторной базой данных.
- Есть вопросы по любым обновлениям? Ознакомьтесь с последней документацией или обратитесь в Zilliz Support — мы готовы помочь.
Создавайте без ограничений: подробный обзор готовых для enterprise возможностей Zilliz Cloud
Global Cluster — это одна часть более широкой платформы, созданной для AI в производственном масштабе. Zilliz Cloud также предлагает:
- Эластичное масштабирование и экономическая эффективность – Развёртывание в один клик, serverless-автомасштабирование и оплата по мере использования.
- Продвинутый AI-поиск – Векторный, полнотекстовый и гибридный (разреженный + плотный) поиск с фильтрацией по метаданным, динамической схемой и мультитенантностью.
- Безопасность enterprise-уровня – SLA 99,95%, сертификации SOC 2 Type II и ISO 27001, соответствие GDPR, готовность к HIPAA, RBAC, BYOC и журналы аудита. Подробнее см. в нашем trust center.
- Глобальная доступность – Развёртывания в AWS, GCP и Azure с задержкой менее 100 мс по всему миру.
- Бесшовная миграция – Встроенные инструменты для перехода с Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate или локального Milvus.
- Запросы на естественном языке – Поддержка MCP server для интуитивных запросов без сложных API.
- И многое другое!

Читать далее

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.