




Представляем функции и инференс моделей в Zilliz Cloud: автоматическое эмбеддинг-представление и переранжирование с размещёнными моделями
Поисковые AI-пайплайны, построенные на векторных базах данных, обычно требуют, чтобы вы самостоятельно генерировали эмбеддинги, вставляли их в векторную базу данных для поиска по сходству, таким же образом эмбеддили каждый запрос и подключали отдельный сервис реранжирования, если хотите повысить качество результатов. Это работает, но означает больше связующего кода и больше мест, где что-то может разойтись.
Сегодня мы объявляем о Functions and Inference Services в Zilliz Cloud — теперь в Public Preview для сторонних моделей и в Private Preview для Zilliz Hosted Models. Вы можете вставлять необработанный текст и выполнять поиск с помощью естественного языка. Затем Zilliz Cloud автоматически обрабатывает генерацию эмбеддингов, хранение векторов и реранжирование результатов.
Что такое Functions and Inference Services в Zilliz Cloud?
A Function — это декларативная операция, привязанная к коллекции, которая сообщает Zilliz Cloud, как обрабатывать ваши данные. Вместо отправки векторов теперь достаточно отправлять необработанный текст. Вместо эмбеддинга запросов на стороне клиента вы отправляете текстовые запросы напрямую. Затем Zilliz Cloud берет на себя все остальное.
Функции делятся на две категории:
- Pre-search Functions выполняются во время ingest и запроса, преобразуя текст в представления, пригодные для поиска. Сюда входят BM25 для полнотекстового поиска по ключевым словам (модель не требуется) и подходы на основе моделей, которые создают плотные эмбеддинги для семантического поиска.
- Post-search Functions выполняются после извлечения, уточнения и переупорядочивания результатов. Сюда входят гибридные ранжировщики, объединяющие несколько наборов результатов, ранжировщики на основе правил для бизнес-логики и ранжировщики на основе моделей, которые оценивают релевантность между запросами и документами.
Следующая диаграмма дает абстрактное представление о том, как Functions работают в поисковом workflow.
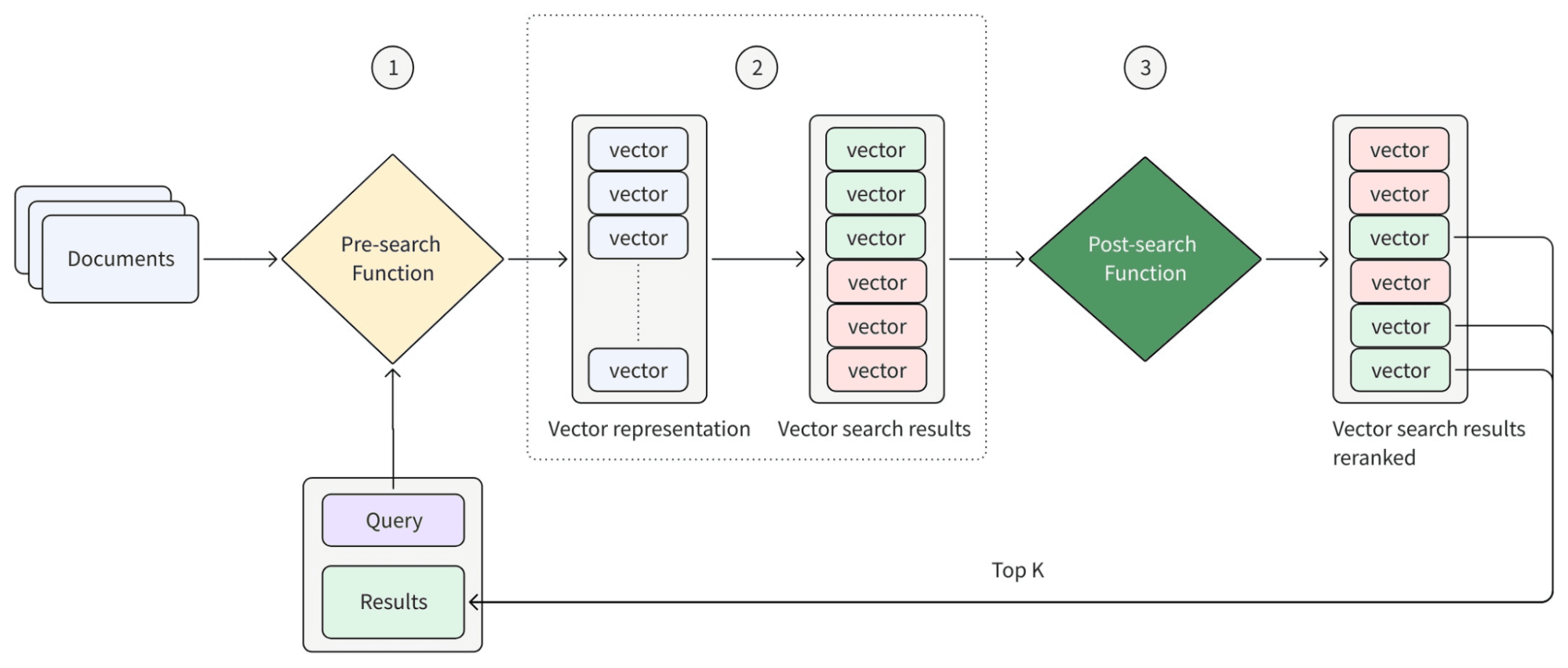
Inference Services обеспечивают работу Functions на основе моделей. Когда Function нужно сгенерировать эмбеддинг или оценить пару «запрос-документ», она вызывает модель из одного из двух источников:
| Источник | Как это работает |
|---|---|
| Сторонние провайдеры (OpenAI, Voyage AI, Cohere) | Вы предоставляете свой API-ключ. Zilliz Cloud управляет интеграцией. |
| Zilliz Hosted Models | Полностью управляемые экземпляры моделей на GPU-инфраструктуре Zilliz. Ваши данные никогда не покидают платформу. |
Самое простое различие: Functions определяют, что происходит с вашими данными. Inference Services определяют, какая модель выполняет работу.
Зачем переносить эмбеддинг и реранжирование в Zilliz Cloud?
Если сегодня вы вызываете API эмбеддингов и вставляете векторы в Zilliz Cloud, это уже работает. Но по мере масштабирования приложений возникает несколько точек трения.
Согласованность моделей становится вашей проблемой
Ваши пути ingest и запросов должны использовать одну и ту же модель. Если они расходятся — например, развертывание обновляет одну сторону, но не другую, — качество поиска незаметно ухудшается. С Functions конфигурация модели принадлежит коллекции. Ingest и запрос гарантированно совпадают.
Реранжирование пропускают, потому что оно создает слишком много трения
Реранжирование на основе моделей существенно улучшает качество результатов, особенно для гибридного поиска. Но добавление еще одного вызова сервиса после каждого запроса — со своим API-ключом, бюджетом задержки и обработкой сбоев — создает достаточно трения, чтобы многие команды выпускали продукт без него. Когда реранжирование является встроенной Function, это трение исчезает.
Учетные данные расползаются по сервисам
Каждому сервису, который записывает или ищет данные, нужен API-ключ вашего провайдера эмбеддингов. С Functions учетные данные хранятся в Model Provider Integration Zilliz Cloud — одно место для управления, одно место для ротации ключей, никаких секретов в коде приложения.
Данные покидают вашу сеть при каждом вызове инференса
Для команд с требованиями к конфиденциальности или соответствию нормативам отправка сырого текста во внешний API при каждой вставке и запросе — реальная проблема. Hosted Models сохраняют всё — данные, инференс, хранение, поиск — внутри частной сети Zilliz.
Что доступно в Public Preview
Функции эмбеддингов на основе моделей
Привяжите модель эмбеддингов к коллекции. С этого момента:
- Вставляйте сырой текст через Insert, Upsert или Import — Zilliz Cloud автоматически генерирует и сохраняет плотные векторные эмбеддинги.
- Ищите по тексту — система преобразует ваш запрос в эмбеддинг с помощью той же модели и выполняет ANN-поиск.
Никакого клиентского кода для эмбеддингов. Никаких проблем с согласованностью моделей. Ваше приложение просто работает с текстом.
Функции реранжирования на основе моделей
Выберите модель реранжирования и применяйте ее как встроенный этап после поиска. Это особенно эффективно для гибридного поиска, где вы объединяете семантический и ключевой поиск в один набор результатов.
Реранжировщики на основе моделей выходят за рамки векторного сходства — они читают содержимое каждого кандидата и оценивают, насколько хорошо он действительно отвечает на запрос. Это разница между «эти векторы находятся рядом» и «этот документ отвечает на вопрос».
Поддерживаемые провайдеры
| Провайдер | Эмбеддинг | Реранжирование |
|---|---|---|
| OpenAI | Да | -- |
| Voyage AI | Да | Да |
| Cohere | Да | Да |
Интеграция с провайдерами моделей
Зарегистрируйте учетные данные стороннего API один раз в консоли Zilliz Cloud через Model Provider Integration. Коллекции ссылаются на интеграцию по ID — никаких ключей в коде. Ротируйте учетные данные в одном месте; каждая коллекция, использующая эту интеграцию, автоматически применяет изменения.
Что доступно в Private Preview: Hosted Models
Для команд, для которых приоритетны задержка, стоимость или резидентность данных, Hosted Models запускают полностью управляемые экземпляры моделей на GPU-инфраструктуре Zilliz. Архитектурное отличие: вместо отправки данных во внешний API модель работает прямо рядом с вашими данными.
На следующей диаграмме показаны процедуры использования hosted models.
| Преимущество | Что это означает |
|---|---|
| Нулевые комиссии за передачу данных | Инференс происходит внутри сети Zilliz |
| Меньшая задержка | Нет внешнего кругового запроса для эмбеддинга или реранжирования |
| Повышенная конфиденциальность | Сырой текст никогда не покидает среду Zilliz |
| Выделенные ресурсы | Нет проблем с производительностью из-за «шумных соседей» |
Доступные модели
| Категория | Модели |
|---|---|
| Эмбеддинг | Qwen3-Embedding (0.6B, 4B, 8B), BAAI BGE series (small, base, large — EN & ZH) |
| Реранжирование | Qwen3-Reranker (0.6B, 4B, 8B), BAAI BGE Reranker (base, large) |
| Semantic Highlighter | zilliz/semantic-highlight-bilingual-v1 — выделяет релевантные фрагменты текста в результатах |
Hosted Models доступны по запросу. Свяжитесь с командой Zilliz, чтобы получить доступ.
Обзор всех возможностей функций и инференса
Функции перед поиском
| Функция | Описание | Статус |
|---|---|---|
| BM25 | Разреженные embeddings для полнотекстового поиска по ключевым словам — модель не требуется | GA |
| Model-Based Embedding (3rd-party) | Плотные embeddings через OpenAI, Voyage AI, Cohere | Public Preview |
| Model-Based Embedding (Hosted) | Плотные embeddings через размещённые в Zilliz Qwen3, BGE | Private Preview |
Функции после поиска
| Функция | Описание | Статус |
|---|---|---|
| Hybrid Rankers | Объединяют результаты из нескольких стратегий извлечения (например, семантический + по ключевым словам) | GA |
| Rule-Based Rankers | Применяют бизнес-логику — актуальность, популярность, пользовательские оценки | GA |
| Model-Based Rankers (3rd-party) | Семантическое переранжирование через Voyage AI, Cohere | Public Preview |
| Model-Based Rankers (Hosted) | Семантическое переранжирование через размещённые в Zilliz Qwen3, BGE | Private Preview |
BM25, гибридные ранжировщики и ранжировщики на основе правил уже были общедоступны. Сегодняшний релиз добавляет интеллектуальные возможности на базе моделей как для embedding, так и для ранжирования — плюс инфраструктуру для запуска этих моделей через сторонние API или непосредственно в Zilliz Cloud.
Как начать работу с Zilliz Cloud Functions
Public Preview (доступно сейчас):
- Зарегистрируйтесь или войдите в Zilliz Cloud — новые аккаунты, зарегистрированные с рабочей электронной почтой, получают $100 бесплатных кредитов
- Настройте Model Provider Integration в консоли
- Создайте коллекцию с функцией embedding
- Вставьте исходный текст и выполняйте поиск по тексту — вот и всё
Private Preview (по запросу):
Свяжитесь с нами , чтобы попробовать Hosted Models с выделенным инференсом.
Полная документация: Руководство по Function and Model Inference
Часто задаваемые вопросы
Несколько вопросов, которые возникают вокруг embedding, переранжирования и управляемого инференса для векторного поиска:
Может ли векторная база данных генерировать embeddings автоматически?
Да. С Zilliz Cloud Functions вы привязываете модель embedding к коллекции и вставляете исходный текст — база данных генерирует и сохраняет плотные векторные embeddings от вашего имени. Запросы работают так же: отправьте текстовый запрос, и система преобразует его в embedding с помощью той же модели перед запуском ANN-поиска. Это устраняет необходимость в клиентском коде для embedding и гарантирует согласованность модели между загрузкой данных и поиском.
Что такое переранжирование на основе модели и как оно улучшает векторный поиск?
Переранжирование на основе модели — это этап после извлечения, на котором языковая модель оценивает, насколько хорошо каждый документ-кандидат действительно отвечает на запрос, — вместо того чтобы полагаться исключительно на оценки векторного сходства. Оно особенно эффективно для гибридных поисковых конвейеров, которые объединяют поиск по ключевым словам и семантическое извлечение. В Zilliz Cloud вы можете применять переранжирование на основе модели как встроенную Function с использованием провайдеров, таких как Voyage AI или Cohere, либо через Zilliz Hosted Models.
В чём разница между hosted и third-party embedding models?
Сторонние модели (OpenAI, Voyage AI, Cohere) работают на инфраструктуре провайдера — вы предоставляете API-ключ и платите за каждый вызов. Hosted Models работают на GPU-инфраструктуре под управлением Zilliz, поэтому ваши данные никогда не покидают платформу. Hosted Models предлагают меньшую задержку, нулевые комиссии за передачу данных и выделенные вычислительные ресурсы без проблем «шумных соседей». Компромисс: оплата за вызов у сторонних провайдеров может быть дешевле при малых объёмах, тогда как hosted-инстансы более экономически эффективны в масштабе.
Как объединить поиск по ключевым словам и семантический поиск в одном запросе?
В Zilliz Cloud вы можете подключить как функцию BM25 (для поиска по ключевым словам через разреженные эмбеддинги), так и функцию эмбеддингов на основе модели (для семантического поиска через плотные эмбеддинги) к одной и той же коллекции. Во время запроса гибридный ранжировщик или реранжировщик на основе модели объединяет результаты в единый ранжированный список. Коллекция обрабатывает разреженные эмбеддинги, плотные эмбеддинги и реранжирование вместе — внешняя оркестрация не требуется.

Читать далее

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.