




Vector Lakebase: покончите с изоляцией данных ИИ
Каждая AI-команда сталкивается с одной и той же стеной — гравитацией данных
Каждая современная команда по работе с данными построила ту или иную версию одной и той же архитектуры. Lakehouse — таблицы Iceberg на S3, Spark-пайплайн и Delta Lake для управления — находится в центре. Это хорошо работает. Затем появляются требования AI.
Вашему RAG-пайплайну нужно отвечать на вопросы по корпоративным документам за 10 лет, поэтому вы копируете всё в векторную базу данных. Вашим AI-агентам нужен доступ с низкой задержкой к эмбеддингам каталога продуктов — ещё один пайплайн, ещё одна задача синхронизации. Обучение вашей мультимодальной модели требует ежедневной дедупликации по миллиарду эмбеддингов изображений — Spark-задача, которая не видит индекс.
Шесть месяцев спустя у вас пять систем вместо двух. Ваша команда data engineering тратит больше времени на поддержку пайплайнов синхронизации, чем на создание AI-функций. У вас три копии одного и того же набора данных без гарантии, что они совпадают. Каждое изменение схемы каскадно затрагивает четыре разных места.
Это не провал исполнения. Это провал архитектуры — в частности, архитектуры, которая продолжает бороться с фундаментальным свойством данных: гравитацией. Каждая система, которая требует сначала скопировать данные, взимает с вас налог на гравитацию. Чем больше AI-нагрузок вы добавляете — RAG-пайплайны, память агентов, обучение моделей, рекомендации в реальном времени — тем выше становится этот налог.
Правильное решение — не лучший пайплайн. Это должна быть новая архитектурная парадигма: Vector Lakebase.
Три поколения архитектурных решений, два тупика
Прежде чем углубиться в детали Vector Lakebase, стоит посмотреть, как архитектура векторного поиска развивалась для решения проблемы гравитации данных. В широком смысле было три поколения решений.
Поколение 1: специализированные векторные базы данных
Специализированные векторные базы данных, такие как Milvus, решили реальную проблему для production AI-систем: семантический поиск с миллисекундной задержкой, полнотой и производительностью, которых не могли обеспечить базы данных общего назначения. Как создатели open-source векторной базы данных Milvus, Zilliz давно сосредоточена на создании надёжной, высокопроизводительной системы для хранения эмбеддингов, построения индексов и обслуживания извлечения с низкой задержкой для RAG, агентов, рекомендательных систем, семантического поиска и мультимодальных приложений. Эта основа всё ещё важна. Production AI-системам по-прежнему нужно извлечение со скоростью базы данных, и векторные базы данных остаются правильным serving-слоем для многих чувствительных к задержкам нагрузок.
Однако по мере зрелости AI-нагрузок задача всё чаще выходит за рамки online serving. Большая часть исходных данных организации уже находится в объектном хранилище, data lake, lakehouse и downstream-аналитических системах. Чтобы использовать эти данные в специализированной векторной базе данных, команды обычно копируют их в отдельную serving-систему, строят ingestion-пайплайны, поддерживают задачи синхронизации и управляют согласованностью между исходными данными и векторным индексом. Когда модели эмбеддингов меняются, а это неизбежно происходит, командам нужно заново генерировать эмбеддинги, перестраивать индексы и согласовывать несколько систем.
Это не ограничение производительности векторной базы данных. Это архитектурная граница, созданная перемещением данных. По мере того как всё больше команд хотят использовать одни и те же данные для production-извлечения, экспериментов с эмбеддингами, offline-оценки, управления, lineage и аналитики, операционная поверхность растёт. Специализированные векторные базы данных чрезвычайно хорошо решили проблему online-извлечения, но сами по себе они не устраняют проблему гравитации данных.
Поколение 2: Vector Lake
Следующей естественной реакцией было приблизить векторный поиск к lake: запрашивать векторы напрямую из Iceberg, Delta Lake или Parquet-файлов, не перемещая их сначала в специализированную serving-систему. Мотивация была правильной. Если данные уже находятся в объектном хранилище или lakehouse, зачем дублировать их где-то ещё, только чтобы сделать доступными для поиска?
Но на практике архитектуры векторных озёр остаются неполноценными для производственных AI-нагрузок по трём причинам.
Во-первых, они не предназначены для обслуживания с низкой задержкой. Большинство подходов к векторным озёрам загружают данные или индексы из объектного хранилища по требованию и оптимизированы скорее для гибкости, чем для конкурентной обработки запросов, чувствительных к задержке. Это может быть приемлемо для офлайн-исследований, но недостаточно для пользовательских RAG, агентов, рекомендательных или поисковых приложений. Когда конвейер извлечения находится на критическом пути вызова LLM, командам нужна предсказуемая задержка менее 100 мс при высокой конкурентности. Если задержка p99 регулярно уходит в диапазон секунд, система всё ещё может быть полезна для анализа, но не может служить производственным слоем извлечения.
Во-вторых, системы векторных озёр обычно останавливаются на этапе поиска. Они позволяют командам запрашивать векторные данные в озере, но не предоставляют более широкую среду выполнения для рабочих процессов AI-данных. Современным AI-системам нужно больше, чем поиск ближайших соседей. Им нужно заново генерировать эмбеддинги, оценивать качество извлечения, сжимать память агентов, извлекать кадры из видео, обрабатывать мультимодальные данные, управлять метаданными и подготавливать данные для дообучения или последующих конвейеров. Система, которая лишь добавляет поиск поверх файлов озера, не решает полный жизненный цикл векторных и мультимодальных данных.
В-третьих, базовый слой хранения не был создан для такой нагрузки. Iceberg и Delta Lake были разработаны для структурированных аналитических данных — без нативных векторных типов, без индексных структур, каждый запрос представляет собой полное сканирование. AI-нагрузкам нужны быстрые точечные обращения (а не последовательные сканирования групп строк Parquet — именно поэтому существуют форматы вроде Vortex и Lance), встроенные индексы, совместно управляемые с данными, и управление неструктурированными данными на основе ссылок, где изображения, аудио и видео связываются по ссылке, а не встраиваются как blob-объекты. Ничего из этого сегодня в озере нет. Vector Lake, построенный на Iceberg, борется со слоем хранения на каждом уровне.
Поколение 3: Vector Lakebase
Vector Lakebase — это то, что получается, когда вы перестаёте рассматривать озеро и векторную базу данных как отдельные системы, которые нужно синхронизировать, и начинаете строить их как два режима работы единого унифицированного слоя. Если говорить точнее:
Vector Lakebase — это новая AI-native и lake-native архитектура, развившаяся из систем векторных баз данных. Она объединяет возможности векторных баз данных по обслуживанию с высоким QPS и низкой задержкой с открытостью, масштабируемостью и экономической эффективностью мультимодальных озёр данных, при этом удерживая все нагрузки на одном источнике истины без миграции данных. Разделяя вычисления и хранение, Vector Lakebase хранит мультимодальные данные, векторы, атрибуты, индексы и метаданные напрямую в недорогом объектном хранилище с использованием открытых форматов. Затем нагрузки обслуживания, обнаружения и аналитики могут выполняться независимо поверх одних и тех же данных.
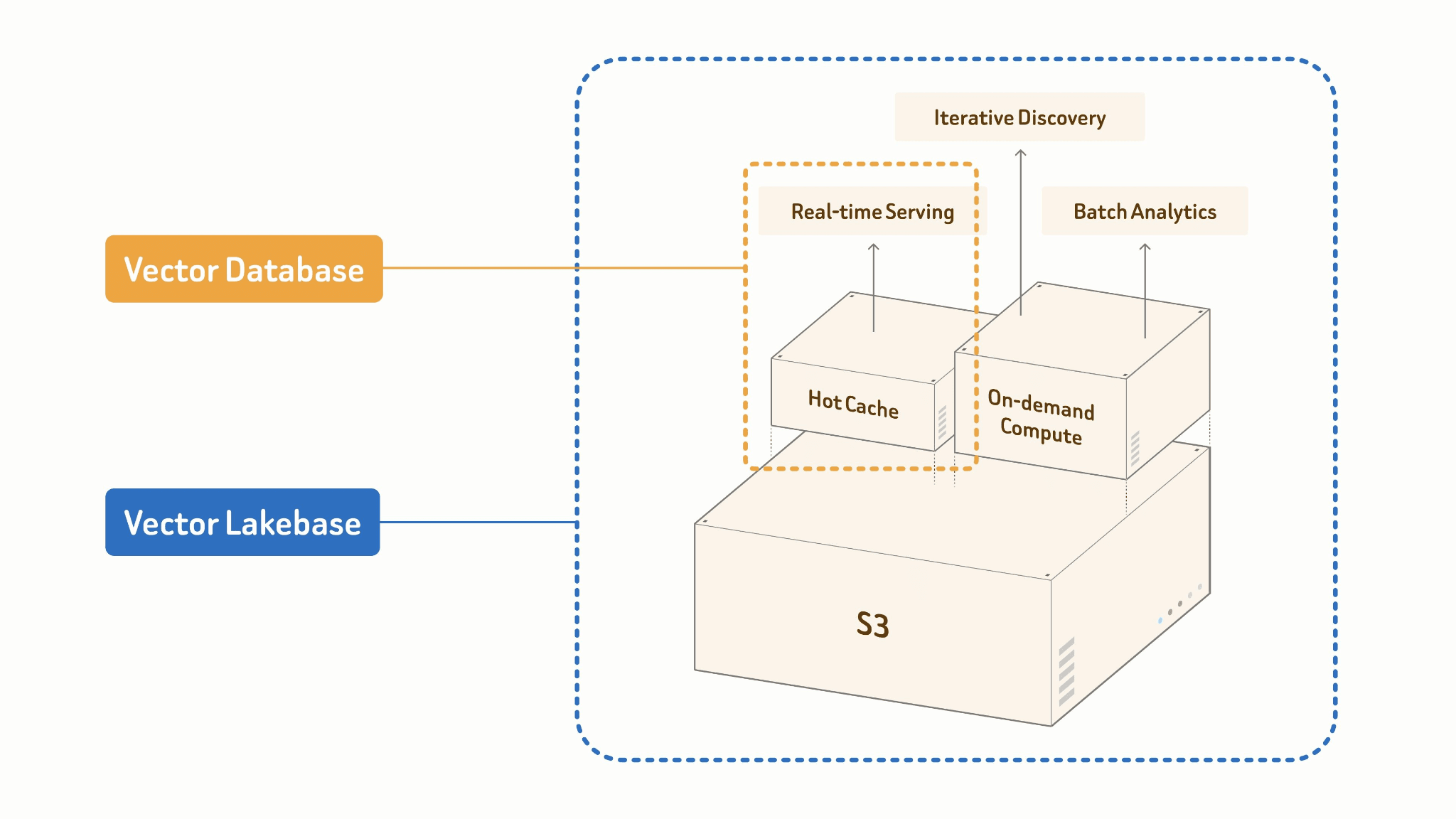
Ключевой принцип: Один источник истины.
Ваша таблица озера — это единый источник истины. Онлайн-обслуживание и офлайн-пакетная обработка используют одни и те же данные, индекс и схему. Между ними нет конвейера, потому что между ними нет границы.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplication + staleness
Vector Lake: [Lake + Index] ◀── batch query only # no serving, no processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN query, <100ms p99 serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ embed, cluster, dedup, feature engineering
Два режима по необходимости устроены по-разному. Онлайн-обслуживание работает с горячим кешем и высокопроизводительным индексом в памяти — оптимизированным для параллельности и хвостовой задержки. Офлайн-пакетные задания строят индексы экономически эффективно и в масштабе: колоночные сканирования, построение с ускорением на GPU, поэтапная запись обратно в lake. Те же данные, тот же формат индекса, радикально разные вычислительные профили.
Как это выглядит на практике? На Iceberg-таблице с 1 миллиардом векторов:
| Режим | Задержка | Контекст |
|---|---|---|
| Spark brute-force scan (без индекса) | Часы | Сегодняшний вариант по умолчанию для векторного поиска на основе lake |
| Vector Lakebase — cold (индекс только что построен) | ~30 секунд | Индекс строится из Iceberg примерно за ~20 минут |
| Vector Lakebase — warm (дисковый кеш) | Десятки мс | Индекс кеширован на локальном SSD |
| Vector Lakebase — hot (в памяти) | Единицы мс | Продакшен-обслуживание RAG и агентов |
| Vector Lakebase — clustering / dedup | Часы | KMeans на 1 млрд векторов или поиск почти дубликатов, полностью распределенно |
Вы переходите от часов к единицам миллисекунд — и при этом никогда не копируете данные из lake.
Это не выбор продукта. Это направление, в котором сходится архитектура данных для AI. Любая система, требующая, чтобы данные существовали в двух местах, взимает с вас постоянный налог — на хранение, на инженерные часы, на устаревание данных. Системы, отделяющие хранилище от AI-операций, ретроспективно будут выглядеть переходными.
Что на самом деле позволяет Vector Lakebase
По меньшей мере три класса рабочих нагрузок, для которых раньше требовались отдельные системы, теперь можно обрабатывать с помощью vector lakebase.
Внешние коллекции: сделайте свой lake доступным для поиска, ничего не перемещая
У вас петабайты эмбеддингов в Parquet-файлах на S3. Сделать их доступными для поиска для нового RAG-приложения сегодня означает загрузку в векторную базу данных — миграцию, измеряемую днями или неделями, плюс постоянное обязательство по синхронизации.
Внешние коллекции Vector Lakebase работают с гравитацией данных, а не против нее. Вы указываете bucket, определяете сопоставление схемы поверх существующих столбцов и строите векторный индекс на месте. Данные остаются в S3. Индекс сохраняется обратно в S3. Когда исходные данные обновляются, вы выполняете инкрементальное обновление — повторно обрабатываются только измененные файлы.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Никакой миграции, никакого пайплайна, никаких новых затрат на хранение. Ваша RAG-система запрашивает те же данные, которыми уже управляет ваша команда аналитики — через Spark, Ray, LangChain, PyMilvus или REST API. Индекс становится полноценным свойством таблицы, а не внешней системой, прикрученной рядом.
ETL, разработка признаков и разработка контекста
Это рабочая нагрузка, которую игнорируют и Vector Database, и Vector Lake, — и она становится самой важной частью стека данных для AI.
AI-native операции с данными не просто перемещают данные между системами — они обогащают их семантическим смыслом, на месте и в масштабе:
- Добавьте колонку эмбеддингов в существующую таблицу: выполните batch-инференс по 100M строк и запишите результаты обратно в ту же таблицу.
- Разбейте корпус документов на чанки для RAG, сохраняя сырые документы и чанки вместе с версионированием.
- Перейдите с text-embedding-3-small на более новую модель — выполните backfill всех 500M векторов на месте, при этом старые и новые эмбеддинги будут сосуществовать до момента переключения.
- Создавайте и версионируйте контекстные пакеты, которые ваши AI-агенты извлекают во время выполнения, — что именно извлекается, как это структурировано, как это сжимается под контекстное окно.
По мере коммодитизации моделей качество того, чем вы их кормите, становится важнее того, какую модель вы выбираете. Эта формирующаяся дисциплина — Context Engineering — должна находиться в lake: рядом с данными, версионироваться вместе с ними, быть воспроизводимой end-to-end. Vector Lakebase делает это операцией первого класса, а не набором ad-hoc скриптов, склеенных cron-задачами.
Кластеризация, дедупликация и обнаружение аномалий
Необходимо для каждой команды, обучающей или дообучающей собственные модели, — и полностью отсутствует в парадигме vector database:
- Дедупликация: Почти дублирующиеся примеры в вашем датасете для fine-tuning LLM завышают training loss и смещают поведение модели. Выявляйте near-duplicates, формируйте канонический набор, записывайте метки дедупликации обратно как колонку.
- Кластеризация: Поймите, что на самом деле содержит ваш датасет перед обучением. Кластеризуйте пространство эмбеддингов — вы часто обнаружите, что 40% «разнообразного» датасета составляют незначительные вариации на одни и те же несколько тем.
- Обнаружение аномалий: Для автономных автомобилей, робототехники или любой safety-critical модели — найдите 0,1% образцов, которые совсем не похожи на остальные. Помечайте их, отдавайте в приоритет для разметки и включайте в обучение. Вы не сможете найти их без индекса; вы не сможете действовать по ним без записи результатов обратно в lake.
Vector Lakebase рассматривает эти задачи как распределенные операции первого класса: index-aware, параллелизированные по данным там, где они находятся, с записью результатов в открытых форматах. Результат запуска дедупликации становится колонкой в той же таблице.
Кто уже строит на этом
Самые ранние design partners Vector Lakebase охватывают две из самых сложных задач AI-данных в масштабе.
Ведущие компании в сфере autonomous driving и EV используют его, чтобы находить corner cases среди миллиардов эмбеддингов дорожных сцен — редкие дорожные сценарии, которые определяют, безопасна ли система беспилотного вождения. Ведущая компания в области foundation models использует его для обнаружения near-duplicates в корпусах pre-training — дедуплицируя миллиарды примеров, чтобы улучшить качество модели до того, как будет потрачен хотя бы один GPU-час на обучение.
У нас уже есть Databricks Lakebase. Нужен ли нам еще один?
Это справедливый вопрос, и ответ требует понимания того, чем на самом деле является Databricks Lakebase.
Databricks Lakebase — построенный на их приобретении Neon — интегрирует serverless PostgreSQL engine в платформу Databricks. Проблема, которую он решает: OLTP и OLAP всегда были отдельными системами. Databricks стирает эту границу. Это реальная проблема, которую стоит решать. Но это принципиально другая проблема.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Основной пользователь | Backend engineers, data engineers | ML engineers, AI platform teams |
| Основные данные | Строки, аккаунты, транзакции | Эмбеддинги, документы, multimodal |
| Модель хранения | Postgres storage + Delta Lake (отдельно) | Единая lake table, unified |
| Batch embedding / dedup | Вне scope | Операция первого класса |
| Context Engineering | Вне scope | Ключевая возможность |
| Строится на существующем lake | Частично | Да — zero migration |
| Оптимизация форматов | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, native unstructured data |
| OLTP (транзакции) | ✓ | N/A |
Databricks Lakebase стирает границу OLTP/OLAP. Vector Lakebase стирает границу между тем, где живут ваши AI-данные, и тем, где выполняются ваши AI-операции. Это взаимодополняющие, а не конкурирующие подходы. Многие команды будут использовать оба.
Архитектурная ставка
В 2013 году Databricks задалась вопросом: Что, если SQL-аналитика будет жить в lake? Этот вопрос стоил $40 миллиардов.
Следующий вопрос: Что, если AI-native операции с данными — RAG retrieval, память агентов, пакетное embedding, курирование данных для обучения моделей, context engineering — тоже будут жить в lake?
Именно на это делает ставку Vector Lakebase. Не новая база данных, на которую нужно мигрировать. Не query layer, прикрученный к вашему существующему lake. Единая основа, где ваши данные живут один раз, индексируются один раз и обслуживают любую AI-нагрузку — без дублирования, без накладных расходов ETL, без борьбы с гравитацией.
AI-гонка вознаграждает скорость. Каждая неделя, которую ваша команда тратит на создание sync pipelines, отладку устаревших данных или миграцию между системами, — это неделя, которую ваши конкуренты тратят на выпуск AI-функций. Инфраструктура должна быть ускорителем, а не узким местом. Побеждают не те команды, у которых лучшие модели, — а те, кто устранил трение между своими данными и своим AI.
Стройте на своих существующих таблицах Iceberg или data lake. Без миграции. Без дублирования. Двигайтесь быстро — ваши данные остаются там, где они есть, и становятся доступными для поиска, обработки и готовыми для AI за минуты.
Это Vector Lakebase.
Zilliz Vector Lakebase доступен в public preview
Мы запустили public preview Zilliz Vector Lakebase — важную эволюцию Zilliz Cloud от managed vector database к единой платформе семантических данных, объединяющей low-latency vector serving с открытостью, масштабируемостью и экономикой data lake.
Ключевые возможности Zilliz Vector Lakebase:
- Многоуровневое serving, оптимизированное под разные компромиссы между производительностью в реальном времени и стоимостью
- On-demand search для крупномасштабных или exploratory workloads без always-on compute
- Поиск по внешнему data lake — индексируйте и ищите напрямую по вашим существующим данным в lake
- Full-spectrum search по векторам, тексту, JSON и геопространственным данным с hybrid retrieval и reranking
- Единое lake-native хранилище, построенное на Vortex, открытом формате с более быстрыми и дешевыми random reads, чем Lance или Parquet
Если ваш текущий стек разделяет serving и discovery на отдельные системы, возможно, стоит взглянуть на Vector Lakebase. Попробуйте его в Zilliz Cloud — новые регистрации с рабочей электронной почтой получают $100 бесплатных кредитов — или свяжитесь с нами, чтобы обсудить ваш сценарий.

Читать далее

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.