




Как выбрать лучшую embedding-модель для RAG в 2026 году: сравнительный анализ 10 моделей
TL;DR: Мы протестировали 10 embedding models в четырех производственных сценариях, которые не охватывают публичные бенчмарки: кросс-модальный поиск, кросс-языковой поиск, поиск ключевой информации и сжатие размерности. Ни одна модель не побеждает во всем. Gemini Embedding 2 — лучший универсальный вариант. Open-source Qwen3-VL-2B превосходит закрытые API в кросс-модальных задачах. Если вам нужно сжимать размерности, чтобы экономить хранилище, выбирайте Voyage Multimodal 3.5 или Jina Embeddings v4.
Почему MTEB недостаточно для выбора embedding model
Большинство прототипов RAG начинаются с OpenAI's text-embedding-3-small. Это дешево, легко интегрируется и достаточно хорошо работает для поиска по английским текстам. Но production RAG быстро перерастает его. В ваш pipeline попадают изображения, PDF, многоязычные документы — и одной text-only embedding model становится недостаточно.
Лидерборд MTEB показывает, что есть варианты получше. Проблема? MTEB тестирует только одноязычный текстовый поиск. Он не охватывает кросс-модальный поиск (текстовые запросы по коллекциям изображений), кросс-языковой поиск (китайский запрос, находящий английский документ), точность на длинных документах или то, сколько качества вы теряете, когда усекаете embedding dimensions, чтобы экономить хранилище в вашей vector database.
Итак, какую embedding model вам использовать? Это зависит от типов ваших данных, ваших языков, длины ваших документов и от того, нужно ли вам сжатие размерности. Мы создали бенчмарк под названием CCKM и протестировали 10 моделей, выпущенных между 2025 и 2026 годами, именно по этим параметрам.
Что такое бенчмарк CCKM?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) тестирует четыре возможности, которые пропускают стандартные бенчмарки:
| Измерение | Что тестирует | Почему это важно |
|---|---|---|
| Кросс-модальный поиск | Сопоставление текстовых описаний с правильным изображением при наличии почти идентичных отвлекающих примеров | Pipeline Multimodal RAG должны иметь текстовые и image embeddings в одном векторном пространстве |
| Кросс-языковой поиск | Нахождение правильного английского документа по китайскому запросу и наоборот | Производственные базы знаний часто бывают многоязычными |
| Поиск ключевой информации | Поиск конкретного факта, скрытого в документе длиной 4K–32K символов (иголка в стоге сена) | RAG-системы часто обрабатывают длинные документы, такие как контракты и научные статьи |
| Сжатие размерности MRL | Измерение того, сколько качества теряет модель при усечении embeddings до 256 измерений | Меньше измерений = ниже стоимость хранилища в вашей векторной базе данных, но какой ценой для качества? |
MTEB не охватывает ничего из этого. MMEB добавляет мультимодальность, но пропускает сложные негативные примеры, поэтому модели получают высокие баллы, не доказывая, что они справляются с тонкими различиями. CCKM разработан, чтобы покрыть то, что они упускают.
Какие embedding models мы протестировали? Gemini Embedding 2, Jina Embeddings v4 и другие
Мы протестировали 10 моделей, охватывающих как API-сервисы, так и open-source варианты, плюс CLIP ViT-L-14 в качестве базового уровня 2021 года.
| Модель | Источник | Параметры | Размерности | Модальность | Ключевая особенность |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Не раскрыто | 3072 | Текст / изображение / видео / аудио / PDF | Все модальности, самый широкий охват | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Текст / изображение / PDF | MRL + LoRA-адаптеры |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Не раскрыто | 1024 | Текст / изображение / видео | Сбалансирована по задачам |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Текст / изображение / видео | Открытый исходный код, легковесная мультимодальность |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Текст / изображение | Модернизированная архитектура CLIP |
| Cohere Embed v4 | Cohere | Не раскрыто | Фиксировано | Текст | Корпоративный поиск |
| OpenAI text-embedding-3-large | OpenAI | Не раскрыто | 3072 | Текст | Самая широко используемая |
| BGE-M3 | BAAI | 568M | 1024 | Текст | Открытый исходный код, 100+ языков |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Текст | Легковесная, ориентирована на английский |
| nomic-embed-text | Nomic AI | 137M | 768 | Текст | Ультралегковесная |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Текст / изображение | Базовая модель |
Кросс-модальный поиск: какие модели справляются с поиском изображений по тексту?
Если ваш RAG-пайплайн обрабатывает изображения наряду с текстом, embedding-модель должна размещать обе модальности в одном и том же векторном пространстве. Представьте поиск изображений в e-commerce, смешанные базы знаний из изображений и текста или любую систему, где текстовый запрос должен находить нужное изображение.
Метод
Мы взяли 200 пар изображение-текст из COCO val2017. Для каждого изображения GPT-4o-mini сгенерировал подробное описание. Затем мы написали по 3 сложных отрицательных примера на изображение — описания, которые отличаются от правильного всего одной-двумя деталями. Модель должна найти правильное соответствие в пуле из 200 изображений и 600 отвлекающих вариантов.
Пример из датасета:
 Винтажные коричневые кожаные чемоданы с туристическими наклейками, включая California и Cuba, расположенные на металлической багажной стойке на фоне голубого неба — используются как тестовое изображение в бенчмарке кросс-модального поиска
Винтажные коричневые кожаные чемоданы с туристическими наклейками, включая California и Cuba, расположенные на металлической багажной стойке на фоне голубого неба — используются как тестовое изображение в бенчмарке кросс-модального поиска
Правильное описание: "На изображении показаны винтажные коричневые кожаные чемоданы с различными туристическими наклейками, включая 'California', 'Cuba' и 'New York', расположенные на металлической багажной стойке на фоне ясного голубого неба."
Сложный отрицательный пример: То же предложение, но "California" заменяется на "Florida", а "голубое небо" — на "пасмурное небо." Модель должна действительно понимать детали изображения, чтобы отличить их.
Оценка:
- Сгенерировать эмбеддинги для всех изображений и всего текста (200 правильных описаний + 600 сложных отрицательных примеров).
- Текст-в-изображение (t2i): Каждое описание ищет ближайшее соответствие среди 200 изображений. Балл начисляется, если верхний результат правильный.
- Изображение-в-текст (i2t): Каждое изображение ищет ближайшее соответствие среди всех 800 текстов. Балл начисляется только если верхний результат — правильное описание, а не сложный отрицательный пример.
- Итоговая оценка: hard_avg_R@1 = (точность t2i + точность i2t) / 2
Результаты
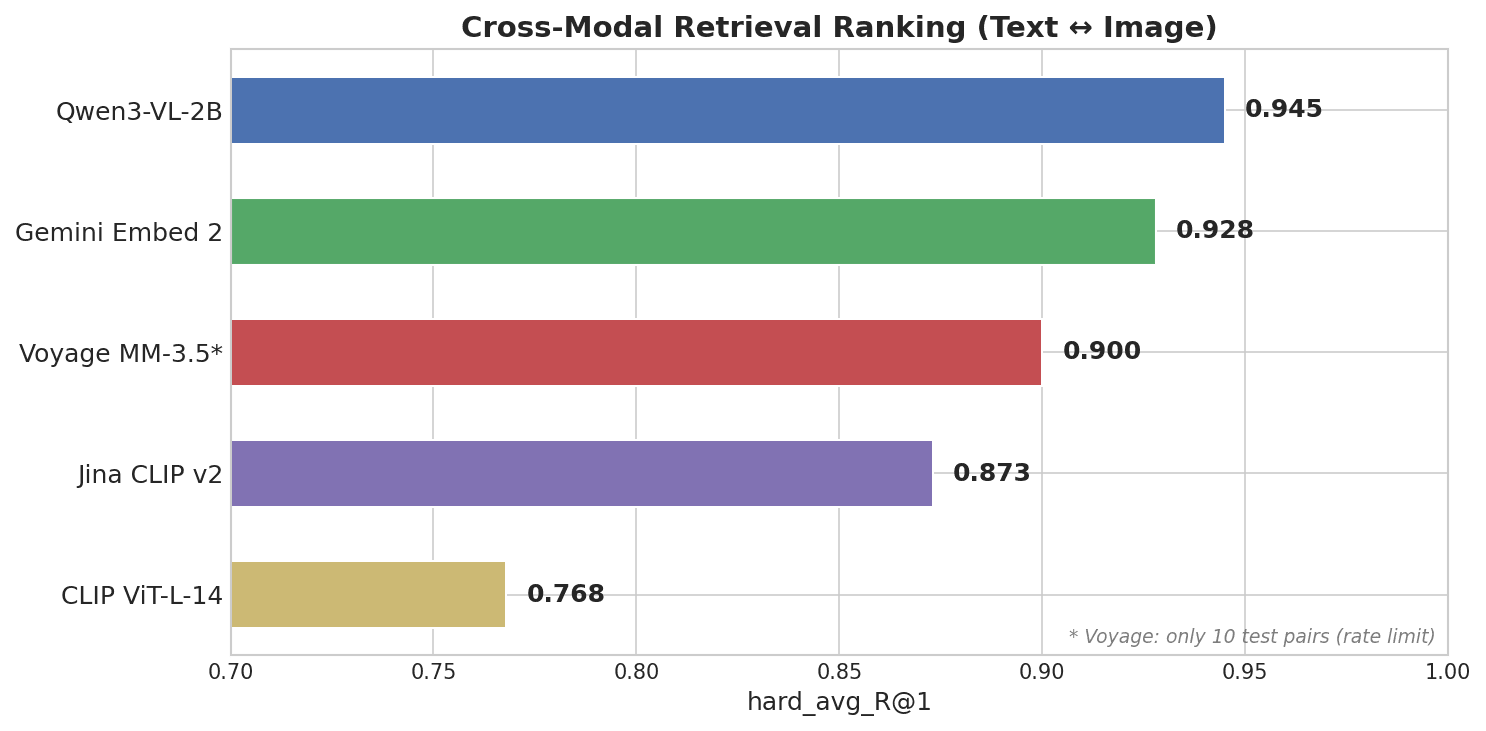 Горизонтальная столбчатая диаграмма, показывающая рейтинг кросс-модального поиска: Qwen3-VL-2B лидирует с 0.945, далее Gemini Embed 2 с 0.928, Voyage MM-3.5 с 0.900, Jina CLIP v2 с 0.873 и CLIP ViT-L-14 с 0.768
Горизонтальная столбчатая диаграмма, показывающая рейтинг кросс-модального поиска: Qwen3-VL-2B лидирует с 0.945, далее Gemini Embed 2 с 0.928, Voyage MM-3.5 с 0.900, Jina CLIP v2 с 0.873 и CLIP ViT-L-14 с 0.768
Qwen3-VL-2B, модель с открытым исходным кодом на 2B параметров от команды Qwen компании Alibaba, заняла первое место — опередив все закрытые API.
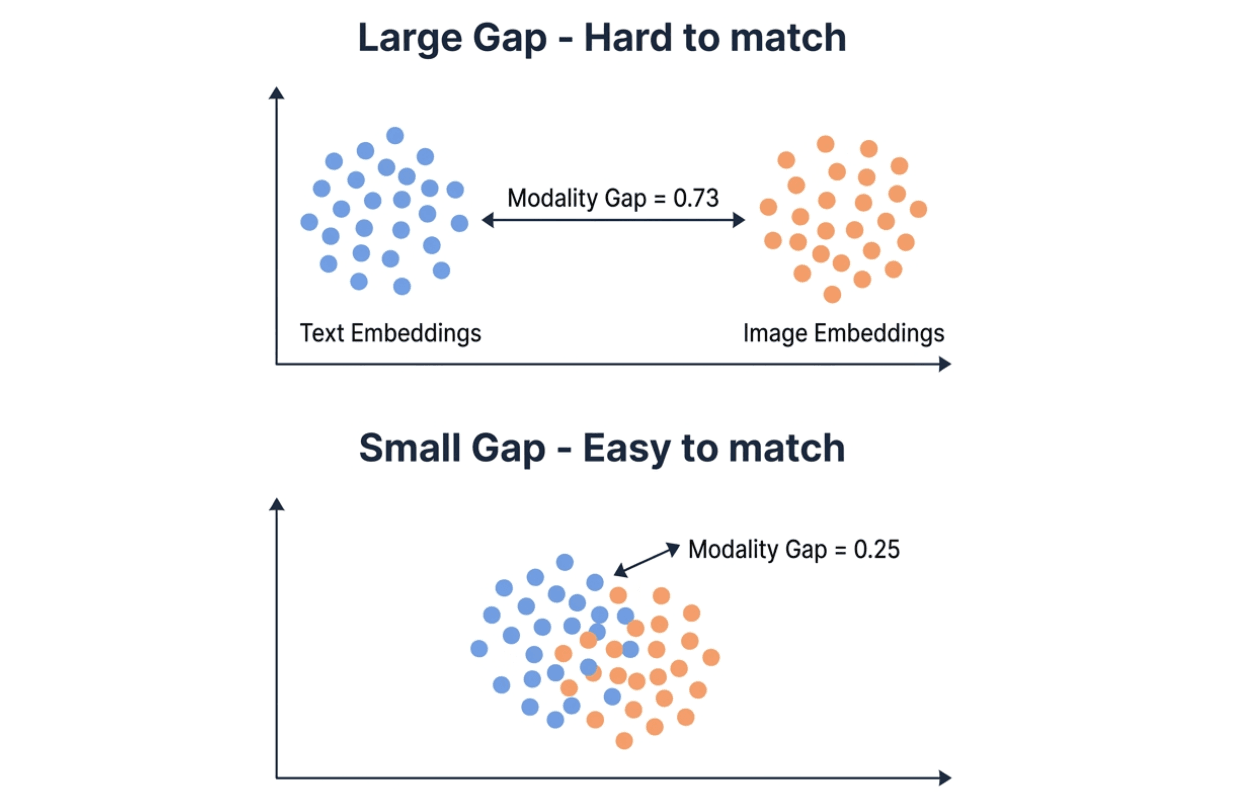
Разрыв модальностей объясняет большую часть разницы. Embedding-модели отображают текст и изображения в одно и то же векторное пространство, но на практике две модальности обычно группируются в разных областях. Разрыв модальностей измеряет L2-расстояние между этими двумя кластерами. Меньший разрыв = более простой кросс-модальный поиск.
 Визуализация, сравнивающая большой модальный разрыв (0.73, кластеры текстовых и изображенческих эмбеддингов находятся далеко друг от друга) и малый модальный разрыв (0.25, кластеры перекрываются) — меньший разрыв упрощает кросс-модальное сопоставление
Визуализация, сравнивающая большой модальный разрыв (0.73, кластеры текстовых и изображенческих эмбеддингов находятся далеко друг от друга) и малый модальный разрыв (0.25, кластеры перекрываются) — меньший разрыв упрощает кросс-модальное сопоставление
| Модель | Оценка (R@1) | Модальный разрыв | Параметры |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Unknown (closed) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Unknown (closed) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Модальный разрыв Qwen составляет 0.25 — примерно треть от 0.73 у Gemini. В векторной базе данных, такой как Milvus, малый модальный разрыв означает, что вы можете хранить текстовые и изображенческие эмбеддинги в одной коллекции и напрямую выполнять поиск по обоим типам. Большой разрыв может сделать кросс-модальный поиск по сходству менее надежным, и для компенсации может потребоваться этап повторного ранжирования.
Кросс-языковой поиск: какие модели сопоставляют смысл между языками?
Многоязычные базы знаний часто встречаются в продакшене. Пользователь задает вопрос на китайском, но ответ находится в документе на английском — или наоборот. Модель эмбеддингов должна сопоставлять смысл между языками, а не только внутри одного языка.
Метод
Мы создали 166 параллельных пар предложений на китайском и английском на трех уровнях сложности:
 Уровни сложности кросс-языкового поиска: легкий уровень сопоставляет буквальные переводы вроде 我爱你 с I love you; средний уровень сопоставляет перефразированные предложения вроде 这道菜太咸了 с This dish is too salty с трудными негативными примерами; сложный уровень сопоставляет китайские идиомы вроде 画蛇添足 с gilding the lily с семантически отличающимися трудными негативными примерами
Уровни сложности кросс-языкового поиска: легкий уровень сопоставляет буквальные переводы вроде 我爱你 с I love you; средний уровень сопоставляет перефразированные предложения вроде 这道菜太咸了 с This dish is too salty с трудными негативными примерами; сложный уровень сопоставляет китайские идиомы вроде 画蛇添足 с gilding the lily с семантически отличающимися трудными негативными примерами
Для каждого языка также есть 152 трудных негативных отвлекающих примера.
Подсчет оценки:
- Сгенерировать эмбеддинги для всех китайских текстов (166 правильных + 152 отвлекающих) и всех английских текстов (166 правильных + 152 отвлекающих).
- Китайский → английский: Каждое китайское предложение ищет свой правильный перевод среди 318 английских текстов.
- Английский → китайский: То же самое в обратном направлении.
- Итоговая оценка: hard_avg_R@1 = (точность zh→en + точность en→zh) / 2
Результаты
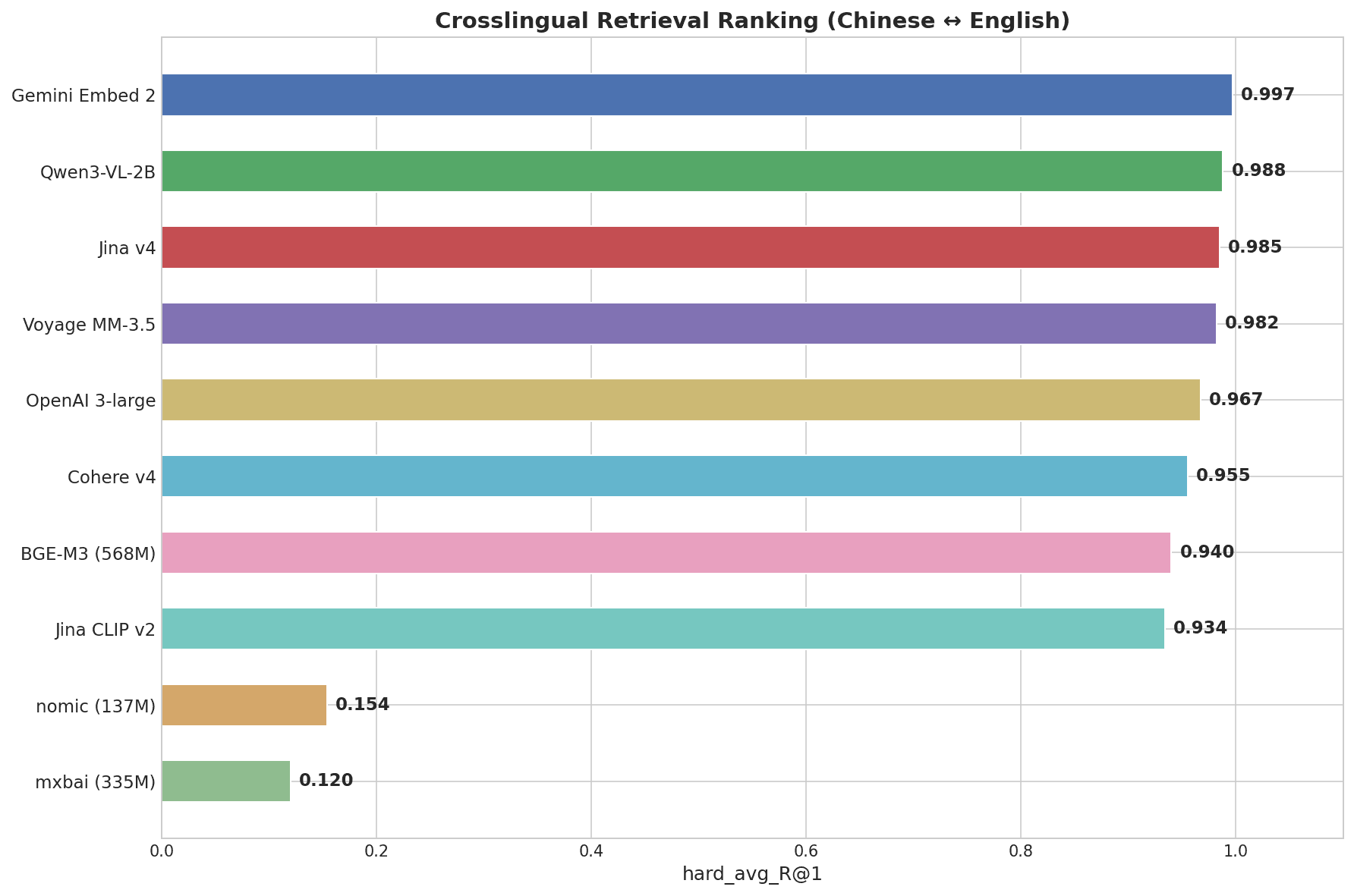 Горизонтальная столбчатая диаграмма, показывающая рейтинг кросс-языкового поиска: лидирует Gemini Embed 2 с 0.997, за ним Qwen3-VL-2B с 0.988, Jina v4 с 0.985, Voyage MM-3.5 с 0.982, вплоть до mxbai с 0.120
Горизонтальная столбчатая диаграмма, показывающая рейтинг кросс-языкового поиска: лидирует Gemini Embed 2 с 0.997, за ним Qwen3-VL-2B с 0.988, Jina v4 с 0.985, Voyage MM-3.5 с 0.982, вплоть до mxbai с 0.120
Gemini Embedding 2 набрала 0.997 — самый высокий результат среди всех протестированных моделей. Это была единственная модель, получившая идеальные 1.000 на сложном уровне, где пары вроде "画蛇添足" → "gilding the lily" требуют настоящего семантического понимания между языками, а не сопоставления шаблонов.
| Модель | Оценка (R@1) | Легкий | Средний | Сложный (идиомы) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
Все 7 лучших моделей преодолевают 0.93 по общей оценке — реальное различие проявляется на сложном уровне (китайские идиомы). nomic-embed-text и mxbai-embed-large, обе легковесные модели, ориентированные на английский, показывают почти нулевой результат в кросс-языковых задачах.
Поиск ключевой информации: могут ли модели найти иголку в документе на 32K токенов?
RAG-системы часто обрабатывают длинные документы — юридические договоры, научные статьи, внутренние отчеты, содержащие неструктурированные данные. Вопрос в том, может ли модель эмбеддингов по-прежнему находить один конкретный факт, скрытый среди тысяч символов окружающего текста.
Метод
Мы взяли статьи Wikipedia разной длины (от 4K до 32K символов) в качестве стога сена и вставили один вымышленный факт — иголку — в разные позиции: начало, 25%, 50%, 75% и конец. Модель должна определить, на основе эмбеддинга запроса, какая версия документа содержит иголку.
Пример:
- Иголка: "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- Запрос: "What was Meridian Corporation's quarterly revenue?"
- Стог сена: статья Wikipedia о фотосинтезе длиной 32 000 символов, внутри которой где-то спрятана иголка.
Оценивание:
- Сгенерировать эмбеддинги для запроса, документа с иголкой и документа без нее.
- Если запрос более похож на документ, содержащий иголку, засчитать это как попадание.
- Усреднить точность по всем длинам документов и позициям иголки.
- Итоговые метрики: overall_accuracy и degradation_rate (насколько падает точность от самого короткого до самого длинного документа).
Результаты
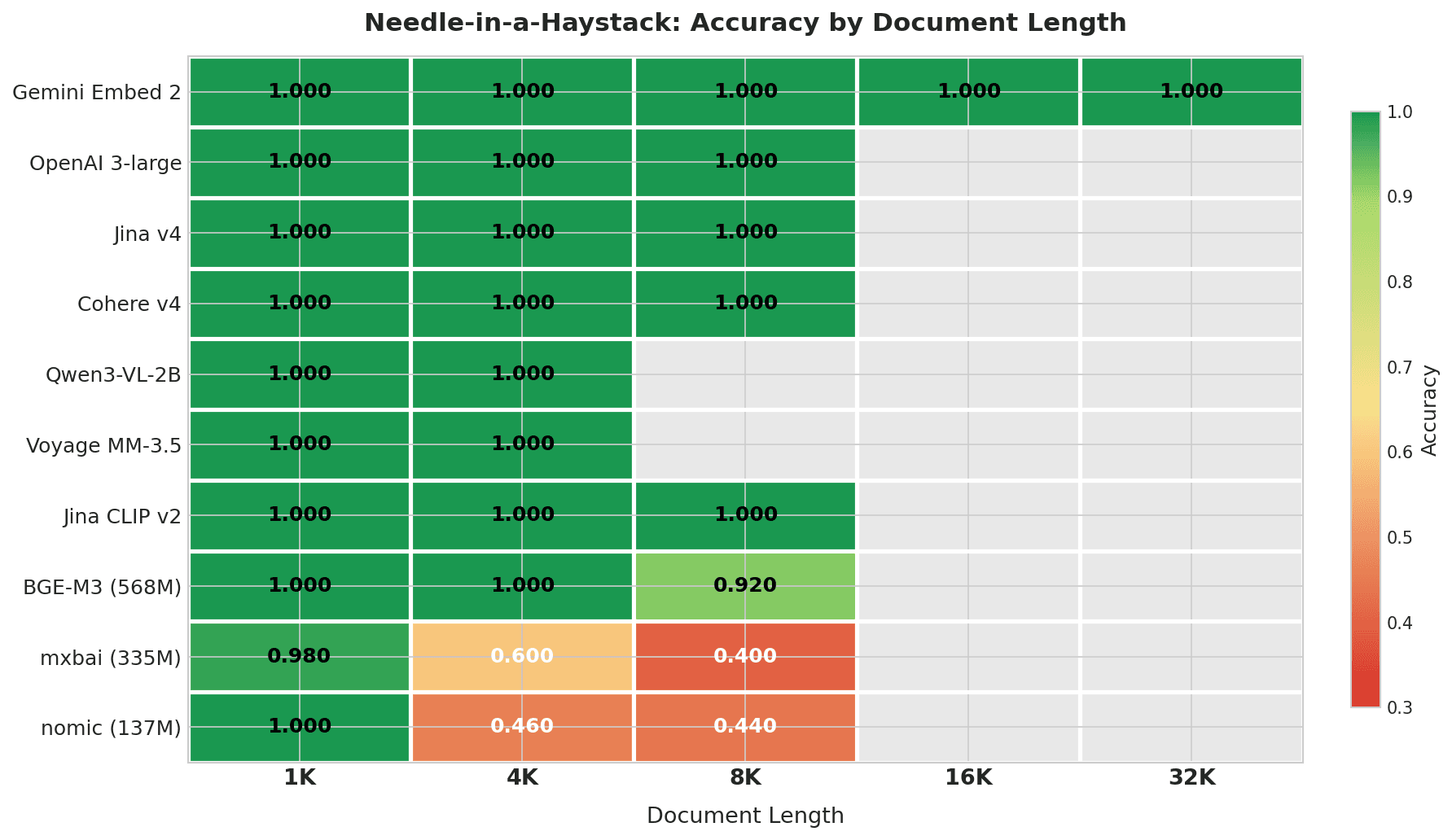 Тепловая карта, показывающая точность Needle-in-a-Haystack по длине документа: Gemini Embed 2 набирает 1.000 на всех длинах до 32K; топ-7 моделей дают идеальный результат в пределах своих контекстных окон; mxbai и nomic резко деградируют на 4K+
Тепловая карта, показывающая точность Needle-in-a-Haystack по длине документа: Gemini Embed 2 набирает 1.000 на всех длинах до 32K; топ-7 моделей дают идеальный результат в пределах своих контекстных окон; mxbai и nomic резко деградируют на 4K+
Gemini Embedding 2 — единственная модель, протестированная на полном диапазоне 4K–32K, и она показала идеальный результат на каждой длине. Ни одна другая модель в этом тесте не имеет контекстного окна, достигающего 32K.
| Модель | 1K | 4K | 8K | 16K | 32K | В целом | Деградация |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" означает, что длина документа превышает контекстное окно модели.
Топ-7 моделей показывают идеальные результаты в пределах своих контекстных окон. BGE-M3 начинает проседать на 8K (0.920). Легковесные модели (mxbai и nomic) падают до 0.4–0.6 уже на 4K символов — примерно 1 000 токенов. Для mxbai это падение частично связано с тем, что ее контекстное окно в 512 токенов обрезает большую часть документа.
Сжатие размерности MRL: сколько качества вы теряете на 256 измерениях?
Matryoshka Representation Learning (MRL) — это техника обучения, которая делает первые N измерений вектора значимыми сами по себе. Возьмите вектор размерности 3072, усеките его до 256, и он все равно сохранит большую часть своего семантического качества. Меньшее число измерений означает более низкие затраты на хранение и память в вашей векторной базе данных — переход с 3072 до 256 измерений дает 12-кратное сокращение объема хранения.
 Иллюстрация, показывающая усечение размерности MRL: 3072 измерения при полном качестве, 1024 при 95%, 512 при 90%, 256 при 85% — с 12-кратной экономией хранения при 256 измерениях
Иллюстрация, показывающая усечение размерности MRL: 3072 измерения при полном качестве, 1024 при 95%, 512 при 90%, 256 при 85% — с 12-кратной экономией хранения при 256 измерениях
Метод
Мы использовали 150 пар предложений из бенчмарка STS-B, каждая с оценкой сходства, размеченной человеком (0–5). Для каждой модели мы сгенерировали эмбеддинги в полной размерности, затем усекли их до 1024, 512 и 256.
 Примеры данных STS-B, показывающие пары предложений с человеческими оценками сходства: A girl is styling her hair vs A girl is brushing her hair — оценка 2,5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach — оценка 3,6
Примеры данных STS-B, показывающие пары предложений с человеческими оценками сходства: A girl is styling her hair vs A girl is brushing her hair — оценка 2,5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach — оценка 3,6
Оценивание:
- На каждом уровне размерности вычисляется косинусное сходство между эмбеддингами каждой пары предложений.
- Ранжирование сходства модели сравнивается с человеческим ранжированием с помощью ρ Спирмена (ранговой корреляции).
Что такое ρ Спирмена? Она измеряет, насколько хорошо согласуются два ранжирования. Если люди оценивают пару A как наиболее похожую, B — второй, C — наименее похожей, а косинусные сходства модели дают тот же порядок A > B > C, то ρ приближается к 1,0. ρ, равная 1,0, означает полное совпадение. ρ, равная 0, означает отсутствие корреляции.
Итоговые метрики: spearman_rho (чем выше, тем лучше) и min_viable_dim (минимальная размерность, при которой качество остается в пределах 5% от производительности при полной размерности).
Результаты
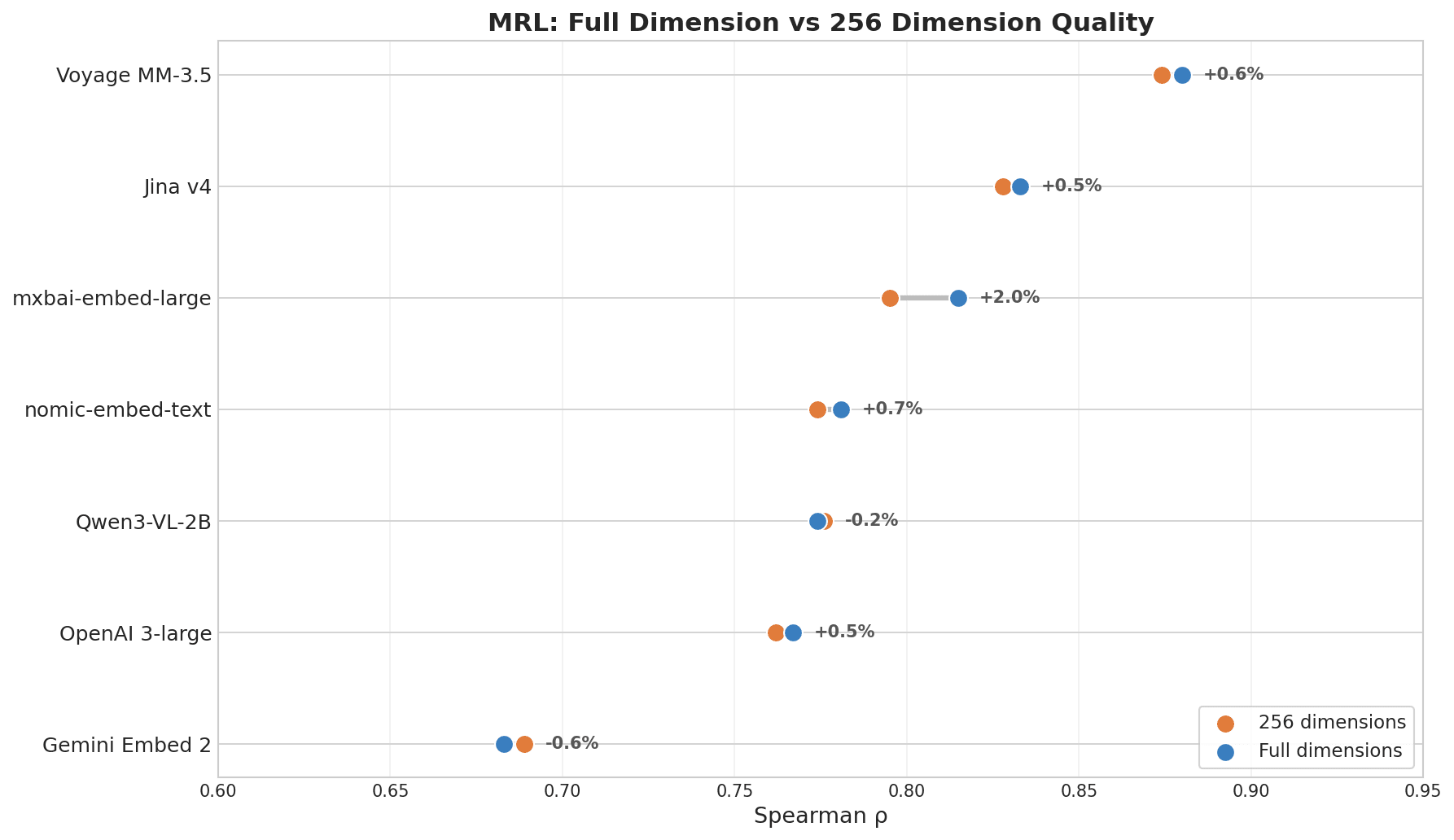 Точечный график, показывающий качество MRL при полной размерности и размерности 256: лидирует Voyage MM-3.5 с изменением +0,6%, Jina v4 +0,5%, тогда как Gemini Embed 2 находится внизу с -0,6%
Точечный график, показывающий качество MRL при полной размерности и размерности 256: лидирует Voyage MM-3.5 с изменением +0,6%, Jina v4 +0,5%, тогда как Gemini Embed 2 находится внизу с -0,6%
Если вы планируете снижать затраты на хранение в Milvus или другой векторной базе данных путем усечения размерностей, этот результат важен.
| Модель | ρ (полная размерность) | ρ (256 размерностей) | Снижение |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage и Jina v4 лидируют, потому что обе модели были явно обучены с MRL в качестве цели. Сжатие размерности мало связано с размером модели — важно то, была ли модель для этого обучена.
Примечание по оценке Gemini: ранжирование MRL отражает, насколько хорошо модель сохраняет качество после усечения, а не насколько хорош ее поиск при полной размерности. Поиск Gemini при полной размерности силен — результаты по кросс-языковым запросам и ключевой информации уже это доказали. Просто она не была оптимизирована для уменьшения размерности. Если вам не нужно сжатие размерности, эта метрика к вам не относится.
Какую модель эмбеддингов следует использовать?
Нет одной модели, которая побеждает во всем. Вот полная сводная таблица:
| Модель | Параметры | Кросс-модальность | Кросс-языковость | Ключевая информация | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Не раскрыто | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Не раскрыто | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Не раскрыто | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Не раскрыто | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" означает, что модель не поддерживает эту модальность или возможность. CLIP — это базовая модель 2021 года для сравнения.
Вот что выделяется:
- Кросс-модальный: Qwen3-VL-2B (0.945) первый, Gemini (0.928) второй, Voyage (0.900) третий. Open-source модель с 2B параметров обошла все closed-source API. Решающим фактором стал модальный разрыв, а не количество параметров.
- Кросс-языковой: Gemini (0.997) лидирует — единственная модель, набравшая идеальный результат на выравнивании на уровне идиом. Топ-8 моделей все преодолевают 0.93. Легковесные модели только для английского набирают около нуля.
- Ключевая информация: API и крупные open-source модели набирают идеальные результаты до 8K. Модели ниже 335M начинают деградировать на 4K. Gemini — единственная модель, которая справляется с 32K с идеальным результатом.
- MRL-сжатие размерности: Voyage (0.880) и Jina v4 (0.833) лидируют, теряя менее 1% при 256 размерностях. Gemini (0.668) на последнем месте — сильна в полной размерности, но не оптимизирована для усечения.
Как выбрать: блок-схема принятия решения
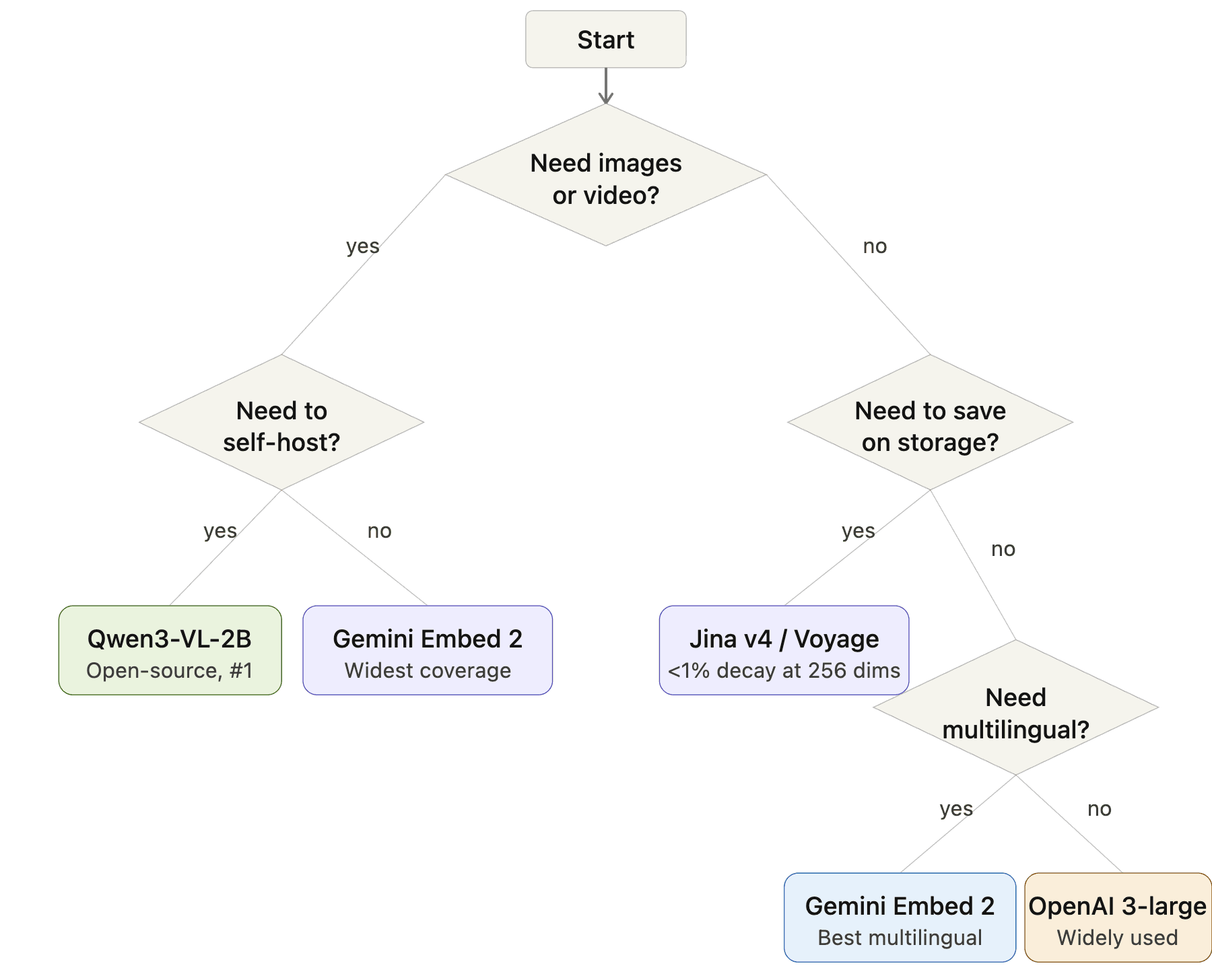 Блок-схема выбора embedding-модели: Старт → Нужны изображения или видео? → Да: Нужно self-host? → Да: Qwen3-VL-2B, Нет: Gemini Embedding 2. Нет изображений → Нужно сэкономить хранилище? → Да: Jina v4 или Voyage, Нет: Нужна мультиязычность? → Да: Gemini Embedding 2, Нет: OpenAI 3-large
Блок-схема выбора embedding-модели: Старт → Нужны изображения или видео? → Да: Нужно self-host? → Да: Qwen3-VL-2B, Нет: Gemini Embedding 2. Нет изображений → Нужно сэкономить хранилище? → Да: Jina v4 или Voyage, Нет: Нужна мультиязычность? → Да: Gemini Embedding 2, Нет: OpenAI 3-large
Лучший универсальный вариант: Gemini Embedding 2
В целом Gemini Embedding 2 — сильнейшая модель в этом бенчмарке.
Сильные стороны: Первое место в кросс-языковом направлении (0.997) и извлечении ключевой информации (1.000 на всех длинах до 32K). Второе место в кросс-модальном направлении (0.928). Самый широкий охват модальностей — пять модальностей (текст, изображение, видео, аудио, PDF), тогда как большинство моделей ограничиваются тремя.
Слабые стороны: Последнее место в MRL-сжатии (ρ = 0.668). Уступает в кросс-модальном направлении open-source модели Qwen3-VL-2B.
Если вам не нужно сжатие размерности, у Gemini нет реального конкурента по сочетанию кросс-языкового поиска + поиска по длинным документам. Но для кросс-модальной точности или оптимизации хранилища специализированные модели справляются лучше.
Ограничения
- Мы не включили все модели, заслуживающие рассмотрения — NVIDIA's NV-Embed-v2 и Jina's v5-text были в списке, но не попали в этот раунд.
- Мы сосредоточились на модальностях текста и изображения; embedding для видео, аудио и PDF (несмотря на заявления некоторых моделей о поддержке) не рассматривался.
- Поиск по коду и другие доменно-специфичные сценарии были вне рамок.
- Размеры выборок были относительно небольшими, поэтому небольшие различия в ранжировании между моделями могут находиться в пределах статистического шума.
Результаты этой статьи устареют в течение года. Новые модели выходят постоянно, и лидерборд меняется с каждым релизом. Более долговечная инвестиция — построить собственный evaluation pipeline: определить ваши типы данных, паттерны запросов, длины документов и прогонять новые модели через собственные тесты, когда они выходят. Публичные бенчмарки вроде MTEB, MMTEB и MMEB стоит отслеживать, но окончательное решение всегда должно приниматься на основе ваших собственных данных.
Наш код бенчмарка открыт на GitHub — форкните его и адаптируйте под свой use case.
После выбора embedding-модели вам нужно место, где можно хранить эти векторы и искать по ним в масштабе. Milvus — самая широко используемая open-source векторная база данных в мире с 43K+ звёзд на GitHub, созданная именно для этого: она поддерживает MRL-усечённые размерности, смешанные мультимодальные коллекции, гибридный поиск, объединяющий dense и sparse векторы, и масштабируется от ноутбука до миллиардов векторов.
- Начните с краткого руководства Milvus или установите с помощью
pip install pymilvus. - Присоединяйтесь к Milvus Slack или Milvus Discord, чтобы задавать вопросы об интеграции моделей эмбеддингов, стратегиях векторной индексации или масштабировании в production.
- Забронируйте бесплатную сессию Milvus Office Hours, чтобы разобрать вашу RAG-архитектуру — мы поможем с выбором модели, проектированием схемы коллекции и настройкой производительности.
- Если вы предпочитаете пропустить работу с инфраструктурой, Zilliz Cloud (управляемый Milvus) предлагает бесплатный тариф для старта.
Несколько вопросов, которые возникают у инженеров при выборе модели эмбеддингов для production RAG:
В: Стоит ли использовать мультимодальную модель эмбеддингов, даже если сейчас у меня есть только текстовые данные?
Это зависит от вашей дорожной карты. Если в ваш пайплайн, вероятно, будут добавлены изображения, PDF-файлы или другие модальности в течение следующих 6–12 месяцев, старт с мультимодальной моделью вроде Gemini Embedding 2 или Voyage Multimodal 3.5 позволит избежать болезненной миграции позже — вам не придется заново создавать эмбеддинги для всего набора данных. Если вы уверены, что в обозримом будущем это будет только текст, текстоориентированная модель вроде OpenAI 3-large или Cohere Embed v4 даст вам лучшее соотношение цены и производительности.
В: Сколько хранилища на самом деле экономит сжатие размерности MRL в векторной базе данных?
Переход с 3072 измерений на 256 измерений дает 12-кратное сокращение объема хранилища на вектор. Для коллекции Milvus со 100 миллионами векторов в float32 это примерно 1,14 ТБ → 95 ГБ. Ключевой момент в том, что не все модели хорошо справляются с усечением — Voyage Multimodal 3.5 и Jina Embeddings v4 теряют менее 1% качества при 256 измерениях, тогда как другие заметно деградируют.
В: Действительно ли Qwen3-VL-2B лучше, чем Gemini Embedding 2, для кросс-модального поиска?
В нашем бенчмарке — да: Qwen3-VL-2B набрал 0,945 против 0,928 у Gemini на сложном кросс-модальном извлечении с почти идентичными отвлекающими примерами. Основная причина — гораздо меньший разрыв между модальностями у Qwen (0,25 против 0,73), что означает, что текстовые и графические эмбеддинги группируются ближе друг к другу в векторном пространстве. При этом Gemini охватывает пять модальностей, а Qwen — три, поэтому если вам нужны эмбеддинги аудио или PDF, Gemini — единственный вариант.
В: Могу ли я использовать эти модели эмбеддингов напрямую с Milvus?
Да. Все эти модели выводят стандартные float-векторы, которые можно вставлять в Milvus и искать с помощью косинусного сходства, расстояния L2 или скалярного произведения. PyMilvus работает с любой моделью эмбеддингов — сгенерируйте векторы с помощью SDK модели, затем сохраняйте и ищите их в Milvus. Для MRL-усеченных векторов просто задайте размерность коллекции равной вашей целевой (например, 256) при создании коллекции.

Читать далее

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.