




Как обнаружить и исправить логические ошибки в моделях GenAI
Введение
Большие языковые модели (БЯМ) изменили область ИИ, особенно в разговорном ИИ, генерации текстов и т. д. LLM обучаются на огромных объемах данных с миллиардами параметров, чтобы генерировать текст, как человек. Многие компании с нетерпением ждут разработки чат-ботов на основе LLM для обработки запросов клиентов, получения отзывов, разрешения жалоб и т. д. По мере роста использования и внедрения LLM нам необходимо решить одну важную проблему: Логические ошибки в выводах LLM. Очень важно решить эту проблему и сделать системы ИИ более ответственными и надежными.
Джон Беннион (Jon Bennion), инженер по ИИ с богатым опытом в области прикладного ОД, безопасности ИИ и оценки, недавно рассказал об интересном подходе к борьбе с логическими ошибками на встрече Unstructured Data Meetup, организованной Zilliz. Джон вносит значительный вклад в LangChain, внедряя новые подходы к борьбе с ошибками в выводах.
Смотрите повтор выступления Джона
Во время своего выступления Джон объясняет распространенные подводные камни в рассуждениях о моделях, которые могут привести к логическим заблуждениям. Он также обсуждает стратегии выявления и исправления этих ошибок, подчеркивая важность приведения результатов моделирования в соответствие с логически обоснованными и человеческими рассуждениями.
Что такое логические заблуждения?
 Что такое логические ошибки?.png
Что такое логические ошибки?.png
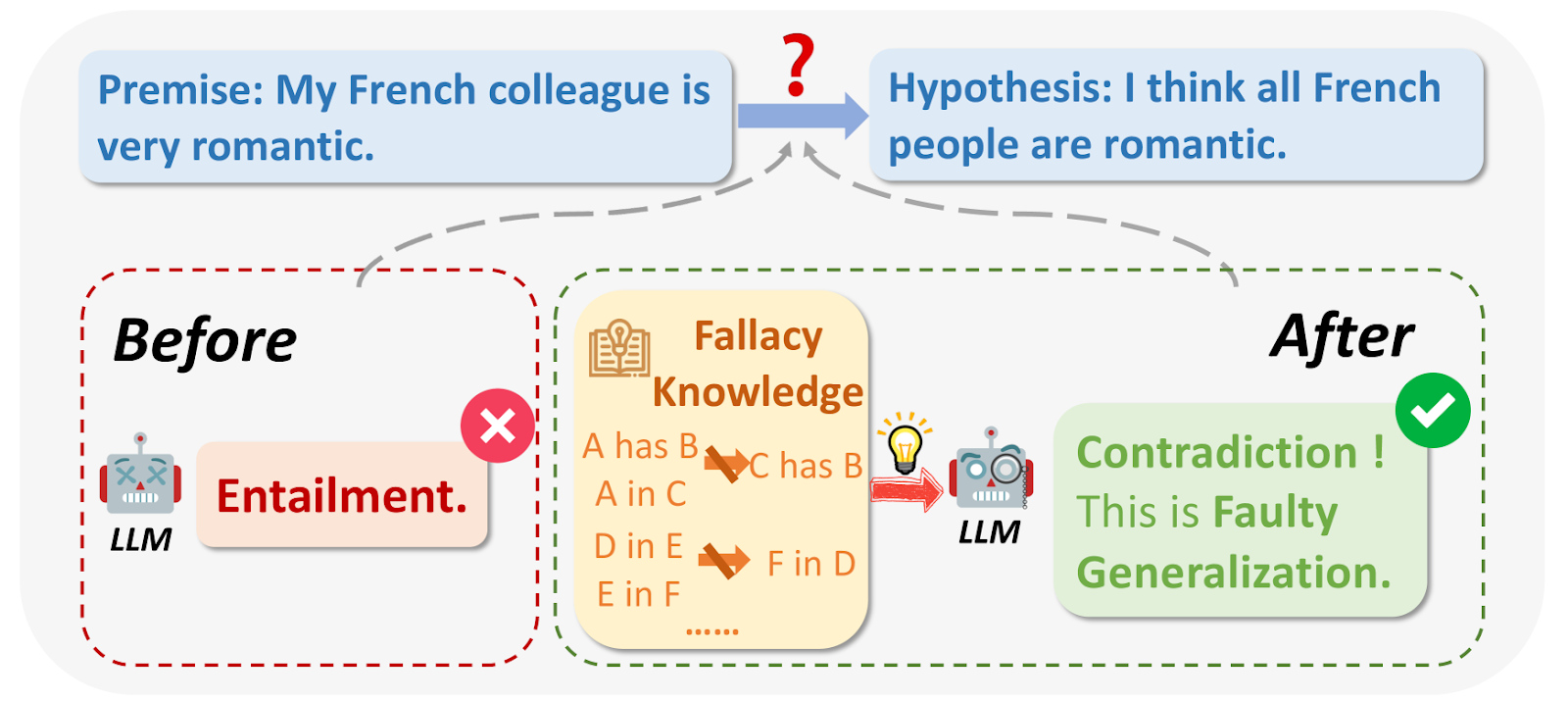
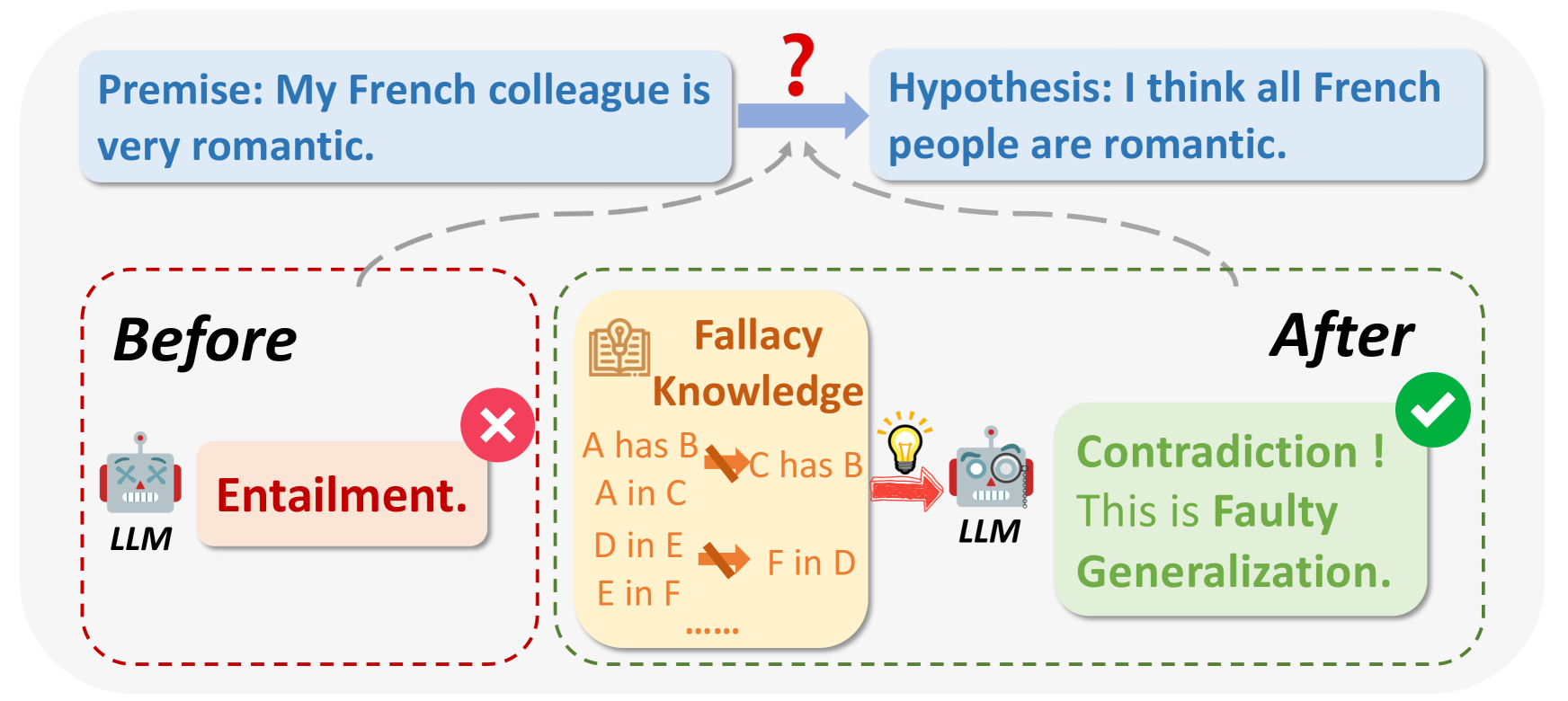
Рис. 1: Что такое логические заблуждения?
Источник изображения:_ https://arxiv.org/html/2404.04293v1/x1.png
При запросе к LLM в некоторых случаях результаты могут быть ошибочными по логическим причинам или не иметь отношения к вопросу. К логическим ошибкам относятся Ad Hominem, круговая аргументация, апелляция к авторитету и т. д. Они часто делают широкие обобщения на основе небольших выборок, например: "Мой друг из Франции груб, поэтому все французы должны быть грубыми".
В некоторых случаях можно предположить, что что-то является истинным или правильным, потому что это популярно.
Пример_: "Все пользуются этим новым приложением, поэтому оно должно быть лучшим". Иногда LLM затрудняются вспомнить детали предыдущего обращения и не могут дать точный ответ.
Почему возникают логические ошибки?
Существует множество причин, по которым логические ошибки могут оказаться на высоте. Как мы все знаем, магистры-практики не обладают идеальной подготовкой, чтобы решать все ситуации так же, как их понимает наш мозг.
Несовершенные данные обучения
Учебные данные, которые мы предоставляем, взяты из различных источников в Интернете и не являются идеальными. Они содержат множество человеческих предубеждений, несоответствий и даже дезинформацию в отдельных случаях. В процессе обучения LLM сталкивается с ошибочными и непоследовательными рассуждениями, и он также учится этому. Если в обучающих данных присутствуют ошибочные аргументы, он улавливает эти закономерности и подражает им в ответах.
Маленькое контекстное окно
В своем выступлении Джон упоминает: "Маленькое контекстное окно может вызвать проблемы в ответах. Многие команды пытаются оптимизировать контекстное окно с учетом требований к памяти и производительности".
Контекстное окно - это количество информации, которое LLM может рассмотреть за один раз, и оно фиксировано. Когда контекстное окно мало, модель может упустить важные детали и не сможет сформировать связный ответ. Это может привести к таким ошибкам, как поспешные обобщения или ложные дихотомии.
Вероятностная природа
LLM генерируют текст, основываясь на том, какое слово в последовательности слов является высоковероятным. Они не могут понять истинное значение слов, как это делают люди. Мы обучаем модели достигать локальной согласованности с контекстом. Иногда это может привести к логическим ошибкам, так как более широкий контекст может быть упущен.
Как бороться с логическими ошибками?
Очень важно обнаружить и предотвратить выдачу LLM ответов с ошибочной логикой, чтобы пользователи могли доверять ему. Джон вкратце рассказывает о распространенных методах решения этой проблемы, таких как обратная связь с человеком, обучение с подкреплением, разработка подсказок и многое другое.
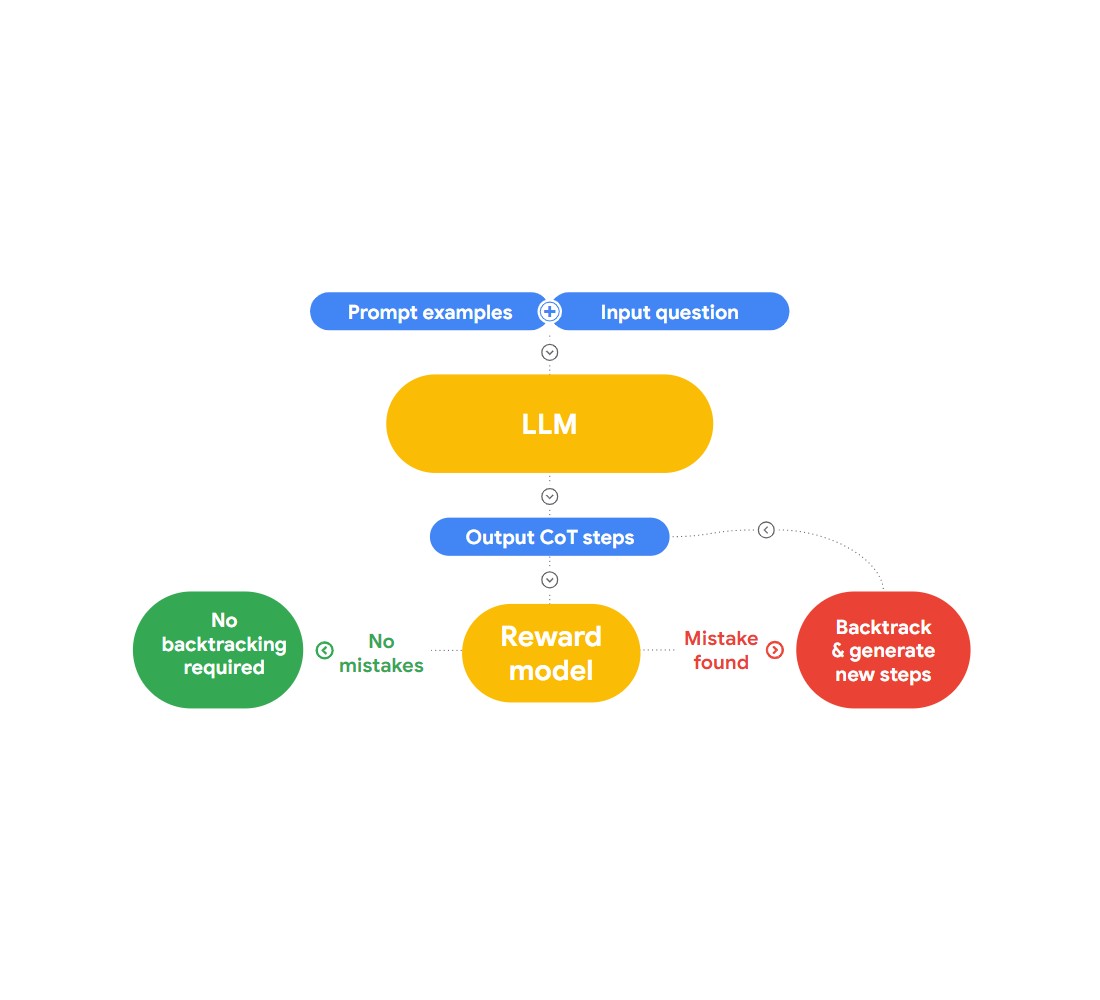
В этом докладе Джон представляет интересный подход к обнаружению и исправлению логических заблуждений - "RLAIF". Идея заключается в том, чтобы использовать ИИ для исправления самого себя.
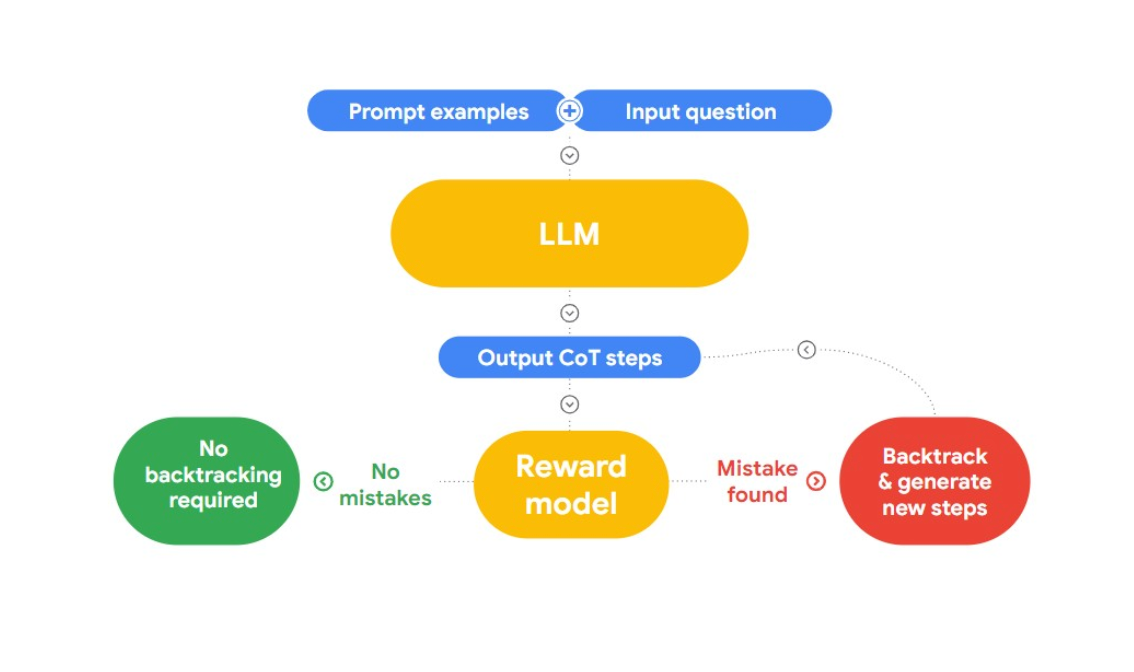
Рис. 2: Как работает RLAIF?
Он ссылается на научную работу "Case-based Reasoning with Language Models for Classification of Logical Policies", которая полезна для нашей проблемы. В работе представлено Case-Based Reasoning (CBR) для классификации логических заблуждений. Он работает в три этапа:
Поиск: Мы предоставляем CBR коллекцию текстовых данных (базу прецедентов), содержащих логические заблуждения и идентифицированных людьми. Когда поступает новый текст, CBR выполняет поиск по базе примеров, чтобы найти похожий случай.
Адаптация: Найденные примеры адаптируются к конкретному контексту нового аргумента, учитывая такие факторы, как цели, объяснения и контраргументы.
Классификация: На основе имеющейся информации CBR выявляет и классифицирует любые логические ошибки.
Джон взял этот подход на вооружение, развил его и реализовал средство обнаружения заблуждений в LangChain.
Предотвращение логических заблуждений с помощью цепочки заблуждений LangChain
Джон демонстрирует пример, предлагая модели предоставить выходные данные с логическими ошибками. В примере ниже показан вывод, который страдает от "Апелляции к авторитету" и является логически ошибочным.
# Пример возвращения вывода модели с логическим заблуждением
misleading_prompt = PromptTemplate(
template="""Вы должны ответить, используя только логические заблуждения, присущие вашим объяснениям ответа.
Вопрос: {question}
Плохой ответ:""",
input_variables=["question"],
)
llm = OpenAI(температура=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="Откуда я знаю, что Земля круглая?")
Вывод:
'Земля круглая, потому что мой профессор сказал, что она круглая, а все верят моему профессору'
Это метод обратного проектирования, при котором мы находим заблуждения, усвоенные моделью, а затем не даем ей их использовать.
Джон объяснил, как мы можем использовать модуль FallacyChain из LangChain для внесения исправлений. Сначала мы инициализируем LangChain с помощью вводящей в заблуждение подсказки, чтобы выделить присущие ей заблуждения.
fallacies = FallacyChain.get_fallacies(["исправление"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="Откуда я знаю, что Земля круглая?")
Далее мы инициализируем цепочку заблуждений, предоставив на вход цепочку заблуждений и модель LLM. Она определит тип присутствующего заблуждения и обновит ответ, удалив его.
> Ввод новой цепочки FallacyChain...
Первоначальный ответ: Земля круглая, потому что мой профессор сказал, что это так, и все верят моему профессору.
Применяем исправление...
Критика ошибочности: В ответе модели используется апелляция к авторитету и ad populum (все верят профессору). Требуется критика фаллатизма.
Обновленный ответ: Вы можете найти доказательства того, что Земля круглая, благодаря эмпирическим данным, таким как фотографии из космоса, наблюдения за кораблями, исчезающими за горизонтом, видение изогнутой тени на Луне или возможность обогнуть земной шар.
> Законченная цепочка.
'Вы можете найти доказательства существования круглой Земли благодаря таким эмпирическим свидетельствам, как фотографии из космоса, наблюдения за исчезающими за горизонтом кораблями, видение изогнутой тени на Луне или способность обогнуть земной шар'.
Джон погружается в работу модуля Fallacy Chain, который он включил в LangChain. Архитектура Fallacy Chain состоит из двух основных компонентов: Цепочка критики и Цепочка ревизии. В обеих цепочках используется оперативная инженерия для обнаружения и изменения ошибочных утверждений в ответе. Кратко о том, как это работает:
Когда мы предоставляем исходные данные, LLM обрабатывает их и генерирует первоначальный ответ.
Следующий шаг - обнаружение заблуждений. Цепочка критики идентифицирует и классифицирует все присутствующие заблуждения на основе выявленных закономерностей. Джон упоминает об использовании списка заблуждений, который был извлечен и использован из исследовательской работы, упомянутой ранее.
Цепочка пересмотра кодируется с помощью техники подсказок для создания пересмотренного ответа, избегающего обнаруженных заблуждений. Это может включать перефразирование, добавление контекста или изменение структуры аргументации.
Демонстрационное приложение
Джон также продемонстрировал приложение для извлечения логических заблуждений из новостных статей. В этой демонстрации он показал, как новые статьи из разных регионов могут иметь политический и авторитетный уклон. Он также продемонстрировал приложение, созданное с использованием Open AI, для извлечения новых статей на заданную тему и определения их главных заблуждений. С помощью этого приложения он искал новые статьи, связанные с "Китаем" в качестве ключевого слова, и результат показан ниже.

В новостных статьях объясняется, как Цепочка логических заблуждений выявила и объяснила проблему "Апелляция к авторитету". Джон рассказывает о том, как подобные инструменты могут очистить наши обучающие данные от логических заблуждений, обеспечивая безупречное обучение модели. FallacyChain может значительно повысить надежность результатов LLM и увеличить доверие пользователей. Кроме того, она обеспечивает прозрачность, объясняя изменения и их причины, помогая пользователям понять, как была достигнута логическая связность.
Для получения дополнительной информации об этой демонстрации [смотрите повтор выступления Джона на встрече] (https://www.youtube.com/watch?v=yqaG2XSv89I&t=75s).
Заключение
FallacyChain в LangChain - это мощный подход к повышению логической целостности текста, сгенерированного LLM. Он может повысить доверие пользователей и упростить внедрение LLM в соответствии с нормативными требованиями. Хотя преимущества этого подхода очевидны, необходимо оценить затраты на его масштабное внедрение. Это захватывающее пространство, и проводятся новые эксперименты по его улучшению с помощью методов машинного обучения для классификации заблуждений и т. д.

{kind=link}
{kind=link}
Читать далее

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.