




Как Zilliz оказалась в центре истории NVIDIA о неструктурированных данных на GTC 2026
На NVIDIA GTC в этом году, среди привычной лавины заявлений о чипах, системах и инфраструктуре, Дженсен Хуанг показал слайд, который был важен по другой причине.
Он был не о следующем GPU. Не о размере модели. И даже, по сути, не об инференсе.
Он был о данных.
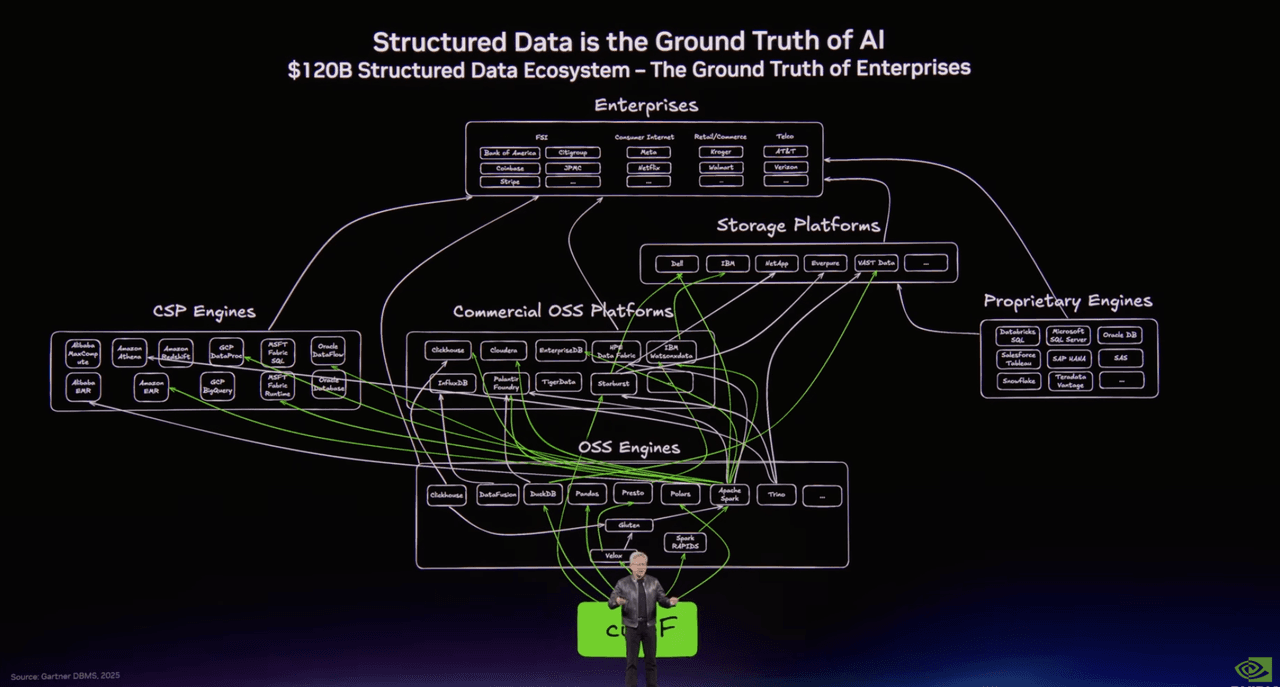
Один слайд отображал мир структурированных данных: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery — знакомый механизм, который десятилетиями обеспечивал аналитику и инженерию данных.
Другой отображал формирующийся стек для неструктурированных данных. И там, в центре этой второй картины, находились Milvus в open source и Zilliz Cloud на уровне корпоративной базы данных.

Заголовок на слайде говорил всё: Неструктурированные данные — это контекст AI.
С этой фразой легко согласиться. Конечно, AI нужен контекст. Конечно, большая часть корпоративных данных неструктурирована. Конечно, текст, изображения, видео, аудио, логи, PDF и всё остальное сейчас важны как никогда. Но если выйти за пределы лозунга, возникает более сложный вопрос: если неструктурированные данные становятся реальной основой AI-систем, как на самом деле выглядит инфраструктура для этого мира?
Это более интересная история. И именно поэтому Milvus прошёл путь от специализированной векторной базы данных до гораздо более стратегической позиции в AI-стеке.
Почему Zilliz (Milvus) продолжает появляться
Это был не первый раз, когда Zilliz появился на GTC, и, вероятно, не последний.
Задолго до того, как векторные базы данных стали стандартным строительным блоком современных AI-систем, Milvus был создан вокруг идеи, что поиск по сходству должен будет работать в совершенно ином масштабе, чем традиционные базы данных. GPU-ускорение не было запоздалой мыслью. Оно было частью логики проектирования с самого начала.
Это стало важным, когда AI перестал быть исследовательской историей и стал историей инфраструктуры.
На GTC 2023 Дженсен Хуанг уже отмечал более глубокую интеграцию между библиотеками ускорения NVIDIA и такими системами, как FAISS, Redis и Milvus. Год спустя, на GTC 2024, эти отношения стали более конкретными с Milvus 2.4, который принёс полное GPU-ускорение в векторное индексирование и поиск за счёт сочетания NVIDIA GPU с CAGRA из RAPIDS cuVS. Результатом стало не косметическое ускорение. В некоторых бенчмарк-сценариях производительность поиска улучшилась до 50 раз по сравнению с HNSW.
К моменту выхода Milvus 2.6 разговор снова эволюционировал. Вопрос был уже не в том, важно ли GPU-ускорение. Вопрос был в том, как использовать его экономически эффективно. Milvus 2.6 представил более гибкие шаблоны развёртывания для CAGRA, включая гибридные GPU-CPU-архитектуры, которые используют GPU для построения графа и CPU для retrieval. Это важно, потому что большинству предприятий не нужна максимально быстрая система любой ценой. Им нужна система, которая остаётся достаточно быстрой и при этом экономически разумной.
На этой детали стоит остановиться, потому что она говорит о более масштабной причине, почему Milvus стал важен. Это не просто история о производительности векторного поиска. Это история о том, что происходит, когда vector retrieval перестаёт быть экспериментальной функцией и становится частью производственной инфраструктуры.
Что нужно, чтобы векторный поиск работал в production
Одна лишь скорость перестаёт быть главным сюжетом.
Но как только векторный поиск выходит за пределы демо и попадает в реальные системы, одна лишь скорость перестает быть главным.
Более сложный вопрос заключается в том, что нужно, чтобы сделать поиск практичным на уровне предприятия, не превращая окружающий стек в хаос из хрупких пайплайнов, высокой нагрузки на память и растущих инфраструктурных затрат.
Часть этой проблемы начинается выше по потоку. В старой модели превращение PDF, изображения или документа во что-то доступное для поиска обычно означало сшивание отдельного слоя парсинга, логики разбиения на фрагменты, сервисов embeddings и записей в базу данных. Система поиска начинала работать только после того, как длинная цепочка предварительной обработки уже завершала свою работу. Milvus 2.6 начал стирать эту границу с помощью подхода Data-in, Data-out, позволяя записывать сырой контент напрямую в систему и создавать embeddings внутри самой базы данных.
Часть ее находится внутри слоя поиска. Разные рабочие нагрузки требуют разных компромиссов, поэтому поддерживайте несколько типов индексов, а не навязывайте единую стратегию поиска для каждого сценария использования. Сжатие тоже становится частью уравнения. Такие функции, как Int8 и RaBitQ, не являются броскими дополнениями, но они решают более важную задачу: снижение нагрузки на память и затрат без ущерба для качества поиска.
А часть ее — просто операционная. Milvus представил переработанную архитектуру write-ahead logging, которая устранила необходимость в Kafka и Pulsar из стека, снизив как сложность, так и накладные расходы. Такая инженерная работа редко попадает в заголовки, но именно она определяет, останется ли инфраструктура интересной в теории или станет пригодной на практике.
Хранилище, как выясняется, — еще одна линия разлома.
По мере роста AI-систем растет и цена притворства, будто ко всем данным нужно всегда относиться одинаково. На крупной мультитенантной платформе лишь небольшая часть данных может быть действительно активной в конкретный день. Большая их часть остается холодной. Но традиционные архитектуры с полной загрузкой все равно обращаются со всем так, будто оно заслуживает одинакового локального размещения, одинакового уровня производительности и одинакового ценового следа.
В малом масштабе это выглядит неэффективно. На уровне предприятия это становится трудно оправдать.
Milvus 2.6 решил эту проблему с помощью многоуровневого хранения. Горячие данные остаются локально — там, где важна задержка. Холодные данные загружаются по требованию из более дешевого объектного хранилища. А граница между ними динамически смещается по мере фактического использования системы. Это звучит как скромная системная оптимизация. На практике это меняет экономику поиска. Когда нужные данные находятся на нужном уровне, затраты на хранение могут снизиться более чем на 70 процентов.
Во всем этом нет особого гламура. Но обычно именно так и взрослеет инфраструктура: не через один драматический прорыв, а через серию проектных решений, которые делают систему быстрее, дешевле и удобнее в эксплуатации.
И все эти функции доступны в Zilliz Cloud, полностью управляемом сервисе Milvus.
Настоящая проблема с неструктурированными данными
Однако более крупный сдвиг на самом деле касается не только Milvus. Он касается того типа данных, от которого теперь зависят AI-системы.
Структурированные данные развивались долго и упорядоченно. Строки, столбцы, схемы, индексы, хранилища данных, движки запросов. Инструменты созревали десятилетиями, потому что сами данные соответствовали предположениям, на которых были построены эти системы. Вы знали, как выглядит запись. Вы знали, какие поля запрашивать. Вы знали, как их индексировать.
Неструктурированные данные ломают эту модель.
Контракт — это не строка. Медицинское изображение, стенограмма обращения в поддержку, репозиторий кода или поток видеонаблюдения — тоже нет. Эти объекты можно хранить, но хранение — самая простая часть. Сложная часть — сделать их доступными для поиска таким образом, чтобы он понимал смысл, а не точные совпадения полей.
Именно поэтому embeddings изменили всё. Как только текст, изображения, аудио и другие формы контента стало возможно отображать в высокоразмерное векторное пространство, извлечение больше не должно было зависеть от точного символьного сопоставления. Системы могли извлекать данные по сходству, намерению и контексту.
Это был прорыв.
Но это также стало началом новой инфраструктурной проблемы.
Как только неструктурированные данные становятся доступными для запросов, предприятия сразу сталкиваются с экономикой масштаба. Миллионы документов превращаются в сотни миллионов embeddings. Обновление модели означает повторное создание embeddings для исторического корпуса. Качество извлечения зависит от качества индекса. Задержка важна в продакшене. Стоимость хранения — тоже. Как и операционная нагрузка по поддержанию всего этого в синхронизированном состоянии.
Иными словами, семантическое извлечение решило проблему доступа, но выявило системную проблему.
Именно в этом контексте Milvus имеет смысл.
Почему векторной базы данных было недостаточно
Для первой волны AI-native компаний ответ был очевиден: использовать векторную базу данных как слой извлечения, подключить её к модели и строить приложение дальше. Эта модель работала и продолжает работать, особенно когда семантический поиск является ядром продукта.
Но крупные предприятия, как правило, упираются в другую стену.
Вопрос не в том, могут ли они запустить векторный поиск. Вопрос в том, что происходит после этого.
Сырые файлы находятся в объектном хранилище или data lakes. Embeddings находятся в векторной базе данных. Метаданные находятся в реляционной системе. Офлайн-обработка происходит где-то ещё. Логи поиска накапливаются в другом pipeline. Затем меняется модель embeddings, или меняется логика ранжирования, или базе знаний требуется курирование, или кто-то хочет отследить, почему система извлечения постоянно ошибается на пограничных случаях. Внезапно система перестаёт быть единой системой. Она превращается в лоскутное одеяло.
Это лоскутное одеяло создаёт три знакомые проблемы.
- Первая — это data silos. Данные, необходимые для работы одной AI-функции, распределены по нескольким системам, каждая со своим форматом, жизненным циклом и операционной моделью.
- Вторая — это стоимость итераций. Когда меняется модель embeddings, перезапись по умолчанию не является инкрементальной. Она может превратиться в многомесячную переиндексацию и миграцию.
- Третья — это разорванный цикл между онлайн-обслуживанием и офлайн-улучшением. Система обслуживает запросы в продакшене, но сигналы, которые могли бы сделать её лучше, результаты дедупликации, метки кластеризации, оценки качества и анализы сбоев, часто существуют в отдельных средах и никогда чисто не возвращаются в слой извлечения.
Именно в этот момент покупка векторной базы данных перестаёт казаться ответом и начинает выглядеть как начало более крупного архитектурного вопроса.
Если реальная проблема — это непрерывное улучшение в масштабе, тогда архитектура должна измениться.
От векторной базы данных к AI Lakebase
До бума AI Databricks помогла популяризировать модель Lakehouse, устранив неудобный разрыв между data lakes и data warehouses. Вместо поддержки отдельных систем для хранения, аналитики и крупномасштабной обработки предприятия могли работать на более унифицированной основе.
Эпоха AI заставляет переосмыслить инфраструктуру похожим образом, но уже вокруг неструктурированных данных.
Если внимательно посмотреть на инфраструктурные схемы, которые использует Jensen Huang, центр тяжести смещается. В эпоху структурированных данных такие фреймворки, как Spark, находились в центре pipeline. В эпоху неструктурированных данных векторная инфраструктура, такая как Milvus, начинает выполнять эту роль. Не потому, что векторный поиск — единственное, что имеет значение, а потому, что он всё чаще оказывается на стыке сырых данных, embeddings, индексов и извлечения для приложений.
Это открывает более широкую возможность: что, если векторный поиск не рассматривать как отдельный обслуживающий слой, пристроенный сбоку к стеку? Что, если интегрировать его напрямую с корпоративным озером данных и окружающими рабочими процессами обработки данных?
Архитектура AI Lakebase
Именно эта идея лежит в основе AI Lakebase.
Смысл AI Lakebase не в том, чтобы добавить еще одну продуктовую категорию на и без того переполненный рынок. Смысл в том, чтобы заменить фрагментированный подход более цельным.
- Внизу находится единый слой хранения. Часть этих данных находится в нативных для Zilliz коллекциях, оптимизированных для высокопроизводительного векторного поиска. Часть остается в открытых форматах, которые уже используются предприятием, Iceberg, Lance, Paimon, а также в виде сырых файлов в объектном хранилище. Важно то, что данные не нужно копировать в пять разных систем только для того, чтобы ими можно было пользоваться.
- Поверх него находится производственный обслуживающий слой, созданный для поиска в реальном времени. В Zilliz Cloud это означает обслуживающие кластеры на базе Cardinal, оптимизированные для задержек на уровне миллисекунд, с различными режимами для производительности, емкости и многоуровневого размещения горячих и холодных данных. На практике это означает, что часто используемые данные остаются локально, а холодные данные загружаются по запросу из более дешевого хранилища. Результат — не просто более удачный дизайн системы. Это контроль затрат.
- Затем идет эластичный вычислительный слой: кластеры по запросу для ETL, дедупликации, кластеризации, анализа качества данных, повторного создания эмбеддингов, оценки и интерактивного исследования. Это не побочные системы, приклеенные позже. Они являются частью той же основы.
Все три слоя используют одни и те же данные, а не поддерживают несколько разрозненных копий.
Это звучит как история об архитектурном упорядочивании, и так оно и есть. Но это нечто большее.
Но более важный момент в том, что такая архитектура делает возможным.
AI Lakebase — это больше, чем архитектурное упорядочивание
Большинство AI-систем сегодня умеют обслуживать запросы. Гораздо меньшее число способно систематически улучшаться.
Обычно это происходит не потому, что модель ошибочна. А потому, что инфраструктура вокруг нее делает обратную связь дорогой.
Производственная система постоянно генерирует сигналы. Каждый запрос о чем-то говорит. Каждый неудачный поиск о чем-то говорит. Каждый ответ низкого качества, каждый повторяющийся результат, каждое тупиковое взаимодействие, каждый кластер похожих документов, каждый шумный фрагмент в корпусе — все это информация, которую можно было бы использовать для улучшения системы.
Но в большинстве стеков эти сигналы разбросаны по логам обслуживания, офлайн-пайплайнам, ноутбукам, дашбордам и одноразовым скриптам. Система работает, но на самом деле не учится на собственном опыте.
Подход AI Lakebase к решению этой задачи — Continuous Serving/Continuous Discovery (AI CS/CD).
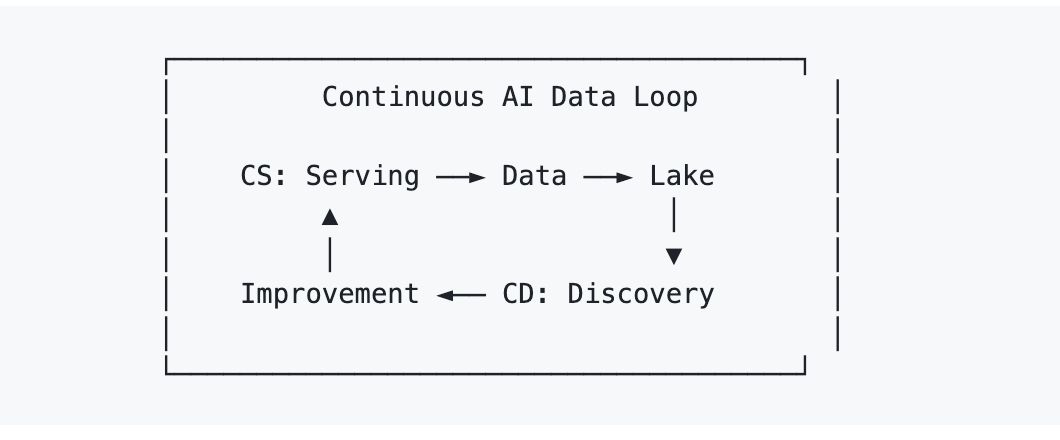
- Continuous Serving — очевидная часть: работающая система обрабатывает поиск и генерацию в продакшене.
- Continuous Discovery — менее очевидная часть: система непрерывно анализирует то, что накопила, пробелы в покрытии, режимы отказов, структуру кластеров, проблемы качества данных, и записывает полученные улучшения обратно в ту же операционную среду.
Это важно, потому что, когда обслуживание и обнаружение используют одну и ту же основу данных, улучшения перестают выглядеть как миграции и начинают выглядеть как итерации. Результаты дедупликации могут возвращаться в живой поиск. Оценки качества могут влиять на ранжирование в продакшене. Метки кластеров могут становиться сигналами поиска. Повторное создание эмбеддингов может выполняться инкрементально с помощью эластичных вычислений, а не как гигантское единовременное мероприятие.
Архитектура начинает вести себя меньше как статическая база данных и больше как живой цикл улучшения.
Это гораздо более существенный сдвиг, чем «векторная база данных, только быстрее».
Быстро масштабируйтесь и быстро итерируйте с AI Lakebase
Многие инфраструктурные компании могут заявлять о масштабе. Многие могут заявлять о скорости. Гораздо меньше тех, кто может правдоподобно заявлять и о масштабе, и о непрерывной итерации в одной и той же системе.
Zilliz утверждает, что следующий этап корпоративной инфраструктуры AI требует и того и другого.
- Scale Fast означает мультирегиональную, мультиоблачную инфраструктуру, способную поддерживать производственные нагрузки в очень большом масштабе, а не только тестовые прогоны или демонстрационные среды.
- Iterate Fast означает, что система спроектирована так, чтобы офлайн-обнаружение и онлайн-обслуживание были частью одного и того же операционного цикла. Улучшение встроено, а не прикручено сверху.
Это различие важно, потому что производственный AI терпит неудачу двумя противоположными способами. Некоторые системы масштабируются, но стагнируют. Они становятся большими, дорогими и всё более сложными для улучшения. Другие быстро итерируют в небольших средах, но так и не становятся устойчивыми производственными системами. Настоящая цель — ни то ни другое. Это система, которая может одновременно расти и обучаться.
Именно в этом заключается обещание перехода от векторной базы данных к AI Lakebase.
Векторная база данных при таком переходе не исчезает. Она по-прежнему важна. Она по-прежнему является обслуживающим движком для извлечения в реальном времени. Но она перестаёт быть конечной точкой архитектуры. Она становится одним слоем в более широкой системе, подобно тому как реляционные базы данных всё ещё существуют в мире Lakehouse, не определяя при этом всю архитектуру самостоятельно.
И, возможно, именно так полезнее всего читать фразу Дженсена Хуанга с GTC.
Если неструктурированные данные — это контекст AI, то потолок AI-приложений будет определяться не только моделями, но и тем, насколько зрелой станет инфраструктура для неструктурированных данных.
Эта инфраструктура всё ещё не завершена. Рынок всё ещё находится на ранней стадии. Но контуры начинают вырисовываться.
И всё чаще Milvus оказывается прямо в центре этого.
Оставайтесь с нами!
AI Lakebase станет архитектурным обновлением, лежащим в основе Milvus 3.0, и важной эволюцией Zilliz Cloud. Если вы хотите заранее увидеть, куда всё движется, свяжитесь с нами для получения раннего доступа.
Читать далее

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.