




Развертывание мультимодальной системы RAG с помощью vLLM и Milvus
Представьте, что вы потратили месяцы на точную настройку своего приложения ИИ для конкретного LLM через поставщика API. И тут, ни с того ни с сего, вы получаете письмо: "Мы отказываемся от используемой вами модели в пользу нашей новой версии". Знакомо? Хотя облачные API-провайдеры предлагают удобство мощных, готовых к использованию возможностей ИИ, полагаясь только на них, вы также сталкиваетесь с рядом существенных рисков:
- Отсутствие контроля: Вы не можете контролировать версии и обновления моделей.
- Непредсказуемость: Вы можете столкнуться с внезапными изменениями в поведении или возможностях модели.
- Ограниченное понимание: Зачастую возможности отслеживания производительности и моделей использования ограничены.
- Приватность: Конфиденциальность данных может быть очень важной проблемой, особенно при работе с конфиденциальной информацией.
Каково же решение? Как вернуть контроль? Как снизить эти риски и одновременно расширить возможности системы? Ответ заключается в создании более надежной, независимой системы с использованием решений с открытым исходным кодом.
Этот блог поможет вам создать Multimodal RAG с помощью Milvus и vLLM. Используя возможности векторной базы данных с открытым исходным кодом в сочетании с LLM, вы сможете создать систему, способную обрабатывать и понимать множество типов данных - текст, изображения, аудио и даже видео. Такой подход не только дает вам полный контроль над технологией, но и обеспечивает мощную и универсальную систему, превосходящую традиционные текстовые решения.
Что мы создадим: мультимодальный RAG под вашим контролем
Мы построим систему Multimodal RAG с использованием Milvus и vLLM, иллюстрирующую, как вы можете self host your LLM и получить полный контроль над своими приложениями ИИ. Наше руководство проведет вас через создание приложения Streamlit, которое продемонстрирует возможности интеграции нескольких типов данных. Вот что мы рассмотрим:
Обработка видеоданных путем извлечения кадров и расшифровки звука
Хранение и эффективное индексирование мультимодальных данных с помощью Milvus
- Мы используем OpenAI CLIP для кодирования изображений в эмбеддинги, которые затем могут быть найдены с помощью Milvus.
- Мы используем модель Mistral Embedding для кодирования текста в эмбеддинги.
Получаем релевантный контекст на основе запросов пользователя с помощью Milvus
Генерирование ответов с помощью Pixtral, работающего с vLLM, используя визуальное и текстовое понимание.
К концу этого урока вы создадите гибкую, масштабируемую систему, полностью подконтрольную вам, и больше не будете беспокоиться об устаревании API или неожиданных изменениях.
Что такое Milvus?
Milvus - это высокопроизводительная и масштабируемая векторная база данных с открытым исходным кодом, которая может хранить, индексировать и искать миллиардные объемы неструктурированных данных через высокоразмерные векторные вкрапления. Она идеально подходит для создания современных приложений ИИ, таких как поиск с расширенной генерацией (RAG), семантический поиск, мультимодальный поиск и рекомендательные системы. Milvus эффективно работает в различных средах, от ноутбуков до крупномасштабных распределенных систем.
Что такое vLLM?
Основная идея vLLM (Virtual Large Language Model) заключается в оптимизации обслуживания и выполнения LLM за счет использования эффективных методов управления памятью. Вот ключевые аспекты:
- Оптимизированное управление памятью: vLLM реализует передовые методы распределения и управления памятью, чтобы полностью использовать доступные аппаратные ресурсы. Эта оптимизация помогает эффективно запускать большие языковые модели, предотвращая узкие места в памяти, которые могут снижать производительность.
- Динамическая пакетная обработка: vLLM адаптирует размер и последовательность пакетов в зависимости от памяти и вычислительных возможностей базового оборудования. Эта динамическая настройка повышает пропускную способность и минимизирует задержки при выводе модели.
- Модульная конструкция: Архитектура vLLM является модульной, что обеспечивает простую интеграцию с различными аппаратными ускорителями. Эта модульность также позволяет легко масштабировать систему на несколько устройств или кластеров, что делает ее легко адаптируемой к различным сценариям развертывания.
- Эффективное использование ресурсов: vLLM оптимизирует использование критически важных ресурсов, таких как CPU, GPU и память. Такая эффективность позволяет системе поддерживать более крупные модели и обрабатывать большее количество одновременных запросов, что очень важно в производственных средах, где масштабируемость и производительность имеют ключевое значение.
- Бесшовная интеграция: Разработанный для плавной интеграции с существующими фреймворками и библиотеками машинного обучения, vLLM предоставляет дружественный интерфейс. Благодаря этому разработчики могут легко развертывать и управлять большими языковыми моделями в различных приложениях без значительной перенастройки.
Основные компоненты нашей мультимодальной RAG
Мультимодальное приложение RAG, которое мы создаем, состоит из следующих ключевых компонентов:
- vLLM - библиотека выводов, которую мы будем использовать для вывода и обслуживания мультимодальной модели Pixtral.
- Koyeb обеспечивает инфраструктурный слой для нашего развертывания, предлагая бессерверную платформу, специализированную для ИИ-нагрузок. Благодаря встроенной интеграции vLLM и автоматизированному управлению ресурсами GPU, она позволяет легко развернуть LLM, сохраняя производительность и масштабируемость производственного уровня.
- Pixtral от Mistral AI выступает в роли нашего мультимодального мозга, объединяя 400M параметров кодера зрения с 12B параметрами мультимодального декодера. Такая архитектура позволяет ему обрабатывать изображения и текст в одном и том же контекстном окне.
- Milvus обеспечивает основу для хранения векторов, эффективно управляя вкраплениями из различных модальностей. Его способность обрабатывать множество типов векторов и выполнять быстрый поиск сходства делает его идеальным для мультимодальных приложений.
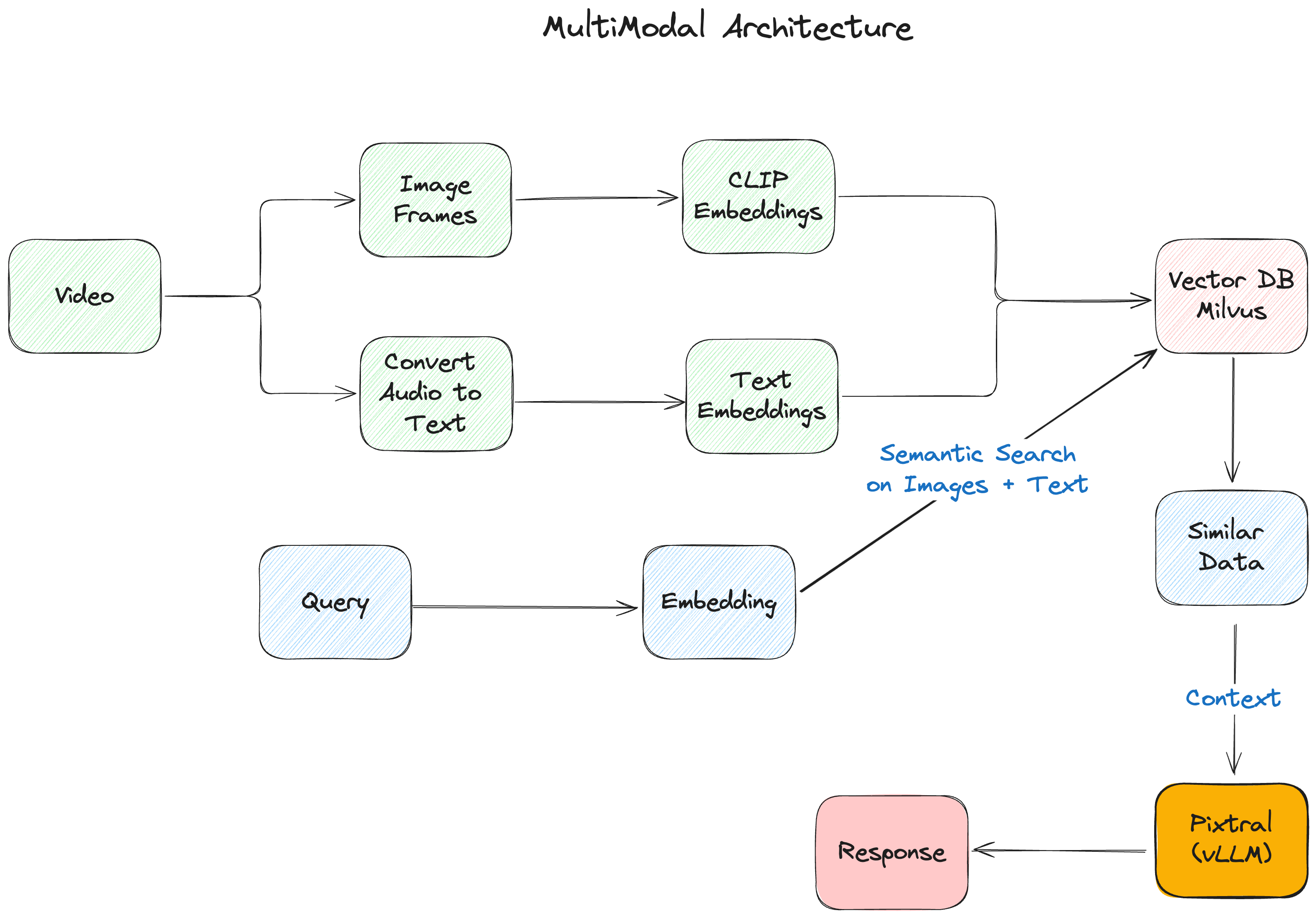 Рисунок - Мультимодальная архитектура RAG.png
Рисунок - Мультимодальная архитектура RAG.png
Рисунок: Мультимодальная архитектура RAG
Начало работы
Сначала установим наши зависимости:
``Python
Основные пакеты LlamaIndex
pip install -U llama-index-vector-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
Обработка видео и аудио
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
Обработка и визуализация изображений
pip install torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
Утилиты и инфраструктура
pip install pymilvus streamlit ftfy regex tqdm
## Настройка окружения
Начнем с настройки окружения и импорта необходимых библиотек:
``Python
импорт os
import base64
import json
from pathlib import Path
from dotenv import load_dotenv
from llama_index.core import Settings
from llama_index.embeddings.mistralai import MistralAIEmbedding
# Загрузка переменных окружения
load_dotenv()
# Настройте модель встраивания по умолчанию
Settings.embed_model = MistralAIEmbedding(
"mistral-embed",
api_key=os.getenv("MISTRAL_API_KEY")
)
Конвейер обработки видео
Сердцем нашей системы является конвейер обработки видео, который преобразует необработанный видеоконтент в данные, которые наша система RAG может понять и эффективно обработать.
``Python def process_video(video_path: str, output_folder: str, output_audio_path: str) -> dict: # Создаем выходной каталог, если он не существует Path(output_folder).mkdir(parents=True, exist_ok=True)
# Извлечение кадров из видео
video_to_images(video_path, output_folder)
# Извлечение и расшифровка аудио
video_to_audio(video_path, output_audio_path)
text_data = audio_to_text(output_audio_path)
# Сохранить транскрипцию
with open(os.path.join(output_folder, "output_text.txt"), "w") as file:
file.write(text_data)
os.remove(output_audio_path)
return {"Автор": "Пример автора", "Заголовок": "Пример заголовка", "Просмотры": "1000000"}
Этот конвейер разбивает видео на части:
- Кадры изображения (извлекаются со скоростью 0,2 кадр/с)
- Аудио транскрипция с помощью Whisper
- Метаданные о видео
## Построение векторного индекса
Мы используем Milvus для хранения наших мультимодальных вкраплений. Вот как мы создаем наш индекс:
``Python
def create_index(output_folder: str):
# Создаем разные коллекции для текста и изображений
text_store = MilvusVectorStore(
uri="milvus_local.db",
имя_коллекции="text_collection",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="image_collection",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
хранилище_изображений=хранилище_изображений
)
# Загрузка и индексирование документов
документы = SimpleDirectoryReader(output_folder).load_data()
return MultiModalVectorStoreIndex.from_documents(
документы,
storage_context=storage_context
)
Обработка запросов с помощью Pixtral
Когда пользователь задает вопрос, нам необходимо:
- Извлечь соответствующий контекст из нашего векторного хранилища
- Обработать запрос с помощью Pixtral, используя как текст, так и изображения.
Вот наша функция обработки запроса:
``Python def process_query_with_image(query_str, context_str, metadata_str, image_document): client = OpenAI( base_url=os.getenv("KOYEB_ENDPOINT"), api_key=os.getenv("KOYEB_TOKEN") )
with open(image_document.image_path, "rb") as image_file:
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Учитывая предоставленную информацию, включая соответствующие изображения и извлеченный контекст
из видео, точно и точно ответьте на запрос без каких-либо
дополнительных предварительных знаний.
---------------------
Контекст: {context_str}
Метаданные: {metadata_str}
---------------------
Запрос: {query_str}
Ответ: """
# Подготовка сообщений для Pixtral
messages = [
{
"роль": "пользователь",
"content": [
{
"type": "текст",
"text": qa_tmpl_str.format(
context_str=context_str,
query_str=query_str,
metadata_str=metadata_str
)
},
{
"type": "image_url",
"image_url": {
"url": f "data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
completion = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
сообщения=сообщения,
max_tokens=300
)
return completion.choices[0].message.content
## Создание интерфейса Streamlit
Наконец, мы создадим удобный интерфейс Streamlit:
``Python
def main():
st.title("MultiModal RAG with Pixtral & Milvus")
# Инициализация состояния сессии
if 'index' not in st.session_state:
st.session_state.index = None
st.session_state.retriever_engine = None
st.session_state.metadata = None
# Ввод видео
video_path = st.text_input("Введите путь к видео:")
если video_path и не st.session_state.index:
with st.spinner("Обработка видео..."):
# Обработка видео и создание индекса
[... код обработки ...]
if st.session_state.index:
st.subheader("Пообщайтесь с видео")
query = st.text_input("Задайте вопрос о видео:")
if query:
with st.spinner("Генерируем ответ..."):
# Генерируем и отображаем ответ
[... код обработки запроса ...]
if __name__ == "__main__":
main()
Запуск приложения
Перед запуском приложения убедитесь, что у вас есть:
- Настройте переменные окружения в файле
.env. - Установили все необходимые зависимости
Затем запустите приложение:
``Bash streamlit run app.py
Вы увидите домашнюю страницу, где вы можете:
- Загружать видео для обработки
- Задавать вопросы о содержании видео
- Прочитать ответы от Pixtral с соответствующими кадрами видео
Рисунок: Интерфейс мультимодального приложения RAG, созданного с помощью Milvus и Pixtral
Теперь вы можете взаимодействовать с видео и, например, узнать больше о гауссовом распределении.

Рисунок: Выполнение мультимодального поиска
## Заключение
В этой статье мы показали, как построить мощную мультимодальную систему RAG с использованием Milvus, Pixtral и vLLM. Благодаря сочетанию эффективных возможностей векторного хранения Milvus и продвинутого мультимодального понимания Pixtral мы создали систему, которая может обрабатывать, понимать и отвечать на запросы о видеоконтенте. И эта система полностью под вашим контролем.
## Мы будем рады услышать ваше мнение!
Если вам понравилась эта статья в блоге, пожалуйста, подумайте:
- ⭐ Дать нам звезду на [GitHub](https://github.com/milvus-io/milvus)
- 💬 Присоединиться к нашему сообществу [Milvus Discord](https://discord.gg/FG6hMJStWu), чтобы поделиться своим опытом
- 🔍 Изучите наш репозиторий [Bootcamp](https://github.com/milvus-io/bootcamp), чтобы найти больше примеров мультимодальных приложений с Milvus

Читать далее

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.