




Funções de Ativação em Redes Neurais

Funções de Ativação em Redes Neurais
 Activation Functions.png
Activation Functions.png
Avanços recentes em inteligência artificial (IA ) têm sido incríveis, particularmente em reconhecimento de imagens, processamento de linguagem natural (NLP) e carros autônomos. Um fator-chave que contribui para essas conquistas é a capacidade das redes neurais artificiais de estimar funções complexas e não lineares frequentemente presentes em dados do mundo real. Essa capacidade é atribuída principalmente às funções de ativação, que introduzem não linearidade nas redes neurais, permitindo que elas modelem relações e padrões complexos.
Vamos entender as funções de ativação em profundidade, seu propósito, como funcionam e por que são importantes para redes neurais.
O que são Funções de Ativação?
Funções de ativação são funções matemáticas usadas em redes neurais para determinar a saída de um neurônio, introduzindo não linearidade no modelo. Elas são aplicadas às entradas dos nós (neurônios), as unidades fundamentais de uma rede neural, para produzir a saída do nó. Uma rede neural calcula a soma ponderada das entradas, adiciona um viés e então passa essa soma pela função de ativação, que produz um valor modificado. Esse valor é passado para a próxima camada da rede ou se torna a saída final.
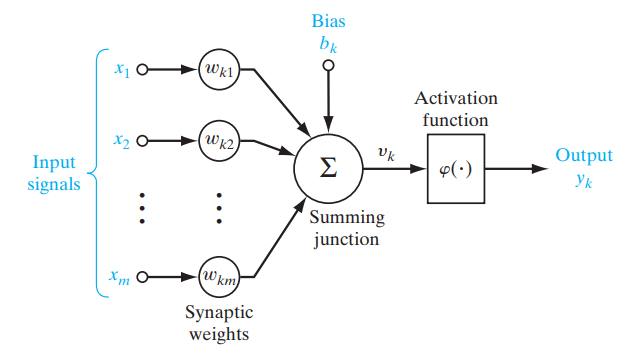 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
Figura: Papel de uma função de ativação em uma rede neural. | Fonte
Por que a Não Linearidade Importa?
Para entender por que as funções de ativação são essenciais, é importante saber por que modelos lineares têm limitações. Um modelo linear representa uma relação em linha reta entre entradas e saídas. Ele funciona bem em tarefas simples, mas falha quando os dados são mais complexos e têm padrões não lineares.
A não linearidade permite que redes neurais criem fronteiras de decisão que não são linhas retas. Portanto, redes neurais podem entender padrões não lineares nos dados que não podem ser representados por modelos lineares.
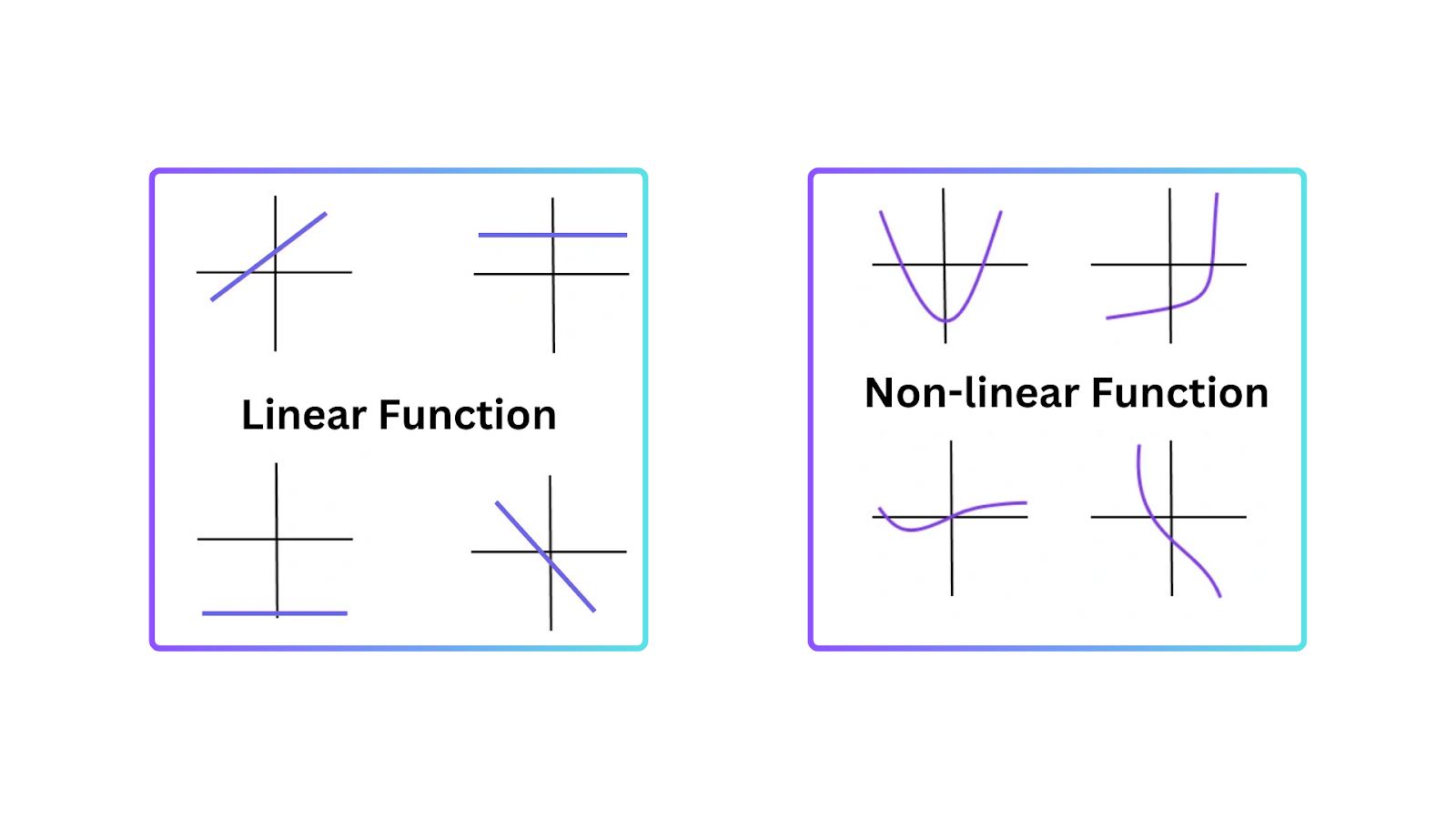 Figure- Types of Functions.png
Figure- Types of Functions.png
Figura: Tipos de Funções
Como as Funções de Ativação Funcionam
Agora que apresentamos as funções de ativação, vamos ver como essas funções funcionam matematicamente para converter o sinal de entrada em um sinal de saída, uma faixa frequentemente entre 0 e 1 ou -1 e 1. Em cada neurônio em uma rede neural, os dados fluem pelas seguintes etapas:
Entrada: Cada neurônio em uma rede neural recebe uma ou mais entradas. Essas entradas podem vir dos dados originais alimentando a rede (no caso da camada de entrada) ou das saídas dos neurônios na camada anterior.
Cálculo da soma ponderada: As entradas são multiplicadas por pesos correspondentes para determinar sua importância. Em seguida, as entradas ponderadas são somadas, e um único valor é retornado, conhecido como soma ponderada.
Aplicação da função de ativação: Uma vez calculada a soma ponderada, ela é passada por uma função de ativação, e o resultado da função de ativação se torna a saída do neurônio.
Esse processo se repete em cada neurônio nas camadas da rede para transformar os dados de maneiras mais complexas.
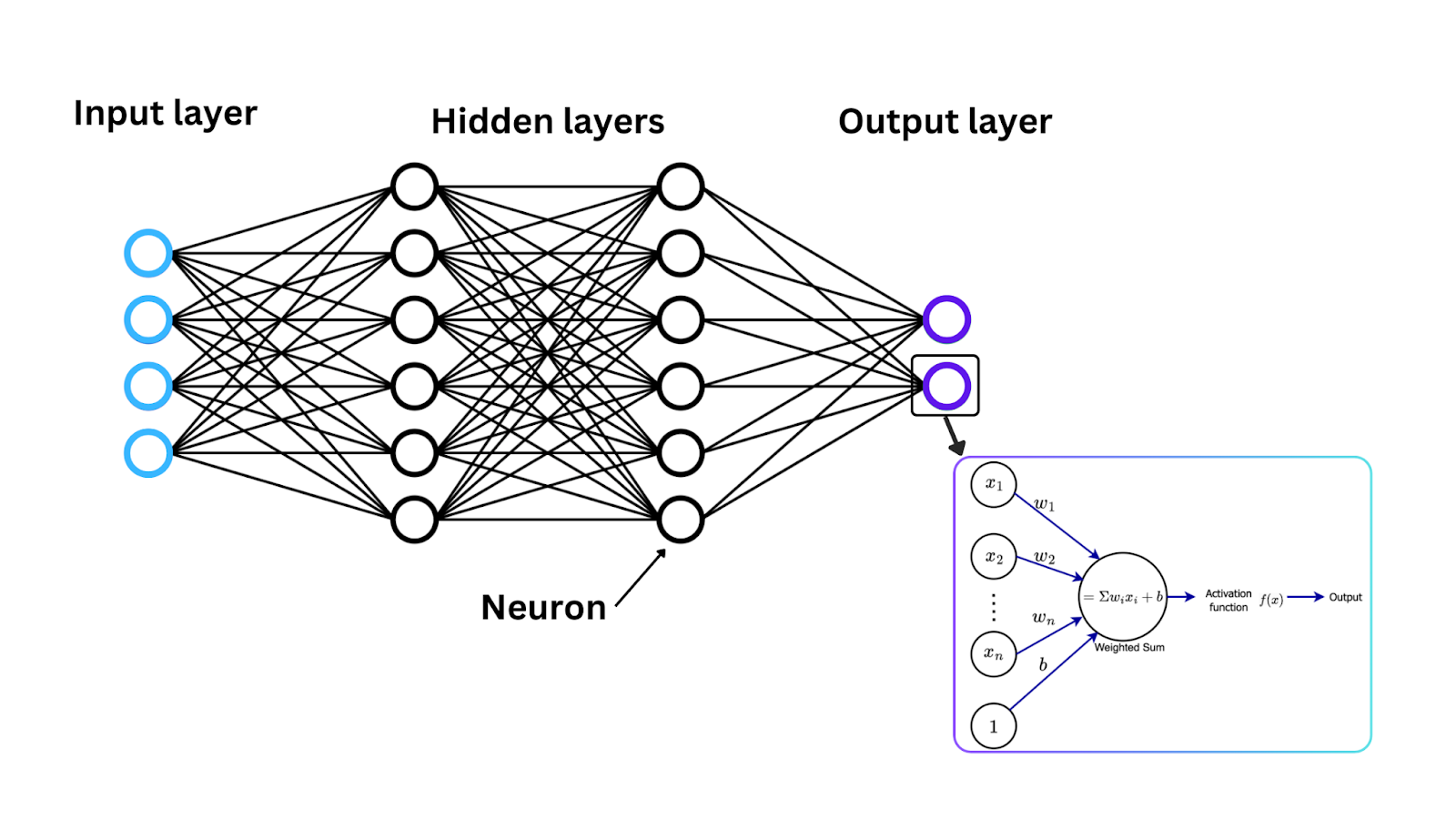 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figura: Arquitetura de rede neural, função de ativação e atualizações de pesos dos neurônios.
Redes neurais usam diferentes tipos de funções de ativação. Cada função tem seus próprios pontos fortes e é mais adequada para tarefas específicas. Por exemplo, a função sigmoid é ideal para problemas de classificação binária, softmax é útil para previsão multiclasse, e ReLU ajuda a superar o problema do gradiente desvanecente.
Escolher a função de ativação correta acelera o treinamento e melhora o desempenho. Agora, vamos ver algumas das funções de ativação comuns:
Ativação Sigmoid
Ativação ReLU (Rectified Linear Unit)
Ativação Tanh (Tangente Hiperbólica)
Ativação Leaky ReLU
Ativação Sigmoid
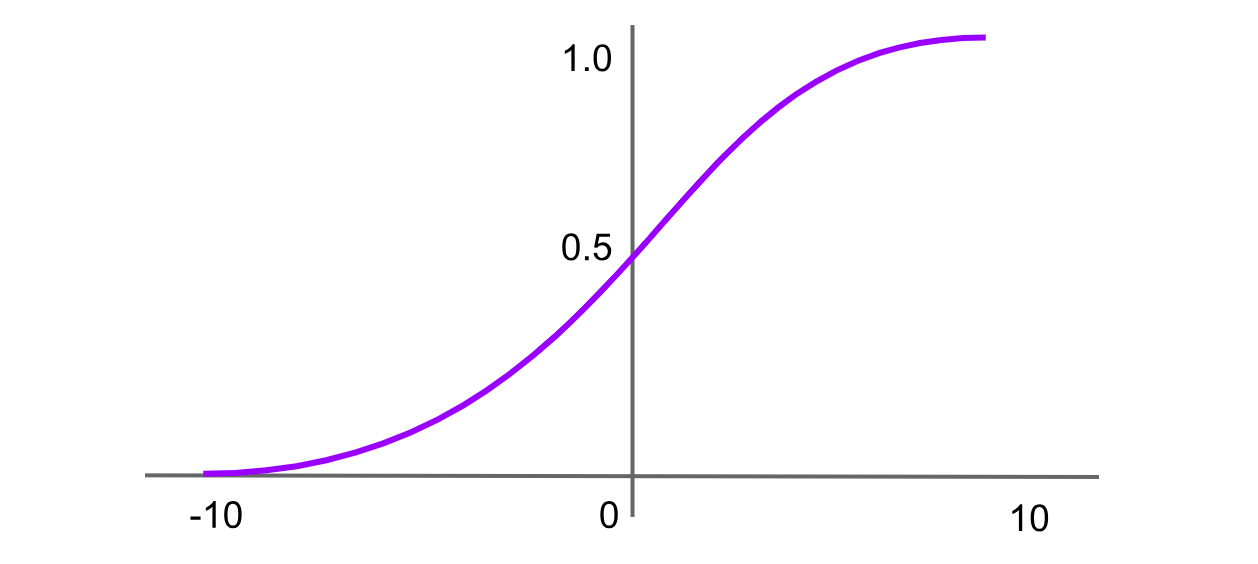 Figure- Sigmoid activation function.png
Figure- Sigmoid activation function.png
Figura: Função de ativação sigmoid
A função sigmoid, também conhecida como função logística, é uma das primeiras e mais amplamente conhecidas funções de ativação. Ela mapeia qualquer valor de entrada para um intervalo entre 0 e 1, produzindo uma curva em forma de "S". A fórmula para a função sigmoid é:
Sigmoid = σ(x) = 1 / (1 + exp(-x))
Aqui está o código para definir a função sigmoid em Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Funções sigmoid são úteis para modelos em que precisamos prever a probabilidade como saída. Por exemplo, em problemas de classificação binária, queremos que a saída seja interpretada como uma probabilidade entre 0 e 1.
No entanto, a Sigmoid tem um problema de gradiente desvanecente. Durante a retropropagação (quando a rede aprende atualizando pesos), os gradientes sigmoid se tornam muito pequenos, o que causa aprendizado lento para camadas mais profundas.
Ativação Softmax
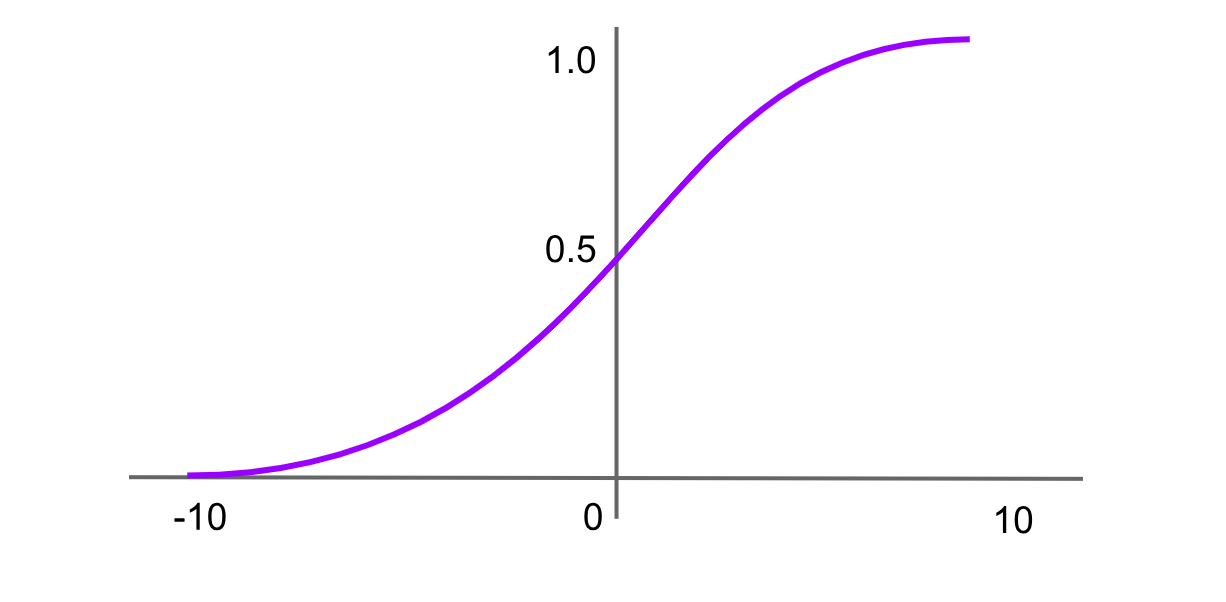 Figure- Softmax activation function.png
Figure- Softmax activation function.png
Figura: Função de ativação softmax
A função softmax é comumente usada na camada de saída de redes neurais para problemas de classificação multiclasse. Ela recebe um vetor de números reais como entrada e o normaliza em uma distribuição de probabilidade sobre as classes. Cada saída fica entre 0 e 1, e todas as saídas somam 1. A fórmula para a função softmax é:
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Vamos codificar isso em Python.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
No entanto, Softmax pode ser computacionalmente caro, especialmente em redes grandes, pois exige calcular exponenciais e normalizá-las por todas as saídas.
Ativação ReLU (Rectified Linear Unit)
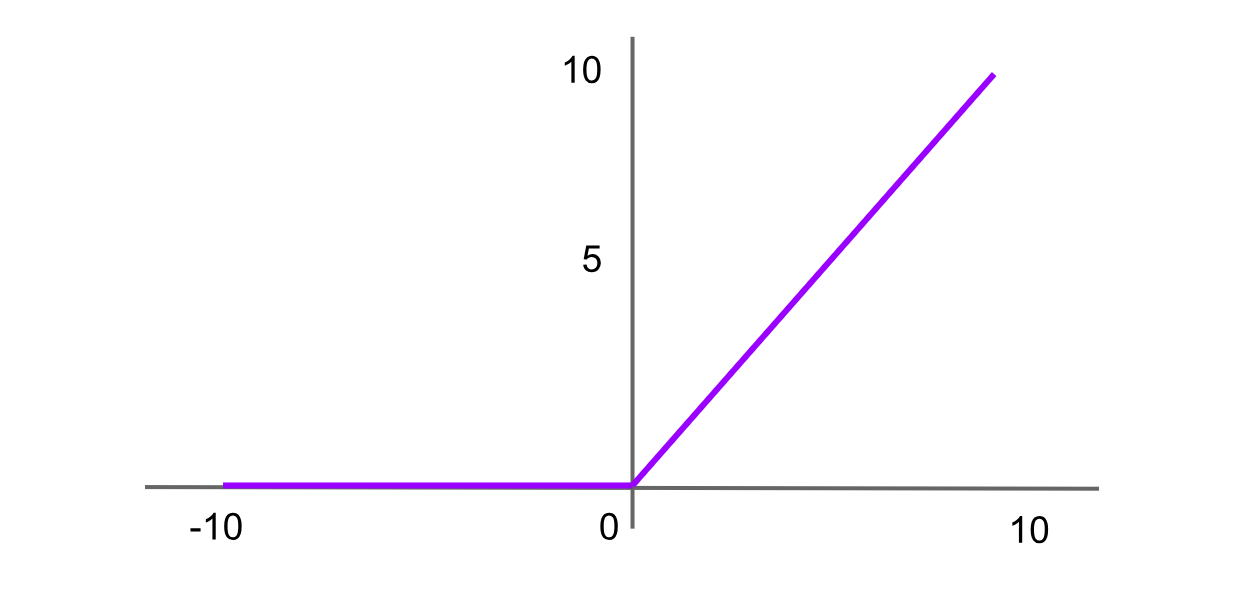 Figure- ReLU activation function.png
Figure- ReLU activation function.png
Figura: Função de ativação ReLU
ReLU é uma das funções de ativação mais amplamente usadas em redes neurais avançadas. Ela retorna 0 para qualquer entrada negativa e, para valores positivos, retorna o próprio valor. A fórmula para a função ReLU é:
ReLU = f(x) = max(0,x)
Aqui está a função Python para ReLU:
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU é usada em camadas ocultas de redes neurais, particularmente em tarefas de visão computacional. Ela é computacionalmente eficiente porque não possui operações exponenciais ou de divisão. Em comparação com sigmoid, também é menos afetada pelo problema do gradiente desvanecente. No entanto, há uma desvantagem da ReLU, que é o problema da “ReLU morrendo”. Se um neurônio produz consistentemente zero para todas as entradas, ele se torna inativo e não consegue mais contribuir para o aprendizado.
Ativação Tanh (Tangente Hiperbólica)
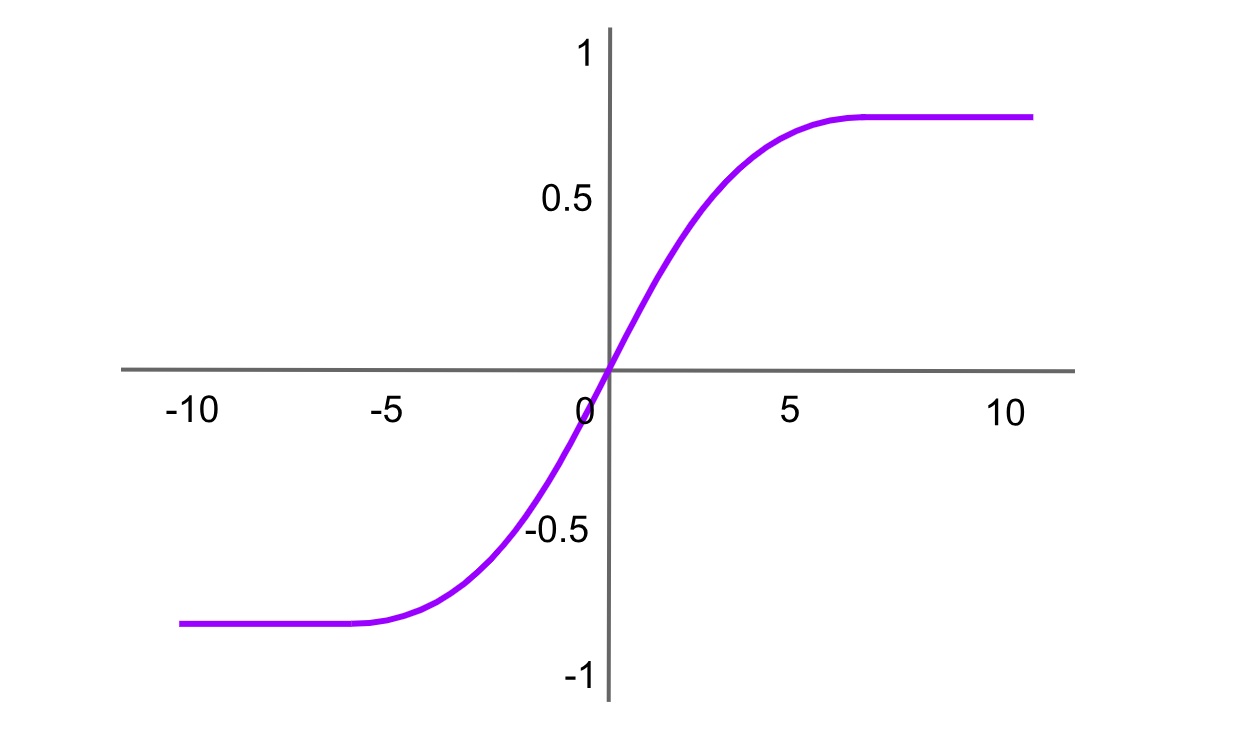 Figura- Função de ativação Tanh .png
Figura- Função de ativação Tanh .png
Figura: Função de ativação Tanh
A função tangente hiperbólica é semelhante à função sigmoide, mas gera valores entre -1 e 1. A fórmula da função Tanh é:
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
Ou
tanh(x)= f(x)=2sigmoid(2x)-1
Aqui está o código Python para a mesma:
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
A tangente hiperbólica é usada em camadas ocultas de redes neurais, particularmente em tarefas de processamento de linguagem natural (NLP). Ela compartilha algumas semelhanças com a função sigmoide, mas tem a vantagem de ser centrada em zero, o que pode acelerar o aprendizado em certas redes. No entanto, assim como a função sigmoide, tanh também é afetada pelo problema do gradiente desvanecente.
Ativação Leaky ReLU
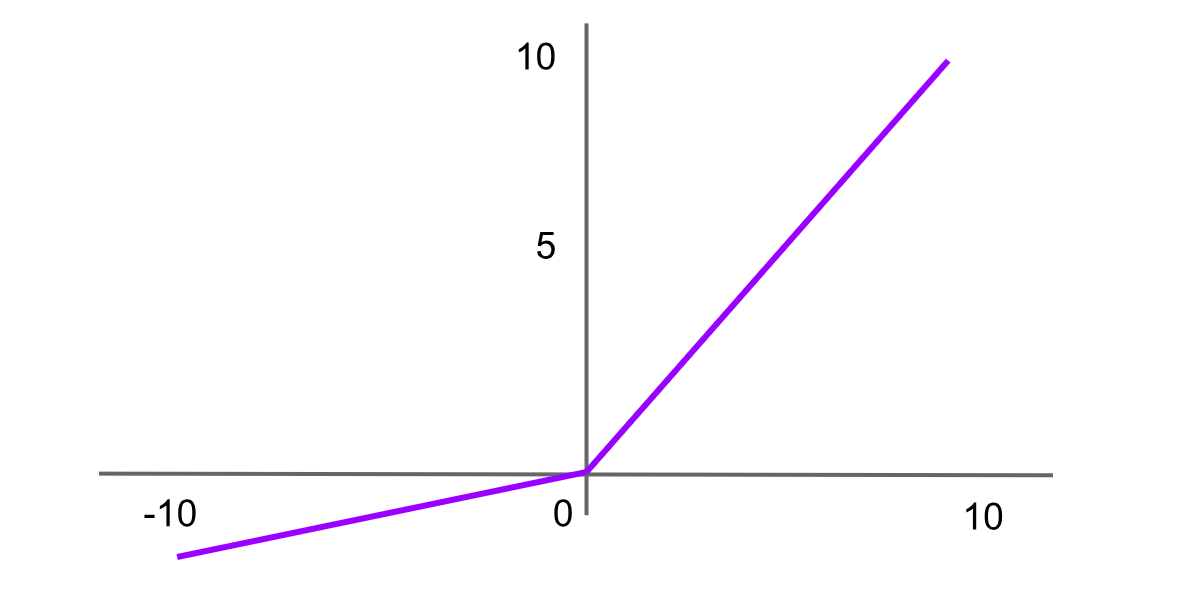 Figura- Função de ativação Leaky ReLU .png
Figura- Função de ativação Leaky ReLU .png
Figura: Função de ativação Leaky ReLU
Leaky Rectified Linear Unit, ou Leaky ReLU, é uma variante da ReLU projetada para resolver o problema da “ReLU morrendo” ao introduzir uma pequena inclinação para valores negativos em vez de uma inclinação plana. Isso ajuda os neurônios a continuarem aprendendo em vez de ficarem permanentemente inativos. A fórmula da função Leaky ReLU é:
Leaky ReLU = f(x)=max(αx,x)
Aqui, 𝛼 α é uma pequena constante positiva (por exemplo, 0,01) para garantir que o neurônio gere um pequeno valor negativo em vez de zero para entradas negativas. Como a Leaky ReLU é uma variante da ReLU, o código Python pode ser implementado com uma pequena modificação.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Comparação
Para obter uma compreensão melhor das funções de ativação, é útil compará-las com outros componentes-chave das redes neurais:
Funções de Ativação vs. Funções de Perda
As funções de ativação definem como os neurônios em uma rede respondem aos sinais de entrada. Elas são aplicadas às saídas dos neurônios (ou camadas) para introduzir não linearidade, o que ajuda a rede a entender padrões e relações nos dados.
Por outro lado, as funções de perda são usadas para determinar quão bem as previsões da rede neural correspondem aos valores-alvo reais (a verdade fundamental). Elas calculam o erro entre a saída prevista e os resultados reais. Além disso, algoritmos de Otimização ajustam os pesos da rede durante o treinamento para minimizar esse erro. As funções de perda incluem:
Erro Quadrático Médio (MSE) é comumente usado para tarefas de regressão.
Perda de entropia cruzada é usada para tarefas de classificação.
Funções de Ativação vs. Normalização
As funções de ativação controlam como os dados se movem de uma camada para outra e como os neurônios "disparam" com base nas entradas.
No entanto, a Normalização, como a normalização em lote, ajuda a tornar o treinamento mais eficaz. Elas funcionam modificando a distribuição das entradas de uma camada para acelerar o aprendizado da rede e evitar gradientes desvanecentes ou explosivos. A normalização em lote normaliza a entrada de cada camada para ter uma média e variância consistentes e ajuda a tornar a convergência da rede mais fácil. Outras técnicas de normalização incluem:
Normalização de camada: Normaliza em cada camada.
Normalização de instância: Geralmente usada em processamento de imagens, normaliza cada instância separadamente.
Benefícios e Desafios das Funções de Ativação
As funções de ativação oferecem várias vantagens às redes neurais, mas também apresentam desafios que precisam ser abordados. Vamos primeiro discutir os benefícios das funções de ativação.
Não linearidade: O benefício mais importante das funções de ativação é que elas introduzem não linearidade na rede. Isso ajuda as redes a capturar padrões não lineares nos dados e é ideal para tarefas como reconhecimento de imagens e compreensão de linguagem natural.
Intervalo de saída: Funções de ativação como sigmoid e softmax limitam as saídas dentro de um intervalo específico (0-1 para sigmoid e entre -1 e 1 para tanh). Isso torna muito mais simples entender as saídas, especialmente em tarefas de classificação.
Computação eficiente: Algumas funções, como ReLU, são computacionalmente eficientes, o que permite que as redes sejam escaladas e aplicadas a grandes conjuntos de dados.
Agora, vamos discutir os desafios das funções de ativação.
Problema do gradiente evanescente: é comum em redes neurais profundas, principalmente ao usar funções de ativação como sigmoid e tanh. Durante a retropropagação, os gradientes podem se tornar muito pequenos à medida que se propagam por várias camadas da rede, causando a convergência lenta da rede e impedindo o aprendizado eficaz.
Gradientes explosivos: Gradientes explosivos são um problema no qual grandes gradientes de erro se acumulam, resultando em atualizações muito grandes nos pesos dos modelos de redes neurais durante o processo de treinamento. Isso torna o modelo instável e incapaz de aprender com os dados de treinamento.
Escolha da função: Escolher a função de ativação ideal para uma tarefa ou rede neural pode ser desafiador e geralmente requer alguma experimentação. Depende do tipo de problema que estamos tentando resolver.
Casos de Uso das Funções de Ativação
As funções de ativação são componentes importantes de várias arquiteturas de redes neurais que executam diferentes tarefas. Aqui estão algumas aplicações principais:
Classificação de imagens: Redes Neurais Convolucionais (CNNs) usam a ativação ReLU em suas camadas ocultas para processar dados de pixels e softmax na camada de saída para classificação multiclasse.
Processamento de linguagem natural (NLP): Redes Neurais Recorrentes (RNNs), Long Short-Term Memory (LSTM) e Transformers usam ativações tanh ou ReLU em suas camadas ocultas para processar dados sequenciais.
Modelos generativos: Redes Generativas Adversariais (GANs) normalmente usam ReLU ou LeakyReLU na rede geradora para introduzir não linearidade e gerar saídas realistas e sigmoid na rede discriminadora.
Vários frameworks de aprendizado profundo, incluindo TensorFlow e PyTorch, fornecem uma ampla gama de funções de ativação integradas e implementações para criar as suas personalizadas.
Perguntas Frequentes sobre Funções de Ativação
- O que é a função de ativação?
As funções de ativação são blocos de construção fundamentais das redes neurais que permitem que elas aprendam padrões complexos nos dados de entrada. Elas convertem o sinal de entrada de um nó (neurônio) em um sinal de saída, que então é passado para a próxima camada da rede neural.
- Por que a função de ativação ReLU é usada?
A função de ativação ReLU introduz não linearidade em uma rede neural, o que ajuda a reduzir o problema do gradiente evanescente durante o treinamento do modelo de aprendizado de máquina.
- Quais são as funções de ativação mais comumente usadas?
ReLU, Leaky ReLU, Softmax e Swish são funções de ativação populares.
- Para que é usada a função de ativação?
O principal objetivo de uma função de ativação é transformar a entrada ponderada somada de um nó em um valor de saída, que então é passado para a próxima camada oculta ou usado como a saída final.
- Você pode ter múltiplas funções de ativação?
Sim, é comum ter diferentes funções de ativação em diferentes camadas de uma rede neural. Por exemplo, uma configuração padrão pode usar ativação ReLU nas camadas ocultas e softmax na camada de saída para um problema de classificação multiclasse.
Recursos adicionais
- O que são Funções de Ativação?
- Como as Funções de Ativação Funcionam
- Comparação
- Benefícios e Desafios das Funções de Ativação
- Casos de Uso das Funções de Ativação
- Perguntas Frequentes sobre Funções de Ativação
- Recursos adicionais
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis